
基于FCM和SVM的TM遥感影像自动分类算法
2015-12-11 02:25:36黄奇瑞
华北水利水电大学学报(自然科学版) 2015年4期
黄奇瑞
(南阳理工学院 电子与电气工程学院,河南 南阳 473004)
卫星遥感技术是20 世纪70 年代发展起来的新兴综合技术,是研究地球资源环境的最有力的技术手段之一[1].遥感影像的分类解译是遥感地理信息系统中的核心技术之一,快速、精准的自动分类算法是实现从遥感影像中提取有用信息的关键[2]. 由于遥感影像数据的信息量大、维数高,对于遥感影像的应用,传统的分类方法有较大的限制.因此探寻适合遥感影像的分类方法是关于遥感技术研究的首要课题.国内外很多学者都在研究和分析探索新的分类方法,以便提高遥感影像自动分类的精度和效率[3].
支持向量机(Support Vector Machine,SVM)是由Vapnik 提出的一种基于统计学习理论的新的通用机器的学习方法[4].统计学习理论是研究在有限样本情况下机器的学习规律的一门学科.SVM 是在统计学习理论的VC 维理论以及结构风险最小化原则基础上建立的一种机器学习方法[5-6]. SVM 分类方法在解决有限样本、非线性及高维模式识别问题中具有很多独特的优势,相关研究成果也表明,其能够达到比传统分类器更高的分类精度[7].
传统的基于SVM 的遥感影像分类法,大部分是通过对待分类的影像进行人工解译形成训练样本集,送入支持向量机训练后进行分类.这种方法虽然也取得了很好的分类精度,但是由于这种监督分类方法需要有丰富经验的专家对影像进行目视解译来选取训练样本,使得分类的精度和分类效率对人的依赖性比较大.
1 支持向量机理论
1.1 SVM 分类的基本思想
SVM 处理分类问题的基本思想是构造一个最优分类超平面作为决策曲面[8],使得两类之间的分类间隔最大,然后将寻找最优分类超平面转化为求解二次规划寻优的对偶问题,从而使计算的复杂度取决于样本数目而非样本空间的维数. 更准确地来说,是取决于样本中支持向量的数目. 因此,支持向量机能够有效地解决样本数据的高维问题.
1.2 最优分类超平面的构造
设有2 类样本集合:(xi,yi;i=1,2,…,n),xi∈Rd.相应的分类标签记为:yi∈{+1,-1},SVM 在高维特征空间中求最优超平面的问题:
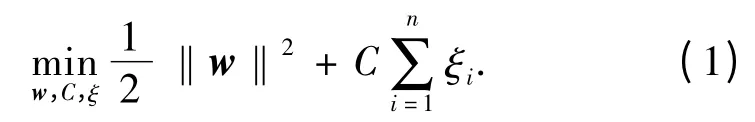
式中:C 为一个正常数,称为惩罚因子,起到控制对错分样本惩罚程度的作用,实现在错分样本的比例和算法复杂程度之间的“折衷”;ξ 为在训练样本线性不可分时引入的非负松弛变量.
