
基于句子权重和篇章结构的政府公文自动文摘算法
2015-11-25 03:00:48毛良文
计算机与现代化 2015年12期
毛良文,徐 亮
(1.湖南省产商品质量监督检验研究院,湖南 长沙 410007;2.湖南师范大学数学与计算机科学学院,湖南 长沙 410081;3.高性能计算与随机信息处理省部共建教育部重点实验室,湖南 长沙 410081)
0 引言
现如今,计算机和互联网技术已经深深地改变了人们的学习、生活和工作。人们的每一项活动都已经与计算机、互联网紧紧相连。人们在享受信息技术所带来的快速、透明和便捷的同时,也在生活中逐渐陷入到海量信息、信息爆炸的困境中。如何从海量信息中快速而准确地找到人们所关注的信息就成为了当今信息处理的一项重要技术。
自动文摘技术就是这其中的一个重要研究领域。早在20 世纪50 年代,美国IBM 公司的H.P.Luhn就开始了自动文摘的研究[1],随后,H.P.Edmandson在Luhn 研究的基础之上提出了综合线索词、标题、词频等因素的加权方法生成自动文摘,在句子的加权计算上前进了一大步[2]。20 世纪70 年代开始,随着自然语言理解技术的发展和人工智能技术的发展,在自动文摘领域产生了各种各样的应用系统,如采用删除句子的策略产生自动文摘的ADAM 系统[3]、基于脚本信息的FRUMP 系统[4]、基于混合方法的SCISOR系统[5]等。
我国从20 世纪80 年代末才开始对中文自动文摘系统进行研究和开发工作。时间虽不长,但发展很迅速。尤其是随着中文分词、中文语义分析等技术的发展,自动文摘技术的研究也快速向前推进,其中比较具有代表性的成果包括:综合考虑句子位置、指示性短语、文本结构等因素的SJTUVAA 系统[6];通过与用户进行交互,利用脚本表示知识的“中文全文自动文摘系统”[7];基于“全信息”自然语言理论研发出了面向各种不同类型文章的中文自动文摘系统[8];基于篇章理解并充分利用句子层面之间的语义信息的MATAS 系统[9]以及基于主题词权重和句子特征的自动文摘算法[10]等。
本文在文献[10]算法的基础上,根据政府公文结构性强这一特点,提出了一种基于句子权重和篇章结构的政府公文自动文摘算法,主要是根据文章中的句子权重大小和文章篇章结构来共同决定一个句子是否能成为自动文摘句子。通过对文章篇章结构和内容层次的划分,并将相关信息融入到对主题词权重和句子权重的计算公式中,从而在一定程度上改进了对文章句子权重排序的结果。实验表明,使用本文提出的自动文摘算法,在进行政府公文的文摘自动生成时,准确率和召回率都较文献[10]中的方法有较大提高。
1 系统框架
基于句子权重和篇章结构的政府公文自动文摘系统框架如图1 所示。

