
一种古建墙壁受污题记文字图像边缘提取方法
2015-12-05 07:31:57刘英杰杨风暴吉琳娜原惠峰
图学学报 2015年5期
刘英杰, 杨风暴, 吉琳娜, 原惠峰
(中北大学信息与通信工程学院,山西 太原 030051)
一种古建墙壁受污题记文字图像边缘提取方法
刘英杰, 杨风暴, 吉琳娜, 原惠峰
(中北大学信息与通信工程学院,山西 太原 030051)
针对古建墙壁题记文字图像受污染影响而边缘提取不完整、易产生伪边缘和不连续边缘等问题,提出了一种受污题记文字边缘提取的方法。首先,对文字图像进行全变分去噪和多尺度视网膜算法明暗增强预处理;然后构造阴影-遮挡准不变模型滤除污染和背景产生的伪边缘,并用Gabor滤波器对其进行空间平均,建立颜色结构张量,结合Canny算法进行边缘提取;最后,通过形态学方法滤除图像中存在的小面积边缘,并做区域连通处理,得到题记文字边缘图像。实验结果表明,相比传统的Canny算法和Sobel算法,该方法有效地克服了污垢和背景造成的伪边缘和不连续边缘,很好地提取出了完整的题记文字边缘,在边缘品质EQ等客观指标上有较明显提升。
题记文字;伪边缘;全变分;颜色结构张量
古建墙壁题记多为古人毛笔书法精髓,承载着大量历史信息,同时也是我国书法的活标本,具有审美和历史研究价值。然而由于长期的风化,墨迹易受菌类的污染,霉变严重,加之墙壁自身的腐蚀和老化质变,许多字迹无法辨识,人工实体修复在去除污染的同时易造成原有字迹的再次破坏。所以,依靠数字处理技术对文字图像进行去污和边缘提取,一方面有助于文字的辨识,另一方面对于研究和欣赏其书法笔画意义重大。山西晋祠内八景题记作为此类文字的典范,受污严重,字迹不易辨识,其字体的去污和恢复工作受到了文物界的关注。
目前,针对文字图像的边缘提取技术有基于数学形态学[1]、变换域[2]和梯度算子[3]等方法。文献[4]对数学形态学方法进行改进,通过对边缘区域进行模糊增强处理提高了形态学边缘提取的完整性,但对于图像中污染和真实边缘的识别性不高,伪边缘较多;文献[5]将数学形态学方法和小波变换模极大方法进行融合使用,提取边缘较完整,且对高斯噪声有较好的鲁棒性,但当污染严重影响目标边缘时,提取效果不好;文献[6]提出多阈值Kirsch算法,并通过连接算法对弱边缘进行连接,边缘连贯性和完整性较好,但对伪边缘滤除效果不佳;文献[7]通过遗传算法控制Canny算子的阈值选取,边缘检测更准确,细节保留较好,但没有克服Canny算子本身的噪声敏感性;文献[8]将二维图像转换为8个方向子图,再对每个方向子图进行Canny算子检测,较好地抑制了噪声干扰,但仍然存在较多伪边缘。上述方法从各方面对边缘提取技术进行了改进,对于污染较少、背景单一的图像提取效果较好,但当污染严重影响目标边缘信息时,检测出的边缘或不够完整或含有较多伪边缘和不连续边缘。
