
基于用户反馈的关键词提取
2015-12-20 06:58李石君
计算机工程与设计 2015年8期
刘 典,李石君
(武汉大学 计算机学院,湖北 武汉430072)
0 引 言
目前关键词的主要应用对象为人类用户和机器用户。在面向人类用户的应用中,需要提取的关键词能简要的概括文本的内容,具有较高的可读性;在面向机器的应用中,关键词具有较高的代表性。例如,文本分类中,根据一定的分类体系和分类标准,对文本进行分类,判定文本关键词是其中一个重要依据。
1 相关研究
关键词提取的研究与不同学科和技术相结合形成了一系列行之有效的方法,可划分为3类:
(1)基于统计特征的关键词自动提取,主要包括词频,共出现频率,TF-IDF 等统计信息。Salton 提出了TF-IDF算法[1]。词频 (TF)表示某个词语在文档中出现的频率,逆文档频率 (IDF)度量的是词语的普遍重要性。TF-IDF用词频与逆文档频率的乘积来表示。
(2)基于机器学习的关键词提取,包括遗传算法,支持向量机[1],最大熵模型,条件随机等。例如,Turney提出的GenEx算法利用遗传算法训练相关参数,用参数给每个候选词打分,提取出关键词。Kea算法[2]则是一个基于贝叶斯模型的非常有效的算法,从已标注关键词的文档中学习,根据学习的模型从无标注文档中提取关键词。Kea算法主要用到TFIDF和词首次出现位置两个特征。
(3)基于语义的关键词提取,包括词性,语法,句法,语义依存等。利用基于语义的方法消除多义词有歧义的词义,提高提取的关键词质量。文献 [3]利用词语的语义相似度合并候选集中的同义词,提高关键词提取的效率。
在上述关键词提取算法中,基于统计特征的算法方便理解,计算简单,但是并不是所有关键性的词语都满足统计特征,一些出现频率不高的有重要意义的词语就会被忽略。有部分基于机器学习的算法充分利用了各种先验知识,但由于过度拟合,使得不具有普适性。基于语义的方法[4],用词语的语义来衡量词语重要性,这能大大提高提取的关键词的可读性,但在博大精深的汉语中,可以使用多样化的句式和词语来表达同样的内容,甚至所用词语不是近义词,这使得同主题的词语大部分未能关联,导致词义在关键词提取中不能发挥应有的作用。