通过引入Lagerange 函数,构造并转化求解上述最优问题为如下凸二次规划(Quadratic Programming,QP)寻优的对偶问题:
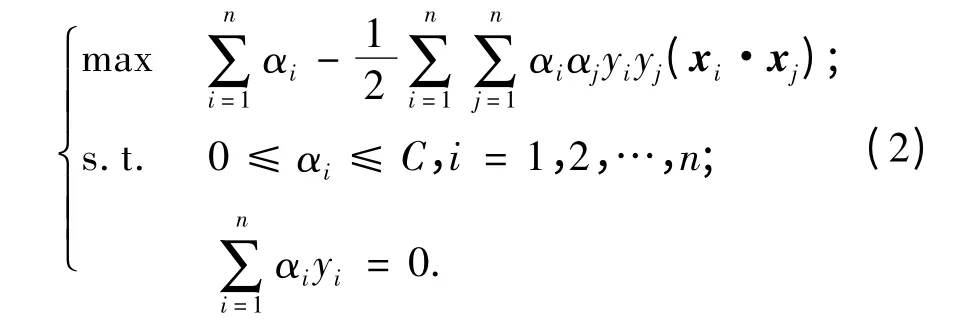
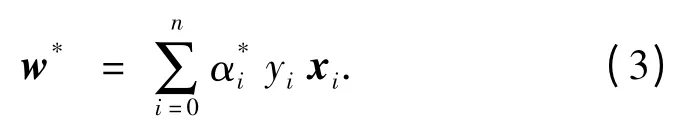
解上述问题后得到的最优分类面函数为:
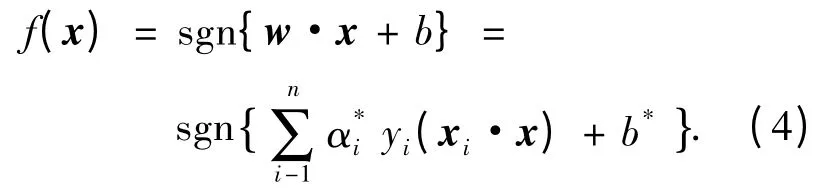
式中b*为分类阈值,可由约束条件
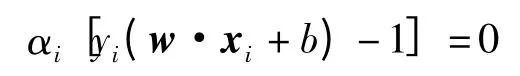
求解.
对于非线性分类问题,根据泛函的相关理论,只要有一种内积函数(核函数)K(xi,xj)满足Mercer条件[9],就能够通过非线性映射把样本空间映射到高维特征空间,从而在高维特征空间中构造最优分类超平面实现线性的分类,同时也解决了算法中维数灾难的问题,计算复杂度却没有增加,此时目标函数式(2)变为:
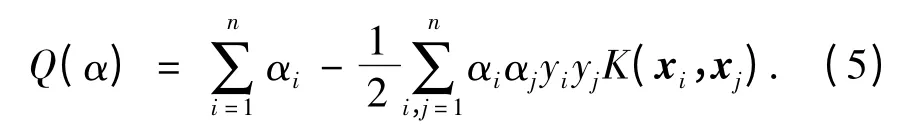
对应的分类判别函数也变为:
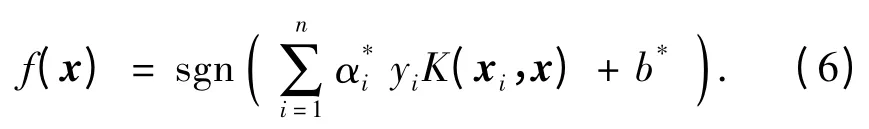
常用的满足Mercer 条件的核函数有以下4 种:线性核函数、多项式核函数、径向基核函数(高斯核函数、Sigmoid 核函数. 选用不同的核函数可构造不同的支持向量机.
2 模糊C 均值基本理论
模糊C 均值聚类算法是1973 年由Bezdek 提出的一种基于目标函数的动态优化算法. 其用隶属度来确定每个样本点属于某个类别的程度,可以实现对数据的自动聚类[10]. FCM 作为早期硬C 均值聚类(HCM)算法的一种改进算法,其不同于HCM 分类时非此即彼的划分方法.FCM 是一种柔性的模糊划分,其聚类原则是使得被划分到同一类别的样本之间具有最大的相似度,而不同类别之间的相似度则最小.因此FCM 是用隶属度来确定每个样本属于某个类别的程度[11].
