
决策树技术在物流金融信用风险中的应用
2015-12-20 08:41蒋礼仁SHAOMeiJIANGLiren
物流科技 2015年4期
邵 梅,蒋礼仁 SHAO Mei, JIANG Li-ren
(1. 西南交通大学 交通运输与物流学院,四川 成都610031;2. 东莞市城建规划设计院,广东 东莞523129)
(1. Transport and Logistics Institute of Southwest Jiaotong University, Chengdu 610031, China; 2. Dongguan City Urban Construction Planning and Design Institute, Dongguan 523129, China)
0 引 言
中小企业的蓬勃发展已经成为推动中国经济向前的重要力量。但是,由于国家政策的倾斜、中小企业自身规模等原因,资金瓶颈问题已经成为其发展道路的主要障碍。中小企业具有信用等级较低、固定资产所有权不明确、融资抵押物和担保匮乏等特点。银行等金融机构为控制贷款风险仅以固定资产抵押担保方式为中小企业提供贷款服务,几乎不对其做信用贷款。那么,如何解决中小企业融资困境呢?解决中小企业融资问题的核心在于金融创新。物流金融通过引入物流企业,优化了银行和企业间的信息不对称所带来的逆向选择和道德风险问题,使得银行对中小企业授信的收益成本得到明显改善。
物流金融是金融服务和物流服务相互集成的创新综合服务。浙江大学经济学院的唐元琦和邹小芃(2004) 首次提出了物流金融的概念,他们认为物流金融就是面向物流业的运营过程,通过开发、提供和应用各种金融服务和金融产品,有效地组织和调剂物流领域中的信用和资金的运动,达到物流、信息流和资金流的有机统一。物流金融不仅能提高第三方物流企业的竞争力、创造新的利润增长点,还能够拓宽金融机构的业务范围、提升利润空间,更能解决中小企业长期面临的融资难问题。
物流金融作为一项较新的金融业务模式,在实现银行、物流企业和中小企业三方共赢的同时也给银行带来了各种各样的风险,比如信用风险、市场风险、操作风险以及流动性风险等。信用风险是指交易一方不能履约或不能完全履约而给另一方带来的风险,是最主要的风险,主要来源于委托人和代理人之间的信息不对称。从信用风险产生的主体来看,融资企业是最主要的风险来源。因此,如何识别融资企业的信用好坏,对银行等金融机构来说就显得尤其重要。随着信息技术在物流企业的普及,大量的数据被存储,这些数据中隐藏了众多信息和关键业务模式,决策树等数据挖掘技术可以从这些数据中提取出潜在的有用信息和知识。把决策树等数据挖掘技术应用到物流金融领域,对海量物流数据信息进行处理、分析和优化,可以充分挖掘出这些信息潜在价值,从而有利于银行等金融机构对需要融资的中小企业的信用进行分类,识别出具有良好信用融资企业的特征属性,为信用风险的防范提供参考依据。
1 物流金融研究现状