本文提出一种基于用户反馈的关键词打分策略。首先根据用户反馈的关键词,提取语义相似或相关的候选词,然后根据这些候选词与关键词的词语扩展度给候选词的用户反馈值打分,利用候选词的统计特征信息和用户反馈值的线性组合作为该词的权重,生成文档的关键词。
2 预备知识
2.1 词语相似度和词语相关度
词语相似度[5]描绘的是文本中两个词语之间的可替换程度。如果两个词语可以在不改变文本语义的情况下互相替换,那说明它们之间的词语相似度很高,比如, “开心-高兴”。一般来说,词语相似度的取值范围为 [0,1],两个在任何文本中都不能替换的词语之间的词语相似度为0,词语与它本身的词语相似度为1。
词语相关度[6]描绘的是文本中两个词语相互关联的程度。如果两个词语总是同时出现在同一个上下文中,说明这两个词语的相关度很高。两个词语可能不存在相似关系,但可能通过某种关联具有相关关系,如 “跑步一健身”。因此,我们用语义扩展度来描述两个词语之间的关系,它由词语相似度和词语相关度的线性组合而成。通过语义扩展度,我们可以将具有一定程度的语义相似和相关的词语组成在一起共同来表达文章的某一主题内容。
2.2 同义词词林
《同义词词林》记录了一个词语的同义词和它一系列的同类词[7]。哈工大在原版的基础上,进行了扩展和修改,最终形成现阶段最常用的同义词词林扩展板。
同义词词林的词典分类层级体系如图1所示。越是底层的级别,对词义的刻画越细化。每个词语在词典中对应一个编码,编码由该词语在每一层的代码和一个标记位组成。每一层的代码共同记录了词语从根节点到叶子节点的路径。最后一个标记位有3个值: “==”, “#”, “@”,分别表示词语同义,词语相关,词语独立。
2.3 用户反馈
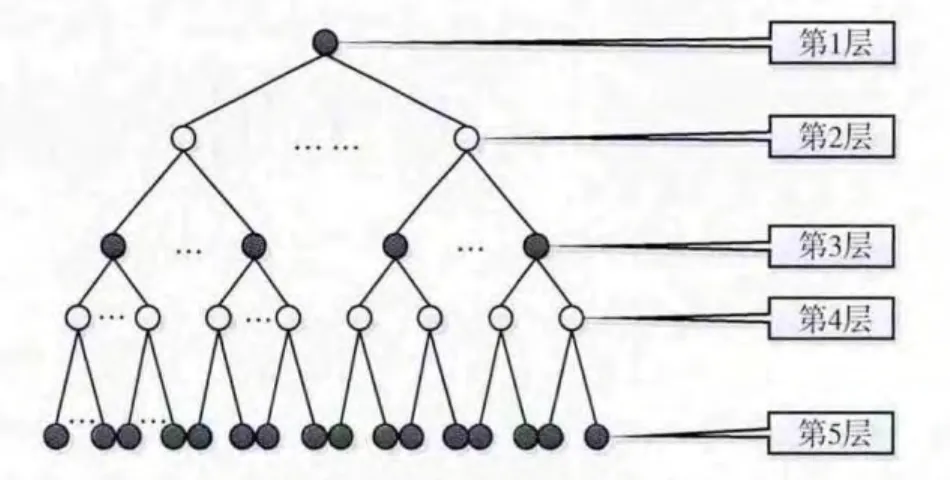
图1 同义词词林的结构
用户反馈包括显式反馈和隐式反馈。显式反馈是指通过用户主动评价某一事物或结果来反映用户的认同度。用户对主题特征词的评价有两个选项,一种是同意,一种是反对。同意越多表示该关键词代表了用户对它关注度越高,类似的,反对越多表示用户不需要这方面的信息。隐式反馈是指在用户没有主动评价的情况下,通过对用户的行为进行分析和估计,推测出用户的认同度。本文涉及到的用户反馈都指显式反馈。
