
基于水利对象分类标签的分面推荐方法研究
2015-11-25 02:59杜丙帅李士进唐志贤孔盛球
计算机与现代化 2015年12期
杜丙帅,李士进,冯 钧,唐志贤,孔盛球
(河海大学计算机与信息学院,江苏 南京 211100)
0 引言
随着计算机技术的发展与普及,以及以物联网、云计算、移动互联网和RS 等技术为基础的智慧水利规划的实施,水利领域迎来了数据的爆炸式增长。国家基础地理资源中心水利资源数据分中心建设的8个专题库,以及第一次全国水利普查的成果库都极大地丰富了水利行业的大数据集[1]。由于水利数据资源具有多点采集、分散处理、独立异构的特点,致使其服务目标单一、利用率低下,资源共享问题突出,如何高效地管理和有效地利用这些宝贵的数据资源,成为水利行业关注的主要问题。
为了实现信息化资源的共建共享和深度开发利用,水利部水利信息中心提出了水利数据资源整合与共享方案,期望通过规范化的数据资源管理实现各级水利部门之间、各应用系统之间的数据交换与共享,满足不同用户对于水利信息资源的需求,为水行政管理提供丰富的信息资源服务和决策支持。通过对水利业务和基础数据的梳理,构建了统一的数据模型,为实现上述目标奠定了基础。
在水利数据资源的整合与共享平台建设过程中,提供数据资源发现和定位服务的信息资源目录体系是数据资源共享的基础。对于水利领域的专业用户,他们确切地知道自己所需要的数据资源是什么,由关键字检索即可实现这些数据资源的查询访问。随着计算机技术的普及,水利数据资源不仅仅为水利领域专业用户服务,社会上的普通群众和企业需要对水利数据资源进行发现,而这些普通用户,其检索意图往往并不明确,他们需要的是探索式的检索,需要系统对其进行引导,此时关键字检索,甚至是高级检索便无法满足这种需求。本文将分面检索技术引入水利数据资源的整合与共享平台,实现了导航式的检索服务,提高了检索效率,提升了用户体验。
与此同时,不同用户可能需要发掘不同维度的水利数据,例如,水利业务单位需要从业务角度分析水利数据,水利数据管理单位需要从管理机构角度对水利数据进行管理,而普通用户可能只是从相关领域对水利数据进行查询。为了满足不同用户的不同需求,本文基于水利对象对水利数据资源分类打标签,对于同一类型的水利数据资源从不同维度对其进行聚类,满足不同用户的查询需求。
1 分面检索技术
分面检索[2](Faceted Search)是一种在图书馆学领域中常用的正交多维划分信息空间的分类体系,是一种基于分面理论的在数据集上的探索性的检索技术[3]。它具有很强的检索结果分类能力,用户可以仅关注所感兴趣类别中的检索结果,通过与分面目录的交互不断对检索结果进行细化或泛化,忽略其它不感兴趣类别的检索结果,从而能有效缓解信息过载问题[4]。同时分面检索的导航功能也可以引导用户进行检索,有效地避免了检索结果为空的情况[5-6]。
由于上述特点,分面检索成为近些年来信息检索中的热点研究方向,并在电子商务网站、电子政务网站、多媒体数据库、图书文献网站、软件开发等多个领域得到广泛应用。