图1 基于主题词权重和句子特征的自动文摘系统框架
在构建一个公文的文摘时,首先分析公文的篇章结构信息,根据篇章结构信息,对句子、词语所在的层级进行统计;然后通过分词及词性标注、词频统计等操作,在考虑词频、词性、词的位置等因素的情况下,计算词语的权重,并根据标题的类型信息和用户偏好信息对词语的权重进行修改;之后在词语权重和句子相关特征信息的基础上计算句子的权重,并根据句子权重得出候选文摘句;最后进行文摘的筛选和润色输出。
2 算法介绍
2.1 篇章结构分析
篇章结构分析是为了获取词语、句子所在的篇章结构信息,这在生成政府公文摘要时,是非常重要的信息,因为大多数情况下,政府公文中的篇章结构信息是十分明显的,据此来进行文摘的自动生成必然会事半功倍。
2.1.1 分句
分句是将一篇文章分成一个个独立的句子。分句是实现精确的句子信息统计的前提条件,准确的分句将为后续的文摘句子权重计算和得到文章的篇章结构打下坚实的基础。分句算法步骤为:
步骤1 将文章的内容和格式统一装进字符串序列S(C1,C2,...,Cn)中。
步骤2 定义2 个下标start、end,初值都为1。
步骤3 判断字符串序列S 中下标为end 的字符是否为句子分割字符flag:
1)如果Cend=flag,则执行步骤4;
2)如果Cend≠flag,则执行步骤6。
步骤4 将S 中的Cstart至Cend之间的字符组合为一个字符串S',装进句子容器D(s1,s2,...,sn)中。
步骤5 将start、end 的值都变为end+1,转步骤3。
步骤6 start 的值保持不变,end 的值变为end+1,转步骤3。
步骤7 如果start >n(n 为S 的最大下标),则算法结束。
2.1.2 句子信息统计
句子信息统计是句子权重计算的前提条件,同时可以为句子权重的计算提供充分的参考。
在句子的信息统计中,每个句子的详细信息都可以用一个六元组{x,y,z,u,v,w}来表示,分别用来代表句子的章节编号、段落编号、段落句子编号、文章句子编号、句子内容的层以及句子的长度。章节编号将可以直接说明句子属于文章的哪一大块内容;段落编号代表句子属于一个章节的第几段;段落句子编号用来代表句子在一个段落中的顺序;文章句子编号是句子在文章中的精确编号,代表句子在整个文章中的顺序,通过文章句子编号可以直接精确定位到句子,同时通过文章句子编号可以在词语信息统计结果中查找到该句子所含有的词语;句子内容的层级用来表示该句子在整篇文章中的层次地位。
句子信息统计的算法步骤为:
步骤1 定义章节编号、段落编号、段落句子编号、文章句子编号、内容层级编号、句子长度分别为x、y、z、u、v、w,且初值均为0。
步骤2 遍历文章句子容器D(s1,s2,...,sn)中的句子Si(C1,C2,...,Cn)。
步骤3 判断Si(C1,C2,...,Cn)是否符合章节分割特征flag1:
1)如果符合flag1,则执行步骤4;
2)如果不符合flag1,则执行步骤8。
步骤4 判断Si(C1,C2,...,Cn)是否含有章节序号No1:
1)如果含有No1,则执行步骤5;
2)如果不含有No1,则执行步骤6。
步骤5 判断序号层级容器N([type1,1],[type2,2],...,[typen,n])中是否含有No1 的类型(其中,typen为序号的括号类型,n 为层级值):
1)如果含有No1 的类型,则将v 赋值为N 中该类型对应的层级值;
2)如果不含有No1 的类型,则将[No1 的类型,n+1]添加进容器N 中,并将v 赋值为n+1。
步骤6 将x 赋值为x +1,y、z 赋值为0,u 赋值为u+1,v 不变。
步骤7 计算出Si(C1,C2,...,Cn)的长度Si.length,将w 赋值为Si.length,将Si(C1,C2,...,Cn)、x、y、z、u、v、w 装进相应的统计对象中,转步骤2。
步骤8 判断Si(C1,C2,...,Cn)是否符合段落分割特征flag2:
1)如果符合flag2,则执行步骤9;