针对上述问题,本文提出了一种基于光照模型和形态学的受污题记文字边缘提取方法,通过预处理去除细小噪声,突出暗区域细节;通过阴影-遮挡准不变模型和改进的Canny算子滤除污染带来的伪边缘;通过形态学和区域连通处理滤除杂边,连接边缘,保证了文字边缘的完整性和连贯性。本文方法的处理流程如图1所示。
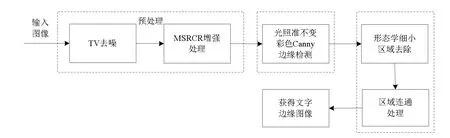
图1 本文方法处理流程图
1 基本原理
1.1 光照准不变量
场景目标的边缘提取往往受到背景信息的干扰,由阴影、遮挡或污染产生大量虚假边缘,Van de Weijer等[9]提出的照度准不变模型很好地解决了这些问题,Shafer[10]认为表面光滑的图像可以看作镜面反射和体反射的加和,如式(1):
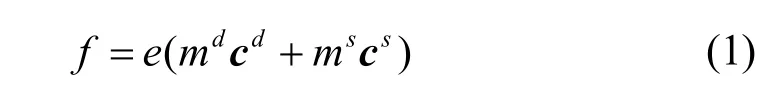
式中,e为光源的能量, cd和 cs分别为体反射和镜面反射的颜色向量,md和ms为其相应的加权幅值通过对上述模型求导,得到空间微分式[11]如下:空间微分式可以看作图像3种边缘的加权和,emd为物质边缘,为阴影和遮挡形成的边缘,为镜面反射边缘。
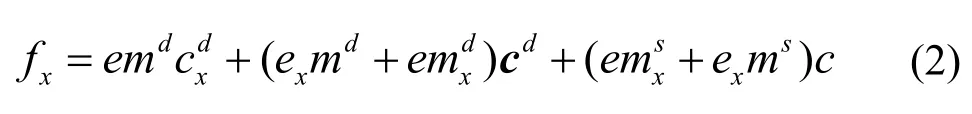
表面粗糙的图像,镜面反射不存在,阴影-遮挡边缘方向和图像的颜色方向一致[12],此时,由阴影-遮挡形成的边缘Sx可以表示为:
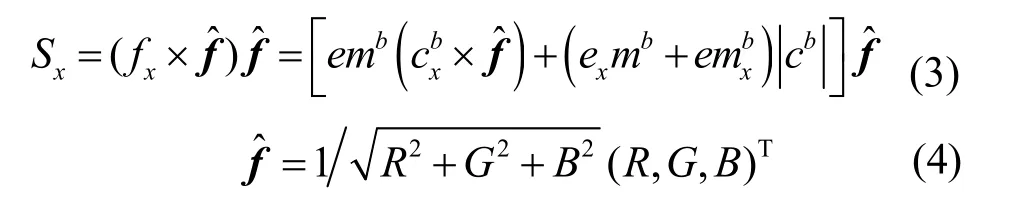

1.2 颜色结构张量
彩色图像在计算梯度时,一般将其转换为灰度图像进行处理,而彩色图像各颜色通道之间存在很大相关性,直接灰度化处理会造成图像信息的丢失,对此Van de Weijer 和Gevers[13]提出了颜色结构张量。RGB彩色图像可表示为 f =(fR,fG,fB)T形式,则其结构张量定义为:
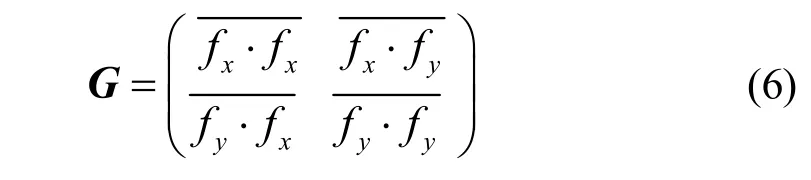
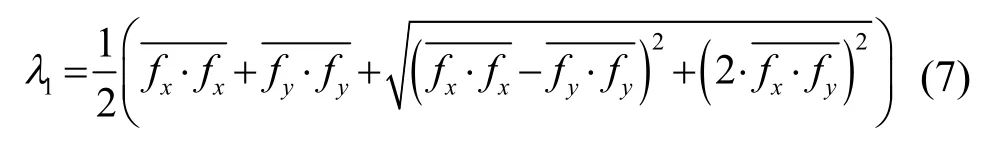
2 预处理
2.1 TV去噪处理
采集的文字图像有许多随机噪声干扰,需要对其进行去噪处理,常用的去噪算法在去除噪声的同时易造成图像高频信息的平滑,不利于后续的文字边缘提取。本文通过全变分(total variation, TV)模型对图像去噪处理,TV模型在去噪时引入偏微分各项异性扩散方程,能较好地控制平滑区域和边缘区域的扩散速度,从而实现抑制噪声的同时对图像高频信息的保护,本文使用的TV去噪模型如下:
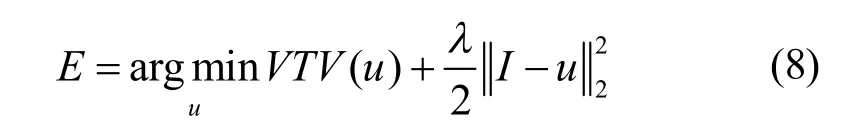
式中,E为能量泛函,I为采集图像,u为去噪图像,VTV(u)为正则项,实现噪声抑制和边缘保护,为保真项,控制去噪图像的偏离程度,VTV为彩色全变分,定义如下:
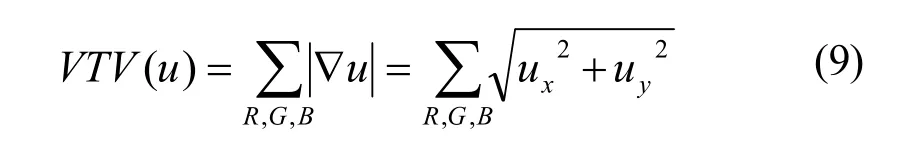
2.2 MSRCR算法增强处理
由于污染和书写材质的影响,去噪之后的图像中仍存在较多的暗区域,这些区域含有大量文字细节信息,本文利用多尺度视网膜增强算法(multi-scale retinex with color restoration, MSRCR)对其进行增强处理。MSRCR算法是由Land提出的Retinex模型发展而来,能显著提高图像暗区域细节,同时对图像彩色像素有较好地恢复效果,利于图像背景和目标的对比度调节。算法主要模拟人类视觉成像原理,去除图像的照度分量来获取反映图像本质信息的反射分量,以还原物体的本来面貌,通过式(10)可以得到反射分量图像,为提高效率,本文将各量转换为对数形式进行迭代运算。
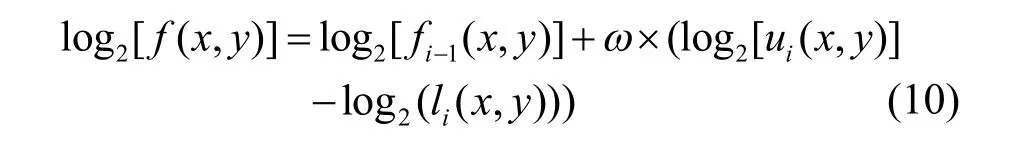
式中,ui(x,y)为第i尺度的去噪图像,li(x,y)代表照度分量,通过对图像进行高斯模糊得到,本文令li= Gσ* ui,Gσ为高斯函数,高斯核取5, f(x,y)代表反射分量,携带图像细节信息,ω为各尺度权重系数,本文取等权重,增强处理结果如图2(c)所示。
3 基于阴影-遮挡准不变的 Canny彩色边缘检测
经过增强的题记图像有许多污垢,对毛笔文字的边缘提取产生干扰。Canny算子在图像边缘检测中应用广泛,检测效果较好,但当图像背景信息较暗或较为复杂时,很容易将目标和背景混淆,使得检测出的边缘往往含有较多伪边缘和不连续边缘,本文利用上节提到的光照准不变量建立文字图像的阴影-遮挡准不变模型,该模型可以排除遮挡、污垢带来的虚假边缘,仅保留图像中文字的边缘,需结合结构张量和Canny算法对图像进行边缘检测。由上节分析可知,结构张量中空间微分经过高斯滤波平均得到,传递信息的同时易造成图像边缘的模糊化,给边缘检测带来困难,本文引入具有方向调节的gabor滤波器代替高斯滤波,一方面通过角度调节可以控制高斯滤波的方向,另一方面其角度调节因子对图像边缘信息有一定的提取作用,本文gabor滤波器设计如下:
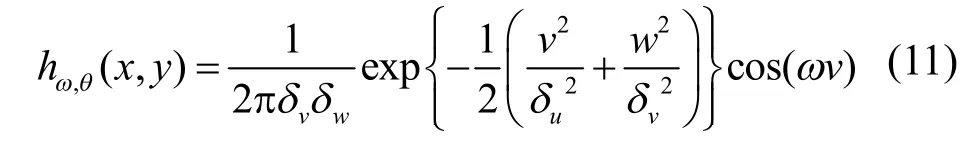