但是当数据项的分面术语较多时,受到界面尺寸的限制,有必要按照某些原则选择出分面术语的子集构成分面检索界面,为用户提供合适的面和值。现有的一些系统,如eBay Express,它是基于分面术语的频率向用户显示一个手动选择面的子集排名,再如Flamenco[7],该系统只是简单地按照字母表的顺序显示前几个分面,所以分面推荐排序的问题并没有被很好地解决。
国内外学者对分面推荐算法进行了相关的研究,提出了许多自动推荐分面机制。文献[8]给出了分面推荐应该遵循的3 个基本原则:1)支持结果集中覆盖率高的分面;2)支持分面值分布熵比较高的分面;3)合并那些有共同值的分面。Eyal Oren 等人在文献[9]中提出在RDF 数据中使用分面导航理论,以及自动评价RDF 属性导航能力的算法。该算法受信息空间规模的限制,同时没有充分利用RDF 元数据,因而丢失了RDF 数据的内在语义信息。王莉等人在文献[10]中提出了一种基于分面浏览技术的持久化RDF语义数据的存储策略,利用统计的方法提取关键词,利用层次聚类的方法考察属性的导航能力。
当前的分面推荐排序方法只考虑了单个分面的导航能力,并且也基本都是针对结构化的数据进行检索,而在半结构的XML 数据中,分面之间是有相关性的[11],以上方法并没有考虑到XML 分面之间的相关性。
由于水利信息资源目录服务系统的用户众多,用户对于水利信息资源关注的层次和维度各不相同,对于水利领域知识的熟识度也不尽相同,很大程度上,用户要在自己所关注的数据维度进行探索式的检索,此时分面检索技术愈显重要。同时水利信息资源数据量大、数据结构复杂的特点,导致在目录服务系统中需使用半结构化的XML 数据作为水利信息资源构建目录的载体,而当前的分面检索技术均集中于结构化数据和非结构化数据上,因此急需一种针对半结构化XML 数据的分面检索技术来实现目录服务系统的分面检索。同时根据水利领域人员制定的分面分类标准,构建分面分类体系,以支持多维度的数据视图。本文主要是在前人研究的基础上,根据水利数据半结构化的特点,提出一种基于区分度的分面推荐算法,用以支持水利数据目录的分面检索,并将该算法应用到实际应用系统中,以满足用户的检索需求。
2 基于区分度的相关性分面推荐算法
水利数据信息涉及面广泛,通常用户的检索都是探索式的检索,这就需要对用户的检索进行导航。在用户第一次进行检索的时候,首先基于用户输入的关键字进行检索,根据关键字的匹配度将覆盖率高的分面推荐给用户;当用户与系统有交互之后,即用户选择分面之后,系统会根据用户选择的分面为用户展示检索结果以及可能再次选择的分面。
系统首先推荐与用户输入关键字匹配度较高的分面,即那些包含用户输入关键字的分面,其计算公式如下:
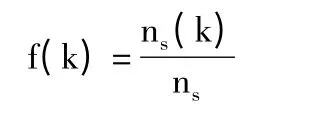
其中,ns(k)表示包含关键字k 的元数据信息总数,ns表示元数据信息总数,f(k)表示关键字k 的覆盖率。