2)如果不符合flag2,则执行步骤12。
步骤9 判断Si(C1,C2,...,Cn)是否含有小章节序号No2:
1)如果含有No2,则执行步骤10;
2)如果不含有No2,则执行步骤11。
步骤10 判断序号层级容器N([type1,1],[type2,2],...,[typen,n])中是否含有No2 的类型:
1)如果含有No2 的类型,则将r 赋值为N 中该类型对应的层级值;
2)如果不含有No2 的类型,则将[No2 的类型,n+1]添加进容器N 中,并将v 赋值为n+1。
步骤11 y 赋值为y+1,z 赋值为0,u 赋值为u+1,v 不变,转步骤7。
步骤12 x、y 不变,z 赋值为z+1,u 赋值为u +1,v 不变,转步骤7。
2.1.3 词语信息统计
词语是文章内容的原子,对词语信息的精确统计是进行词语权重计算和句子权重计算的基础。词语信息统计可以分成3 大步骤:分词词性标注、词语统计和词语频率统计。分词词性标注,笔者选择使用中科院的ICTCLAS 中文分词系统[12]。
词语信息统计的算法步骤为:
步骤1 调用ICTCLAS 中文分词系统,对文档进行分词词性标注,并拿到返回的分词结果:字符串S(C1,C2,...,Cn)。
步骤2 采用基于游标的字符截取算法对S(C1,C2,...,Cn)进行分词模块Wi(wi,flag,pi)的截取,并将截取到的分词模块Wi(wi,flag,pi)装进容器D(W1,W2,...,Wn)。
步骤3 定义句子编号变量a、词语长度变量len,且初值均为0。
步骤4 遍历容器D(W1,W2,...,Wn),对其中的分词模块Wi(wi,flag,pi)再次进行分割得到wi和pi,然后判断词语wi是否含有句子分割符flag2:
1)如果含有flag2,则a 增加1;
2)如果不含有flag2,a 保持不变。
再将 (wi,pi,a) 作为一条记录,装进数据库中的词语统计表list1 中,直到遍历结束。
步骤5 删除词语统计表list1 中词语wi为停用词的相关记录。
步骤6 遍历词语统计表list1 中的记录(wi,pi,a),判断数据库中词频统计表list2 中是否含有该词语wi(词语相同且词性相同):
1)如果不含有,则计算词语wi的长度并将其赋值给变量len,将 (wi,pi,len,1)作为一条记录装进list2 中;
2)如果含有,则将表list2 中词语为wi的词频字段加1。
本算法中相关参数说明:
分词模块Wi(wi,flag,pi):wi表示词语,flag 表示词语词性分隔符,pi表示词性;词语统计表list1 的表结构为:(‘词语’,‘词性’,‘句子编号’);词语统计表list2 的表结构为:(‘词语’,‘词性’,‘词长’,‘词频’)。
2.2 词语权重计算
在词语自身所拥有的属性当中,词义、词性、词频、词语长度、词语位置都是需要考虑的因素。
不同的词语本身意味着不同的词义,但是对于自动文摘来说,很难说某一个词义对于文章重要,某一个词义对于文章就不重要。所以,在讨论词语的权重时,词义暂不考虑。而词性在决定它是否能代表文章内容上往往有着决定性的作用。计算机研究人员的实验研究结果则更证明了这点[13-14]。在表达文章内容方面,名词相对于其它词有着天然的优势,所以在对词语权重进行计算时,会给名词以较高的权重。在词语的长度方面,文献[14]对2006 年度CSSCI 关键词词库中关键词的词语长度进行统计发现,4~6 字词占到关键词总数的78.42%。所以,笔者对于长度为4~6 个字的词语赋予较高的权重。在词语位置方面,文章各个小标题中的词语无疑是最具概括性和代表性的词语。除了文章的大小标题,研究人员还发现,出现在首段、尾段位置的词语往往也更具代表性。在词频方面,词语出现的次数越多,往往越能代表它对文章内容的重要程度。
综合以上各因素,算法中词语评分计算公式为:
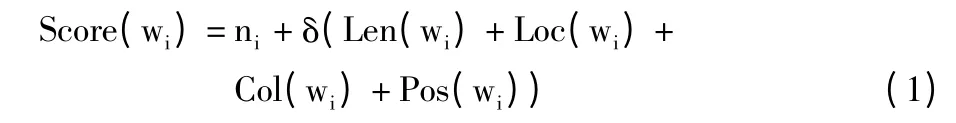
其中,ni为词wi出现的次数;δ 为均衡系数,δ 的取值方法为:

其中,L 为文章的长度。

其中0 <α <1。

其中,0 <β4<β3<β2<β1<1。

其中,0 <γ2<γ1<1。
上述公式中的各参数根据不同的文章类型会有不同的最优值,可以根据情况给予不同比例的赋值,在本系统中则采用:
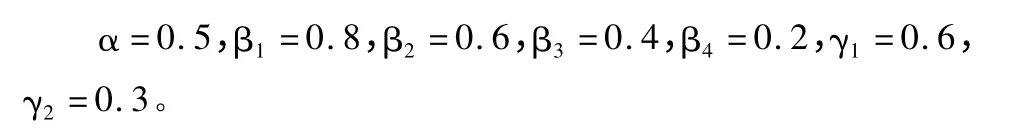
词语权重的计算公式为:

2.3 句子权重计算
句子权重计算的结果将直接决定一个句子是否会被当作文摘句输出。影响句子权重的因素包括句子的内容、位置、长度、是否含有线索词、是否是用户关注的内容等。为了能够让这些因素在句子权重计算中都发挥作用且满足用户的要求,笔者采用加权和来进行句子权重计算。当不考虑用户偏好时,句子权重计算公式为:
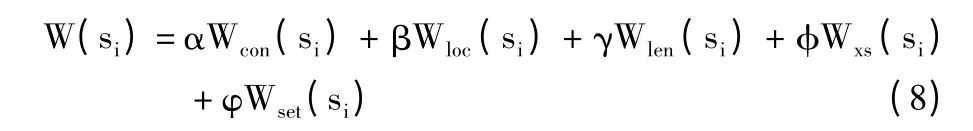
其中,α、β、γ、φ、φ 为调节参数,α+β+γ+φ+φ=1。
基于内容的句子权重Wcon(si)计算公式如下:

其中,N 为句子si中词语的个数,词语wj∈si,0 ≤Wcon(si)≤1。
基于位置的句子权重Wloc(si)计算公式如下:

句子的长度其实也是选为文摘句的一个重要参考因素。以抽取式的方式生成文摘,较短的句子往往因为与上下文有着较紧密的联系,如果单独抽取出来作为文摘句,容易造成该句与其他句子的不协调。其实,在人工文摘中,如果同样是以抽取式生成文摘,测试者在选文摘句的时候考虑的也更多是有较长内容的句子。因为这些长的句子含有的内容更加丰富,同时往往具有更强的独立性和内容的全面性,这些特性让长句子拥有被选为文摘句的天然优势。基于长度的句子权重Wlen(si)计算公式如下:

句子的类型对于一个句子也非常重要,句子的内容往往会因语气的不同而不同。陈述句往往用来讲述或说明某一事实或情况,表达的内容明确、肯定;疑问句一般用于表达疑问提出问题;感叹句则用于抒发情感。对于希望看到文章中心内容的用户来说,陈述句所具有的价值会更大,感叹句次之,疑问句的价值往往最小。基于类型的句子权重Wset(si)计算公式为:

不同的用户对于同一篇文章有着不同的需求,计算机生成的单一文摘很难满足所有人的要求。在生成文摘的时候,如果计算机可以根据用户的需求来决定文摘的生成,毫无疑问将大大提高文摘的有效性。在自动文摘生成之前,用户可以输入自己感兴趣的关键词,让计算机在生成文摘的时候选择更多含有用户关心的内容的句子。笔者认为,用户的偏好是直接对句子的重要程度产生了方向性改变,应该成为决定句子权重的重要因素,而不是与上述的各项因素处于同一影响层次。当需要考虑用户偏好因素时,一个句子的权重计算公式为:
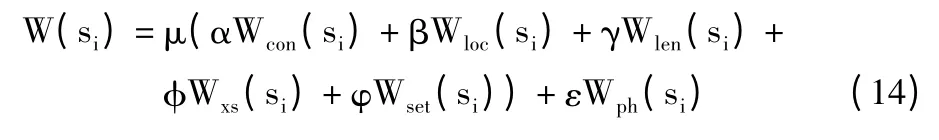
其中μ+ε=1。
2.4 文摘后处理
通过句子权重排序,得到的候选文摘集,在格式和可读性上还存在一定的缺陷,需要对得到的候选集中的文摘句进行一定的后处理。文摘后处理的主要内容包括:
1)删除关系连词。删除句首诸如“因为”、“所以”、“还是”等连词;
2)删除线索词。删除句首诸如“整体来说”、“总之”等线索词;
3)删除句首序号。删除句首的(1)、(一)等类型序号;
4)调整文摘的格式。删除部分句尾的回车符,删除句首的空格,在文摘第一句添加2 个空格。
通过文摘后处理,可以将文摘句容器中的句子按照其在文章中的顺序组织成一个段落进行输出,得到最终的文摘句。
3 实验结果与分析
3.1 实验数据
为了验证系统的性能,随机的选取了来自新闻、军事、财经、科技和政府公文题材的文档材料各50 篇进行实验测试。
3.2 实验结果及分析
实验结果的评价方法如下:首先由3 名大学生对所选取的文档单独进行人工文摘,然后综合3 人生成的人工文摘形成理想文摘,将理想文摘作为自动文摘的评价依据,并计算自动文摘的准确率、召回率和F值[15]。
首先,为了找出α、β 的较优分配比例,随机抽取50 篇政府公文,将α:β 的比值分别取3 种不同比例,在2 种压缩比(摘要字数:文章字数)下进行试验。实验的结果如表1 所示。
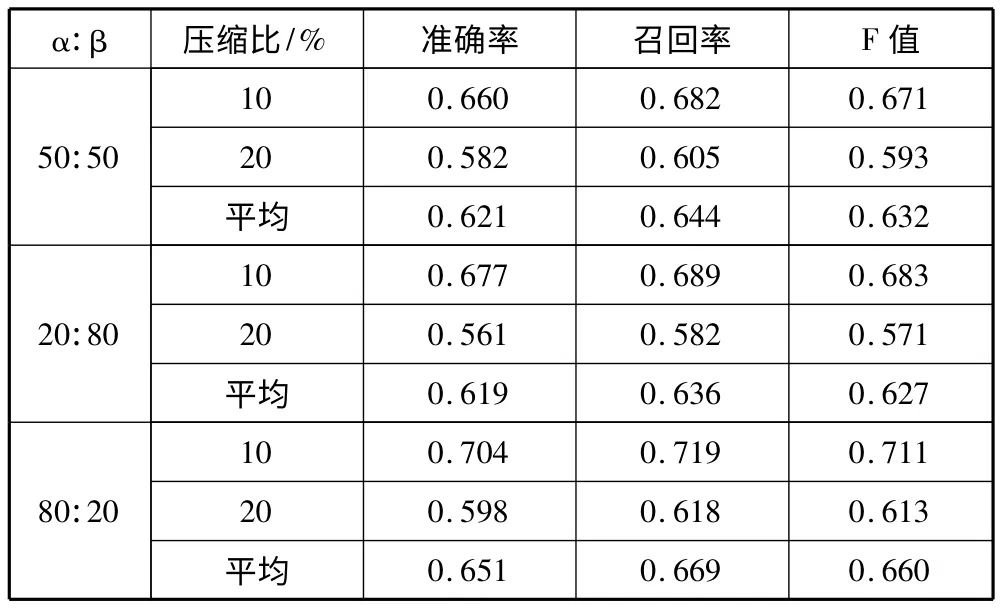
表1 α、β 在不同比例下的自动文摘结果
通过对表1 进行分析,发现当α:β=80:20 时,有着较高准确率和召回率,同时F 值也较高。因此,将α:β 的比值取为80:20 进行后面的实验对比。
为了进行对比实验,笔者还采用了文献[10]中的方法和Microsoft Word 2003 中的自动摘要工具对相同的250 篇政府公文进行自动文摘。其中,句子权重计算公式(3)~公式(8)中的相关参数取其较优值:α=0.48,β=0.12,γ=0.1,φ=0.2,φ=0.1。实验结果如表2 所示。