定义1 用户反馈库:记录主题下的关键词和用户对生成关键词的评价。每次生成关键词时,把库中没有记录的关键词添加到库中。初始化时,库中仅包含主题特征项。
定义2 用户反馈值:用户反馈库的反馈词的用户反馈值是量化用户对该反馈词的关注度以及准确度的评价。
用户反馈库的结构可表示为
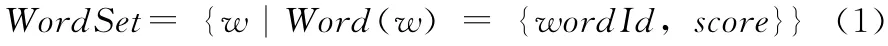
式中:WordSet——用户反馈库中所有反馈词的集合,w——反馈词,Word(w)表示反馈词的详细结构,word-Id——反馈词的编号,是对反馈词的唯一标识,score——反馈词的用户反馈值,初试化时值为1。
3 关键词提取流程
基于用户反馈的关键词提取的主要思想是据用户反馈结果优化关键词提取。使用用户反馈库量化用户对关键词的反馈。在特征选择中,将用户反馈库记录的用户反馈值作为计算词语权重的影响因子;用户对生成的关键词做出评价后,据词语的语义扩展度更新用户反馈库;关键词生成产生的新词会扩充到用户反馈库。图2为关键词提取的系统流程。
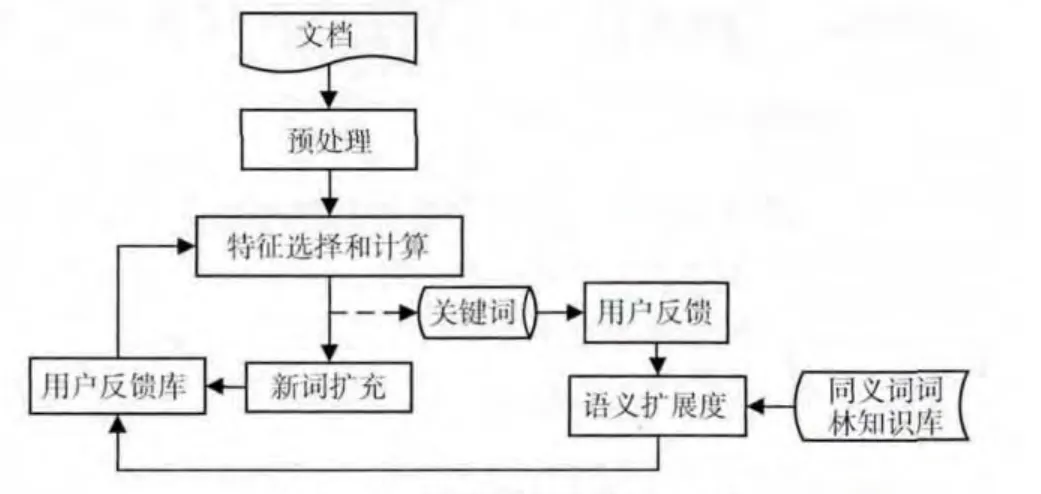
图2 关键词提取的系统流程
3.1 预处理
预处理中的中文分词用ICTCLAS[8]来完成。去掉一些停用词,得到粗略的候选词集。利用文献 [9]提出的根据计算词语相似度来合并同义词,合并候选词集中的同义词,形成最终的候选词集。
3.2 词语扩展度
词语相似度的计算是自然语言处理相关领域的一个基础性工作,已经形成了很多卓有成效的方法。计算方法主要有:①以大规模的语料库为基础的语义相似度计算[10];②以词素为单位的相似度计算;③以余弦相似度为代表字面相似度计算。本文选用的第一种方法,根据文献 [11]提出的基于同义词词林的方法来计算。它的主要思想为先在同义词词林中获取要计算相似度的两个词汇对应的编码。然后,判断两个词汇的编码在5 层结构中的哪一层分支,根据分支层的两个义项的语义距离,计算出相似度。一般来说,距离越近,相似度越高。语义相似度计算公式如下