对于由n 个样本组成的数据集Xi(i =1,2,…,n),用隶属度函数进行定义的聚类损失函数可写为
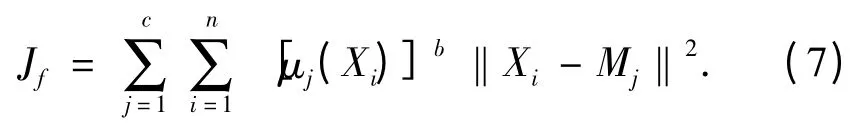
式中:c 为设定的聚类数目;Mj(j=1,2,…,c)为各个类别的聚类中心;μj(xi)为第i 个样本数据对于第j个类别的隶属函数;b >1,为一个常数,其能够控制聚类结果的模糊程度. 由不同的隶属度定义下最小化聚类损失函数Jf,可得到不同的模糊聚类算法.其中的典型代表就是FCM 聚类算法,其基本要求是每个对象对各类别的隶属度之和为1,即
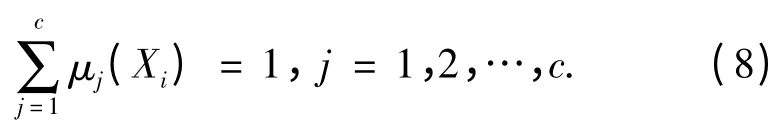
在条件式(8)下求式(7)的极小值,令Jf对Mi和μj(Xi)的偏导数为0,得到必要条件:
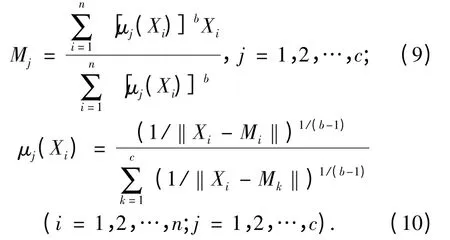
用迭代的方法求解式(9)和式(10),就是模糊C 均值算法.当算法收敛时,就得到了各个类别的聚类中心以及每个对象对于各个类别的隶属度函数,也即实现了对所有对象的模糊分类.
3 结合FCM 和SVM 的自动分类方法
由上文所述SVM 的基本原理可知,支撑SVM最优分类超平面的支持向量即为距离这个超平面最近的样本,然而这些样本在整个训练数据中通常只占很小的比例,即最优分类超平面仅取决于少数的支持向量,而占绝大多数的非支持向量对SVM 分类器的构建是不起作用的[11]. 在用SVM 分类器进行分类的时候,这些大量的非支持向量的训练样本在训练过程中会耗费大量的时间和内存,从而降低SVM 分类器的分类效率,甚至会因计算机内存不足而使训练无法完成.
FOODY 等[12]指出,在求解SVM 分类器的最优分类超平面时,使用混合像元比使用纯净像元更有效.即在SVM 分类器的构建时,采用少量的混合像元作为训练样本集和采用大量的纯净像元作为训练集,其训练效果是一样的.因此,笔者结合FCM 聚类算法提出了一种基于模糊C 均值聚类和支持向量机的且能够自动挑选混合像元的算法.FCM 作为非监督聚类算法,可以根据预先设定的类别数自动聚类,并得到每个样本隶属于各个类别的隶属度矩阵.因此所谓的混合像元,可以认为是那些同时对某两个类别具有较高隶属度的像元. 同时根据遥感影像的特点,为了避免影像中孤立点(噪声)对训练分类器产生的影响,在聚类后每个类别中最大的连通区域内挑选符合上述条件的像元作为训练样本集. 由此提出自动选取混合像元D(i,j)的算法,即对于影像中每个像元D(i,j)需要满足如下的约束条件:
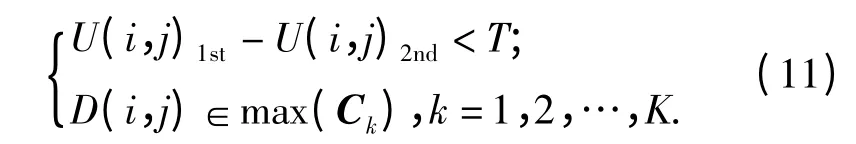
式中:U 为利用FCM 算法对遥感影像聚类后得到的隶属度矩阵;U(i,j)1st,U(i,j)2nd分别为像元D(i,j)的隶属度矩阵中的最大值和次大值;T 为设置的用于挑选纯净像元的阈值;Ck为聚类后第k 类地物的所有连通区域.
4 试验验证
为了验证笔者所提出的算法的有效性,选取大理洱海西南区域(如图1 所示)的一块TM 影像作为对象进行验证.数据来源于中国科学院计算机网络信息中心的地理空间数据云平台(http://www.gscloud.cn).该试验区域的假彩色合成图(4、5、3 波段)如图2 所示.TM 遥感影像是由美国Lansat 7 卫星获取的,共7 个波段,其空间分辨率为30 m×30 m.试验选用的是第1—5 和第7 波段,共6 个波段.TM 遥感影像的分类方法基本上都是基于像元分类的,因此每个像元是一个6 维的特征向量. 试验的测试环境为P4 2. 80 GHz CPU,1G 内存,操作系统为Windows XP,在MATLAB 7.1 的平台上编程实现.
