
EoC带宽增强方案的设计和实现
2015-12-20 06:59:12刘孝圣郑艳伟
计算机工程与设计 2015年1期
刘孝圣,刘 磊,郑艳伟,彭 飞
(1.中国科学院大学,北京100190;2.中国科学院声学研究所国家网络新媒体工程技术研究中心,北京100190)
0 引 言
目前国内进行的混合光纤同轴电缆 (hybrid fiber-coaxial,HFC)接入网双向化改造方案主要有有线传输数据业务接口 规 范[1,2](data over cable service interface specification,DOCSIS)方案和以太网无源光网络+基于同轴电缆的以太网传输[3](Ethernet passive optical network+Ethernet over coax,EPON+EoC)方案。文献 [4]对这几种接入方式进行了详细的比较。EPON+EoC 方案由于其网络设计简单、适合国情和维护简单方便等优点而被大规模采用[2,4],但是其下行带宽仍然不能满足不断增长的带宽需求。为了进一步支持带宽需求较大的业务,需要提升EoC网络的下行带宽,本文提出一种可以有效提升EoC 网络下行带宽的带宽增强方案。由于该方案需要处理较大的网络吞吐,因此选择在网络处理器平台上予以实现。
1 EoC带宽增强方案
图1给出了EoC带宽增强方案的部署。该方案通过在原有的EoC通道之外,新增多个QAM 通道,并利用这些新增通道提升接入用户的下行带宽。在EPON+EoC 方案中,OLT 直接和因特网相连。而在该增强方案下,融合通道网关 (converged channel gateway,CCGW)桥接在OLT和因特网之间,每个OLT 搭配一个CCGW。桥接方式的好处在于不需要对报文进行特殊处理就能让所有的数据包经过CCGW。该方案的优势在于,用户在带宽升级的过程中,仅需要更换或者在线升级机顶盒即可,而且可以根据实际的带宽升级需求,通过更改IPQAM 资源数量来实现渐进扩容。第4节分析了该方案的带宽提升效果。
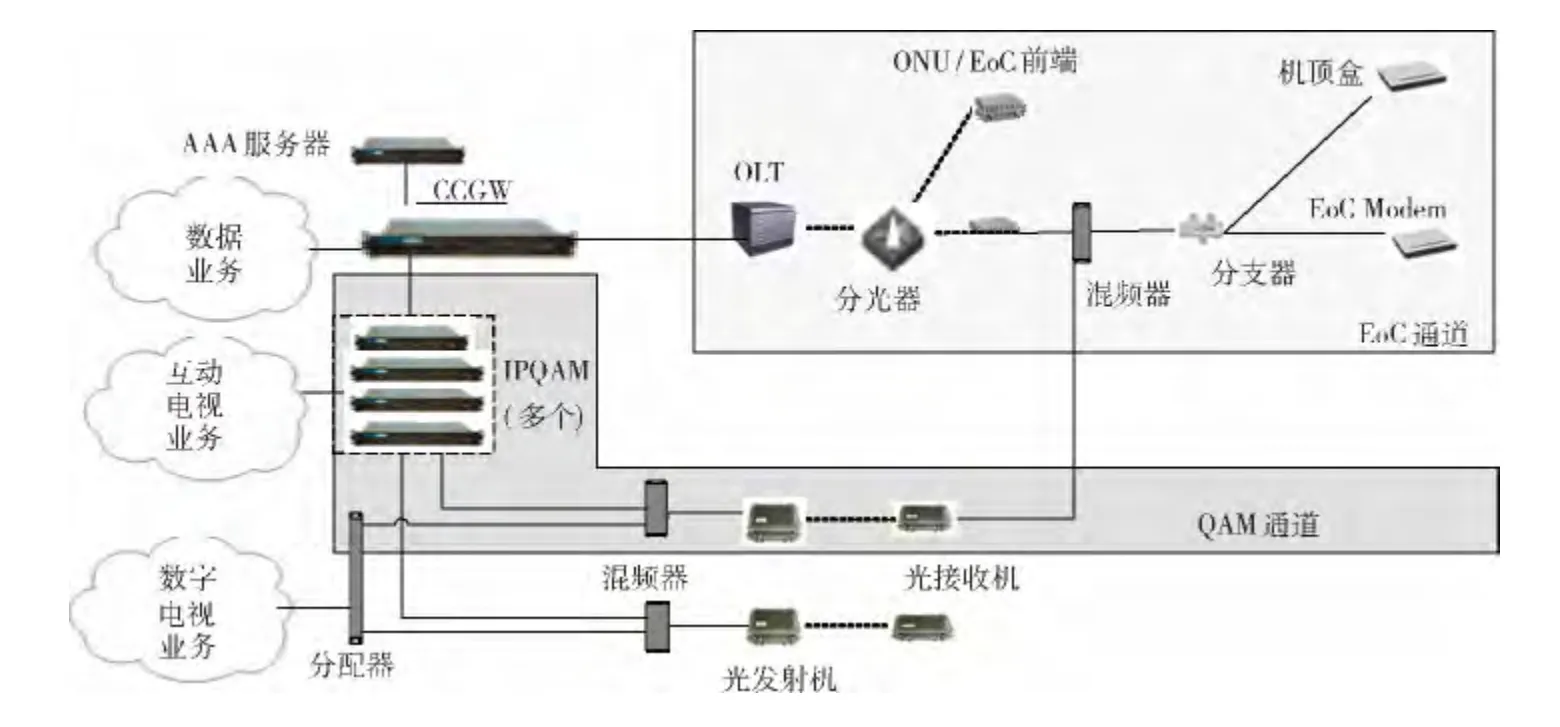
图1 EoC带宽增强方案网络部署
融合通道网关是该方案中的关键设备,CCGW 使用QAM 通道和IP通道协同下发数据,并使用IP通道作为回传,充分利用QAM 通道高带宽的优势实现非对称的宽带数据通信。作为多个用户终端的网关设备,CCGW 需要承载较大的吞吐量,在传统的通用处理器平台上实现很难满足其性能需求,因此在网络处理器平台上进行开发成为一种必要的选择。本文提出了一种在OCTEON CN5860网络处理器平台上的设计和实现方式。实际测量结果显示平均每个处理核心可以提供920 Mbps的吞吐量。
