
Nutch搜索引擎的公安应用研究
2015-12-08 09:23萍申亚鹏
中国刑警学院学报 2015年1期
肖 萍申亚鹏
(1 中国刑警学院 辽宁 沈阳 110035;2 大连市公安局西岗分局 辽宁 大连 116011)
Nutch搜索引擎的公安应用研究
肖萍1申亚鹏2
(1中国刑警学院辽宁沈阳110035;2大连市公安局西岗分局辽宁大连116011)
网络“爬虫”作为网络信息搜索的工具,在网络舆情管控、搜查中起着至关重要的作用。随着互联网的广泛普及,网络中不安全因素、不和谐因素日益增多,使用百度等商业搜索引擎已经不能满足日益增长的公安舆情信息监控工作需求。在介绍搜索引擎工作原理的基础上,详细分析了Nutch的工作机制,并与商业搜索引擎进行了比对分析,实验结果表明了商业搜索引擎在公安应用中的局限性,在特定的公安应用背景下,在搜索精度、结果排序方面,Nutch要优于商业搜索引擎。
搜索引擎Nutch网络舆情信息搜索
Nutch是Apache公司推出的一款用JAVA语言编写的支持分布式的开源网络爬虫软件,它提供了用户构建网络搜索引擎的全部工具。Nutch性能卓越,构建简易,功能强大。当下,海量的、复杂的舆情信息充斥在网络间,如何快速、精确地找到网络舆情信息是对公安工作的重大考验。基于Nutch网络爬虫可针对舆情信息频发的网站进行重点布控,精确查找。本文研究了Nutch网络爬虫的工作机制,通过实验比对Nutch与商业搜索引擎的性能,指出了Nutch在公安工作中的应用优越性。
1 搜索引擎工作原理
搜索引擎也称为“网络爬虫”,其核心任务是抓取网页,该过程复杂、多变。爬虫抓取过程总的来说,是依照“抓取——生产——更新”这一模式进行的。具体过程是:添加初始URL,爬虫程序访问并解析初始网页内容,同时更新Visited表;分离初始网页链接,保存初始网页内容,更新爬虫队列(初始URL不比对Visited表);继续访问爬虫队列中的URL,寻址、解析网页,更新Visited表;分离网站链接,比对Visited表。若网站链接已被访问,则过滤删除。否则,更新至爬虫队列中,进行下一循环。网络爬虫的抓取原理如图1所示。
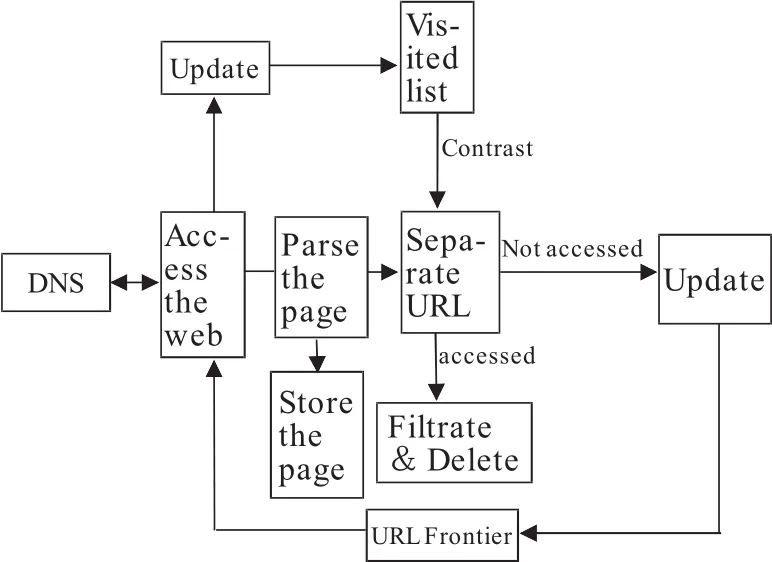
图1 网络爬虫抓取原理
网络爬虫原理由URL寻址,遍历互联网,爬虫队列,Visited表和网页更新策略五部分核心内容组成。
1.1URL寻址
URL(Uniform Resource Locator)是用于标识网络资源位置的标志。它由服务方式、主机地址和文件存储位置三部分组成。网络爬虫通过人工方式添加初始URL。而对初始URL的寻址则类似于浏览器访问网站,通过DNS服务器获取被访问主机IP地址以便进行下一步抓取。
1.2遍历互联网
如果把目标网站比作一个图,那么每一个页面即为图的节点,页面间的链接关系则为图的有向边。爬虫注入初始URL后,选择对网站的遍历方式至关重要,因为这直接影响到爬虫工作效率。爬虫通用网站遍历方式为宽度优先遍历,也叫层级遍历方式。这种遍历方式通过对网站的URL分层,按层顺序遍历。宽度优先遍历的优势在于其节省系统资源,易于封闭目标网站,形成重点布控区。
1.3爬虫队列