式中, v =x c osθ + ysinθ, w =- y s in θ + xcosθ,θ为滤波器方向,为抑制边缘模糊,本文取为文字边缘的等照度方向,ω为调制频率,本文根据文字图像纹理特点,令ω=0.3。用gabor算子代替高斯函数进行结构张量的计算,得到新的结构张量计算公式:表示用gabor滤波器对进行空间平均,具体处理步骤如下:
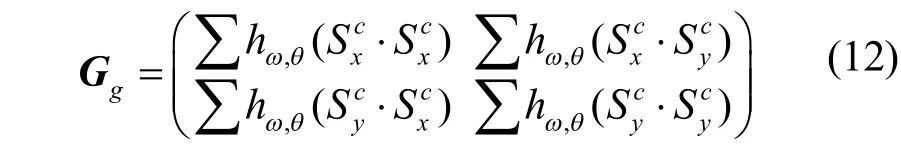
(1) 根据式(5)建立文字图像的阴影-遮挡准不变模型;
(2) 计算增强图像各点梯度方向和照度方向,将照度方向作为gabor滤波器角度调节方向,可用gabor滤波器对阴影-遮挡准不变量进行滤波和空间平均;
(3) 将步骤(2)处理结果带入结构张量式(6)中,得到新的结构张量式(12),结合式(7)计算结构张量的主特征值λ1;
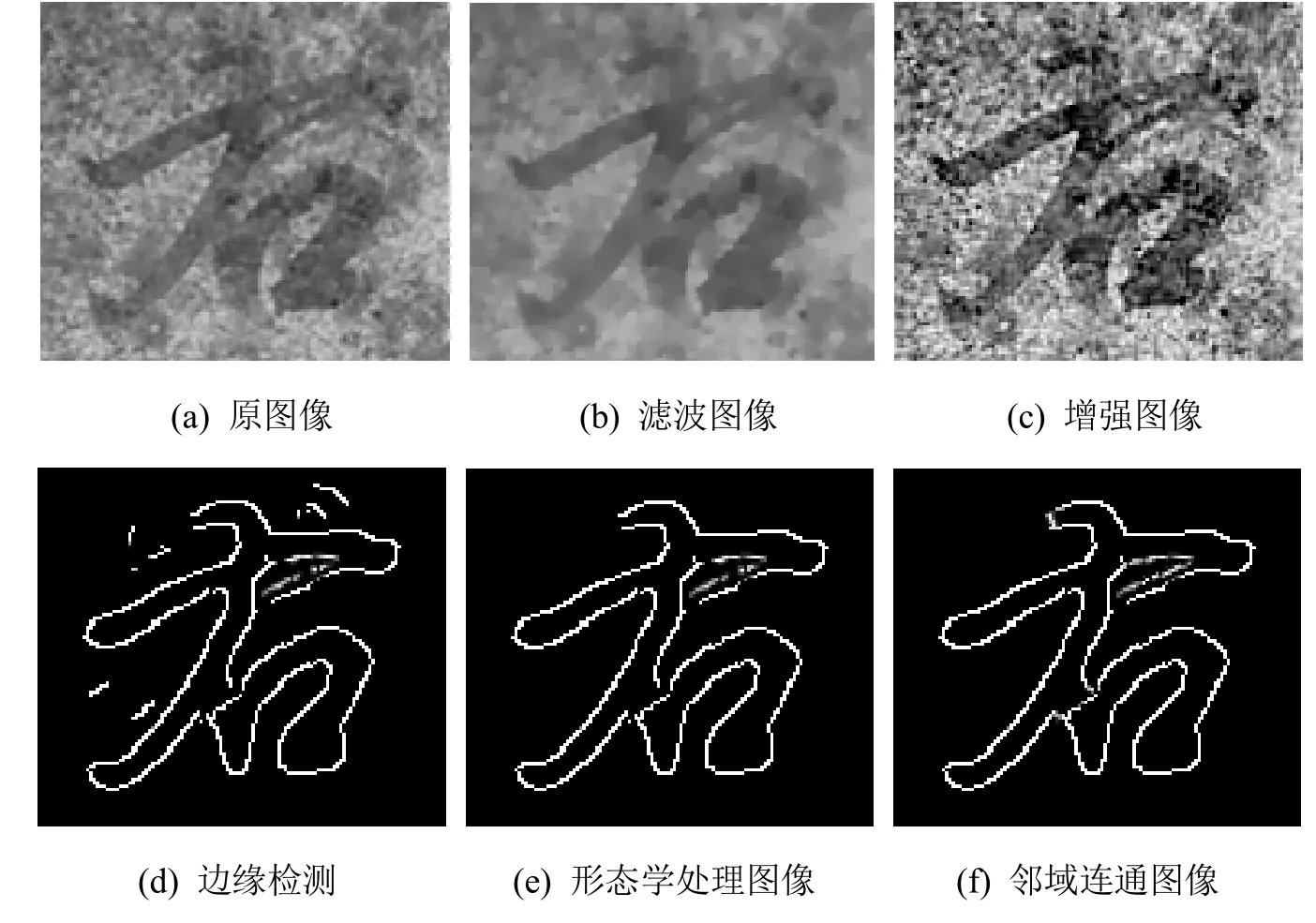
图2 本文方法边缘提取具体过程
4 形态学处理和邻域连通
得到的边缘图像在文字区域附近有一些细小的背景边缘,影响对文字笔画的提取,本文通过形态学方法对这些小区域进行滤除。首先,对图像各连通区域进行标记,相邻的灰度值为1的各像素点组成标记区域,并统计每一标记区域像素点数目作为该区域面积;然后设定阈值对标记区域过滤,滤去面积小于给定阈值的连通域;最后,对图像进行形态学开运算,以进一步去除细小区域。形态学开运算是对图像进行先腐蚀后膨胀的过程,腐蚀运算可以去除图像中的小面积区域,膨胀运算可以连通邻近区域,本文用半径为3的结构因子对图像进行开运算,处理结果如图2(e)。
从图2(e)可以看出,由于噪声和污染的影响,形态学处理后图像的文字边缘仍存在许多不连续线条,影响文字笔画的连贯性和完整性,本文通过邻域连通处理对这些线条进行连接。具体步骤为:以每一个像素点为中心,考察其八邻域像素点的灰度值情况,如果在其邻域中存在灰度值不为零的像素点,则认为两像素点为一对不连续边缘点,将两者连接,邻域连通结果如图2(f)。
5 实验结果与分析
为验证本文方法的效果,在奔腾双核2.10 GHz处理器的PC机上,以matlab2012a为平台进行仿真测试,并与传统的Canny算法和Sobel算法进行对比,仿真实验中所选图像均为山西晋祠内八景题记图像,为充分验证本文方法的有效性和适用性,根据文字的污染程度,将获取的图像分为 5级,如表1所示,本文主要对后3级文字图像进行实验研究,处理结果如图3~5所示。

表1 文字图像级别划分
