
基于特征字符识别的文本图像方向判定
2015-12-20 06:58吴建胜祖旭良薛涵今
计算机工程与设计 2015年8期
吴建胜,祖旭良+,薛涵今
(1.辽宁科技大学 软件学院,辽宁 鞍山114051;2.国网鞍山供电公司,辽宁 鞍山114000)
0 引 言
由于扫描仪馈纸幅面或光学字符识别 (optical character recognition,OCR)软件自身对文本图像处理的缺陷等原因,经常会要求扫描的纸质文件或票据按照一定方向进行放置扫描,否则将无法得到识别结果。实际上在OCR 软件进行处理之前,需要将文本图像按照约定的方向进行旋转,或者按照文本图像的长宽比,进行简单的判断旋转,保证文本图像处于人们正常视觉方向之后才能进行文字识别工作。本文提出了一种基于文本图像中特征字符识别的图像正常视觉方向判定的方法,增强了文本图像方向的鲁棒性,实现了无方向约束扫描,有利于提高使用友好度。
1 OCR 技术简介
OCR,光学字符识别技术是指通过光学输入设备如扫描仪、写字板、摄影机等外部设备,将各种纸质材料如报表、发票、文件、报纸、杂志等印刷品的文字转换为二维点阵信息,然后再利用文字识别技术将图像中的文字信息转换为计算机可编辑的字符形式。研究内容涉及:图像处理、模式识别和人工智能等多学科。
1.1 OCR 处理流程
字符识别的过程一般由以下模块组成,如图1所示。
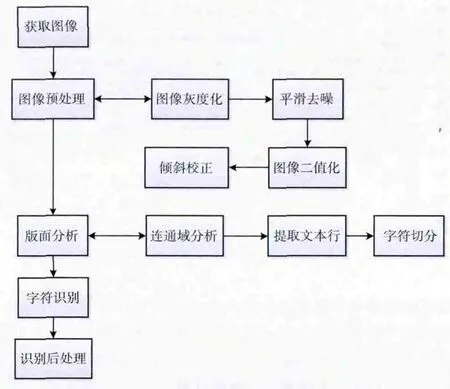
图1 字符识别流程
本文论述的重点是特征字符的提取,在版面分析阶段,根据要解决的实际问题情况,加入部分规则约束以及约束指标,分析得到文本图像中最有可能是文字字符的图像区域。OCR 处理的图像中一般包括表格和文字信息,扫描输入过程中或多或少肯定会有某种程度的倾斜,倾斜矫正的核心算法在于如何检测出图像的倾斜角,Hough变换[1,2]是最常用的倾斜角检测的方法。对于文本图像的倾斜矫正[3,4],虽然涉及到具体的系统处理方法不一样,但是整体的原理基本相同。这些文字图像的特征就是有统一的方向性,还有各个文字的宽度和高度都差不多,在二值图像中很容易通过连通域将文字图像部分提取出来,然后提取特征点,进行直线拟合,确定其方向性,最后进行方向矫正。单纯的倾斜矫正不能得到正常视觉方向的文本图像,因为倒置180°情况下,不存在倾斜角。旋转90°和270°情况下,得到的倾角是一样的,仍然无法判断如何旋转才能得到正常视觉方向的图像,所以提出了本文的方法。