物流金融起源于物资融资业务。国外物流和金融的结合可以追溯到公元前2400 年美索不达米亚的“谷物仓单”。国内关于物流金融的研究起步相对较晚,1987 年陈淮提出了关于构建物资银行的设想,但由于种种原因,这一设想没有被充分发现和认识。随后又出现了物流银行、仓单质押、融通仓、金融物流等概念。
储雪俭等提出目前我国金融物流信贷风险防范中的四个主要难点,并给予了相关的对策建议。孙颖对物流金融的业务风险、宏观环境风险和法律风险进行了分析,提出了相关的风险管理建议。王元元认为物流金融业务中进行融资的中小企业是银行最主要的信用风险来源,其次,物流企业也是银行面临的信用风险来源。
随着定性研究的逐步深入,定量研究开始出现。潘永明从物流金融运营状况、第三方物流企业综合实力、中小企业综合实力和行业状况四个方面对物流金融信用风险的影响因素进行分析,建立了物流金融信用风险评价指标体系。刘哲等利用模糊层次综合法从企业基本特征、财务能力、货物风险、履约能力、发展潜力等五个方面构建物流金融信用评价指标体系,并对这些指标因素进行细分,建立了三级四层的指标评价体系。何明珂运用BP 神经网络评估模型以及Matlab 软件将某一项具体的物流金融业区分为高、中、低三种风险。
综上所述,国内对物流金融的研究多集中在物流金融基本知识、风险种类及防范和信用评价指标体系建立等方面。
2 决策树技术
数据挖掘(Data Mining,DM) 就是从大量的、不完全的、有噪声的、模糊的、随机的数据中,提取隐含在其中的、人们事先不知道的、但又是潜在的有用信息和知识的过程。数据挖掘又称数据库知识发现。决策树是数据挖掘诸多技术和方法中常见的一种,它的优势在于通过对已知类别训练集的分析,可以提取出有价值的分类规则,从而对新数据的类别进行预测,给决策者提供一定的参考。
ID3 算法是基于决策树的挖掘算法,以信息增益作为属性测试,并选取具有最高增益的属性值作为分裂属性,自顶向下地构建决策树,直到不能再划分为止。ID3 算法的核心问题是如何选取决策树的每个节点要测试的属性。
设S是s个样本数据的集合,将样本划分为m个不同类Ci(i=1,…,m)的信息熵按式(1) 计算(其中pi是任意样本属于Ci的概率):

假设属性A作为决策树的根节点,属性A具有v个不同取值,把数据集S划分成v个子集{S1,S2,…,Sv},根据属性A划分成的子集熵按式(2) 计算:

信息增益为原来的信息需求(基于类比例) 与新的信息需求(对A划分之后得到的) 之间的差,即式(3):

3 算例研究
决策树技术应用于物流金融信用风险中的基本思路是:根据已知样本和原始信用评价状态,发现贷款企业信用状态与其某些特征属性之间的关系,进而通过对这些企业属性的具体观察值,对其信用状况进行预测。本文利用ID3 算法给出某物流企业的具有高还款风险客户的特征属性,为银行等金融机构进行风险控制提供参考依据。
