
K-means聚类中心的鲁棒优化算法
2015-12-20 06:58罗倩
计算机工程与设计 2015年9期
罗 倩
(北京信息科技大学 信息与通信工程学院,北京100192)
0 引 言
由于K-means方法[1]的初始聚类中心是随机选择的,不同的初始聚类中心可能会得到不同的聚类结果,因此不能获得最佳聚类效果。为了克服K-means算法的局限性,不少学者研究了优化算法,如通过中值预测[2]、KD树[3,4]、线性判别分析[5]、变异精密搜索的蜂群算法[6]以及其它改进算法[7-9]对聚类簇中心进行优化并改善K-means算法分类结果,取得了一定的效果,但是算法的鲁棒性有待进一步提高。研究聚类中心的优化问题、获得有效、准确和 稳 定 的 聚 类 结 果 具 有 重 要 意 义[10-15]。
本文提出基于邻域数据距离加权的聚类中心优化方法,提高了算法的准确性和鲁棒性,且不需要大量计算。
1 K-means算法的基本思想
K-means分析方法是广泛使用的聚类算法。算法需要事先依据某种评价函数确定最优类别数K,确保每一类中数据的相似度较高,而各类之间数据的相似度较低。Kmeans分类算法要解决的问题是将N 个数据样本{yi}Ni=1(每个数据样本的维数是n维)分类到K 个聚类之中,算法主要包括两个过程:一是根据某种准则把每个样本分配给最近的聚类中心;二是更新各个聚类中心,使其最佳地适应样本。K-means算法的具体步骤是:①采用某种评价函数确定分类数K,并随机初始化K 个聚类中心。②计算每个数据样本与每一个聚类中心的距离,距离采用2-范数距离计算,把与类中心距离最小的样本划分到该类中。③对上述每类样本计算平均值,采用平均值更新聚类中心。④判断迭代是否终止,否则返回第②步继续执行。