随着抓取的进行,成千上万的URL被解析出来。在爬虫程序中,通常使用队列数据结构来管理未被访问的URL。但受计算机内存容量的限制,直接以队列方式存储海量的URL不现实。通用方法是引入HASH算法。对URL进行md5计算,存储其散列值,降低对计算机内存的要求。在实际应用中,爬虫队列通常会构建一个优化机制,来微调爬虫队列中URL的排序,分离访问流量,避免爬虫程序对某一服务器造成过大访问压力。
1.4Visited表
Visited表用来存储已被访问的URL。爬虫程序在分离出网站链接之后,与Visited表比对,保存未被访问的URL,优化爬虫队列。构建Visited表的通用技术是BLOOM过滤器。BLOOM过滤器的工作原理如图2所示。

图2 BLOOM过滤器的工作原理
首先划分出存储块,块大小=16*N(N为URL个数)位。然后将块中的每个二进制位设置为0。对每一个URL通过随机数产生器1生成8位的指纹信息,以此来标识URL。然后再通过一个随机数产生器2将这8位指纹信息映射到存储块中,将映射位置的二进制位修改为1。当需要对URL进行比对时,只需查看这一URL对应的8位存储位置是否全部为1。若全为1,就表明该URL已被访问;否则,未被访问。BLOOM过滤器的这种工作原理保证其不会漏掉任何一个已访问的URL,但有一定概率误识未被访问的URL。因为有可能某一URL的地址对应的8位二进制恰好被设置为1。通用的解决方法是建立一张白名单,以此来标识被误识的URL。
1.5网页更新策略
互联网上的网页信息并非是一成不变的,而是随着用户的需求时刻更新。对于网络爬虫来说,不仅仅要抓取网页,而且也要随着互联网的更新而更新本地网页。通用的网页更新策略有:历史参考策略、用户体验策略和聚类抽样策略。
历史参考策略是建立在以往更新经验之上的一种更新策略。基本工作思路是:过去更新频繁的网页,未来也将频繁更新。该策略利用泊松过程来对网页的变化进行建模,根据网页过去的更新情况,来推测其未来的更新情况。
用户体验策略是建立在用户最为关心的特定网页上的更新策略。基本工作思路是:优先更新搜索结果排序靠前的网页。该策略根据过去每次内容变化对搜索质量的影响,通过建立数学模型,计算影响值。值高的网页,优先进行调度抓取。
聚类抽象策略认为:网页有一些属性,根据这些属性可以预测其更新周期,具有相似属性的网页,其更新周期也类似。该策略的优势在于不用依赖对网页的历史更新信息,减少系统负担。
2 主流开源搜索引擎
随着互联网信息量的激增,如何准确快速地搜索出网上热点舆情信息成为公安网络信息监控部门的迫切需求。由于百度等商业搜索引擎存在着付费和功能限制的弊端,不能很好准确地提供搜索结果,因此在实际公安工作中可以研究应用开源搜索引擎来定制个性化的公安搜索工具。目前主流的开源搜索引擎有以下几种。
2.1Sphider
Sphider是一个轻量级,采用PHP开发的web spider和搜索引擎,使用mysql来存储数据。Sphider非常小,易于安装和修改,已经有数千网站在使用它,它支持所有的标准搜索选项,还包括大量的如Word自动完成、拼写建议等选项,使系统易于管理,Sphider支持中文搜索,但对中文分词的效果不是很好。
2.2PhpDig