1.2 OCR 技术原理
所谓的字符识别,是先让计算机对字符样本的特征进行分析、记忆和学习,使其成为系统自身的知识,然后运用这些先验知识去分析和比较新输入的字符图像,评估相似度,获得识别结果[5,6]。特征体系的选取各不相同,根据图像质量以及时间效率等因素而定。根据不同特征体系的选取,识别方法主要分为以下两类:基于统计特征的字符识别技术和基于字符结构的识别技术。
基于字符统计特征的识别技术是目前比较普遍使用的方法,程序实现起来比较简单。这种方法选取同一类字符中有代表性的、分类性能好的字符特征作为特征向量,常用的统计特征有字符经过频域变换形成的特征、二维平面的位置特征、垂直和水平投影的直方图特征和矩特征[7]等等。从大量已知结果的样本中提取特征进行学习和分类器训练,对未知结果的图片采取同样的分析处理方法,得到相同的统计特征,采用向量间的距离指标如欧氏距离、马氏距离等评估相似度,获得识别结果。
基于结构特征的字符识别技术通过识别字符图像内部的轮廓特征、拐点特征和突变点特征等基元,运用模板匹配的方法来实现字符识别[8]。
2 特征字符提取及方向判定
本文方法的特征字符提取过程包含在版面分析模块中,图像经过预处理后,进行连通域分析和文本行 (列)区域确定,然后通过一系列规则约束,最终确定特征字符。
2.1 连通域分析
目前已有的连通域分析算法分为两类:一种是局部邻域算法,确定一个起点,向周围扩展,从局部到整体;另一种是从整体到局部的分析算法,先确定不同的连通成分,再对每个成分填充[9]。本文对预处理后的二值图像,使用游程编码算法,按照从上到下,从左至右的顺序对图像进行扫描[10-12],将结果保存到所示的结构体中。

2.2 连通域属性判定
对连通域属性进行判定之前,通过式 (1)对其中所有最小宽度或高度和所有的最大宽度或高度进行直方图统计

式中:m1、m2——连通域宽和高中的最小长度和最大长度,H1、H2分别是其统计直方图。
通过式 (2)~式 (4)计算直方图的峰值,估算有效连通域的长度范围,通过此范围过滤部分噪音、分割线等无意义连通域