K-means算法结果对初始聚类中心具有依赖性,导致聚类结果不稳定,按照距离量度可能会将两类的中心处收敛为同一个聚类中心,造成分类错误,且算法本身在收敛时无法更正,如图1所示。图1 (a)用3种不同符号表示3个不同的样本数据类,采用K-means算法进行数据聚类时,可能会产生如图1 (b)的聚类结果,图中米字符号表示各类的聚类中心。图1 (b)中,上方的数据簇应属于同一个数据类,但是K-means算法却将其分为两类,分别用不同符号表示;图1 (b)的下方,原始数据应该是两个数据类,却聚类为同一类。因此K-means算法聚类结果不稳定,可能会造成分类错误。

图1 原始数据分类情况和K-means算法聚类结果
聚类是实现数据稀疏表示、数据分类、信息抽取、信号压缩和数据挖掘等应用的基础,因此准确、可靠和稳定的聚类方法对这些应用具有现实意义。本文从样本的各维数据分析出发,提出了基于邻域数据距离加权、采用数据密度约束值进行聚类更新的优化算法。
2 基于邻域数据距离加权的K-means聚类算法优化设计
图1 (b)的下方,K-means算法把两个数据类聚类为同一类,其聚类中心不处于数据密集处。图2 示出了图1所用数据样本各维直方图与上述K-means算法收敛聚类中心之间关系的分析结果。
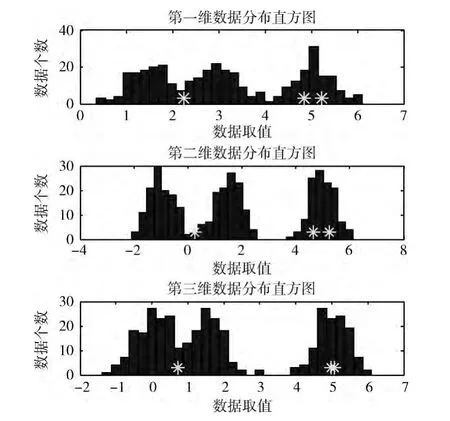
图2 样本中各维数据的直方图与聚类中心的关系
对样本的各维数据进行分析,可以看到,这种Kmeans聚类结果的出现是由于其收敛的聚类中心并不位于数据密集之处,而是位于两个数据簇之间,导致分类错误。因此,本文提出采用数据邻域距离加权的数据样本密度约束值法优化聚类效果的算法,确定聚类中心是否处于数据密集处,这样可以很好地解决K-means算法的问题,使分类结果更准确。
2.1 采用邻域数据距离加权的密度约束值判断聚类效果
本算法采用K-means方法对数据进行聚类分析,并计算数据各维的直方图,采用邻域数据距离加权的密度约束值判断聚类结果,即对直方图计算每一分析点的相邻点距离加权和,获得该点的密度约束值,建立适当的门限,只要任意一个收敛的聚类中心的任一维低于密度约束值门限,就判断聚类结果为非最优,并重新进行分类迭代。