2 CN5860处理器简介
CN5860处理器是Cavium 公司开发的64位MIPS架构的多核网络处理器,采用系统级芯片技术,将多个同构处理引擎或处理核心 (process engine,PE)、多种功能的协处理器以及丰富的网络接口集成在同一颗处理器上,通过集成一系列的硬件加速单元来优化对网络数据包的处理过程。如利用硬件进行TCP/UDP 数据包的校验和计算、完整性检查;利用硬件定时器设置实现对TCP数据流的加速处理,硬件支持多种加密算法[5,6]。支持16 个主频为800 MHz的PE。图2给出了CN5860处理器的硬件结构。
2.1 基本硬件单元
以 “接收-处理-转发”网络报文为例,通过说明该处理器的处理流程,来介绍涉及到的常用硬件组件。流程大致如下:①PIP/IPD (packet input processing unit/input packet data unit)单元接收数据包,进行如校验、过滤等前期操作后,通过DMA 方式把链路层帧从PIP/IPD 的内部存储空间拷贝至内存,并向SSO (schedule/synchronization/order unit)单元提交消息。内存由FPA (free pool allocator unit)单元管理,通过将内存分为若干种固定大小的块达到高效管理内存、优化数据包处理的效果。②SSO 单元维护消息队列,将消息调度到合适的PE。③PE 处理报文,如加密、校验、查找等操作。④PE 转发该报文,PKO(packet output unit)单元同样通过DMA 方式将 报文数据从FPA 单元拷贝到其内部的存储空间,计算TCP/UDP的校验和,发送数据包,并释放消息和内存空间。
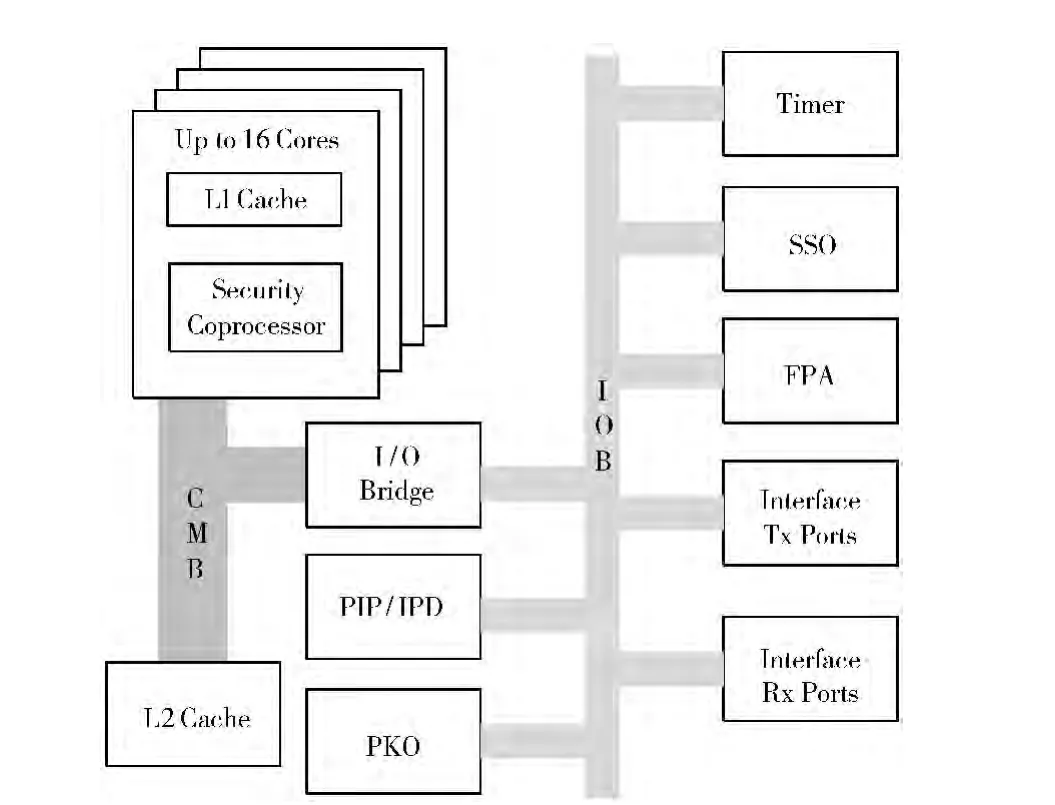
图2 OCTEON CN5860网络处理器硬件结构
在该平台下,定时器也是由硬件实现。系统为每个PE设计了硬件Timer Ring结构,可以通过软件方式设置时间间隔,生成消息,在定时时刻达到时,将消息送入SSO,由SSO 进行调度。
2.2 消 息
消息是SSO 进行调度的基本单位,是在OCTEON 平台上开发应用时的一个重要概念。SSO 维护消息队列,并且从消息队列中取出消息时,根据消息的类型将该消息分配给PE 处理。除了在PIP/IPD 硬件接收到数据包时向SSO 提交消息 (此时消息携带链路层数据帧的完整信息)外,也可以利用系统内置的add_work ()操作向SSO 中添加消息。常见的利用软件设置消息的场景是添加定时器。由于定时器和数据包都是通过消息实现的,在PE收到消息时仅需简单判断是定时器消息还是报文消息即可。