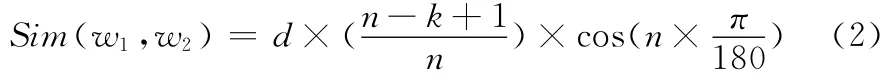
式中:Sim ——词语相似度 (0<Sim <1);d——系数,由两个词汇所对应的编码在哪一层分支所决定;n——分支层节点的总个数;k——分支间的距离。
采用文献 [8]提出的方法计算词语相关性
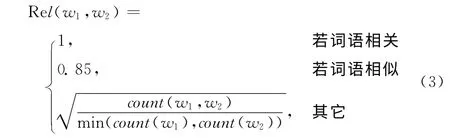
词语扩展度的计算方法,线性结合词语相似度的计算和词语相关性的计算,如下
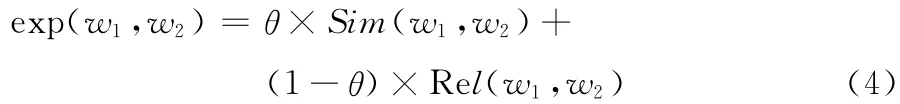
式中:θ——调节因子,本文实验中θ取0.5。
3.3 用户反馈分析
用户反馈库有很多语义相近或相关的词语,通过用户反馈对关键词的用户反馈值进行打分时,根据词语扩展度,对与该关键词语义相似的关键词使用不同程度的打分。
用户反馈分析的基本思想:根据用户的反馈信息,利用式 (2)计算词语扩展度。引入阀值μ,筛选用户反馈库中与反馈词语扩展度较高的词语集合ExpSet,对这些词语的用户反馈值做相应的修正。根据用户反馈的性质,用户反馈值的修正公式如下
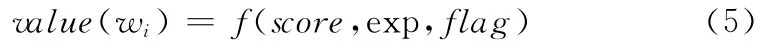
式 中:w——用 户 反 馈 词;score——w 的 用 户 反 馈 值;exp——w 与wi的词语扩展度;wi∈ExpSet(w);flag 为1表示正例反馈,0表示反例反馈。
根据数形结合的思想,描绘函数图像大致的趋势模拟用户反馈函数。假设X 轴表示反馈前的值,Y 轴表示反馈后的值。由前文可知,用户反馈值的数值范围在0到2之间,X 轴和Y 轴的取值范围都应为 [0,2]。正例反馈的函数图像应在y=x上方。反例反馈的函数图像应在y=x下方。用渐进式曲线来模拟,函数图像的变化趋势如图3所示。
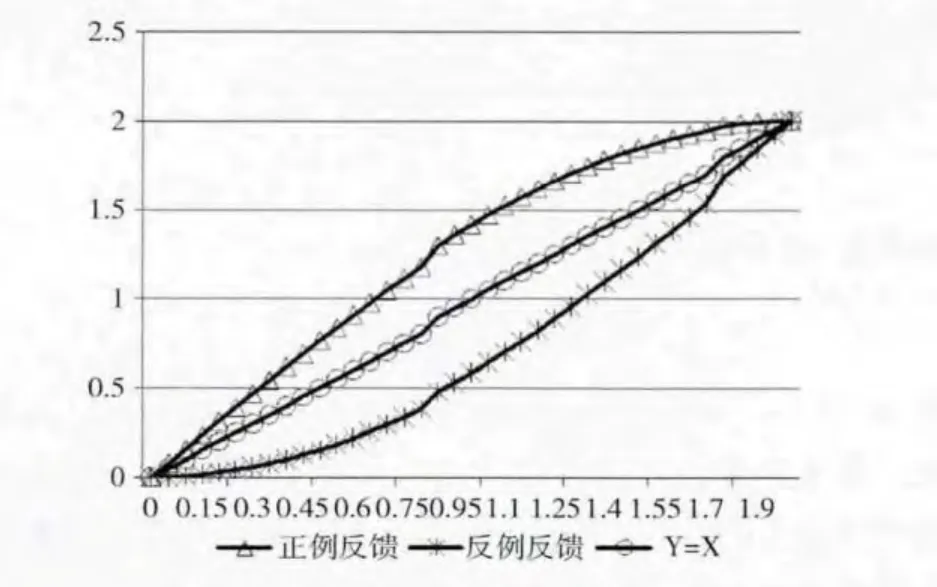
图3 用户反馈函数的图像趋势
由图像得到的启发,设计如下函数计算用户反馈值
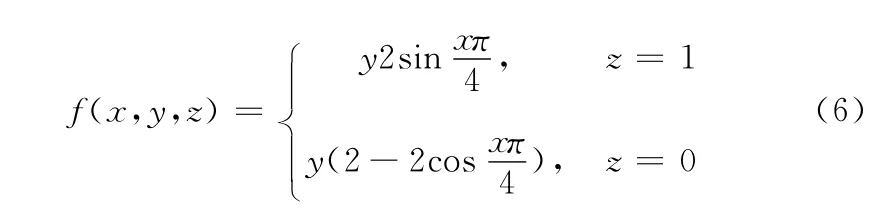
综上所述,把式 (5)代入式 (6)可得,用户反馈的修正公式为