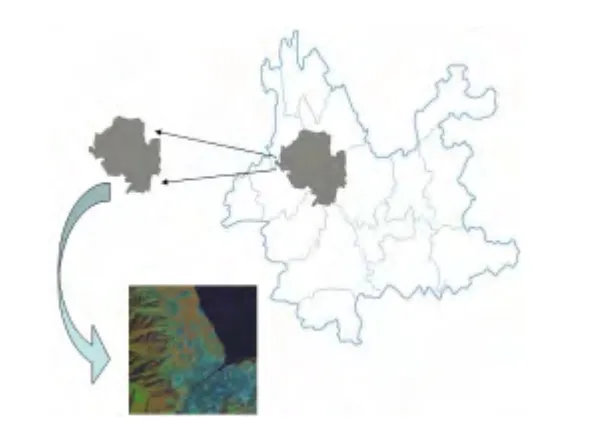
图1 阴影区域为试验所选的研究区域

图2 研究区域的假彩色合成图(TM 4,5,3)
通过参照对应的1∶50 000 的土地利用图,将试验区地物类别分为5 类:水体、林地、耕地、建筑(包括道路)和草地.首先通过FCM 算法对试验区影像进行聚类,结果如图3 所示,同时得到聚类后所有像元的隶属度矩阵.
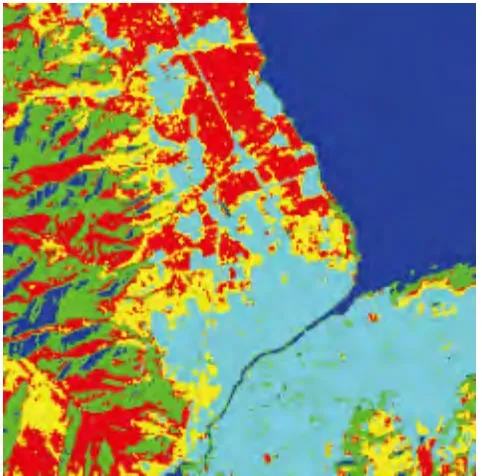
图3 FCM 非监督分类的结果
结合上述聚类结果,根据笔者提出的训练样本自动选择算法,从影像中自动挑选出混合像元作为训练样本集,并将其归一化处理后送入SVM 分类器进行训练.用径向基核函数作为SVM 分类器的核函数,通过网格搜索和交叉验证的寻优方法确定最佳参数(C,g),其中C 为惩罚系数,g 为核函数宽度.利用上述方法训练完成后,就可以得到最终用来分类的SVM 分类器,并对遥感数据进行分类,分类结果如图4 所示.
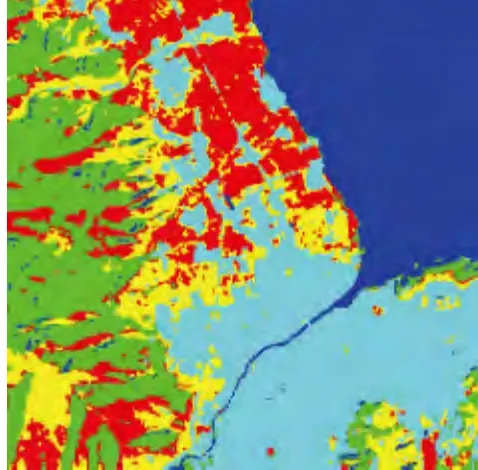
图4 笔者提出方法的分类结果
为了对比SVM 监督分类方法和笔者所提出方法的分类效果,利用人工选取的训练样本(如图5所示),用同样的方法训练SVM 分类器,并对遥感数据进行分类,最终得到的分类结果如图6 所示.