3 CCGW 的设计和实现
作为该EoC带宽增强方案中的关键设备,CCGW 需要融合两种通道并优化调度这两种通道的带宽资源。其特点体现在:
(1)采用类似于链路层交换机的 “学习-转发”方式对上行数据包和未进行带宽升级的用户 (简称“未升级用户”,下同)的下行数据包在原有的EoC通道上透明传输,利用网络处理器平台高效的转发机制实现上行报文的快速处理。
(2)为已升级用户的下行数据包选择合适的通道(EoC通道或者某个QAM 通道)进行转发,采用以流为单位的分配方式,保证属于同一条流的数据包的顺序关系。在QAM 通道转发前,采用IP over DVB 中最常用的MPE(multi-protocol encapsulation)协 议 将 数 据 包 封 装 成QAM设备所需的格式,利用网络处理器多核并行处理的优势保证吞吐量。
(3)CCGW 维护、分配和回收QAM 通道的频点资源,维护已升级终端的状态信息,维护流和通道的对应关系,对这些信息的查询操作次数要远大于修改的次数,因此采用Hash表存储,达到快速响应查询请求的目的。采用令牌桶技术对用户和各通道的流量进行限速,保证用户的公平性和系统的稳定性。
由于CCGW 需要承载较大的吞吐量,因此在功能实现的同时,也必须考虑处理过程的优化,减少不必要的开销,加速网络数据包的处理。结合OCTEON 5860 处理器的特性,根据上述CCGW 的主要特点,设计了CCGW 的模块,并划分为控制层面和数据层面,如图3所示。
3.1 控制平面
控制平面主要负责与客户端的信令交互、请求认证客户、管理系统的频点资源,以及维护终端状态等。
3.1.1 基本模块
控制平面的模块和对应的功能如下:①频点管理模块负责管理、分配和回收频点资源,维护频点状态 (如剩余带宽、用户数量等);②客户端管理模块维护终端状态,包括终端标识、终端密码、终端状态、最大带宽、业务类别等信息;③信令交互模块负责与终端设备的信令交互,包括终端的注册、保活等交互报文的解析和处理;④配置管理模块负责CCGW 的配置、管理以及请求对用户进行认证;⑤轮播模块通过在IPQAM 通道上广播CCGW 的基本信息,供终端开机注册使用。
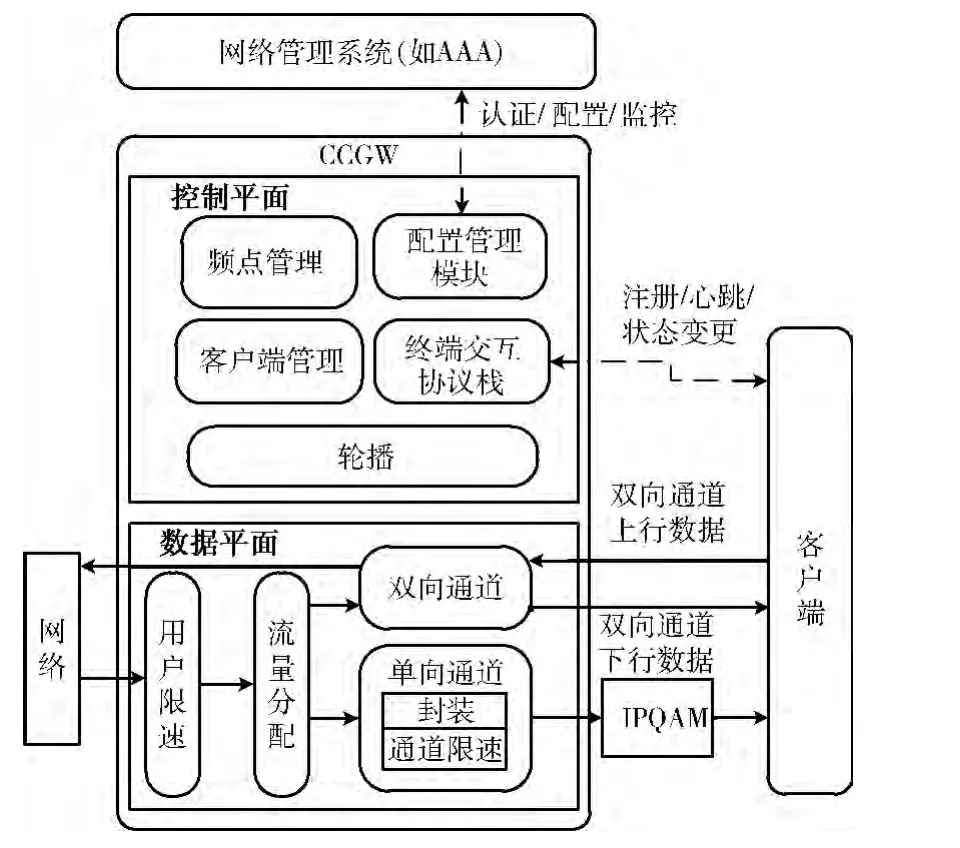
图3 CCGW 基本模块结构
3.1.2 CCGW 与周边设备的交互流程