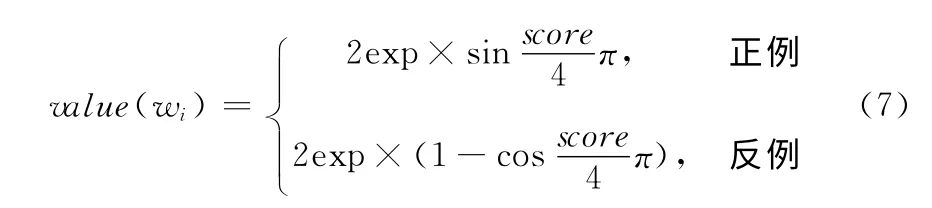
3.4 特征选择和计算
特征的选择决定候选词的计算的权值,因此,有效的特征选择可以提高关键词提取的质量。本文选取词频TFIDF,词语出现的位置,词语的词性以及词语的用户反馈值,特征描述信息见表1。
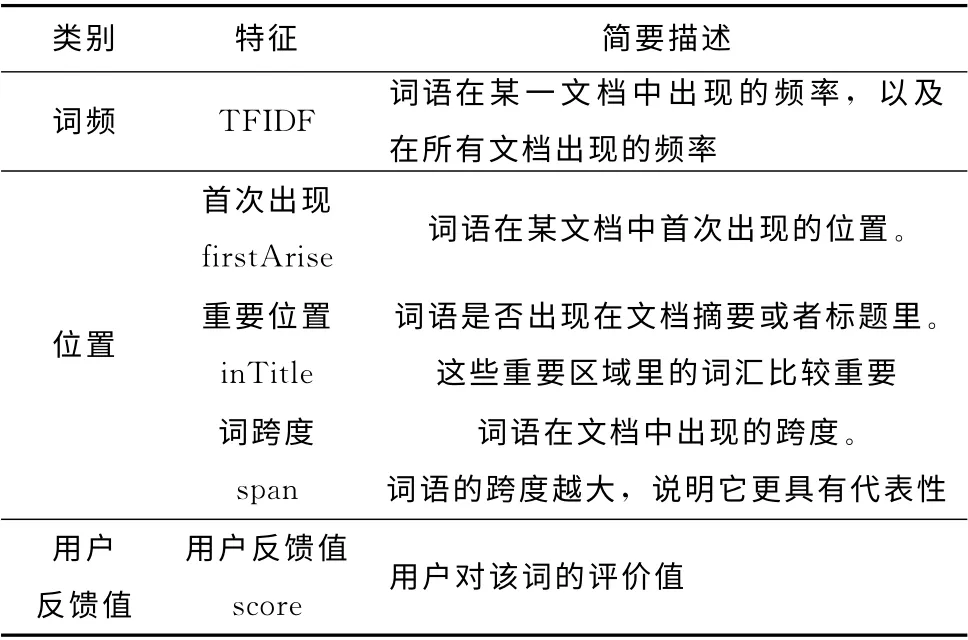
表1 统计信息特征
词语TF-IDF计算公式为
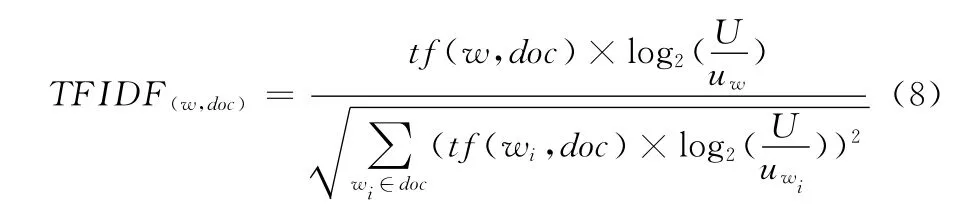
式中:TFIDF(w,doc)——词w的TFIDF值;tf(w,doc)——词语w的词频TF;uw——含有w的文档数;U——总文档数。
首次出现位置firstArise的计算方法为
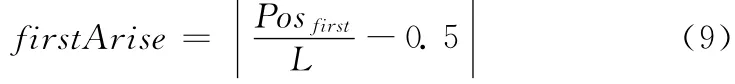
词跨度span的计算方法为
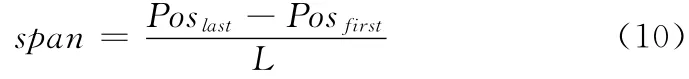
式中:L——文档包含的词汇的总数;从文档开始,给每个词汇标上序号,从1到L,Posfirst——词语w 首次出现在文档中的位置的序号,Poslast——词语w 最后一次出现在文档中的位置的序号。
词语重要位置inTitle的计算方法

在用户反馈库中查询词语w 的用户反馈值时,如果使用词语的完全匹配,会出现词语重复,影响效率。所以,使用基于词语相似度的查询。根据词语间的相似度,在用户反馈库里筛选出与词汇w 的相似度大于阀值t 的词汇集(一般取t=0.9),取词汇集中用户反馈值与初始值的差距最大的值。查询词语w 的用户反馈值的算法如算法1所示。

算法1:查询词语的用户反馈值输入:词语w,用户反馈库WordSet= {m1,m2,…,mn}输出:词语w 的用户反馈值S SimSet←S←1;for i=1to n do //compute the word similarity between w and mi sim←Sim (w,mi);if sim >=t then add miat the end of SimSet endif endfor if SimSet is not NULL then S ←compute max (abs(score-1))in SimSet endif return S;