3.1 数据选择和预处理。假设从某物流企业的数据库中收集到的客户信息有注册方式、信用等级、企业规模、企业性质等。需要注意的是进行相关分析的数据不是只存储在一个数据库中,还可能存在于其它数据集中,要根据实际需要进行相关的收集整理。收集后的数据往往不能直接挖掘,需要进行一定的选择、清理、转换和归纳等预处理工作,数据预处理工作准备是否充分,对于挖掘算法的效率乃至正确性都有关键性的影响。
ID3 算法比较适合处理离散数值的属性,表1 中的注册资本和销售业绩是连续属性,可以通过分箱、直方图分析、直观划分等离散方法将属性的值划分为几个区间,然后就可采用和离散值处理相同的方法。由于考虑的是一组具有高还款风险物流企业的客户的特征属性,选取企业规模、企业性质、企业地点、银行资信等级和还款风险属性来进行分类预测。
3.2 信息增益的计算。决策属性为高还款风险和低还款风险,S1(高还款风险)=8,S2(低还款风险)=12,则信息熵I(S1,S2)
公司规模分为大型企业、中型企业、小型企业三组,在大型企业中具有高还款风险属性的企业有0 个,具有低还款风险属性的企业有6 个,
在中型企业中具有高还款风险属性的企业有4 个,还款风险低的企业有5 个,则信息熵=0.9911。
在小型企业中还款风险高的企业有4 个,具有低还款风险属性的企业有1 个,则信息熵为=0.7219。
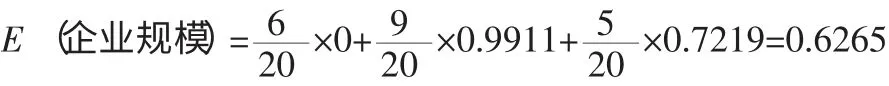
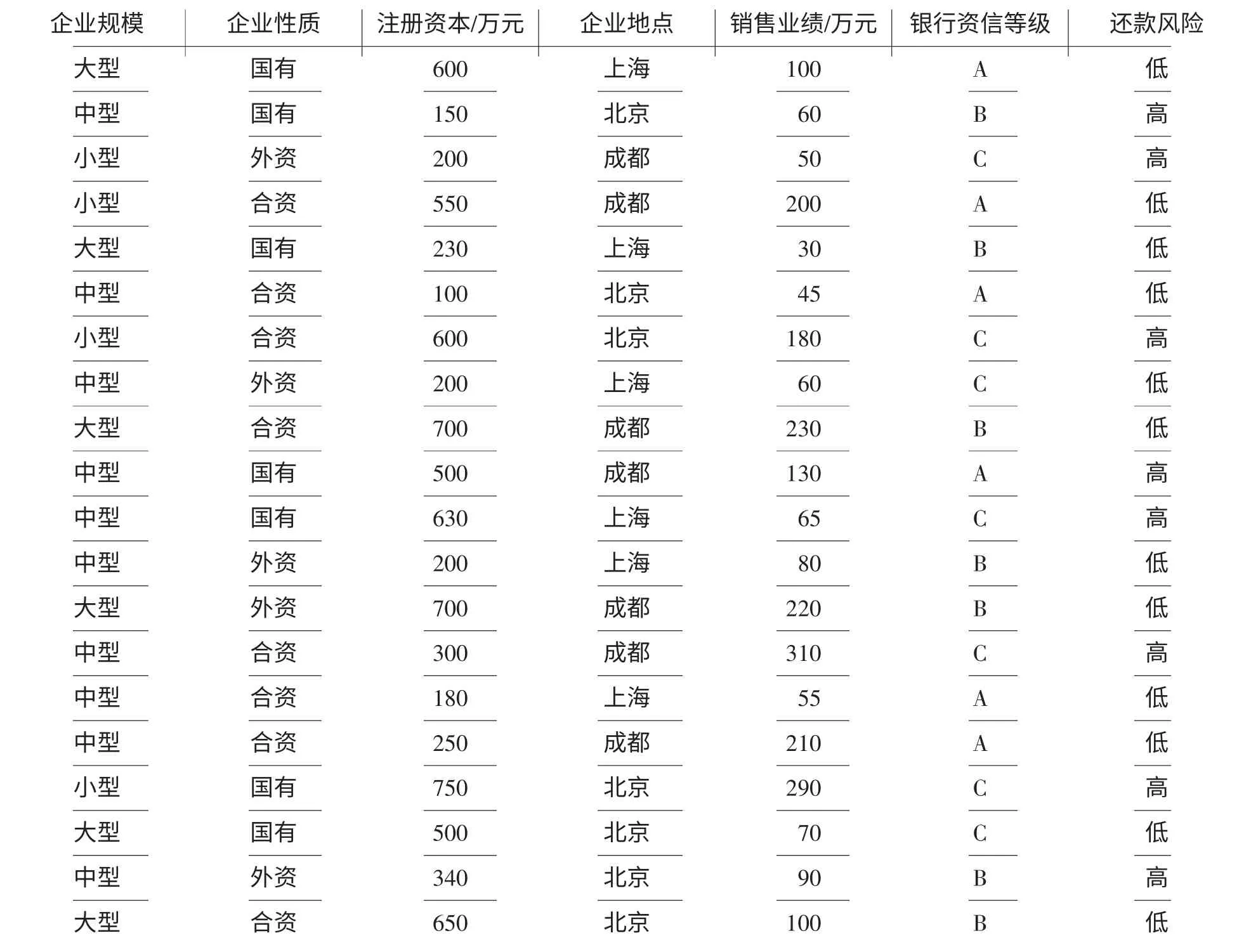
表1 企业信息表
企业地点分为上海、成都、北京三个地方:
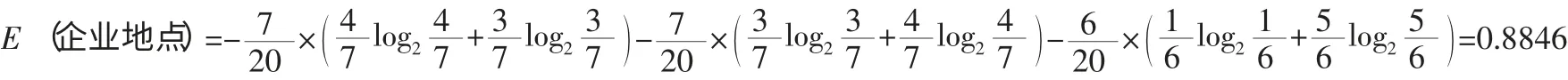
银行资信等级分为A,B,C 三组:
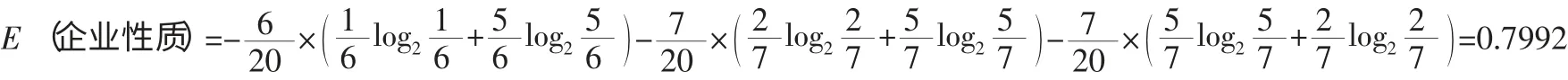
各属性的信息增益:
G(企业规模)=0.9710-0.6265=0.3445
G(企业性质)=0.9710-0.9121=0.0589
G(企业地点)=0.9710-0.8846=0.0864
G(银行资信等级)=0.9710-0.7992=0.1718
我们知道,信息增益越大,选择测试属性对分类提供的信息越多。从上面计算出的值可以看出具有高信息增益的属性是企业规模,所以选择企业规模为根节点。当企业规模都为大企业时,企业的还款风险低,当企业规模为中型企业或者小型企业时,企业的还款风险或者低或者高,没有具体的特征属性,所以可以继续对属性进行分类。
对中型企业进行分类:
S1(还款风险高)=4,S2(还款风险低)=5
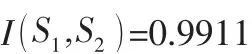
G(企业性质)=0.991-0.660=0.3311
G(企业地点)=0.991-0.612=0.3791
G(银行资信等级)=0.991-0.988=0.0311
对于中型企业来说,选择属性企业地点为节点进行分类。类似,可以给小型企业选择信息增益最大的属性作为节点进行分类。经过进一步的分类,得到如图1 所示的决策树。在这里,采用预剪枝的方法进行剪枝,停止树的增长,防治过度拟合。