分面推荐的思想是用户以最少的检索次数(分面选择次数)检索到期望的结果。具体来说,如果将数据集构建成一棵检索树,树的节点为数据的属性,每条边表示该属性的不同属性值,树的叶子节点为某个具体的数据记录,则从根节点到叶子节点的路径即为该条数据记录的完整数据,系统所需要做的就是将深度最低的树的结构信息抽取出来,其中的内部节点作为分面推荐给用户。当数据项的分面术语较多时,受到界面尺寸的限制,则将某几个深度较低的子树的根节点作为分面推荐给用户,以确保用户所做选择最少。
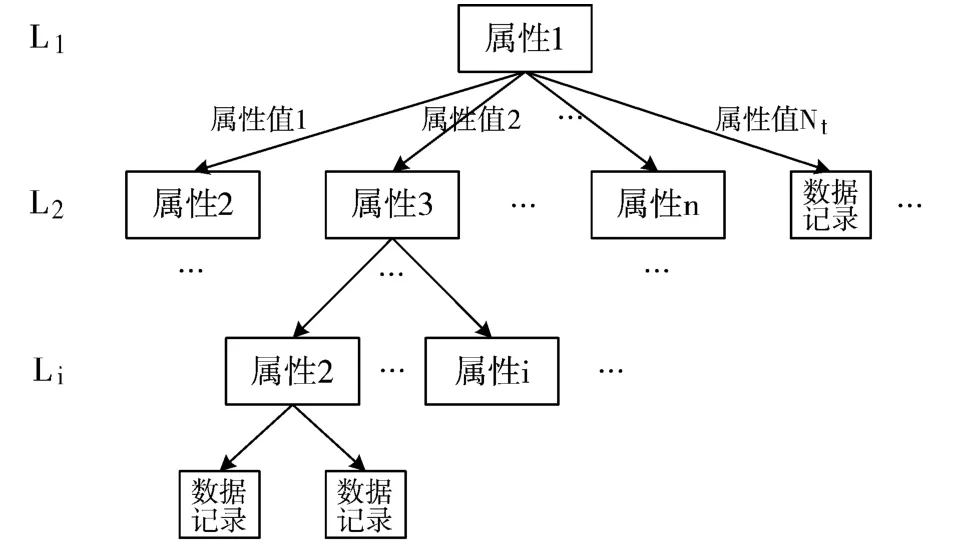
图1 检索树示例
检索树的个数根据数据集分面数的大小而确定。如图1 所示,是由属性1 作为根节点生成的检索树,以其不同的属性值分割其子树,直至到达一个数据记录,整棵树的深度即为该属性下的最高检索深度,这样在生成了所有的检索树后,将可以引导用户以最小代价检索到结果的属性分面优先推荐,也即可以将检索结果区分出来的属性分面优先推荐。
构建检索树的伪代码描述如下:

在通过上述算法构建完检索树后,可以得到每棵检索树的深度length,length 越小说明该属性节点的区分度越高,则系统优先推荐length 最小的分面。同时考虑半结构化XML 数据的特点,每种XML 数据都有其Schema,系统可以预先计算每个分面的相关性[11]:

其中,XiYj表示第i 个面与第j 个面同时出现在一篇文档中的文档总数。Xi表示包含第i 个面的文档总数,Yj表示包含第j 个面的文档总数。
在区分度相同时,根据相关性计算公式预先计算的分面相关性,优先推荐与用户所选分面相关性高的分面,完成分面的建立。
3 基于水利对象分类标签的分面检索系统
3.1 分面检索在应用系统中的应用
本文以某水利委员会目录检索子系统为基础,将分面检索技术引入其中,并通过分面推荐算法为用户提供分面选择。其检索模块的结构框架如图2 所示。

图2 检索模块结构框架图
3.2 分类标签设计
在水利数据资源的整合与共享平台建设中,形成了由业务数据库、基础数据库、专题产品库和元数据库构成的中心共享数据库,这些数据由于集中存储在同一物理节点,也称为物理集中的水利数据资源。同时还有大量的水利数据资源分布地存储在各级水利行政单位,由于前期水利业务系统的设计并没有统一的标准规范,这些水利数据资源无法像物理集中的水利数据资源进行集中存储,只能是分布存储在各级水利行政单位,也称逻辑集中的水利数据资源[12]。
对于物理集中的以对象为单位的数据资源根据其对象分类标准建立分类,对于逻辑集中的数据资源根据现有部颁标准[13]建立分类,为了满足不同用户的查询需求建立分类标签库,对水利数据资源进行添加标签的管理。通过上述3 个层次对水利数据资源进行分类,建立水利数据资源的不同维度,为实现水利数据资源的高效管理和有效共享打下基础。
对于物理集中和逻辑集中的数据资源,均可依据相关标准构建分类,这里不再赘述。
对于为了满足不同领域用户的查询需求而建立的分类标签库,本文只给出一级分类标签,二级分类标签及其子分类标签可由系统管理者进行相应的增加,对于同一类型不同纬度的分类亦可以建立多组分类标签,但是其必须在由本文给出的一级分类标签框架下。水利数据资源的一级分类标签见表1。

表1 一级分类标签