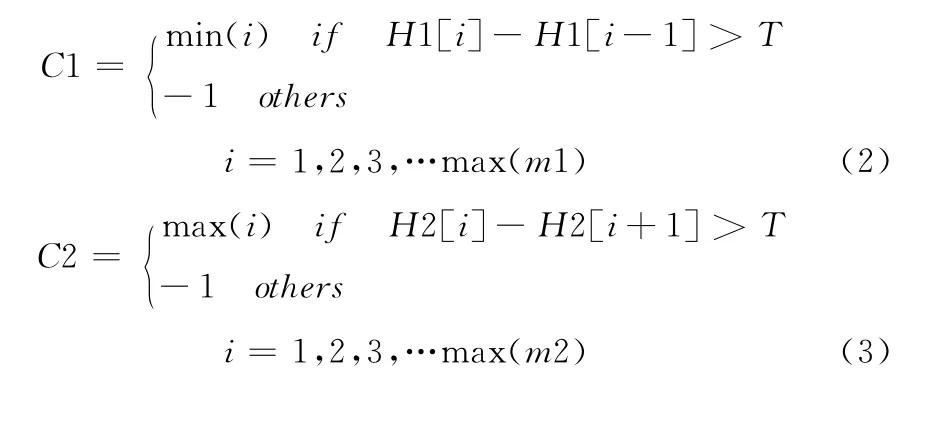
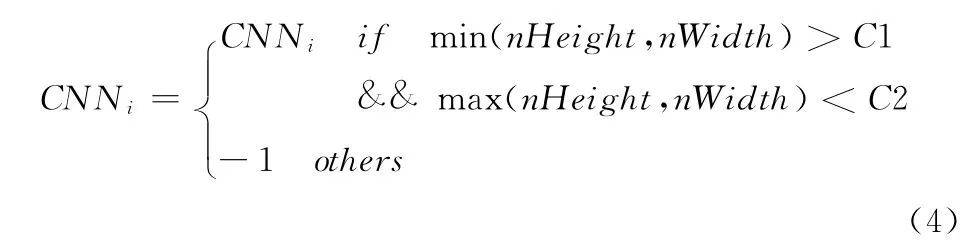
式中:C1和C2分别表示字符的长度和宽度中最小值和最大值。
使用式 (5)、式 (6)对剩余的连通域进行属性估算,通过宽高比、像素点个数估算哪些连通域可能为字符[13,14]。根据字形和印刷特点,大多数字符连通域的宽度和高度比较接近,可以依据此特性,为连通域属性赋值

式中:A 是对属性估计的置信度计算,T 是判断连通域是否为文本区的置信度阈值,经过大量实验确定,该值取0.85时,完全可以满足本算法的要求。
对连通域属性进行估算之后,认为nAttribute的值为1的连通域才有可能是文本行 (列)的连通域。进行属性估算可以为后续处理过滤没有必要的连通域,提高时间效率,还可以为后续处理打基础,提高正确率。
2.3 文本行 (列)合并
对nAttribute的值为1的连通域根据近邻连接强度I进行横向文本行合并与纵向文本列合并
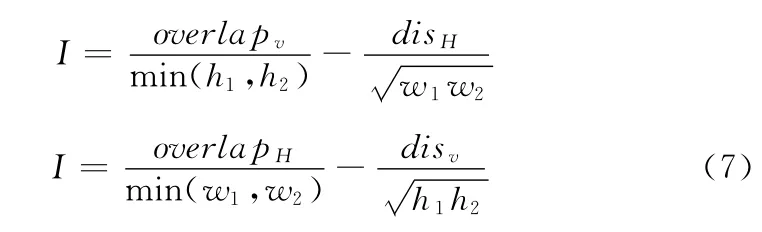
式中:overlapv——两个连通域竖直重合的高度,overlapH——水平重合的宽度,h1,h2——两个连通域各自竖直高度,disH——他们间的水平距离,disv——他们间的垂直距离,w1,w2——各自的水平宽度。将结果保存到如下的文本行 (列)结构体中:

文本行 (列)合并的结果如图2所示。
2.4 筛选特征文本行 (列)
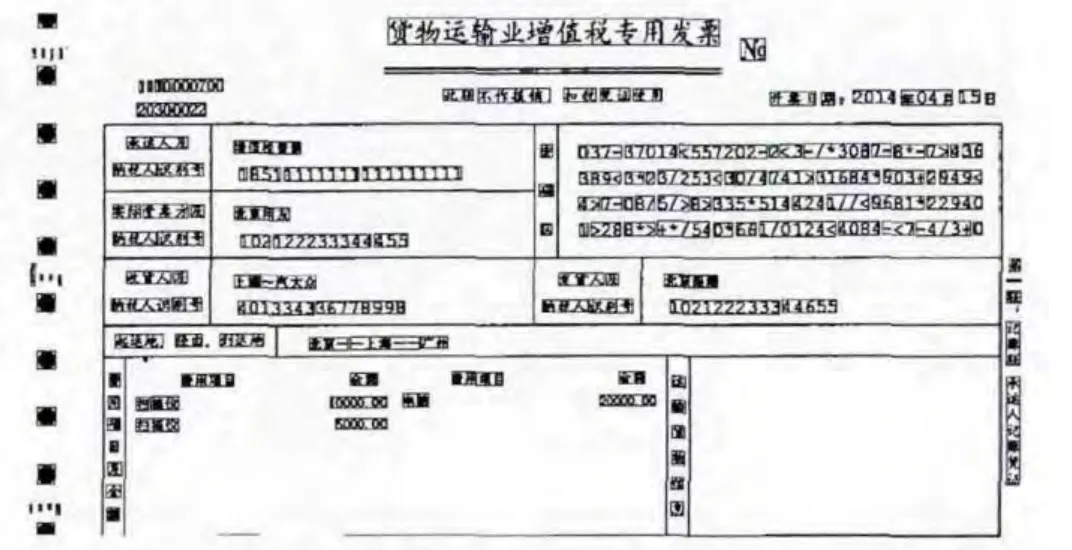
图2 文本行 (列)合并结果
特征文本行 (列)是指特征字符所在的行或者列,最能代表图像正常视觉方向的文字定义为特征字符,例如复杂版面中的标题字符和文本段中具有上下文的字符。所以特征文本行 (列)可能具有以下特征中的一种或几种:
(1)包含一定数量以上的连通域;
(2)文本行高度大于平均高度,文本列宽度大于平均宽度;
(3)上下存在其它文本行或者左右存在其它文本列;将具有以上特征的文本行 (列)按照式 (8)加权计算特征权重