综合考虑各项特征因素,提出词语w 的权重计算方法
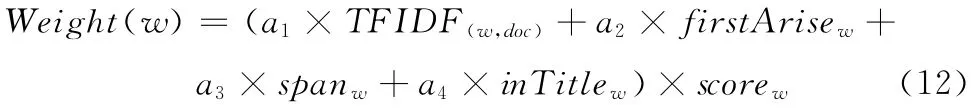
式中:a1+a2+a3+a4=1。
综上所述,按照式 (8)~式 (11)分别计算候选词的各个统计信息特征的值,根据式 (12)计算候选词的权重,输出前n个权重最高的关键词。
4 实验结果与分析
4.1 实验评估与分析
我们将关键词提取算法提取的关键词与文档标注的关键词做匹配,用这样的方法来评估算法。如果我们用精准匹配来匹配关键词,不考虑词语的语义信息,匹配的结果不准确。比如,文档标注的关键词是 “通货紧缩”,算法提取的关键词是 “通缩”,该方法会认为两者是不同的,其实,“通缩”是 “通货紧缩”的缩写。所以,在匹配关键词时,用词语相似度是否大于阀值来衡量是否相同。
关键词提取比较常用的评价指标包括:查全率R,查准率P和综合指标F-measure。具体计算公式分别为
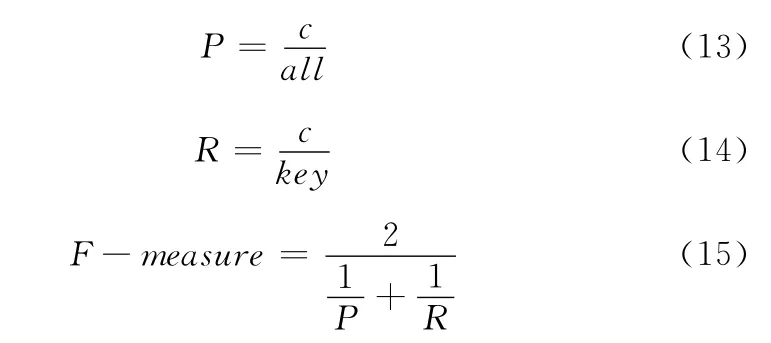
式中:c为关键词正确匹配的个数;all为提取的关键词的总数;key 为文档标注的关键词个数。
4.2 实验结果与分析
本实验选定财经领域为示例。我们从网上下载了100篇已标注关键词的财经类文章。为了验证基于用户反馈的关键词提取方法的有效性,进行了这两类实验:
(1)本文算法的对比实验。将进行无任何用户反馈和有用户反馈的对比,以验证用户反馈的有效性。在实验的100篇文章了随机选择40篇文章进行用户反馈,剩余60篇文章作为测试集。抽取的关键词个数分别取5,7,9,11进行4组实验,结果见表2。
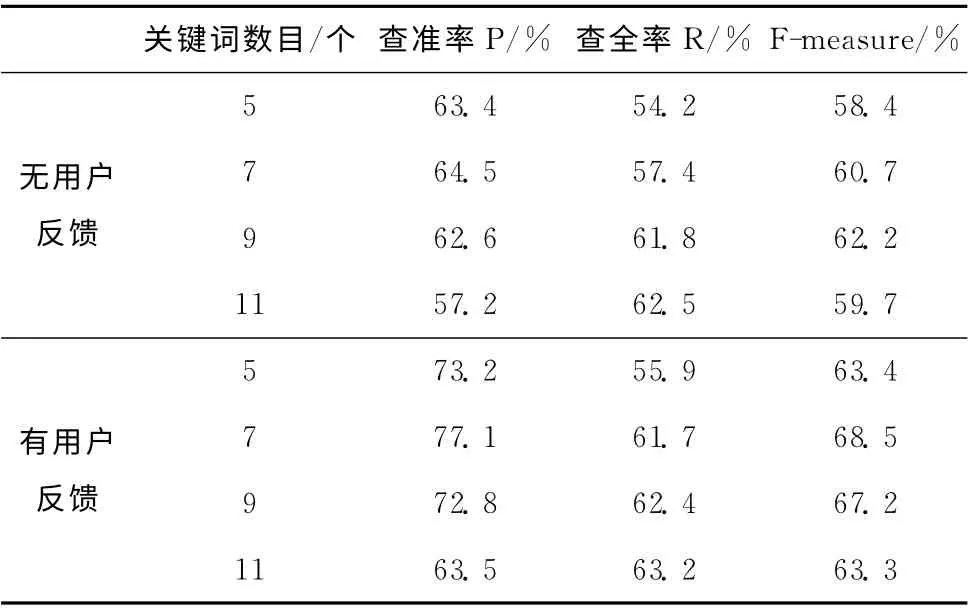
表2 是否进行用户反馈的对比实验结果
实验结果表明,进行用户反馈后的方法提取效果比没有用户反馈的方法提取效果更好。随着提取关键词个数的不断增加,特别是当个数大于7 时,查准率有明显下降,查全率缓慢上升甚至有所下降。这是因为文档标注的关键词个数的平均值为6.2,提取的关键词个数超出关键词平均值时,生成了部分不准确的关键词,影响了评估结果。