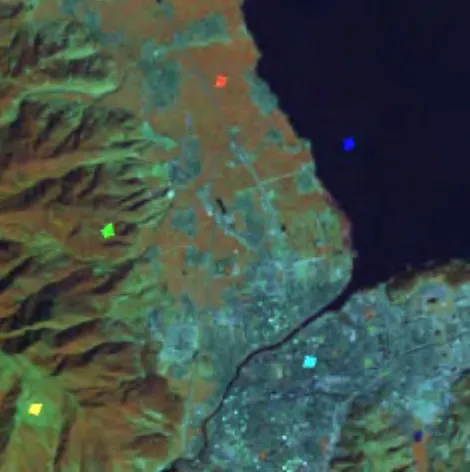
图5 SVM 分类器人工标注的训练样本

图6 SVM 监督分类的结果
以上3 种分类方法的分类结果的混淆矩阵见表1. 通过对比图4、图5 和图6 以及对表1 中数据的分析可知,传统的FCM 非监督分类和SVM监督分类方法对阴影区域都出现了大面积的错分,同时对较小的河流由于处于阴影中,也会出现一定的错分,致使分类后的河流出现断裂.利用笔者所提出的方法分类能避免上述问题. 从图6可以看出,只有极少量的阴影被错分,能较完整地分出影像中的河流. 从表1 中也可看出,笔者提出的方法总体分类精度和Kappa 系数分别达到了0. 952 和0. 940,明显高于其他两种分类方法.
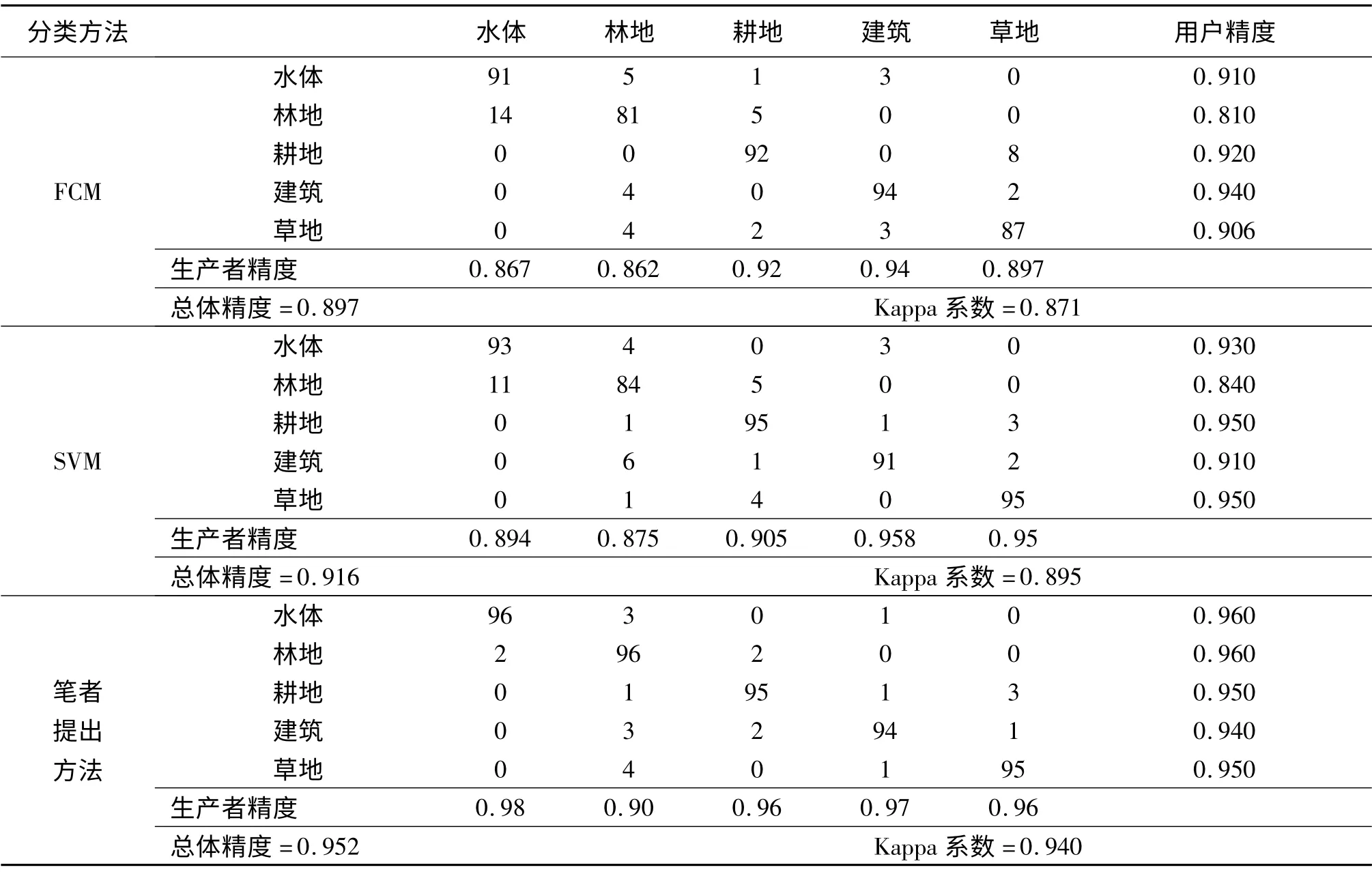
表1 3 种分类方法分类结果的混淆矩阵
5 结 语
利用笔者提出的方法,将FCM 非监督分类和SVM 监督分类结合,实现了对遥感影像的自动分类.该方法不需要对待分类的影像有太多先验知识,只需通过简单的目视解译,确定出原始影像所具有的类别数,将其和其他参数输入编好的程序即可完成整个分类流程.该方法比传统的非监督分类具有更高的分类精度,同时解决了监督分类时需要人工选择训练样本且样本难以选定的问题,分类精度也有所提高,对于利用TM 影像进行大尺度的地物类别判定具有实用价值.
[1]丁志雄,颜廷松,屈吉鸿. 多源遥感影像在水库水位-库容曲线复核中的应用[J]. 华北水利水电学院学报,2012,33(4):32 -35.
[2]朱建华,刘政凯,俞能海. 一种多光谱遥感图像的自适应最小距离分类方法[J]. 中国图象图形学报,2000,5(1):21 -24.
[3]张立民,刘峰,张瑞峰. 一种构造系数的自相关函数特征提取算法[J]. 无线电通信技术,2012,38(5):56-59.
[4]VAPNIK V N. Estimation of Dependencies Based on Empirical Data[M].Berlin:Springer-Verlag,1982.
[5]边肇祺,张学工. 模式识别[M]. 北京:清华大学出版社,2000.
[6]VAPNIK V N. The Nature of Statistical Learning Theory[M].Berlin:Spring-Verlag,1995.