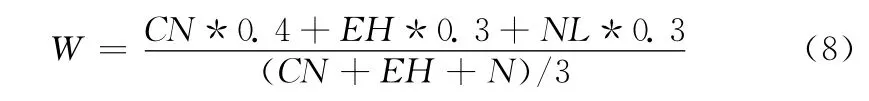
式中:CN——文本行中具有的连通域数量,EH——文本行高出平均高度的长度,NL——文本行近邻的文本行数量。
将权重从大到小排序筛选,取得到权重较大的前4个文本行 (列)作为算法的效果展示,如图3、图4所示。
图3 书籍页特征文本行筛选结果
从图3和图4筛选的结果来看,完全符合特征文本的属性。正常情况下,书籍的题目和票据的类型名称会比一般的字体大,属于特征文本行;书籍段落中,具有上下文,而且比较紧凑的大段文字属于特征文本行;票据中,税控码部分,具有上下文,而且大量税控码排列整齐紧凑,属于特征文本行。
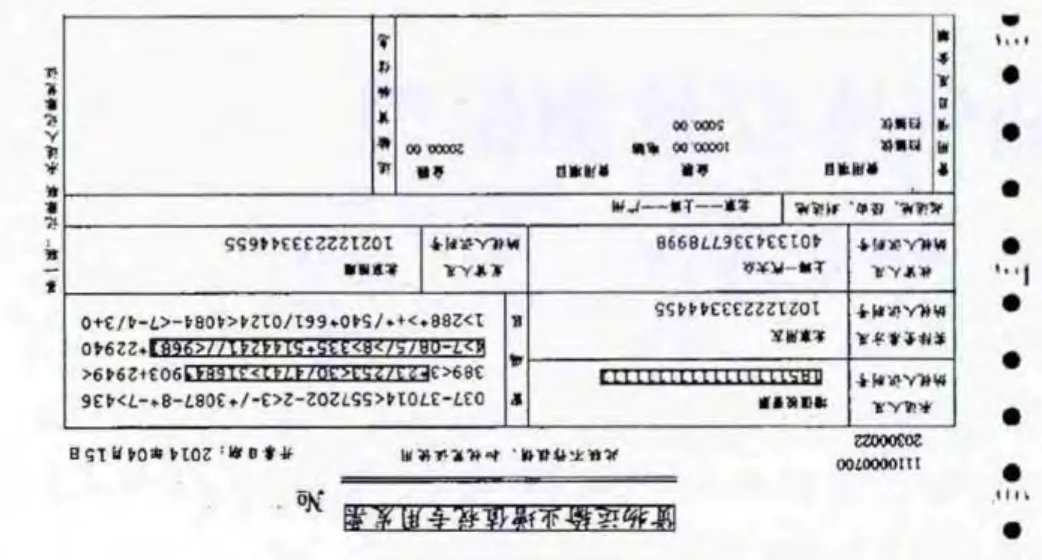
图4 票据特征文本行筛选结果
2.5 方向判定
采用统计特征识别技术将特征字符的特征向量与模板库中特征向量的识别距离进行计算统计,依次统计相同特征字符4个方向的特征向量识别距离,根据最小距离判定图像方向
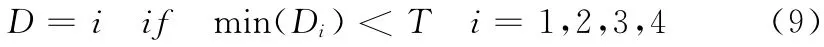
式中:i的值代表4个方向,D 为该方向的识别距离,T 为判定阈值,本文通过大量实验,取值为150。
按照本文叙述方法,使用北京文通科技有限公司随机采集的16975张包括书籍、报纸、文件、税务票据等样本对理论的可行性进行了验证,在已知正确结果情况下,对图像分别做出不旋转、顺时针旋转90°、180°和270°操作,实验结果见表1。
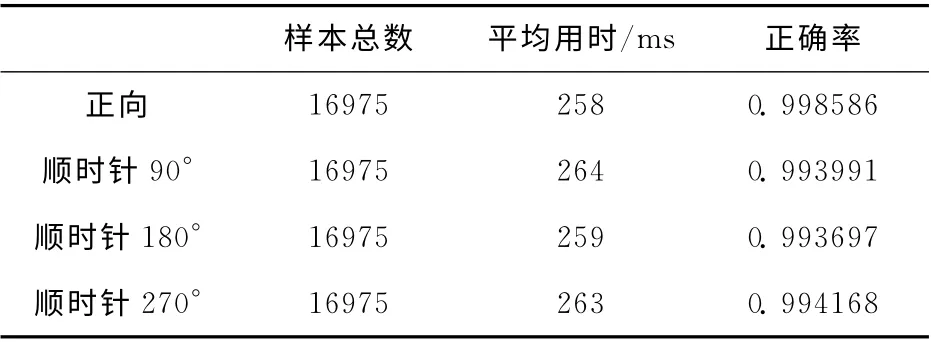
表1 实验结果统计
实验结果表明,平均用时和正确率完全达到预期目的。对整张图像进行连通域分析,消耗了本文算法的主要时间,该方法在其它以OCR 技术为基础的应用中,平均用时仍会有大幅度提升,因为该方法最初设计的目的是依据OCR 技术,所以所用数据与OCR 的图像预处理部分有重叠,在以上显示的时间基础上还可以进行提升,对于实践应用有重大意义。通过分析方向判断错误的图像,得到导致错误的主要原因是图像有歪斜,预处理工作没有做好,还有一点原因是图像中只包括外文字符,没有中文,或者中文字符过小,不具有代表性,没有挑选出来,最后导致识别判断失效。
3 结束语