图4 给出了与终端注册相关的报文交互流程。首先CCGW 通过QAM 通 道 轮 播NIT (network information table),NIT 中包含了CCGW 的注册端口、注册IP以及所在的业务组等注册信息。轮播模块还定时广播PAT (program association table)和PMT (program map table),为终端提供与用户一一对应的PnId (program number identifier)信息。采用轮播方案可以减少对终端设备的人工配置,也便于设备升级和部署。终端上线时扫描并锁定对应频点,解析NIT,获取注册信息后,向CCGW 注册。注册时,CCGW 需要向AAA 服务器认证用户请求服务是否已授权,并为用户分配QAM 通道,通道属性包括PnId、频点、调制方式等等。注册成功后,需要在CCGW 和终端之间定时维护保活信令。
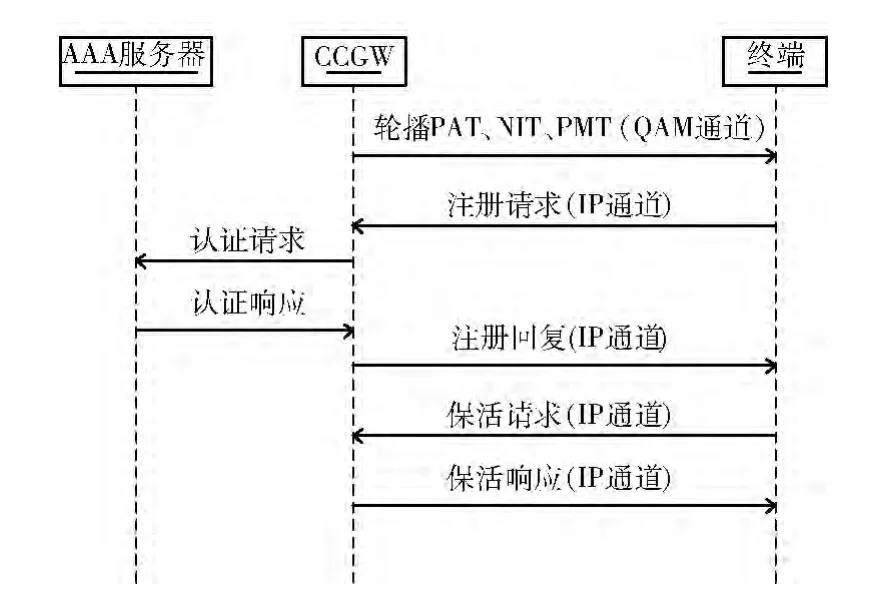
图4 CCGW 与终端交互时序
3.2 数据平面
数据平面分上行和下行进行分别处理。对于上行数据包,CCGW 只需确定对应端口并转发即可;对下行数据包的处理相对复杂,图5给出了下行数据包的大致处理流程。首先检查终端是否注册,未注册则直接通过IP 通道转发;若注册,则根据数据包的属性确定转发通道 (IP通道或者QAM 通道,QAM 通道也有多个);若转发到QAM 通道,首先进行通道的限速处理,然后经多层封装后发往对应的IPQAM。以下对几个模块的处理细节进行详述。
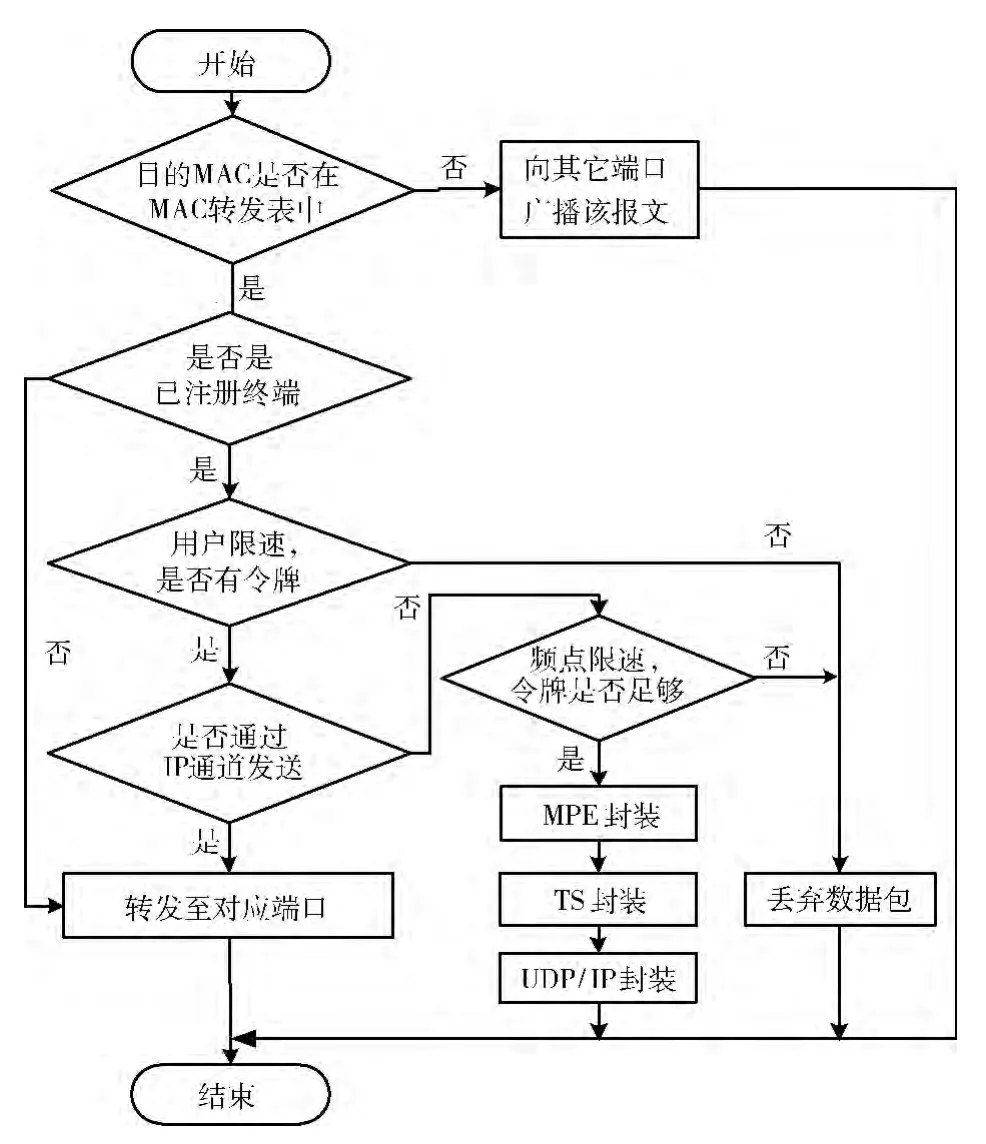
图5 CCGW 数据层面下行数据包流程
3.2.1 流量分配模块
对注册用户而言,下行通道分IP 通道和QAM 通道。由于两种通道物理特性不同,传输延迟等也不同,容易造成客户端接收时报文乱序。为了避免乱序,我们以流为单位进行分配,保证属于同一条流的报文经过同一个通道传输。流标识由协议、目的IP、目的端口、源IP和源端口组合而成。优先将数据流分配到带宽较大的QAM 通道,在QAM 通道剩余带宽 (可以通过通道限速功能的剩余令牌数推断得到)不足时,将部分流分配或者切换到IP 通道上去,提高资源利用率。
3.2.2 封装模块
由于QAM 设备传输TS (transport stream)格式的数据包,所以在发往QAM 通道前要预先处理,这部分功能由封装模块提供。封装主要分为3个步骤:
(1)MPE封装[7],包含12字节的MPE 头部、4字节的尾部CRC字段和载荷部分,载荷部分即为下行的IP 包(包含IP层及其上层的报文信息),MPE 头部中的长度字段指明该IP包的实际长度;
(2)将MPE 封装后的报文进行切分,添加TS 头部,形成为188字节的多个TS包,不足188字节则以0补齐;
