
基于视频监控场景的用户视觉注意力模型
2015-11-23 06:34刘仁砚蔡晓东黄嘉成梁东旭甘凯今
大众科技 2015年9期
刘仁砚 蔡晓东 黄嘉成 梁东旭 甘凯今
(桂林电子科技大学信息与通信学院,广西 桂林 541004)
基于视频监控场景的用户视觉注意力模型
刘仁砚 蔡晓东 黄嘉成 梁东旭 甘凯今
(桂林电子科技大学信息与通信学院,广西 桂林 541004)
视频监控图像帧中所有物体具有同等地位,造成用户感兴趣的物体并没有能够分配到更多的视觉注意力。文章针对视频监控场景,构造了一个两层的用户视觉注意力模型,首先,进行前景和背景的分类,其次,通过用户对前景和背景的理解,将物体的视觉重要性进行特征属性的抽象化表述,最后,根据注意力模型计算物体的重要性。模型旨在借鉴人类的视觉系统,获取一个基于视频监控场景的用户视觉注意力模型。实验表明,该模型获得了良好的效果。
视频监控;视觉注意力模型;物体重要性
1 引言
如何对大量的视频监控场景进行快而有效的分析,是监控领域亟待解决的问题[1]。人类的视觉系统通过判断视觉场景中物体的重要程度,能够准确、高效地将视觉注意力集中到重要的物体上,并对具有较高视觉注意力的图像信息进行细致而深入的分析。
在图像研究领域,描述场景的视觉注意力信息时常使用“显著图”的方法。文献[2]利用视觉显著图过滤与检索任务不相关的背景信息。文献[3]使用注意力驱动模型提取图像显著图,将能代表图像的部分分割出来。文献[4]通过计算图像灰度通道与彩色拮抗对的显著性描述,将三者的加权平均作为彩色图像的显著图。
然而显著图本身是基于对像素的操作获取的,既不能反映观察者感兴趣物体的重要性,无法完整地表示感兴趣物体的形状。对于抽象的人类视觉观察系统,如何去衡量观察者感兴趣物体的重要程度正是本文的主要研究内容。
2 模型框架与原理实现
人类的视觉注意力机制在处理复杂场景时,选择性地对信息进行分析和处理,从而使得视觉注意点集中在场景中的某些物体[5]。对观察者而言,物体的视觉重要程度取决于人类视觉系统对物体感知特征的敏感程度。在视频图像帧中,物体的视觉重要性可以被诸如运动、大小、纹理、颜色、位置等图像属性所表示,这些属性信息从不同方面表达了一个物体的重要性程度。使用图像属性对视频图像帧中物体的视觉重要性进行定义,这与人类视觉系统的工作方式相一致,由此,本文提出了一个基于图像属性的两层用户视觉注意力模型,模型结构如图1所示。

图1 用户视觉注意力模型的两层结构图
2.1第一层:前景和背景物体的分类
在用户视觉注意力模型中,对监控场景视频的前景物体和背景对象进行分类具有重要意义[6]。这是由于在对监控视频做进一步分析处理之前,选择一个依赖于应用并且有意义的视觉信息的子集特征可以减小场景分析的复杂性。这个特征就是人类视觉系统的“注意力特征”。由于使用摄像机进行监控的过程中,视频中背景物体往往要比前景物体大得多,而且对于本文研究的视频场景,抽取的前景物体才是人类感兴趣的目标,因此,把前景和背景的视频物体的大小、运动、位置和编码复杂度直接进行比较是不合理的。为了建立更为合理的视觉注意力模型,本文从最佳的视频质量控制的角度出发,创新性的把视频中的物体以组的形式进行分类,然后再去比较组中的重要性特征。
本文提出的物体重要性模型是根据视频物体的分类情况由组级别来确定各个视频对象的重要性。为了定义基于前景和背景组的重要性,用表示第t帧的第i个物体在前景和背景分类时的重要性,如下所示:

其中α和β依赖于视频监控的具体应用,当物体i属于背景时,其获得的重要性大小为α,当物体i属于前景时,其获得的重要性大小为β,(α,β)∈[0,1]且α+β=1。
2.2第二层:重要性特征的分析
在传统的多视频目标速率控制算法中,物体的大小是影响视频目标重要性的主要因素,但位置信息却没有被平等地对待。正常情况下,观察者更多关注的是处于视觉场景中心位置的物体,而且同一物体在不同的位置将会得到不同的注意力。由此可见,物体的位置信息对视觉注意力具有一定的影响,应该作为影响物体重要性的因素之一。
一方面,对于前景物体,本文采取的策略是使用大小和位置相结合的归一化高斯函数来定义物体的重要性。在第 t帧,物体i的大小和位置因子对于整个物体重要性的贡献定义如下:
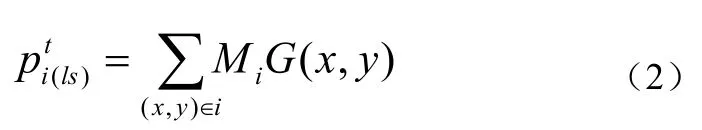
其中,iM是物体i的二元分割掩膜,x,y是物体的坐标,表示在中心位置(W-1)/2和(H-1)/2的归一化高斯函数,如下所示:

其中,xμ,yμ,xσ,yσ是x和y的平均值和标准差,满足:其中,T是向量转置,W和H分别表示视频帧图像大小的宽度和高度。
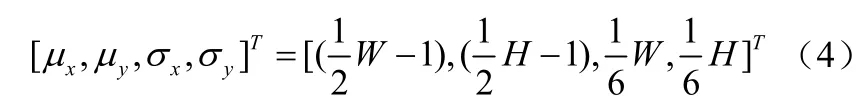
另一方面,对于背景物体,不管背景物体出现在什么位置都不是我们的感兴趣点,所以不考虑位置,只用大小来计量物体的重要性。此外,如果有多个背景物体时,每个物体的重要性将被同等对待,用同一个重要性参数计算背景物体的重要性,如下:
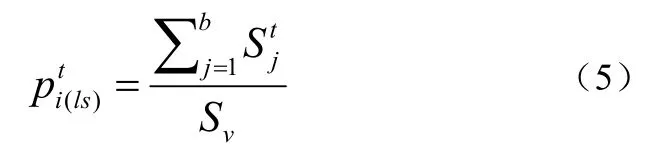
静态场景下,运动物体会更容易引起观察者的注意[7]。一般来说,在视频监控应用中,观察者注意的是相对运动或相对静止的前景物体而不是背景物体。因此,对于背景物体,运动不作为重要性考虑的因素。对于前景物体而言,物体本身和摄像头之间存在着相对运动的关系。具体的监控应用可分为以下两种情况:一种是摄像头固定,背景不变,前景相对摄像头运动;另一种是摄像头随着前景运动而相对静止。对于前者,在整个摄像头能摄取到运动物体的过程中,把相对运动的物体的运动作为重要性的度量。这是因为,如果一个前景物体在一个监控区域相对摄像头运动,它表明这个物体是观察者感兴趣的方面。对于后者,相对摄像头静止的运动常常度量重要性,它表明这个物体正在被跟踪而应该给与更高的视觉重要性。综上,无论是相对运动还是相对静止,用定义第t帧物体i的运动因子的重要性,如下式所示:
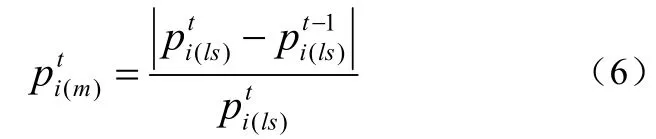
在两层用户视觉注意力模型中,编码复杂性是计算重要性所需考虑的另一个因素。传统方法中对于编码的复杂性通常使用变化程度来度量。在室外监控系统中,就强度变化而言背景物体是复杂的。但是,由于背景的复杂性不是观察者感兴趣的,所以并不意味着复杂的背景的重要性就高于简单的前景。这也使得传统度量编码复杂性的方法在许多场景没有明确的物理含义。因此,为了使编码更具意义性,对于前景物体i而言,用物体的任意形状区域的信息来度量物体重要性的编码复杂性,如式(7)所示:
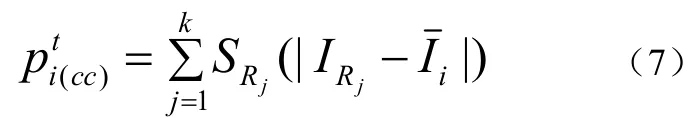
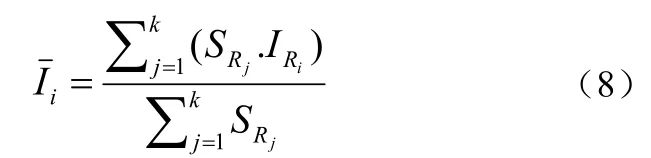
k,jRS和jRI由Blob块检测算法得到。
基于上述讨论,构成两层重要性模型的所有因子有:大小和位置因子,运动因子,编码复杂性因子,表示第 t帧的视频中物体i的总视觉重要性度量,如下式所示:
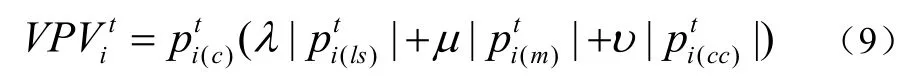
其中,|.|表示每个因子的归一化运算,λ,μ和υ分别表示了大小和位置,运动以及编码复杂性的权重。它们表示在观察者的视角每一个参数的重要性,约束条件是(λ,μ,υ)∈[0,1]且λ+μ+υ=1。
3 实验结果
为了验证所提出的基于视频物体本身的两层用户视觉注意力模型的有效性,实验选取一段行人视频序列的前60帧进行视频物体重要性的计算。
对于本文的视频监控场景而言,前景物体比背景物体更加的重要,同时,每一个前景物体的大小和位置、运动、编码复杂性都具有相似的重要性,所以,基于该视频序列,可设置相似的权重值(λ,μ,υ)=(0.3,0.4,0.3)。需要指出的是,这三个权重参数是根据具体的应用场景进行设置。
如图2所示,视频场景中包含三个物体:行人A、行人B和道路。行人A和行人B是前景物体,道路作为背景物体。视频中,行人A现在中心位置逗留,然后向左移动,逐渐走出监控区域,行人B从左向右走过从监控区域。前45帧行人A在视频的中心位置附近,这是观察者注意力集中的地方。随着行人A远离中心的位置,行人B往视频中心的方向靠近,使得行人B逐渐得到越来越多的视觉注意力而越来越重要,反之,行人A越来越不重要。

