
一种适宜于子空间聚类的离群点检测算法
2015-11-25 02:59:16杨维永郑生军张旭东
计算机与现代化 2015年12期
杨维永,何 军,郑生军,张旭东
(1.南京南瑞集团公司,江苏 南京 210003;2.南京信息工程大学电子与信息工程学院,江苏 南京 210044;3.北京国电通网络技术有限公司,北京 100070;4.国网浙江省电力公司信息通信分公司,浙江 杭州 310007)
0 引言
随着互联网、社交媒体[1]和物联网[2]的快速发展,人们所处的数字世界已经迈入了大数据[3]的时代。然而数据的洪流给传统的数据处理带来了新的挑战:大数据的处理面临数据的非结构化[4],收集到的数据存在信息缺失,甚至数据污染[5]等苛刻条件。因此,数据清理是大数据分析的一个首要的预处理过程。本文主要针对数据污染问题,即数据中存在离群点,在子空间聚类模型下讨论并提出一个离群点检测的有效算法。
1)离群点检测。
在数据分析中,对于所分析的数据集D,通常假定D 服从某种概率分布D~P(θ),而离群点指的则是数据集中那些明显偏离数据分布P(θ)的数据点。离群点的检测与去除是数据分析的一个重要预处理环节,因为离群点的存在会严重干扰传统的数据分析的结果。学术界对于离群点的检测做了许多深入的研究,例如针对经典的主成分分析(PCA)受制于离群点的污染,性能严重下降的问题,近些年提出了若干优秀的鲁棒性主成分分析的理论与方法(Robust PCA)[6];另一方面,在数据分析中的聚类分析方面,也出现了若干方法能够有效克服离群点对于聚类的影响[7]。
2)子空间聚类。
经典的主成分分析方法是假定数据来源于一个低维的线性子空间,进而可以将高维数据投影到此低维子空间从而得到数据的紧凑表示形式,以便利于后续的分析。然而,在数据收集的过程中,数据通常来自于多个不同的数据源,因此一种更为恰当的数据模型是假定每个数据源是一个低维动力系统,则收集的数据可以归集为该低维子空间的集合。从数据中辨识出子空间集合,并将数据分配至相应子空间的方法称之为子空间聚类。
近些年来在机器学习、计算机视觉等领域对于子空间聚类问题进行了深入的研究,提出了诸如SSC[8]、LRR[9]、SCC[10]等优秀的子空间聚类算法。另一方面,基于迭代方法的k-subspace 算法[11]及其变种,例如LBF[12]等由于其算法的效率和易于并行处理等优势,在子空间聚类方面也有较好的应用前景。
在大数据处理中的子空间聚类问题,一个不可回避的问题是如何面对数据遭受离群点污染这样的苛刻情况[13]。离群点的存在,破坏了经典子空间聚类算法对于数据分布的假设,因此学者们也提出了若干鲁棒性的子空间聚类算法,典型的方法是基于离群点稀疏性的先验知识,通过对子空间聚类的目标函数增加ℓ1范数的正则化项,进而克服了离群点的影响。本文所提出的离群点检测算法也遵循此思路,将ℓ1范数的正则化引入k-subspace 此类迭代式子空间聚类算法中,以适应于大规模的数据处理。