PhpDig是国外非常流行的垂直搜索引擎产品,采用PHP语言编写,使用Mysql来存储数据。利用了PHP程序运行的高效性,极大地提高了搜索反应速度,它可以像Google或者Baidu以及其他搜索引擎一样搜索互联网,搜索内容除了普通的网页外还包括.txt,.doc,.xls,.pdf等类型的文件,具有强大的内容搜索和文件解析功能,适用于专业化更强、层次更深的个性化搜索引擎,但是目前所有版本的PhpDig均不支持中文检索。
2.3Lucene
Lucene是Apache软件基金会Jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,即它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便地在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。其运算速度较快,在现在流行的硬件平台上每个小时可处理超过150GB的数据,并且内存占用小,只需1MB的堆内存。由于Lucene是由JAVA语言实现的,因此具有良好的兼容性。
2.4Nutch
Nutch是Apache基金会的一个开源项目,它原本是开源文件索引框架Lucene项目的一个子项目,后来渐渐发展为一个独立的开源项目。它基于Lucene框架,由JAVA语言实现,提供了搜索引擎所需的全部工具,包括全文搜索和Web爬虫。它具有以下主要特点:(1) 使用Plugin机制来提高可扩展性;(2)通过多协议和多线程分布式抓取,提供抓取效率;(3)具备可扩展的数据处理模型,全文索引器和搜索引擎;(4)支持分布式查询,具有强大的API接口和集成配置。
2.5Heritrix
Heritrix作为JAVA开源项目,是SourceForge上的开源产品,它提供了丰富的抓取设置选项,主要被用来获取完整的、精确的站点内容深度复制,包括获取图像以及其他非文本内容。Heritrix的体系结构是采用了多线程和链接队列的形式组织。整个系统的工作部分可以分成对配置文件管理部分、下载任务管理部分、下载控制部分和下载工作单元。附带的工作队列、缓冲区等的引入则为网络蜘蛛提供了良好的性能。Heritrix主要具有以下特点:(1)专注的网络信息下载功能;(2)适用于各种类型网页信息并严格保持网页原貌;(3)在保留历史的下载网页库内容基础上不断地添加新的下载内容;(4)以任务形式管理并提供命令行和友好的Web控制界面。
3 Nutch搜索引擎研究
对目前主流的几款开源搜索引擎进行了比较分析发现,Sphider及PhpDig搜索引擎均是使用mysql数据库来存储数据,对数据的存储能力有限,而且不能很好地支持中文检索,另外考虑到Lucene不是一个完整的全文检索引擎,仅仅是一个工具包,而且相对于Heritrix来说,Nutch具有集群扩展能力,并具备多种功能,包括内容索引功能、搜索功能、内容解析、链接解析等,因此本文选择Nutch作为应用研究对象,其运行原理如图3所示。
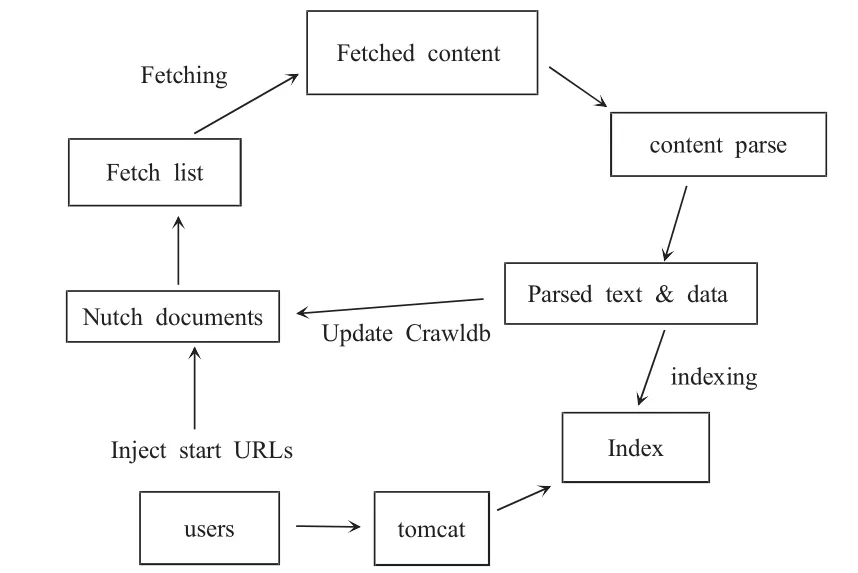
图3 Nutch网络爬虫运行原理
注入初始url,启动爬虫程序;抓取指定网页,解析网页内容,更新Nutch文件;待抓取全部完毕后,为抓取内容建立索引。用户进入Nutch服务界面,键入关键字,检索索引文件,返回结果。