为了便于标签的管理,同时能够以最小的系统维护开销支持分面标签的扩展,将分类标签库设计为独立的表。以二级标签库表为例,一级标签库用于存储一级分类标签内容,二级标签库用于存储二级分类标签内容,并通过外键的方式与一级标签库建立关联,标签索引库用于存储元数据与标签之间的对应关系。这样可以在不影响原系统表结构的情况下实现分类标签的功能扩展,适应性高。分类标签的存储结构见图3。

图3 分类标签存储结构图
3.3 检索模块设计
检索模块包含3 个子模块:关键字检索模块、分面检索模块和检索结果排序模块。用户首次检索需要输入关键字进行关键字检索,系统给出初步检索结果集,此后用户便可以通过选择分面进行分面检索,每次的分面检索结果都经由检索结果排序模块展示给用户。其中的分面检索模块,包括分面推荐和分面排序,分面推荐可以基于分面推荐原则把最有价值的分面推荐给用户,分面排序可以基于水利领域的特殊性把用户最期望获取的检索结果所在分面优先排列向用户展示。
1)分面推荐。
在用户第一次进行检索的时候,首先基于用户输入的关键字进行检索,根据关键字的匹配度将覆盖率高的分面推荐给用户;然后用户选择分面,根据用户选择的分面将对用户所选分面区分度高的分面推荐给用户以备用户再次选择,如此往复,直到用户检索到所需的数据资源信息。
分面推荐的流程见图4。
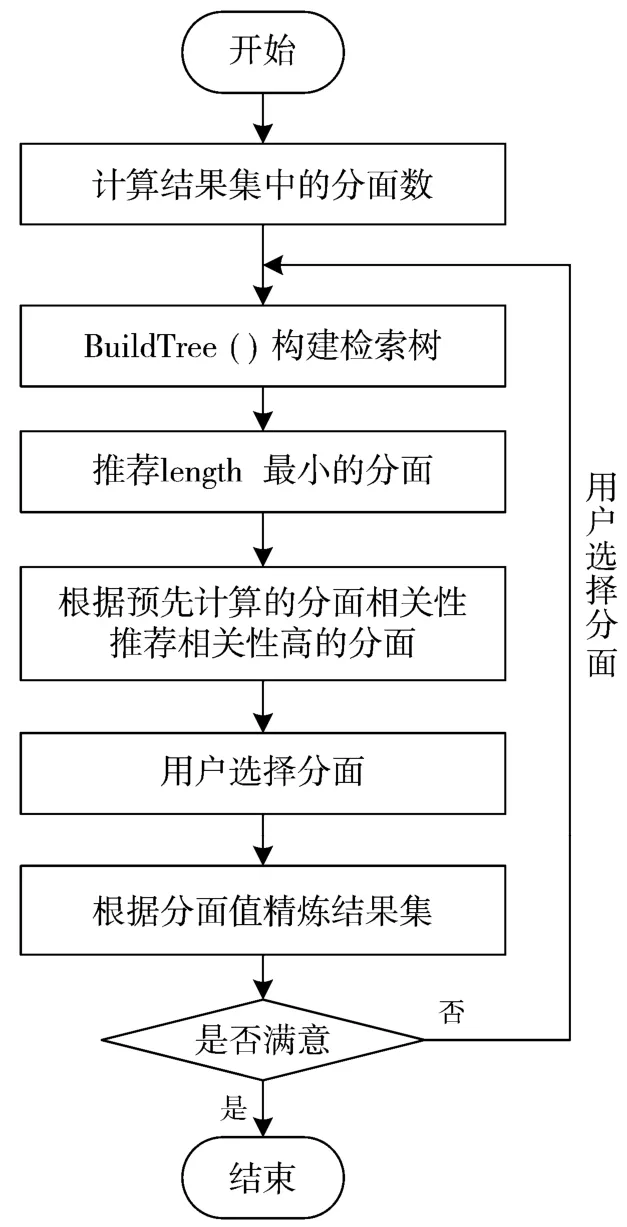
图4 分面推荐流程图
第2 章介绍了基于区分度的分面推荐算法,将该分面推荐算法应用到系统中,实现分面的推荐导航。
2)分面排序。
根据前期调研发现,用户对于水利数据的关注点集中在水利数据类型、数据更新时间、数据来源单位、数据负责人等几个分面。在系统中如果用户不进行关键字的检索,则提供以上几个默认分面供用户选择。当用户与系统产生交互后便由系统根据用户选择进行分面的推荐排序。
3)检索结果排序。
为了保证检索的效率,在对检索结果进行排序时,根据水利业务的特点,用户一般都是为了获取最新的信息而进行检索的,所以,在对检索结果进行排序时使用联合域排序,关键字匹配程度作为第一个域,时间作为第二个域。
3.4 系统实现展示
将本文提出的基于保持率的分面推荐算法应用到实际项目中,开发一套面向水利领域的目录服务系统,系统最终效果如图5 和图6 所示。

图5 系统截图展示1

图6 系统截图展示2
与之前系统相比,引入分面检索技术的系统在大部分检索过程中可以减少用户的检索次数,并且检索过程中也没有出现信息过载和检索结果为空的情况,提高了用户的检索效率,提升了用户体验。
4 结束语
本文提出的基于区分度的分面推荐算法,通过构建检索树,将不同的导航路径推荐给用户,其原则是使用户所做选择最少。为了验证算法的有效性,本文将算法应用到实际业务应用系统中,并给出了系统实现展示,效果良好。本文还有诸多不足,比如算法的效率问题、排序方法的改进等。下一步的工作是对检索树构建算法进行改进以提升其效率,并在检索结果排序模块中考虑多重因素的影响,由用户配置用户期望的排序方式,在结果排序的方式上满足不同用户的需求。
[1]冯钧,许潇,唐志贤,等.水利大数据及其资源化关键技术研究[J].水利信息化,2013(4):6-9.