1 适宜于子空间聚类的离群点检测模型
对于向量空间ℝn中的数据集X={x1,x2,…,xN},假定数据来源于K 个低维线性子空间=1,为了简化讨论,假定K 个子空间的维度均为d,则一个n×d 规范正交的矩阵Uk能够张成子空间Sk。对于数据集X 中的任意数据xi,假定其必然能够由某一个子空间Sj线性表示,即满足xi=Ujw,其中w 是权重系数向量。另外,对于向量空间ℝn中的离群点集O={o1,o2,…,oM},离群点均不能够由此K 个低维子空间中的任意一个子空间线性表示。
对于子空间聚类中典型的k-subspace 模型,其优化的目标函数如公式(1)所示:
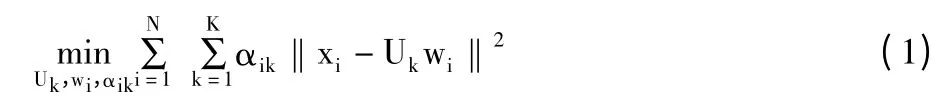
其中αik是分配因子,即:
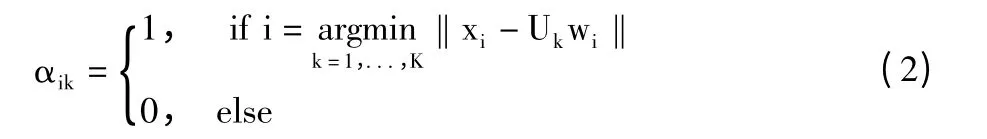
表示数据xi适合归类于子空间Uk。然而,由于离群点的出现,根据假定,任意一个离群点oj均无法由子空间线性表示,则离群点对于K 个子空间的线性回归残差值无法达到最优。因此,在离群点的影响下,模型(1)无法进行正确的子空间聚类。
根据离群点具有稀疏性的先验条件,对模型(1)增加ℓ1范数正则化,即引入离群点残差向量y 和动态离群点判别阈值∈t,则离群点检测的方法如公式(3)所示:

其中,向量y 的长度与数据集大小一致,因此公式(3)表示如果对于某个数据xi,其投影到任意子空间的最小残差ri超过给定判别阈值∈t,则将其检测为离群点,并将最小的残差ri记录在向量y 的对应分量。于是,离群点越稀疏,则向量y 的ℓ1范数会越小。因此,得到适宜于离群点的子空间聚类模型(4):

需要指出的是,模型(4)与k-subspace 一致,是一类迭代更新的子空间聚类模型,离群点判别阈值在算法的迭代过程中会进行相应的改变。由于在迭代的初期,子空间刚刚初始化,模型还不能准确地判定数据归为哪一个子空间,自然也就无法准确给出离群点的判定,因此,∈0设定为一个较大的数值。引入一个衰退因子η(0 <η <1),在每次模型迭代更新后,更新判别阈值∈t=η∈t-1。于是,随着模型的迭代,离群点判别阈值以指数级衰减,最终会将所有的离群点准确地检测出,并对子空间进行合适的聚类。
2 离群点检测与子空间聚类算法
根据离群点检测公式(3),可以列出伪码如算法1 所示。
算法1 离群点检测算法

从算法1 可以看出,确定一个数据是否是离群点,需要将该数据分别投影至K 个子空间,因此该算法本质上是计算K 个最小二乘问题。又因为构成子空间的矩阵Uk规范正交,于是最小二乘算法被简化为仅需进行一次矩阵和向量的相乘。
根据修改后的子空间聚类模型(4),可以列出该算法的伪码如算法2 所示。
算法2 适宜于离群点的子空间聚类算法