由于Nutch网络爬虫提供给用户构建搜索引擎的全部工具,所以其不仅仅包含网页抓取功能,还包含信息索引功能和关键字检索功能。
Nutch网络爬虫的存储文件共有五个,分别是Crawldb,Linkdb,Indexes,Index和Segments。
(1)Crawldb文件夹用来存储爬虫爬取的url。
(2)Linkdb文件夹用来存储网页间的链接信息。
(3)Segments文件夹是Nutch的核心文件,其中有若干个以时间命名的文件夹,每个文件夹是爬虫抓取的一次循环。用于存储爬虫抓取来的网页内容、预抓取URL等信息。每个段都有一个完整的子索引。
(4)Index文件夹用来存储Nutch的索引文件。该文件不是直接通过网页内容建立索引,而是合并众多子索引文件来实现。
(5)Indexes文件夹用于存储子索引。
Nutch网络爬虫工作机制分为三部分,分别是抓取部分、索引部分及检索部分。
3.1抓取部分
Nutch网络爬虫在抓取部分的主要任务是获取网页,其依照“抓取——生产——更新”这一循环进行的。
在爬虫抓取的过程中,Nutch生成Crawldb、Linkdb和Segments文件夹。在Segments文件夹中,共存储六类文件,Crawl_generate存储待抓取的URL;Crawl_fetch存储每个下载URL的状态;Content存储抓取网页的内容;Parse_text存储抓取URL的文本信息;Parse data存储每个 URL的外连接;Crawl parse存储用来更新Crawldb的URL集。
3.2索引部分
Nutch网络爬虫的抓取部分与检索部分通过索引部分连接。因此,索引部分是Nutch网络爬虫的关键技术。
在Nutch的工作流程中,索引阶段负责对网页重要度评测、抓取网页分析和构建逆向索引表。
3.2.1PageRank算法
PageRank算法是由Google的创始人Larry Page和Sergey Brin于1998年提出的一种网页重要度排序算法。该算法的基本思路是“被大量网页所链接的网页必然是优质网页”。PageRank值表明用户访问某一网站的概率。这就需要基于用户随机从互联网上任意一个网页开始访问互联网这样一个前提。
Nutch自身并没有实现PageRank算法,而是通过构建Hadoop集群来实现。大量实验证明,Nutch实现PageRank算法,可提高系统的检索效率,更好地为用户提供检索服务。
计算网页PageRank值的公式定义为

其中,P(A)表示网页A的PageRank值;P(Ti)为链接指向网页A的网页Ti的PageRank值;C(Ti)为网页Ti的外连接总数;d为阻尼系数,Google推荐d值为0.85。
Google的研究表明,进行大约100次的迭代运算能估计出整个互联网中任意一个网页的PageRank值。
网页PageRank值可作为一个独立的索引项添加到倒排索引文件中,优化Nutch检索结果排序。
3.2.2Luence工具包
Nutch检索阶段构建索引表,主要依赖Luence完成。Luence构建索引的对象是文本文件。这就要求必须对Nutch抓取到的网页进行预处理,把网页内容转换为文本格式。
Luence的最终目的是构建索引表,为用户提供查询服务。索引表是由文档(Document),域(Field)和项(Term)组成。索引表存储结构类似关系数据库,项是组成索引表的最小单位,若干项组成一组