对数据进行直方图分析后,用直方图数据进行密度约束值的计算相比采用全部数据计算可以更节省计算时间,并能提高准确率,但在做直方图运算时,应根据数据范围选择合适的组距。
本文提出算法的具体计算过程为:
(1)给定合适的组距,计算数据每一维的直方图。
(2)确定数据分布范围,计算每一值点的邻域数据距离加权值,得到数据点的密度约束值
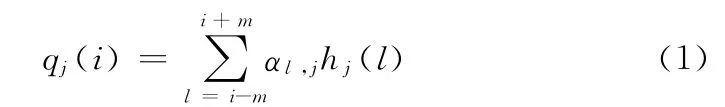
式中:j——数据维数的标号,qj(i)——第j维第i 个直方图统计点的邻域距离加权值,αl,j——距离加权系数,l——邻域距离标号,由m 确定所选取的邻域的大小,hj(l)——邻域中各点的直方图统计值。
(3)当收敛的聚类中心的某一维位置ck,j所对应的密度约束值小于某个给定的阈值Tj时,即当

则判定为本次聚类不准确,并用2.2 节方法重新确定聚类中心,并重新分类。
式 (2)中,k为数据的类号,阈值Tj取

式中:β——阈值系数。这里,只要任意一个j (j=1,…,n)或k(k=1,…,K)满足式 (2),则重新迭代。
图3示出了图1中的数据及前述收敛聚类中心的邻域数据距离加权分析结果。可以看出,此结果满足式 (2),造成这种K-means聚类结果不准确。

图3 邻域数据距离加权的密度约束值分析结果
2.2 聚类中心的优化方法
在重新聚类时,仍采用K-means聚类算法,但是不再随机选取聚类中心,而是对于上述聚类中心中某一维低于阈值的中心,用与错误聚类中心距离最近的、达到最大密度约束值的数据位置更新这个类中心,作为这个类的初始化中心,其它类的聚类中心仍采用已收敛的聚类中心。这里的距离采用2-范数距离。
再次迭代收敛条件为两次迭代后的聚类中心没有显著变化。具体为:当满足式 (4)时,则迭代终止