从算法2 可以看出,对于待判别的数据,首先确定其是否是离群点,如果是离群点则标记对应的离群点残差向量,否则进行子空间归类,进而更新该子空间。在算法迭代的过程中,逐步更新K 个子空间,由于算法是逐数据进行处理,因此更新子空间的过程相当于是随机梯度下降算法(SGD),对于内存的要求相当低,只需要维护k 个n×d 矩阵;同时算法的计算量也非常低,对于每个数据仅需计算k 次矩阵和向量乘法和进行一次子空间的梯度下降更新。由此讨论可以看出,算法2 满足对于大数据处理的需求,即较低的计算复杂度和较少的内存需求。
3 实验仿真验证
为了验证算法1 和算法2 在子空间聚类方面对于离群点的鲁棒性,笔者设计了如下的仿真实验进行验证。
根据上述讨论,算法2 本质上是一种随机梯度下降算法,适宜于大数据处理[14]。这里考虑一种流式大数据情况,也就是数据以序列方式不断地产生,数据来源于K=4 个低维线性子空间,子空间的秩d=1,并以随机方式p(o)=0.1 加入离群点,为了方便可视化,本实验考虑数据的维度为n=3。图1 展示了原始序列数据的空间分布情况。可以看出,对于秩为1 的子空间,其数据分别呈现出线性的形状;而离群点的分布则完全随机化。
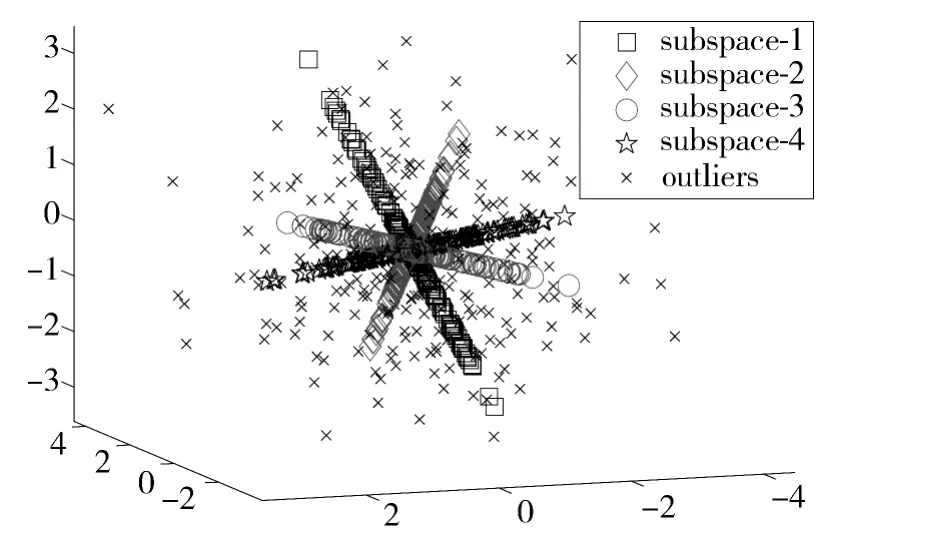
图1 原始序列数据
图2 展示了子空间聚类算法2 的收敛速度。可以看出,尽管受到离群点的影响,算法2 依然显示出了近似线性的快速收敛速度,成功地辨识出K=4 个子空间。
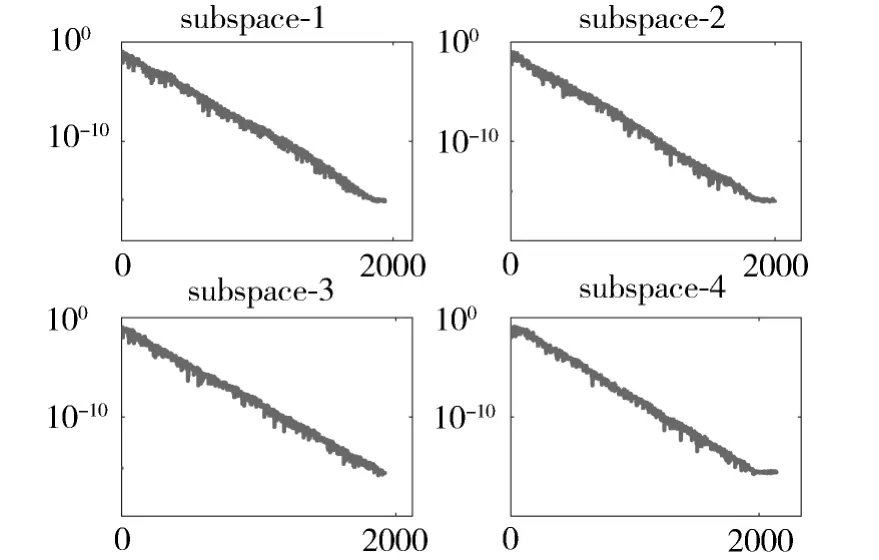
图2 算法的收敛过程
最后,图3 展示了最终对于序列数据的聚类结果,可以清晰地看出,数据流规整地来源于K=4 个子空间,而离群点被准确地检测出。其中图中的横坐标表示数据流的标号,纵坐标的数值表示数据被归为第几个子空间,因为K=4,所以纵坐标的最大数值为4,离群点的标记为-1。
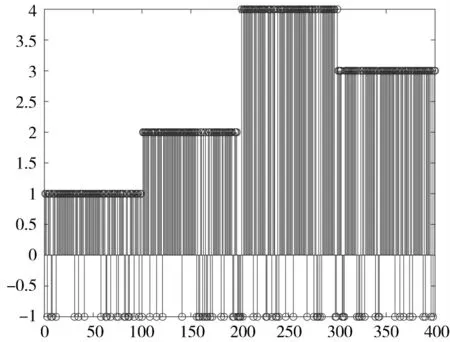
图3 子空间聚类的结果
4 结束语
针对大数据分析中不可避免的数据污染问题,本文以子空间聚类为研究对象,讨论并提出了一种适合于子空间聚类的离群点检测算法。本文所提出的算法能够自适应地确定离群点检测阈值,并结合随机梯度下降算法动态更新子空间,算法复杂度低,内存需求小,适合于大数据处理。通过数值仿真实验,验证了本算法的有效性和收敛性。对于未来的工作,笔者考虑将算法实现在目前流行的大数据处理平台,诸如Spark[15],并结合大数据流式计算技术[16],在网络日志安全检测等方面进行应用和开发。
[1]LaValle Steve,Eric Lesser,Rebecca Shockley,et al.Big data,analytics and the path from insights to value[J].MIT Sloan Management Review (Winter 2011),2011,52(2).