其中,P(X,Y)表示字X与字Y相邻的概率。P(X)标识字X出现的频率;P(Y)标识字Y出现的频率。当M(X,Y)的值高于某一阀值时,字X与Y被定义为一个词。
实际应用中,是把此两种分词法结合起来。用字符串分词法划分简单,常用词汇,同时结合统计分析法提取新词汇。这样既继承了字符串分词法效率高的特点,又结合了统计分词法灵活的特点,明显提高分词器的工作效率。
(3)逆向索引。逆向索引技术,又称倒排索引技术。是当前搜索引擎应用最普遍的技术之一。可以说,正是它的出现,搜索引擎才得以发展到如今的规模。逆向索引技术原理如图4所示。
.fnm文件、.tis文件、.frq文件及.prx文件是构建逆向索引表的关键文件,存储在index文件夹中。其域,若干组域组成一个文档。
Luence构建索引的过程总共分为三步:第一,网页内容分析;第二,中文分词;第三,构建逆向索引表。
(1)网页内容分析。网页内容分析是将Nutch抓取来的网页去除广告信息等无用内容,分析网页结构,将网页内容转换为文本文件,为Luence提供索引对象。
通用网页分析方法有简单语言标记法,正则式信息抽取法和DOM内容抽取法。其中简单言语标记法,主要是根据HTML语言的特点,通过简单程序的遍历,删除所有被标记出来的信息;正则式信息抽取法,通过事先定义好的规则和模块快速提取网页中符合要求的信息。这种方式效率高,但抽取的精度低,对于一些特殊网页效果不好;DOM树内容抽取法是把原始网页内容转换成树形结构储存,这样就可以灵活获取网页任何内容。
(2)中文分词。中文分词是将已经文本化的网页文件以项为单位划分,为下一步的建立索引表提供语素。中文分词过程包括整句划分切割,词提取,标点符号去除,连接词语去除等
目前通用自动分词方法有两种:基于字符串的分词法和基于统计的分词法。
基于字符串的分词法,它是按照一定的策略,将汉字字符串与一个“词典”进行比对,提取信息。该方法分词效率高,但分词过程机械,死板。
基于统计的分析法,是根据统计学原理,将出现频率高的相邻字视为一个词。其计算公式为中.fnm文件维护索引表的域名(Field name)信息。Luence为域名信息提供两种选用功能:Indexed和Stored。Indexed功能标注该域名信息是否被索引。Stored功能标注每个field索引的内容是否被存储在索引文件中,通常大量索引文件存储在Segments文件夹中;.tis文件维护一张域(Field)信息表。该表存储所有域名称,值以及出现该值的文档数量(Doc frequency);.frq文件列出了Luence文档中出现任意项的次数;.prx文件展现了每一项在文档中的具体位置,便于精确查找。

图4 逆向索引表
逆向索引技术对文档中的每一项(Term)建立索引库,详细标明项在文件中出现次数以及位置。当用户键入关键字进行搜索时,Nutch可根据事先建立的索引表,迅速找到关键字的位置,提高Nutch的检索效率。
3.3检索部分
检索部分主要是为用户提供查询服务。Nutch根据建立的索引表来完成此功能。这一部分是由Luence完成。