由图3可看出,对于第3级文字图像,本文方法相比传统Canny算法和Sobel算法有更好地提取效果,很好地抑制了伪边缘和不连续边缘,文字完整性较好;由图4可看出,对于第4级文字图像,本文方法提取效果显著,对污染和噪声的鲁棒性较好;由图5可看出,对于第5级文字图像,本文方法能有效地识别出文字和霉变污染,边缘提取准确、完整,提取效果较好。
为定量分析图像边缘检测效果,本文用边缘品质EQ对其进行客观评价,EQ定义如式(13):

其中,Ec为图像细小边缘数,用来表征边缘图像中伪边缘的数量;Rm为最大连通域面积,用来表征边缘图像中目标的完整性。对 Canny算法、Sobel算法和本文方法处理结果的客观评价如表2所示。

图3 第3级文字图像提取结果对比

图4 第4级文字图像提取结果对比

图5 第5级文字图像提取结果对比

表2 Canny算法、Sobel算法和本文方法客观指标对比表
由表2可看出,相比其他方法,本文方法的Ec较小,Rm较大,边缘品质EQ高,结果表明其在伪边缘去除和文字边缘的完整性上都有较明显的提升。通过主客观分析可知,本文方法对于各种污染程度的文字图像都有较好的提取效果,能有效克服污染对文字边缘的干扰,准确识别出文字边缘和伪边缘,且提取边缘的完整性和连续性较好。
6 总 结
针对受污染和背景影响的古建墙壁题记文字边缘提取不完整,易产生伪边缘和不连续边缘等问题,本文提出了一种通过光照模型和形态学方法抑制污染、提取边缘的新方法。该方法的优点在于:①通过预处理提高了算法鲁棒性,并突出了文字暗区域细节信息;②结合光照模型,改进了Canny算子,能较好地识别出伪边缘和文字边缘;③对边缘图像进行了进一步处理,保证了边缘的连贯性和完整性。实验结果表明,本文方法对于各种污染程度的古建题记文字边缘均有较好的提取效果,鲁棒性好、准确率高,与传统Canny算法和Sobel算法相比,在检测效果上有明显提升。
(致谢:感谢山西省晋祠博物院李晋芳和赵涛两位专家为本文研究提供了相关支持。)
[1] 王金凤, 焦斌亮. 基于数学形态学的彩色图像边缘检测[J]. 工程图学学报, 2011, 32(6): 43-46.
[2] Li Jing, Lei Zhiyong. Adaptive thresholds edge detection for defective parts images based on wavelet transform [C]// 2011 International Conference on Electric Information and Control Engineering. Wuhan, China, 2011: 1134-1137.