这里x2表示x的2-范数,ε为一个很小的正数,E 为两次相邻迭代间聚类中心误差矩阵
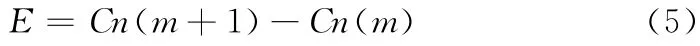
式中:Cn(m)——第m 次迭代归一化的聚类中心矩阵
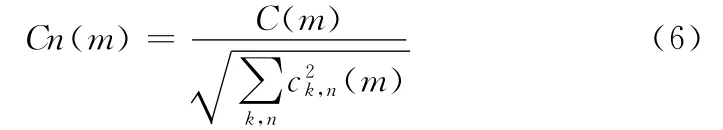
式中:m——迭代次数,C(m)——第m 次迭代所得到的各类聚类中心构成的K ×n 维矩阵,ck,n(m)——该矩阵中的各元素。
3 实验与分析
3.1 仿真实验
首先采用仿真实验。随机产生具有不同均值、方差的3类高斯分布数据,数据样本维数为三维,并随机产生初始聚类中心,图4 (a)给出了3类仿真数据的情况。
采用本文的算法得到的聚类结果在图4 (b)和图5中显示。可以看到本文算法能够准确确定各聚类中心,并获得准确的聚类结果。图5显示出收敛的聚类中心的各维都是分布在数据密度约束值相对较大的地方。
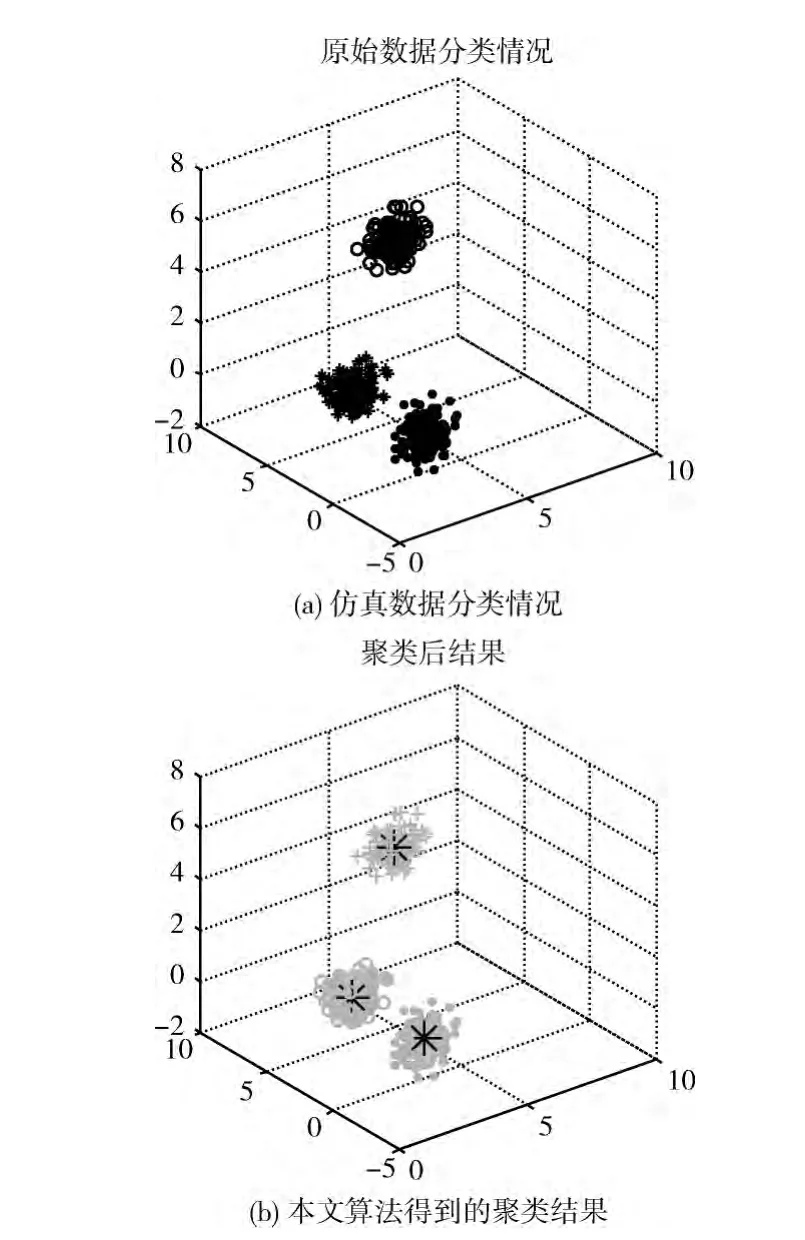
图4 原始分类数据情况和本文算法聚类结果
3.2 标准数据集实验
本部分采用UCI标准数据集 (ftp://ftp.ics.uci.edu/pub/machine-learning-databases/)中的Iris、Wine和Abalone_Data这3种数据集,将本文算法与K-means算法进行比较实验。
Iris数据包含3类,每类有50个样本,每个样本有4个属性,共150 个数据;Wine数据集是13 维数据集,共178个样本数据,分为3类;Abalone_Data数据集上含有4177个数据,每个样本维数是8维,分为3类。
3种数据集的特征见表1。

图5 仿真数据的密度约束值与各聚类中心关系
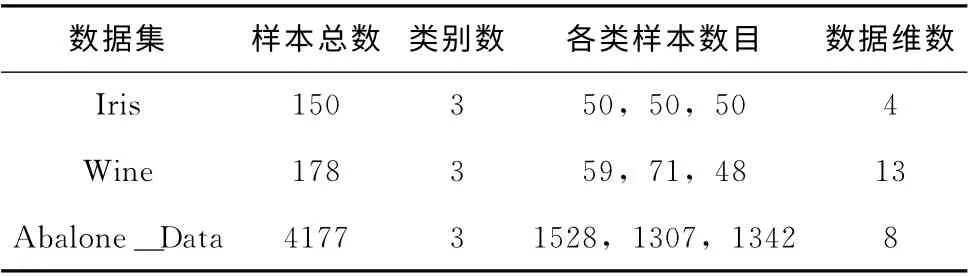
表1 Iris、Wine和Abalone_Data数据集特征