文中提出一种具有特征字符的文本图像方向判定算法,增强了基于OCR 技术的应用软件对于扫描方向的鲁棒性。通过分析版面中能够代表图像方向的字符具有的通用特征,在算法中添加约束条件,提取特征字符,根据最小特征识别距离,达到了判断整张图像方向的目的。最后实验数据显示,该方法的平均用时仅为260ms,正确率高达99%以上,完全可以应用于实践。但算法仍有局限性,对于不支持识别的文字不能达到判断方向的目的,这是今后需要改进的方向。
[1]DUAN Rujiao,ZHAO Wei,HUANG Songling,et al.Fast line detection algorithm based on improved Hough transformation [J].Chinese Journal of Science Instrument,2010,31(12):2774-2780 (in Chinese). [段汝娇,赵伟,黄松岭,等.一种基于改进Hough变换的直线快速检测算法 [J].仪器仪表学报,2010,31 (12):2774-2780.]
[2]LIU Nian,SU Hang,GUO Chunhong,et al.Improvement of eye location method based on circle examination of Hough transformation [J].Computer Engineering and Design,2011,32(4):1359-1362 (in Chinese). [刘 念,苏杭,郭 纯 宏,等.基于Hough变换圆检测的人眼定位方法改进 [J].计算机工程与设计,2011,32 (4):1359-1362.]
[3]PAN Meisen.Research on medical image tilt correction method and its application [D].Changsha:School of Geosciences and Info-Physics,2011:23-25 (in Chinese).[潘梅森.医学图像倾斜矫正方法与应用研究 [D].长沙:中南大学地球科学与信息物理学院,2011:23-25.]