表2 自动文摘系统结果对比
从表2 可以看出,本系统的平均准确率为0.651,平均召回率为0.669,平均F 值为0.660,3 项指标均高于文献[10]中的方法和Word 2003 summarizer的平均值。这表明,考虑文章的篇章结构,并将其应用到对候选文摘句的权重计算中,对文摘的自动生成质量有较为明显的提升。
4 结束语
本文根据政府公文结构性强的特点,提出了一种基于句子权重和篇章结构的政府公文自动文摘算法,通过对篇章结构信息的掌握,以及在此基础上对词语、句子权重进行计算得出候选文摘集,并通过后处理最终形成文摘。实验结果表明,该算法有效地提高了政府公文自动文摘系统的准确率和召回率。今后,笔者考虑在该算法中,尤其是文摘后处理部分,增加相似度计算[16-18]、语义处理[15,19]的功能,让其生成的自动文摘更加符合标准文摘的定义和规范,更加接近于人工提取的文摘。
[1]Luhn H P.The automatic creation of literature abstracts[J].IBM Journal of Research and Development,1958,2(2):159-165.
[2]Edmundson H P.Problems of automatic abstracting[J].Communications of ACM,1964,7(4):259-263.
[3]Mathis B A,Rush J E.Abstracting[M]// Encyclopedia of Computer and Technology.NewYork:Marcel Dekker Inc.,1975:102-142.
[4]De Jong G.An overview of the FRUMP system[M]//Strategies for Natural Language Processing.London:Lawrence Erlbaum,1982:149-172.
[5]Hahn U,Reimer U.The TOPIC project:Text-oriented procedures for information management and condensation of expository texts[J].Decision Support Systems,1985,1(4):342-343.
[6]王永成,徐慧.OA 中文文献自动摘要系统[J].情报学报,1997,16(2):124-129.
[7]姚天顺,朱靖波,张利,等.自然语言理解—一种让机器懂得人类语言的研究[M].北京:清华大学出版社,1995.
[8]李蕾,郭祥昊,钟义信.面向特定邻域的理解型中文自动文摘系统[J].计算机研究与发展,2000,37(4):6-10.
[9]刘挺,吴岩,王开铸.中文自动文摘系统CAAS 的研究与实现[J].哈尔滨工业大学学报,1999,31(6):59-62.
[10]蒋昌金.基于关键词提取的中文网页自动文摘方法研究[D].广州:华南理工大学,2010.
[11]陈学智.基于分层的中文句子相似度研究[D].长沙:湖南师范大学,2014.
[12]张华平.NLPIR 汉语分词系统[EB/OL].http://ictclas.nlpir.org,2015-10-15.
[13]刘佳宾,陈超,邵正荣,等.基于机器学习的科技文摘关键词自动抽取方法[J].计算机工程与应用,2007,43(14):170-172.
[14]钱爱兵,江岚.基于改进TF-IDF 的中文网页关键词抽取—以新闻网页为例[J].情报理论与实践,2008,31(6):945-950.
[15]江军.基于语义的自动文摘系统[D].成都:电子科技大学,2011.
[16]陈学智.基于分层的中文句子相似度研究[D].长沙:湖南师范大学,2014.
[17]张培颖.多特征融合的语句相似度计算模型[J].计算机工程与应用,2010,46(26):136-137.
[18]夏天.中文信息相似度计算理论与方法[M].1 版.郑州:河南科学技术出版社,2009.
[19]王腾毅.基于语义的中文自动文摘系统的设计与实现[D].厦门:厦门大学,2013.
猜你喜欢
环境影响评价(2020年2期)2020-12-02 01:23:50
当代陕西(2020年17期)2020-10-28 08:18:18
智富时代(2019年6期)2019-07-24 10:33:16
人大建设(2018年5期)2018-08-16 07:09:00
电信科学(2017年6期)2017-07-01 15:44:57
宝藏(2017年2期)2017-03-20 13:16:46
高中生·天天向上(2016年9期)2016-11-22 09:10:34
河南科技(2014年15期)2014-02-27 14:12:51
青苹果·教育研究版(2013年2期)2013-04-29 00:44:03
外语学刊(2011年3期)2011-01-22 03:42:20