[2]Gubbi Jayavardhana,Rajkumar Buyya,Slaven Marusic,et al.Internet of Things (IoT):A vision,architectural elements,and future directions[J].Future Generation Computer Systems,2013,29(7):1645-1660.
[3]Manyika James,Michael Chui,Brad Brown,et al.Big data:The Next Frontier for Innovation,Competition,and Productivity[R].McKinsey Global Institute,2011.
[4]Sagiroglu Seref,Duygu Sinanc.Big data:A review[C]//IEEE 2013 International Conference on Collaboration Technologies and Systems(CTS).2013:42-47.
[5]Wu Xindong,Zhu Xingquan,Wu Gongqing,et al.Data mining with big data[J].IEEE Transactions on Knowledge and Data Engineering,2014,26(1):97-107.
[6]Emmanuel J Candès,Li Xiaodong,Ma Yi,et al.Robust principal component analysis?[J].Journal of the ACM(JACM),2011,58(3):11.
[7]Victoria J Hodge,Jim Austin.A survey of outlier detection methodologies[J].Artificial Intelligence Review,2004,22(2):85-126.
[8]Elhamifar Ehsan,Rene Vidal.Sparse subspace clustering:Algorithm,theory,and applications[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2013,35(11):2765-2781.
[9]Liu Guangcan,Lin Zhouchen,Yan Shuicheng,et al.Robust recovery of subspace structures by low-rank representation[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2013,35(1):171-184.
[10]Chen Guangliang,Gilad Lerman.Spectral curvature clustering (SCC)[J].International Journal of Computer Vision,2009,81(3):317-330.
[11]Ho Jason,Yang Ming-Hsuan,Lim Jongwoo,et al.Clustering appearances of objects under varying illumination conditions[C]// Proceedings of 2003 IEEE Computer Society Conference on Computer Vision and Pattern Recognition.2003:1-11.
[12]Zhang Teng,Arthur Szlam,Yi Wang,et al.Hybrid linear modeling via local best-fit flats[J].International Journal of Computer Vision,2012,100(3):217-240.
[13]Vidal René.A tutorial on subspace clustering[J].IEEE Signal Processing Magazine,2010,28(2):52-68.
[14]Cevher Volkan,Steffen Becker,Martin Schmidt.Convex optimization for big data:Scalable,randomized,and parallel algorithms for big data analytics[J].IEEE Signal Processing Magazine,2014,31(5):32-43.
[15]Zaharia Matei,Mosharaf Chowdhury,Michael J Franklin,et al.Spark:Cluster computing with working sets[C]//Proceedings of the 2nd USENIX Conference on Hot Topics in Cloud Computing.2010:10-10.
[16]Zaharia Matei,Tathagata Das,Li Haoyuan,et al.Discretized streams:Fault-tolerant streaming computation at scale[C]// Proceedings of the 24th ACM Symposium on Operating Systems Principles.2013:423-438.
猜你喜欢
数学物理学报(2022年4期)2022-08-22 04:08:00
中学生数理化·高一版(2021年2期)2021-03-19 08:32:06
中央民族大学学报(自然科学版)(2018年3期)2018-11-09 01:16:34
电子测试(2017年15期)2017-12-18 07:19:27
中国房地产业(2016年9期)2016-03-01 01:26:47
智能系统学报(2015年4期)2015-12-27 09:38:39
作文评点报·低幼版(2015年5期)2015-05-30 10:48:04
电子设计工程(2015年6期)2015-02-27 12:04:53
西安交通大学学报(2014年8期)2014-04-16 05:07:06
上海电机学院学报(2014年3期)2014-02-28 14:29:45