3.3 结果分析。由图1 可以得到如下规则:(1) 如果公司规模是大型企业,则还款风险低;(2) 如果是中型公司且公司地点在上海,则还款风险低;(3)如果公司是小型企业,则具有高还款风险。
根据上述结论,具有高风险还款能力的是小型企业或地点在北京或者成都的中型企业,还款风险低的是大型企业或在上海的中型企业。针对这种分类,银行在对物流公司进行还款风险预测时,可以将主要精力集中在具有低还款风险特征属性的物流企业上。
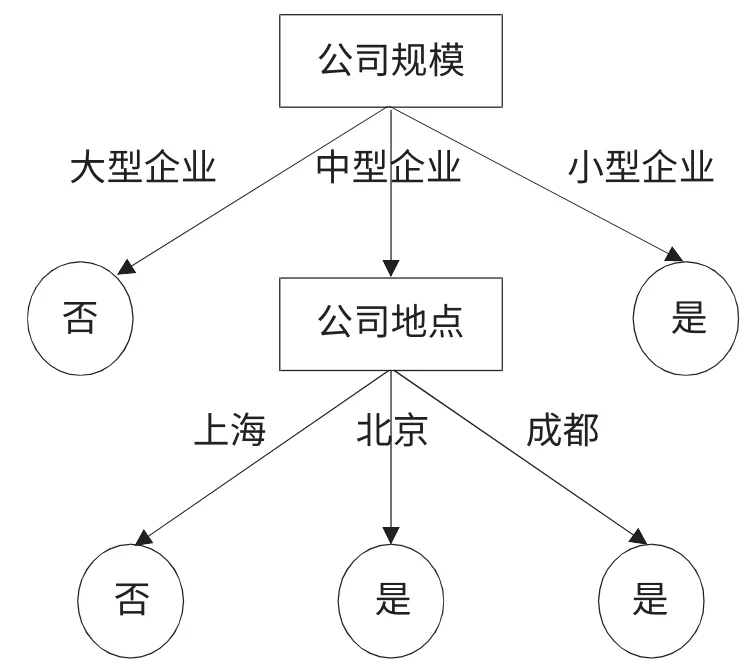
图1 决策树
4 结束语
随着信息化水平的提高,银行和物流企业都积累了各种各样的数据,如何从大量的数据中挖掘出潜在的应用价值,有效地降低物流金融的信用风险是个值得探讨的问题。本文利用决策树ID3 算法对某物流企业客户的高还款风险特征属性进行了挖掘,能够给银行进行信用风险分类预测时提供一些参考,克服人为经验因素带来的不确定性,降低信用风险。需要指出的是,在实际应用时,可以根据实际情况选择相应的属性进行分类,以期找到更加符合现实情况的分类,为物流金融信用风险的防范提供一定的科学依据。
[1] Jiawei Han Micheline Kamber. 数据挖掘概念与技术[M]. 范明,孟小峰,等译. 北京:机械工业出版社,2006:128-137.
[2] 陈祥锋,石代伦,朱道立. 金融供应链与融通仓服务[J]. 物流技术与应用,2006(3):93-95.
[3] 裴英梅. 基于数据挖掘技术的现代物流决策研究[J]. 物流技术,2008,27(7):47-49.
[4] 郭洪涛,郭永红. 数据挖掘技术在物流信息系统中的应用[J]. 科技信息,2009(4):262-263.
[5] 薛华,朱杰. 物流决策中决策树分类技术的应用研究[J]. 商场现代化,2012,10(698):72-73.
[6] 谢江林,何宜庆,陈涛. 数据挖掘在供应链金融风险控制中的应用[J]. 南昌大学学报,2008,6(32):278-281.
[7] 唐元琦,邹小芃. 物流金融浅析[J]. 浙江金融,2004(5):20-21.
猜你喜欢
大众投资指南(2021年35期)2021-02-16
成都信息工程大学学报(2019年3期)2019-09-25
电子制作(2018年16期)2018-09-26
辽宁经济(2017年6期)2017-07-12
电力与能源(2017年6期)2017-05-14
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
当代经济(2016年26期)2016-06-15
信息通信技术(2015年6期)2015-12-26
新疆财经大学学报(2015年3期)2015-12-10
郑州大学学报(医学版)(2015年1期)2015-02-27