[3] 刘 勇, 姚 刚, 肖人彬, 等. 自适应多窗口梯度幅值边缘检测算法[J]. 华中科技大学学报, 2011, 39(1): 14-18.
[4] 乔闹生, 邹北骥, 邓 磊, 等. 一种基于图像融合的含噪图像边缘检测方法[J]. 光电子·激 光, 2012, 23(11): 2215-2220.
[5] 黄海龙, 王 宏, 纪 俐. 基于局部模糊增强的顺序形态学边缘检测算法[J]. 仪器仪表学报, 2012, 33(11): 2608-2614.
[6] 朱晓临, 邓祥龙, 胡德敏. 多阈值选取与边缘连接的边缘检测算法[J]. 图学学报, 2012, 33(2): 72-76.
[7] 董 昱, 高云波, 刘 翔. 改进的遗传算法在Canny算子阈值选取中的应用[J]. 兰州交通大学学报, 2014, 33(6): 1-5.
[8] Shanmugavadivu P, Kumar A. Modified eight-directional canny for robust edge detection [C]//International Conference on Contemporary Computing and Informatics (IC3I). Mysor, India, 2014: 751-756.
[9] Van de Weijer J, Gevers T, Geusebroek J M. Edge and corner detection by photometric quasi-invariants [J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2005, 27(4): 625-630.
[10] Shafer S. Using color to separate reflection components [J]. Color Research and Application, 1985, 10(4): 210-218.
[11] 丁 文, 李 勃, 陈启美. Canny色彩边缘检测及分类新方法[J]. 北京邮电大学学报, 2012, 35(1): 115-119.
[12] 余成文, 郭 雷, 李晖晖. 基于改进颜色张量的照度不变轮廓检测[J]. 西北工业大学学报, 2007, 25(6): 814-819.
[13] Van de Weijer J, Gevers T. Tensor based feature detection for color images [C]//Proceedings 12th Color Imaging Conference: Color Science and Engineering Systems. Scottsdale, AZ, USA, 2004: 100-105.
An Edge Extraction Method for Polluted Text Image of Ancient Inscription Wall
Liu Yingjie, Yang Fengbao, Ji Linna, Yuan Huifeng
(Information and Communication Engineering College, North University of China, Taiyuan Shanxi 030051, China)
On the issue that inscription text image of the ancient wall is contaminated leading to its edge extraction is not complete, easy to produce false edge and discontinuous margin, this paper proposes a novel method of edge extraction from polluted inscription text. Firstly, text image for total variation denoising and multi-scale retinal algorithm shading to enhance preprocessing is used. Then construct a shadow-blocking quasi-invariant model filtering out pollution and pseudo-edge generated by background. Meanwhile, use Gabor filter to do spatial averaging and establish color structure tensor combined with Canny algorithm to do edge detection. Finally, filter small area edge existing in the image by morphological method and do the regional connectivity to obtain the edge inscription text image. The results show that, compared to traditional Canny algorithm and morphological method, this method effectively overcomes the false edge and discontinuous edge caused by dirt and background which makes good extraction of edge inscription from the full text and a more objective indicators such that edge quality has improved significantly.
inscription text; false edge; total variation; color structure tensor
TP 391
A
2095-302X(2015)05-0783-06
2015-04-16;定稿日期:2015-05-31
山西省自然科学基金资助项目(2013011017-4)
刘英杰(1989-),男,山西大同人,硕士研究生。主要研究方向为文物图像数字化处理。E-mail:1197430107@qq.com
杨风暴(1968-),男,山西临汾人,教授,博士,博士生导师。主要研究方向为红外信息处理。E-mail:55849613@qq.com
猜你喜欢
中国书法(2023年5期)2023-09-06 10:00:45
数学物理学报(2021年1期)2021-03-29 03:13:38
五邑大学学报(自然科学版)(2020年4期)2020-12-09 06:28:48
杭州师范大学学报(社会科学版)(2020年5期)2020-10-19 09:31:42
东方考古(2019年0期)2019-11-16 00:46:02
山西大同大学学报(自然科学版)(2016年2期)2016-12-12 03:19:27
中国继续医学教育(2015年2期)2016-01-06 01:36:16
振动、测试与诊断(2014年6期)2014-03-01 01:14:50
河南科技(2014年19期)2014-02-27 14:15:33
现代检验医学杂志(2014年1期)2014-02-06 01:29:31