[4]CHEN Ling,LI Xiying,LU Lin.Research and modification of license plate tilt correction algorithms [J].Computer and Modernization,2013,29 (12):91-97 (in Chinese). [陈玲,李熙英,卢林.车牌倾斜校正算法研究及改进 [J].计算机与现代化,2013,29 (12):91-97.]
[5]GUO Siyu,KONG Yaguang,ZHANG Xufang.Comer detection algorithm based on Hough transform [J].Chinese Journal of Science Instrument,2008,22 (11):2424-2429 (in Chinese).[郭斯羽,孔亚广,张煦芳.基于Hough变换的角点检测算法 [J].仪器仪表学报,2008,22 (11):2424-2429.]
[6]FU Weiping,QIN Chuan,LIU Jia,et al.Image object matching and positioning based on SIFT algorithm [J].Chinese Journal of Science Instrument,2011,32 (1):163-169 (in Chinese).[傅卫平,秦川,刘佳,等.基于SIFT 算法的图像目标 匹 配 与 定 位 [J].仪 器 仪 表 学 报,2011,32 (1):163-169.]
[7]NIU Jie.Research of character recognition algorithm [D].Beijing:College of automation,Beijing:Beijing University of Posts and Telecommunications,2010:19-22 (in Chinese).[牛洁.字符识别算法研究 [D].北京:北京邮电大学自动化学院,2010:19-22.]
[8]CHEN Junsheng.Study on digital recognition algorithm for handwritten combination structure of freedom [J].Computer Engineering and Applications,2013,49 (5):179-184 (in Chinese).[陈军胜.组合结构特征的自由手写体数字识别算法研究 [J].计算机工程与应用,2013,49 (5):179-184.]
[9]GAN Ling,LIN Xiaojing.License plate character segmentation based on connected component extraction [J].Computer Simulation,2011,28 (4):336-339 (in Chinese). [甘玲,林小晶.基于连通域提取的车牌字符分割算法 [J].计算机仿真,2011,28 (4):336-339.]
[10]HU Min,LI Mei,WANG Ronggui.Application of improved Otsu algorithm in image segmentation [J].Journal of Electronic Measurement and Instrument,2010,24 (5):443-449(in Chinese).[胡敏,李梅,汪荣贵.改进的Otsu算法在图像分割中的应用 [J].电子测量与仪器学报,2010,24 (5):443-449.]
[11]Xiang S M,Nie F P,Zhang C S.Semi-supervised classification via local spline regression [J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2010,32 (11):2039-2053.
[12]Zhong F,Qin X Y,Peng Q S.Robust image segmentation against complex color distribution [J].The Visual Computer,2011,27 (6-8):707-716.
[13]XIE Fangfang,XU Liancheng,NIU Bingru.An improved outlier detection algorithm based on reverse K-nearest neighbor[J].Computer Applications and Software,2014,31 (6):267-270 (in Chinese).[谢方方,徐连诚,牛冰茹.一种基于反向K 近邻的孤立点检测改进算法 [J].计算机应用与软件,2014,31 (6):267-270.]
[14]LU Gang,HAO Ping,SHENG Jianrong.On applying an improved deep neural networks in tiny image classification[J].Computer Applications and Software,2014,31 (4):182-184 (in Chinese).[吕刚,郝平,盛建荣.一种改进的深度神经网络在小图像分类中的应用研究 [J].计算机应用与软件,2014,31 (4):182-184.]
猜你喜欢
小天使·一年级语数英综合(2021年9期)2021-09-22
小雪花·小学生快乐作文(2020年6期)2020-10-13
文苑(2020年12期)2020-04-13
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
数字通信世界(2019年3期)2019-04-19
少儿美术(快乐历史地理)(2018年7期)2018-11-16
成都信息工程大学学报(2017年3期)2017-11-09
湖南城市学院学报(自然科学版)(2016年2期)2016-12-01
华东理工大学学报(自然科学版)(2015年2期)2015-11-07