(3)添加UDP/IP 头部,目的字段填写为对应的IPQAM 的IP 地 址 和 端 口。TS 中 的PID 字 段 与 注 册 时CCGW 为终端分配的PnId相对应。由于封装部分需要多层封装,耗时最长,因此在实现时应尽量进行优化。通过事先细致地分配报文每部分对应的空间,只需拷贝一次即可,减少了不必要的操作和时间开销。
3.2.3 MAC转发模块
该模块的主要作用是对未升级用户的数据包进行透传,其功能类似于链路层交换机。对于进入CCGW 的数据包,记录和更新源MAC与进入的物理端口,存储在MAC 转发表中,该表采用Hash桶实现;对于CCGW 转发的数据包,如果其目的地址在Hash表中,则往对应的物理端口上进行转发,否则向除进入端口外的其它所有物理端口转发。由于查找该表是处理报文的第一步,因此还在该表项中设置了表示是否注册的标志位,从而减少了一次向终端管理模块查询注册状态的开销。
3.2.4 限速模块
为了保证用户的公平性和系统的稳定性,需要对用户进行限速处理。用户限速和通道限速均采用令牌桶实现。令牌桶是一种简单有效、易实现的流量控制方式。主要步骤是:①系统初始化时,初始化定时器消息;②当定时器消息被调度后,根据与上一次触发的时间差和用户购买的带宽大小往令牌桶里添加相应个数的令牌;③当系统转发时,减去与数据包大小成正比的令牌个数,如果剩余令牌不足,则丢弃该数据包。
3.3 CCGW 的实现
我们采用OCTEON 5860处理器平台配套的SE (simple executive)操作环境,关于该操作环境的详细介绍参考文献 [8]。在该环境下开发可直接操作底层的PE、内存、协处理器等硬件资源,因此有助于提升系统的吞吐量。
根据CCGW 的功能,可将CCGW 视为链路层和网络层设备。在通用处理器平台 (通常安装Linux系统)上,获取链路层和网络层数据通常利用libpcap等工具或原始套接字进行抓包[9]。而在该平台下,PIP/IPD 在接收到网络帧时就向SSO 提交消息,在实现时,PE 直接向SSO 请求消息,判断消息类型,若是报文消息,则通过物理端口分辨上下行报文,解析报文的头部字段,然后进行针对性的操作;如果是定时器消息,则分辨定时器种类后合理处理该定时器任务。发送报文时,CCGW 直接封装好MAC 层帧,并调用底层硬件转发报文,实现报文的快速传输。
CCGW 使用了很多定时器:轮播模块需要定时向终端广播注册信息、信令交互模块需要超时重传、限速模块需要定时增加令牌、MAC转发模块需要删除老化表项以节约内存等。相较于Linux上的基于信号的软件定时方式,使用硬件定时器精度高,并且也被统一成消息,更方便使用,有效地保证了上层的业务处理的高效性。