下面分别用K-means算法和本文算法对3种标准数据运行100次,K-means算法中每次运行均采用随机的初始聚类中心,分析两种算法的聚类样本个数、聚类中心、平均准确率、平均代价函数和附加迭代次数等。
首先使用K-means算法和本文算法在Iris数据集上进行测试,聚类结果见表2。
其中,平均准确率为每次收敛的准确率与该种收敛出现频次的加权和,即第i种聚类结果的准确率 (7)
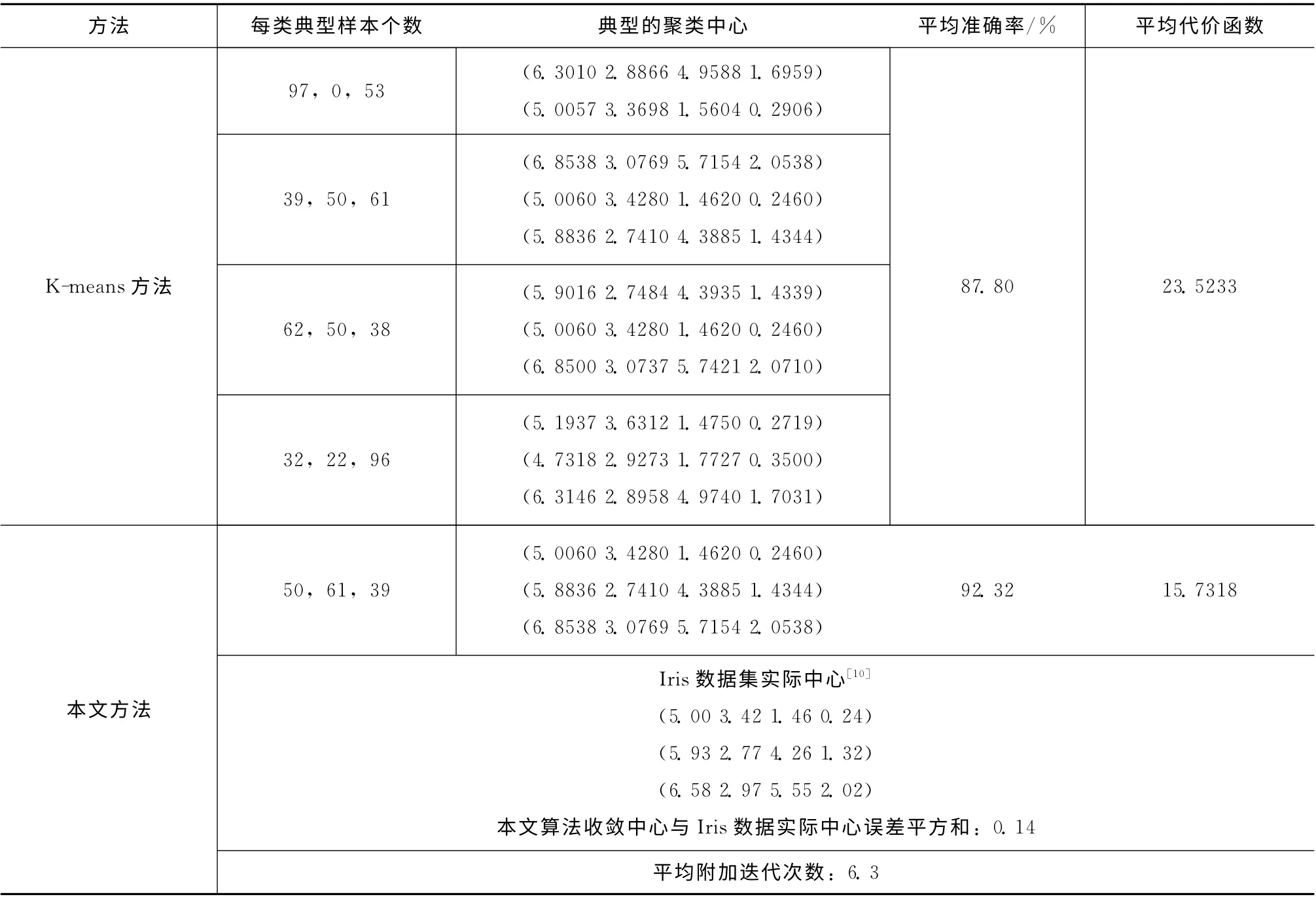
表2 采用Iris数据集算法结果对比
这里,fi为在100 次运行中,第i种聚类结果出现的频次。
各个聚类的代价函数为所有样本到各自聚类中心的2-范数距离的平均值,即

式中:Objk——第k类聚类的代价函数,Ck——第k类的聚类中心,datak,s——第k类、第s类样本,Nk——第k类的样本数。各聚类总的代价函数为

由于K-means方法收敛后聚类结果不是唯一的,所以定义平均代价函数为
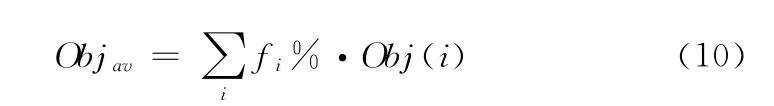
式中:Obj(i)——第i种聚类结果的代价函数。
由于Iris数据集是4维数据,不易显示,本文选取其第2-4维数据进行显示。图6 (a)用不同符号给出了Iris数据的分类情况。图6 (b)给出了本文算法对Iris标准数据集的聚类中心和聚类结果。图7是聚类中心各维的数据密度约束值情况。
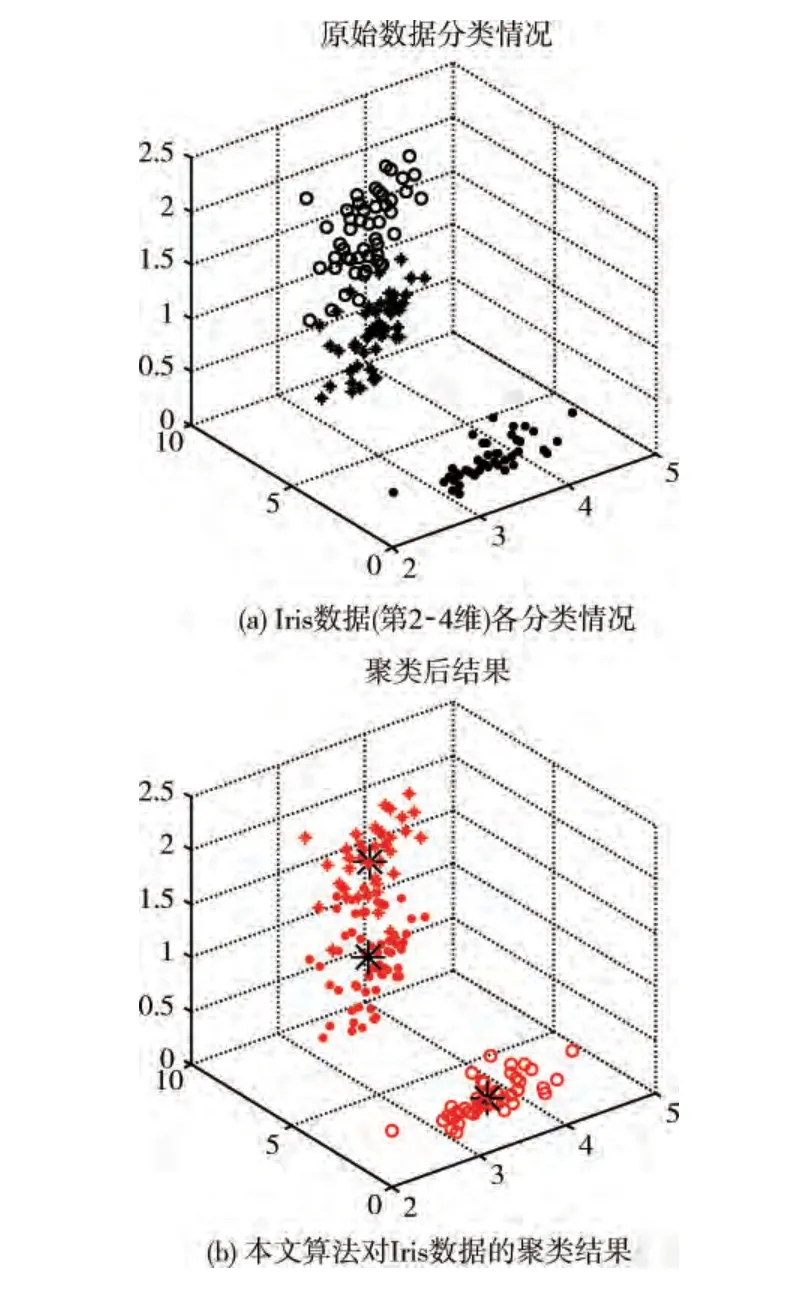
图6 本文算法应用于Iris标准数据集聚类结果
从表2和图6~图7中可以看出,对于Iris标准数据集,K-means算法聚类收敛结果不是唯一的,平均准确率较低,代价函数较高;本文算法聚类结果唯一,并与Iris数据的实际中心非常接近,且平均准确率较高,代价函数较低。此外,采用本文的收敛准则,附加迭代次数大大减少。