[2]Hai Zhuge,Wilks Y.Faceted search,social networkingand interactive semantics[J].World Wide Web,2014,17(4):589-593.
[3]Kashyap A,Hristidis V,Petropoulos M.FACeTOR:Costdriven exploration of faceted query results[C]// Conference on Information and Knowledge Management,CIKM.2010:1-12.
[4]高建忠,何绯娟.分面检索模型与关键技术综述[J].图书馆论坛,2012,32(6):112-116.
[5]何超,程学旗,郭嘉丰.面向分面导航的层次概念格模型及挖掘算法[J].计算机学报,2011,34(9):1589-1602.
[6]陈波.基于开源全文检索系统Solr 的OPAC 分面浏览[J].现代图书情报技术,2007,2(11):72-75.
[7]Hearst M A.Clustering versus faceted categories for information exploration[J].Communications of the ACM,2006,49(4):59-61.
[8]Daniel Tunkelang.Faceted Search:Synthesis Lectures on Information Concepts,Retrieval,and Services[M].Morgan &Claypool Publishers Series,2009:47-51.
[9]Oren E,Delbru R,Decker S.Extending faceted navigation for RDF data[M]// The Semantic Web-ISWC 2006.Springer Berlin Heidelberg,2006:559-572.
[10]王莉,高仲利.基于分面导航理论的RDF 数据的持久化研究[J].计算机工程与应用,2010,46(9):130-133.
[11]李新叶,郭力洁,李丹丹,等.分面搜索的分面推荐方法研究[J].计算机应用与软件,2013,30(6):75-78.
[12]成建国,冯钧,杨鹏,等.水利数据资源目录服务关键技术研究[J].水利信息化,2014(6):18-21.
[13]中华人民共和国水利部SL701-2014,水利信息分类[S].
[14]陈波.基于开源全文检索系统Solr 的OPAC 分面浏览[J].现代图书情报技术,2007(11):72-75.
[15]Niu N,Mahmoud A,Yang X.Faceted navigation for software exploration[C]// 2011 IEEE 19th International Conference on Program Comprehension(ICPC).2011:193-196.
[16]Li Chengkai,Yan Ning,Roy S B,et al.Facetedpedia:Dynamic generation of query-dependent faceted interfaces for wikipedia[C]// Proceedings of the 19th International Conference on World Wide Web,ACM.2010:651-660.
[17]Basu Roy S,Wang H,Das G,et al.Minimum-effort driven dynamic faceted search in structured databases[C]//Proceedings of the 17th ACM Conference on Information and Knowledge Management,ACM.2008:13-22.
[18]Hahn R,Bizer C,Sahnwaldt C,et al.Faceted Wikipedia search[C]// Lecture Notes in Business Information Systems,Springer.2010:1-11.
猜你喜欢
水利建设与管理(2020年6期)2020-07-08
水利建设与管理(2020年6期)2020-07-08
河南水利年鉴(2020年0期)2020-06-09
意林图解作文(小学版)(2019年6期)2019-07-16
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
专利代理(2016年1期)2016-05-17
公民与法治(2016年10期)2016-05-17
计算机工程(2015年8期)2015-07-03
江苏年鉴(2014年0期)2014-03-11