其它的一些优化还有:利用RNG 硬件协处理器为配置管理模块提供随机数生成功能、利用硬件加密单元为配置管理模块提供MD5校验、利用硬件校验单元计算UDP 数据包和TCP报文的校验和等。
3.4 软件架构
除了利用好网络处理器平台提供的多种硬件加速功能外,还需要选择合适的软件架构[5,6]。在多核处理器件上的软件架构主要有流水线架构、混合架构和完全并行结构。流水线架构中的每个PE均完成部分任务,每个任务对应1个PE,所有的PE加起来共同完成整个应用,混合结构类似于流水线架构,但其中的部分任务可以由多个PE共同完成。而在完全并行的软件架构,每个PE 均完成整个应用。采用流水线架构和优化流水线的好处在于对特定应用可以优化指令缓存 (instruction cache,Icache)的命中率,提高指令执行的效率。对于处理流程长,指令数量较多的应用来说,使用流水线方式可以提升Icache的命中率,从而提升性能指标。采用完全并行结构的好处在于数据缓存的效率更高,且方便实现、易扩展。我们实际测量了CCGW 的主流程的运行时间,约为6800个执行周期,一般1个周期对应着1 条指令,考虑到内部的循环函数,访存延迟等,主流程的指令数实际上小于6800。而OCTEON 5860处理器的每个PE的Icache的容量是32KB,每条MIPS指令占4字节空间,因此每个PE 可以容纳8192 条指令,大于主流程的指令数。因此我们采用了完全并行的软件架构。第4节给出的测试结果验证了CCGW 使用这种架构的合理性。
4 测试结果与分析
4.1 CCGW 性能测试
CCGW 实现在OCTEON 5860处理器平台上,每个PE主频800MHz,整体内存为4GB。我们利用QAM 设备和终端测试了CCGW 功能的完整性和正确性。为了测量CCGW的性能,我们根据实际部署的场景,利用OCTEON 5860处理器平台仿真了终端设备,仿真的终端设备可以模拟多个终端。在测试中,通过模拟900个终端,与CCGW 进行交互并通过QAM 通道接收数据。模拟终端设备主要的功能是与CCGW 进行交互,并与应用服务器进行交互,应用服务器回送大量数据包,经过CCGW 封装后从QAM 通道转发。
我们测试了PE数和对应的QAM 通道的吞吐量之间的关系。从模拟客户端到CCGW 的上行流量维持在850 Mbps,从应用服务器往CCGW 端的下行流量等于QAM 通道的吞吐量。图6给出了测试的结果。从图中可以看出,随着PE数的增长,吞吐率呈线性地增长,这反映了该实现良好的可扩展性。每增加一个PE,吞吐量约增加920 Mbps。在使用8 个PE 的情况下,QAM 通道的吞吐量达到7.3 Gbps,由于平台的物理网口所限,无法测量更多PE 对应的最大吞吐量。但从图中的线性性质可以近似推算出在更多PE情况下的吞吐量。在实际部署中,可以根据实际需要的吞吐量大小配置合适的PE数量,减少设备的能量消耗。