设D={t1,t2,…,tn} 为系统记录的项,集合P={p1,p2,…,pn}为系统当前网页集合。系统的索引表示为集合R={<t,p>|r(t,p)>0,(t,p)∈D×P}。其中,r(t, p)是项与网页的相关度函数,若r>0,表示项与网页相关;若r=0,表示项与网页无关。搜索引擎S={<t, p,r>|r(t,p,r)>0,(t,p,r)∈D×P×R}。检索关键字T函数φ(T,S)={p|(t,p)∈R,p∈P}。由上可知,检索部分是将关键字T与索引表通过r(t,p)函数相关联,最后返回网页p。
Lunece对检索部分的优化在于初次索引时,并不是返回所有符合函数r(t,p)的p值,而是将r值最高的头100项返回。对于一般的模糊检索,头100天记录已经可以满足90%以上的检索需求。
4 Nutch搜索引擎公安应用研究
目前公安机关网监部门对网络监管手段还比较单一,大多是依赖商业搜索引擎来实施信息搜索和查询。由于商业搜索引擎是根据用户缴费情况来返回搜索结果,掺杂了各种推广链接,制约了公安舆情监控工作的发展。因此在公安机关网监部门普及应用个性化搜索引擎是势在必行的,尤其是在公安队伍信息化大发展的今天。本小节通过实验来验证应用Nutch搜索引擎在公安工作中的优越性。
本实验应用对比:Nutch爬虫和百度搜索引擎。应用目标:通过百度搜索引擎和Nutch网络爬虫找到诈骗信息。Nutch网络爬虫配置所需软件如表1所示。

表1 Nutch配置所需软件
4.1Nutch搜索引擎测试
本实验将Nutch的抓取线程设为5,抓取深度为4,开始对目标网站进行网页抓取。打开Nutch用户界面,输入关键字“辽宁家园论坛和风瑜”,“辽宁家园论坛二手车和风瑜”。搜索部分结果如图5和图6所示
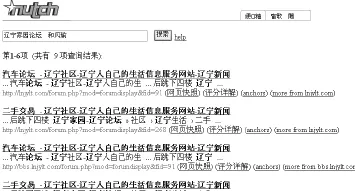
图5 Nutch网络爬虫搜索结果(一)

图6 Nutch网络爬虫搜索结果(二)
实验中Nutch搜索结果共18条记录(每组搜索结果各9条)。这18条结果实则是2条URL的重复出现,分别是 http://lnjylt.com/forum.php? mod=forumdisplay&fid=91及http://lnjylt.com/forum.php? mod=forumdisplay&fid=268。这两条URL分别是辽宁家园论坛中“汽车论坛”和“二手交易”频道。在其中可直接找到目标信息。
在Nutch搜索结果中,当中出现“二手车”字样时,“二手交易”频道排在首位;否则,“汽车论坛”频道排在首位。因此Nutch的排序结果更能满足用户需求。
4.2百度搜索引擎测试
打开百度搜索引擎,输入“辽宁家园论坛和风瑜site:www.lnjylt.com”及“辽宁家园论坛二手车和风瑜site:www.lnjylt.com”进行搜索,其中第一组搜索结果4条,第二组搜索结果0条。逐个打开第一组搜索结果,都不能直接找到目标信息,搜索精度为0。
若不指定目标搜索网站,仅使用“辽宁家园论坛和风瑜”及“辽宁家园论坛二手车和风瑜”进行搜索,则搜索结果多达数百万条,在搜索结果中,对于用户来说很难快速准确找到目标网页。
从搜索结果看,百度搜索引擎总是能定位到信息的大概位置,但是不精确到具体的位置。尤其是在论坛中,大量的帖子、留言充斥着整个网站,信息量如此之大,仅仅是找到信息的大概位置而不是精确位置是远远不够的。同时,在百度搜索结果中,往往是“百度推广”信息被排在前边,而用户真正需要的结果却被排到后边,进一步地暴露了商业搜索引擎的应用局限性。