[7]杜培军.基于支持向量机的高光谱遥感分类进展[J].测绘通报,2006(12):37 -40.
[8]张学工.关于统计学习理论与支持向量机[J].自动化学报,2000,26(1):32 -41.
[9]CRISTIANINI N,SHAWE-YAYLOR J. An Introduction to Support Vector Machines and Other Kemel-based Learning Methods[M].Cambridge:Cambridge University Press,2000.
[10]BEZDEK J C,EHRLICH R.FCM:The fuzzy c-means clustering algorithm[J].Computers & Geosciences,1984,84(10):191 -203.
[11]刘志勇,耿新青. 基于模糊聚类的文本挖掘算法[J].计算机工程,2009,35(5):44 -49.
[12]FOODY G M,MATHUR A,FULL W. Toward intelligent training of supervised image classifications:Directing training data acquisition for SVM classification[J]. Remote Sensing of Environment,2004,93(1):107 -117.
猜你喜欢
数学年刊A辑(中文版)(2021年3期)2021-11-05 08:36:32
数学年刊A辑(中文版)(2021年2期)2021-07-17 08:37:58
科技创新与应用(2020年6期)2020-02-29 10:39:27
数学物理学报(2019年1期)2019-03-21 05:26:12
电子测试(2018年1期)2018-04-18 11:52:35
北京理工大学学报(2016年6期)2016-11-22 11:17:22
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
电视技术(2016年9期)2016-10-17 09:13:41
系统工程与电子技术(2016年7期)2016-08-21 13:59:00