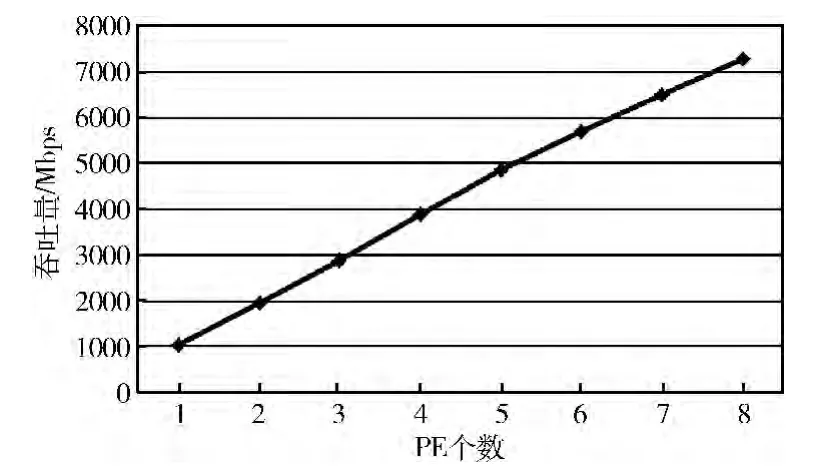
图6 CCGW QAM 通道吞吐量与核数的关系
4.2 带宽增强方案效果分析
上述测试结果表明CCGW 的实际性能足以满足设计要求。为了说明该增强方案的有效性,表1给出了EoC 带宽增强解决方案的带宽增强效果。一个光线路终端 (optical line terminal,OLT)接入带宽为1Gb/s,1:32的分光比,每个EoC局端覆盖200户,业务接入率假定为10%,那么对于未采用增强方案 (即表中的普通方案)的用户来说,其下行带宽为:1Gb·s-1/32/ (200×10%)=1.6Mb/s。采用带宽增强方案的用户,每个OLT 配置1个CCGW,每个IPQAM 设备提供1Gb/s带宽,CCGW 和IPQAM 的配比为1:4 (即1个CCGW 配套4个QAM,CCGW 的吞吐量达到4Gb/s),那么下行带宽将增加4倍,达到8 Mb/s;若配比为1:9 (CCGW 的吞吐量达到9Gb/s),那么下行带宽将增加9 倍,达到16 Mb/s。综上可见该方案可以显著地提升下行带宽效果。
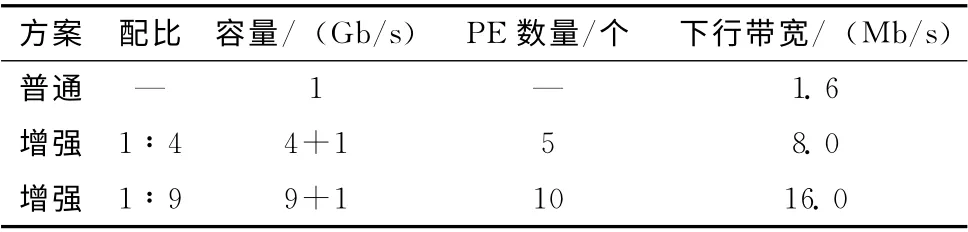
表1 EoC带宽增强方案的效果
5 结束语
为了进一步提升EPON+EoC 双向改造后的有线电视网的下行接入带宽,本文提出了一种EoC 带宽增强方案。详细分析了该方案中的关键设备CCGW 的作用和功能,由于该设备需要承载较大的网络流量,因此采用基于网络处理器的实现方案。结合OCTEON CN5860处理器的功能和特性,设计了CCGW 的主要模块,并最终在该网络处理器平台上实现了CCGW,并对该设备进行了测试,测试结果显示出该实现方案具有较高的吞吐量和良好的可扩展性,可以显著地提升用户的下行带宽。下一步将继续优化内部处理模块和资源分配算法。
[1]LING Mingwei,LI Yuandong.On the development status and tendency of cable access network techniques[J].China Cable Television,2011 (11):1253-1257 (in Chinese). [凌 明 伟,李远东.广电接入网技术发展现状与趋势探讨 [J].中国有线电视,2011 (11):1253-1257.]