4.3Nutch搜索引擎在公安工作中的优势
在搜索结果、搜索精度、结果排序方面将Nutch与百度的搜索能力比对,结果如表2所示。
从实验对比结果中可看出在搜索精度、结果排序方面Nutch要优于百度等商业搜索引擎,商业搜索引擎由于其技术内幕隐秘、非公开,并且搜索结果也是具有商业性质的,因此难以满足公安工作需求。在特定的公安应用背景下,相对于百度等商业搜索引擎来说,Nutch能够更高效准确地完成搜索任务。
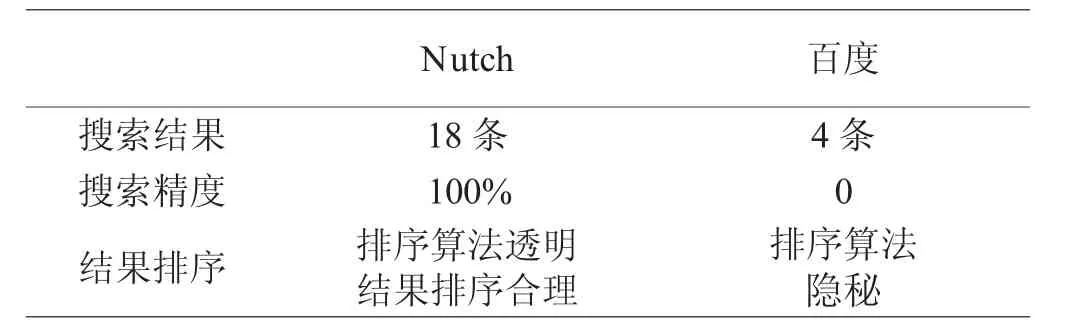
表2 实验比对结果
5 结束语
本文在分析Nutch工作机制且在实验验证的前提下,总结出Nutch较之百度等商业搜索引擎的优势,但通过实验也看出Nutch的每组关键字搜索结果为9条,实际都指向2条链接,重复度较高,未来可以对Nutch的检索模块进行优化,减少搜索结果的重复度。另外,在实际公安工作应用中,可建立热点舆情数据库,应用Nutch实时过滤区域信息,查询舆情热点,提高公安舆情信息监控工作效率。
[1]罗刚,王振东.自己动手写网络爬虫[M].北京:清华大学出版社,2010.
[2]张俊林.这就是搜索引擎核心技术详解[M].北京:电子工业大学出版社,2012.
[3]黄德才,威化春.PageRank算法研究[J].计算机工程,2006,32(4).
[4]Brin S,Page L.The anatomy of a large-scale hypertextual Web search engine[J].Computer Network and ISDN Systems,1998,30.
[5]童威.基于Nutch框架下的中小型网络开源搜索引擎的研究与应用[D].贵州:贵州大学,2010.
[6]何世林.基于Java技术的搜索引擎研究与实现[D].四川:西南交通大学,2006.
[7]龚磊,武友新.Lucene全文搜索系统的研究与实现[J].计算机与数学工程,2010.
[8]李晓明,闫宏飞,王继民.搜索引擎—原理、技术与系统[M].北京:科学出版社,2005.
(责任编辑:孟凡骞)
TP391.1
A
2095-7939(2015)01-0039-06
2014-11-10
公安部公安理论及软科学研究项目(编号:2012LLYJXJXY052);辽宁省教育科学“十二五”规划立项课题(编号:JG14db440)。
作简简介:肖萍(1978-),女,黑龙江鸡西人,中国刑警学院网络犯罪侦查系讲师,硕士,主要从事网络安全、信息监控研究。
猜你喜欢
房地产导刊(2022年10期)2022-10-18
现代信息科技(2021年21期)2021-05-07
成都信息工程大学学报(2021年6期)2021-02-12
疯狂英语·新阅版(2020年11期)2020-12-21
电子制作(2018年10期)2018-08-04
魅力中国(2018年5期)2018-07-30
电子制作(2018年2期)2018-04-18
电子制作(2017年2期)2017-05-17
电子制作(2017年9期)2017-04-17
中国卫生(2015年12期)2015-11-10