(2)本文算法与Kea算法的对比实验,以验证本文提出的方法有改进的效果。将下载的文章按7∶3的比例分为训练集和测试集,抽取的关键词个数分别取5,7,9,11进行4组实验。选定F值作对比数据,结果如图4所示。
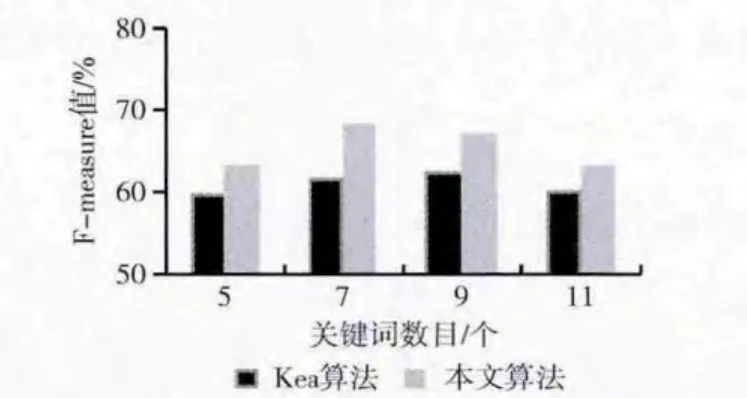
图4 本文方法与Kea算法的对比实验
由图4中实验数据分析可得,F 值的变化趋势和实验一是相同的,在关键词个数为7 时,取极大值。总体上,相对于Kea算法,基于用户反馈的关键词提取的准确度更高,证明了本文算法是有改进的效果。
根据以上两个实验,基于用户反馈的关键词提取确实有一定的改进效果。使用 《同义词语林》计算词语的相似度,合并候选词中的同义词,有效的减少了关键词中同义词的出现。基于用户反馈的方法,有助于提取到出现频率很小但有重要意义的关键词。然而,从两个实验的实验数据可知,该方法还有提升空间。一是同义词词林在面向专业领域术语时,规模还有待扩大。二是本文仅使用了部分统计信息特征,忽略了候选词的词性特征。
5 结束语
根据Kea算法提出的文本特征选择,提出一种基于用户反馈的关键词提取方法。利用 《同义词词林》计算词语相似度和词语相关性,对关键词候选集进行同义词合并。提出用户反馈库和用户反馈值量化用户对关键词的反馈,用户反馈值作为候选词权重计算的一个影响因子。把词语所在位置,TFIDF等统计信息特征和用户反馈值结合起来,计算词语的权重。考虑用户反馈后,生成的关键词会更符合用户对某一特定领域的关注点。实验验证了较好的抽取效果。实验发现该方法在提取关键词上有改进空间。将对用户反馈函数做进一步优化,挖掘具有代表性的关键词,提高算法稳定性。
[1]LIANG Weiming.Chinese keyphrases extraction technique[D].Shanghai:Shanghai Jiao Tong University,2010 (in Chinese).[梁伟明.中文关键词提取技术 [D].上海:上海交通大学,2010.]