[2]ZHENG Yanwei.Research on key technologies of collaborative multipath transfer in converged network [D].Beijing:Graduate University of Chinese Academy of Sciences,2012:11-27(in Chinese).[郑艳伟.融合网络多通道协同传输关键技术研究 [D].北京:中国科学院研究生院,2012:11-27.]
[3]XIE Liwei,LI Yuehui,REN Xunyi,et al.Two–way transformation scheme of EPON+EoC [J].Computer Technology and Development,2011,21 (7):238-241 (in Chinese).[解立伟,李跃辉,任勋益,等.EPON+EoC双向改造方案 [J].计算机技术与发展,2011,21 (7):238-241.]
[4]ZHANG Tingke.EPON+EoC-based research of construct the next generation of radio &TV broadcast integrated services access network[D].Guangzhou:South China University of Technology,2012:13-25(in Chinese).[张挺科.基于EPON+EoC构建下一代广播电视综合业务接入网的研究[D].广州:华南理工大学,2012:13-25.]
[5]YANG Qijun,LU Shiwen.Design and implementation of IPS based on multi-core [J].Computer Engineering and Design,2010,31 (21):4595-4598 (in Chinese). [杨启军,鲁士文.基于多核的入侵防御系统的设计与实现 [J].计算机工程与设计,2010,31 (21):4595-4598.]
[6]MENG Jinli,CHEN Xinming,CHEN Zhen,et al.Towards high-performance IPsec on Cavium OCTEON platform [G].LNCS 6802:Proceedings of the Second International Conference on Trusted Systems.Springer,2011:37-46.
[7]WANG Xianguan,NI Hong,ZHU Ming,et al.The analysis and improvement of IP data encapsulation method for hybrid fiber coaxial[J].Journal of Chinese Computer Systems,2013,34 (4):721-726 (in Chinese). [王献冠,倪宏,朱明,等.有线电视网络IP数据封装方法的分析与改进 [J].小型微型计算机系统,2013,34 (4):721-726.]
[8]LI Ting,ZHANG Wu,CHEN Xiao.An implementation of the streaming media transmit-unit based on multi-core network processor[J].Journal of Network New Media,2012,1 (2):28-33 (in Chinese).[李婷,张武,陈晓.一种基于多核网络处理器的流媒体转发单元的实现 [J].网络新媒体技术,2012,1 (2):28-33.]
[9]WANG Changqing, ZHANG Sujuan.JIANG Jinghong.Scheme of embedded data transmission based on Ethernet frame and its implementation [J].Computer Engineering and Design,2011,32 (6):1952-1956 (in Chinese). [王长清,张素娟,蒋景红.基于以太网帧的嵌入式数据传输方案及实现 [J].计算机工程与设计,2011,32 (6):1952-1956.]
猜你喜欢
汽车电器(2022年9期)2022-11-07 02:16:24
铁道通信信号(2020年4期)2020-09-21 09:15:24
中国外汇(2019年11期)2019-08-27 02:06:30
网络安全和信息化(2018年4期)2018-11-09 12:01:54
集装箱化(2016年11期)2017-03-29 16:15:48
集装箱化(2016年12期)2017-03-20 08:32:27
铁道通信信号(2016年8期)2016-06-01 12:10:21
中国新通信(2014年11期)2014-09-11 19:27:52
集装箱化(2014年2期)2014-03-15 19:00:33
深圳信息职业技术学院学报(2013年3期)2013-08-22 11:42:30