以上实验说明,本文算法对Iris数据是有效的和具有鲁棒性的,算法运算量较小。
对Wine和Abalone_Data数据集的分析分别见表3和表4。可以看出,对于这两个标准数据集本文算法相比于K-means分析方法同样获得了较好的平均准确率和代价函数,聚类效果具有较高的鲁棒性。
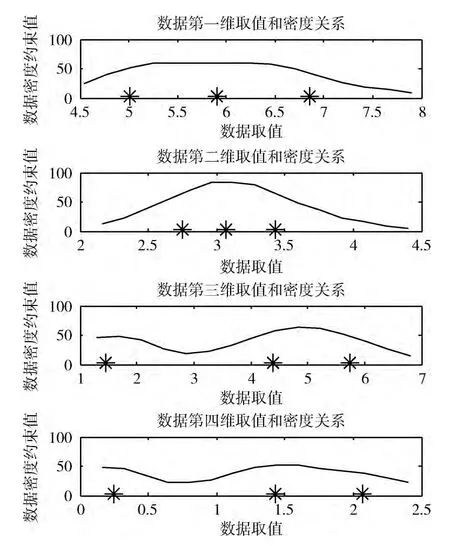
图7 本文算法对Iris数据集各聚类中心各维的数据数据密度约束值
本节的仿真实验和对各标准数据集的分析结果说明Kmeans算法由于其初始聚类中心是随机选取的,算法稳定性差,聚类质量差;本文提出的算法由于采用数据邻域距离加权约束分类判决和聚类中心的更新,可以有效地将聚类中心控制在数据密度较高的地方,所以算法可以得到准确和鲁棒的聚类效果,而且,按照本文算法的收敛准则,算法额外迭代次数较低,不影响聚类分析的运算时间,本文算法对K-means算法获得了较有效、鲁棒的优化性能。
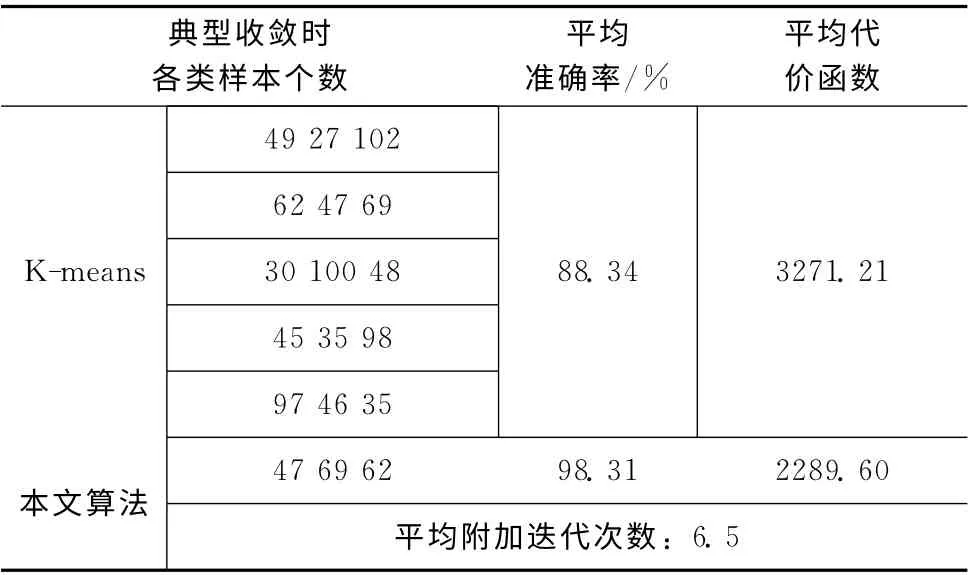
表3 采用Wine标准数据集的算法结果对比
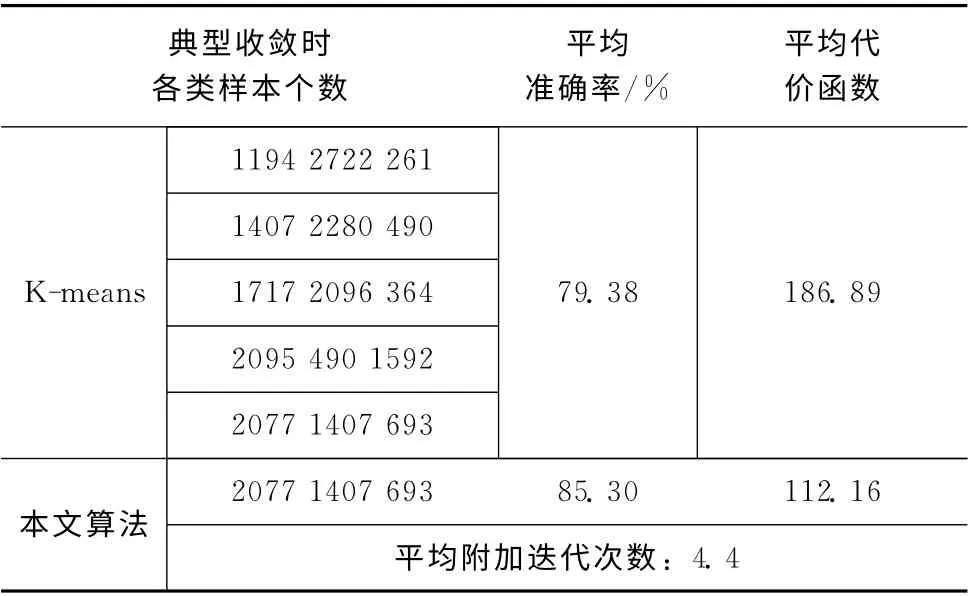
表4 采用Abalone_Data数据集的算法对比
4 结束语
K-means算法作为如图像分割、信号的稀疏表示等诸多应用的预处理算法,对其准确性和鲁棒性的要求较高。但是由于K-means分析方法对初始聚类中心的选择非常敏感,造成分类结果的不稳定,错误分类会造成以此算法为基础的后续处理的错误,因此建立高可靠性和鲁棒性聚类算法非常重要。本文提出了基于邻域数据距离加权、依据数据密度约束聚类中心更新的鲁棒算法,在仿真数据以及Iris、Wine和Abalone_Data标准数据集上对K-means算法和本文算法进行了对比分析。实验结果表明,该算法优于K-means聚类方法,具有鲁棒聚类效果,可以提高聚类质量,可以为后续的数据挖掘、模式识别、信息检索和信号的稀疏表示等处理奠定良好的基础。
[1]SU Qinghua,HU Zhongbo.K-means clustering algorithm based on differential evolution [J].Journal of Wuhan University of Technology,2010,32 (1):187-191 (in Chinese).[苏清华,胡中波.基于差分演化的K-均值聚类算法 [J].武汉理工大学学报,2010,32 (1):187-191.]
[2]Suresh L,Jay B Simha,Rajappa Velur.Seeding cluster centers of K-means clustering through median projection [C]//International Conference on Complex,Intelligent and Software Intensive Systems,IEEE,2010:15-18.
[3]Siti Noraini Sulaiman,Khairul Azman Ahmad,Nor Ashidi Mat Isa,et al.Performance of hybrid radial basis function network:Adaptive fuzzy K-means versus moving K-means clustering as centre positioning algorithms on cervical cell pre-cancerous stage classification [C]//IEEE International Conference on Control System,Computing and Engineering,IEEE,2012:607-611.