[2]Frank E,Paynter G W.Domain-specific keyphrase extraction[C]//Proceedings of 16th International Joint Conferenceon Artificial Intelligence,1999:668-673.
[3]JIANG Changjin,PENG Hong,CHEN Jianchao,et al.Keywords extraction algorithm based on combined word and sunset[J].Application Research of Computers,2010,27 (8):2853-2856 (in Chinese).[蒋昌金,彭宏,陈建超,等.基于组合词和同义词集的关键词提取算法 [J].计算机应用研究,2010,27 (8):2853-2856.]
[4]WANG Lixia,HUAI Xiaoyong.Semantic-based keyword extraction algorithm for Chinese text [J].Computer Engineering,2012,38 (1):1-4 (in Chinese).[王立霞,淮晓永.基于语义的中文文本关键词提取算法 [J].计算机工程,2012,38 (1):1-4.]
[5]WANG Teng,ZHU Qing,WANG Shan,et al.Statements verification based on semantic similarity [J].Chinese Journal of Computers 2013,36 (8):1668-1681 (in Chinese).[王腾,朱青,王珊,等.基于语义相似度的Web信息可信分析 [J].计算机学报,2013,36 (8):1668-1681.]
[6]WANG Yi,WANG Xiaolin.Algorithm forwords’semantic relevancy based on modified algorithm for sememes’relevanc[J].Journal of the China Society for Scientific and Technical Information,2012,31 (12):1271-1275 (in Chinese). [王义,王小林.基于改进的义原关联度算法的词语相关度计算[J].情报学报,2012,31 (12):1271-1275.]
[7]LIU Dandan,PENG Cheng,QIAN Longhua,et al.The effect of TongYiCi CiLin in Chinese entity relation extraction[J].Journal of Chinese Information Processing,2014,28(20):91-99 (in Chinese).[刘丹丹,彭成,钱龙华,等.《同义词词林》在中文实体关系抽取中的作用 [J].中文信息学报,2014,28 (20):91-99.]
[8]ZHANG Huapin,LIU Qun.Institute of computing technology,Chinese lexical analysis system [S].2009 (in Chinese).
[张华平,刘群.中国科学院计算技术研究所汉语词法分析系统ICTCLAS2009版 [S].2009.]
[9]LIU Duanyang,WANG Liangfang.Extraction algorithm based on semantic expansion intergrated with lexical chain [J].Computer Science,2013,40 (12):264-269 (in Chinese). [刘端阳,王良芳.结合语义扩展度和词汇链的关键词提取算法[J].计算机科学,2013,40 (12):264-269.]
[10]LIU Qun,LI Sujian.Word similarity computing based on HowNet[J].Computational Linguistics &Chinese Information Processing,2007,31 (7):59-76 (in Chinese).[刘群,李素建.基于 《知网》的词汇语义相似度计算 [J].计算机语言学及中文信息处理,2007,31 (7):59-76.]
[11]TIAN Jiule,ZHAO Wei.Words similarity algorithm based on TongyiciCilinin semantic web adaptive learning system [J].Journal of Jilin University,2010,28 (6):602-608 (in Chinese).[田久乐,赵蔚.基于同义词词林的词语相似度计算方法 [J].吉林大学学报,2010,28 (6):602-608.]
猜你喜欢
国际医药卫生导报(2022年18期)2022-09-29
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
小天使·一年级语数英综合(2020年4期)2020-12-16
开放教育研究(2020年2期)2020-03-31
信息安全研究(2016年4期)2016-12-01
现代语文(2016年21期)2016-05-25
传奇故事(破茧成蝶)(2015年7期)2015-02-28
大连民族大学学报(2015年2期)2015-02-27