[4]Pahala Sirait,Aniati Murni Arymurthy.Cluster centres determination based on KD tree in K-means clustering for area change detection[C]//International Conference on Distributed Frameworks for Multimedia Applications,IEEE,2010:1-7.
[5]Zhang Yuhua,Wang Kun,Lu Heng,et al.An improved Kmeans clustering algorithm over data accumulation in delay tolerant mobile sensor network [C]//8th International Conference on Communications and Networking in China,IEEE,2013:34-39.
[6]LUO Ke,LI Lian,ZHOU Boxiang.Artificial bee colony rough clustering algorithm based on mutative precision search[J].Control and Decision,2014,29 (5):838-842 (in Chinese).[罗可,李莲,周博翔.基于变异精密搜索的蜂群聚类算法 [J].控制与决策,2014,29 (5):838-842.]
[7]WANG Zhong,LIU Guiquan,CHEN Enhong.A K-means algorithm based on optimized initial center points [J].Pattern Recognition and Artificial Intelligence,2009,22 (2):299-304 (in Chinese). [汪中,刘贵全,陈恩红.一种优化初始中心点的K-means算法 [J].模式识别与人工智能,2009,22 (2):299-304.]
[8]Jiang Dongyang,Zheng Wei,Lin Xiaoqing.Research on selection of initial center points based on improved K-means algorithm [C]//2nd International Conference on Computer Science and Network Technology,IEEE,2012:1146-1149.
[9]Liao Qing,Yang Fan,Zhao Jingming.An improved parallel K-means clustering algorithm with map reduce [C]//Proceedings of 15th IEEE International Conference on Communication Technology,IEEE,2013:764-768.
[10]Xie Juanying,Jiang Shuai.A simple and fast algorithm for global K-means clustering [C]//2nd International Workshop on Education Technology and Computer Science,IEEE,2010:36-40.
[11]JI Suqin,SHI Hongbo.Optimized K-means clustering algorithm for massive data[J].Computer Engineering and Applications,2014,50 (14):143-147 (in Chinese). [冀素琴,石洪波.面向海量数据的K-means聚类优化算法 [J].计算机工程与应用,2014,50 (14):143-147.]
[12]YU Haitao,LI Zi,YAO Nianmin.Research on optimization method for K-means clustering algorithm [J].Journal of Chinese Computer Systems,2012,33 (10):2273-2277 (in Chinese).[于海涛,李梓,姚念民.K-means聚类算法优化方法的研究[J].小型微型计算机系统,2012,33 (10):2273-2277.]
[13]FENG Bo,HAO Wenning,CHEN Gang,et al.Optimization to K-means initial cluster centers [J].Computer Engineering and Applications,2013,49 (14):182-185 (in Chinese). [冯波,郝文宁,陈刚,等.K-means算法初始聚类中心选择的优化 [J].计算机工程与应用,2013,49 (14):182-185.]
[14]YANG Mingchuan,LV Xuebin,ZHOU Qunbiao.Image segmentation algorithm based on incomplete K-means clustering and category optimization [J].Journal of Computer Applications,2012,32 (1):248-251 (in Chinese). [杨明川,吕学斌,周群彪.不完全K-means聚类与分类优化结合的图像分割算法 [J].计算机应用,2012,32 (1):248-251.]
[15]SHI Yabing,HUANG Yu,QIN Xiao,et al.K-means clustering algorithm based on a novel approach for improved initial seeds[J].Journal of Guangxi Normal University (Natural Science Edition),2013,31 (4):33-40 (in Chinese).[石亚冰,黄予,覃晓,等.基于优化初始种子新策略的K-Means聚类算法 [J].广西师范大学学报 (自然科学版),2013,31(4):33-40.]
猜你喜欢
湘潭大学自然科学学报(2022年2期)2022-07-28
吉林大学学报(理学版)(2020年3期)2020-05-29
摄影之友(影像视觉)(2018年12期)2019-01-28
自动化学报(2018年7期)2018-08-20
电子测试(2017年15期)2017-12-18
雷达学报(2017年6期)2017-03-26
初中生世界·八年级(2017年3期)2017-03-24
周口师范学院学报(2016年5期)2016-10-17
潍坊学院学报(2016年6期)2016-04-18
电子设计工程(2015年6期)2015-02-27