图2 (a)原始视频帧图像;(b)提取的前景物体;(c)提取的背景物体

图3 影响物体重要性的特征因子分析图
由图 3(a)可知,对于大小和位置高斯函数确定的物体重要性而言,在26帧之前,由于行人A处于视频的中心位置附近,行人B在视频的左侧,此时,行人A的值高于行人B。随着行人A在中心位置的偏离,行人B从左侧渐渐走入视频画面,两者大小和位置均发生变化,在32帧之后使得行人B越来越重要,其值最终高于行人A的。
由图3(c)可知,图2中两个前景物体的区域色彩已经确定,使得行人A的总是高于行人B且相差不大。
由图3(d)可知,48帧之前行人A比行人B得到了更多的注意力,之后行人B逐渐成为用户注意力的中心所在,而且,背景信息的重要性远远小于行人A和行人B的重要性。
4 结论与分析
本文提出了一种针对视频监控场景的两层用户视觉注意力模型,能够准确的描述视频图像中吸引注意力的物体信息。通过计算视频物体的VPV值来定义物体的视觉重要性。这种模型可以容易地运用到视频的快速分析算法中,进一步保证了分析的正确性和鲁棒性。接下来的研究工作将重点放在视觉注意力模型的应用部分,希望能联合模型本身应用到具体的视频分析中,如行人检测与跟踪。
[1] 梁晔,刘宏哲.基于视觉注意力机制的图像检索研究[J].北京联合大学学报(自然科学版),2010,24(1):30-35.
[2] 胡胜雄,尚赵伟,张太平,等.基于视觉显著图的彩色图像检索[J].计算机工程,2012,(8):189-191.
[3] 王雪峰.一种基于注意力驱动模型提取图像显著图的方法[J].伊犁师范学院学报(自然科学版),2011,(1):58-61.
[4] 黄虹,张建秋.彩色自然场景统计显著图模型[J].复旦学报(自然科学版),2014,53(1):51-58.
[5] 叶刚.基于视觉注意的立体视频感兴趣区域提取[D].杭州:浙江大学,2013.
[6] 李庆武,蔡艳梅,徐立中.基于分块分类的智能视频监控背景更新算法[J].智能系统学报,2010,(3):272-276.
[7] 孙业.基于运动选择注意的目标跟踪系统的研究[D].天津:河北工业大学,2012.
User visual attention model based on video surveillance scene
All objects in the frame of surveillance video have equal status, so that the objects which users interested in may not have more attention. A two-level user visual attention model are proposed for video surveillance scenes in this paper. Firstly, classify foreground and background objects, and then, according to user’s understanding of foreground and background, abstractly express the visual importance related to feature property, finally, calculate the visual importance of the object according to visual attention model. In video surveillance scene, the model aim to extract a user visual attention model learn from the human vision system. The validity of the model has been confirmed through a series of experiments.
Video surveillance; visual attention model; importance of objects
TP391.4
A
1008-1151(2015)09-0030-03
2015-08-10
国家大学生创新性实验计划(101059509)。
刘仁砚(1995-),男,桂林电子科技大学信息与通信学院学生,研究方向为通信工程;蔡晓东(1971-),男,桂林电子科技大学信息与通信学院硕士生导师,研究方向为图像和视频处理、模式识别与智能系统。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
建材发展导向(2021年6期)2021-06-09
意林(2021年5期)2021-04-18
今日农业(2020年17期)2020-12-15
中国外汇(2019年11期)2019-08-27
扬子江(2019年1期)2019-03-08
传媒评论(2017年3期)2017-06-13
小天使·一年级语数英综合(2017年6期)2017-06-07
汽车与安全(2016年5期)2016-12-01
第二课堂(课外活动版)(2016年2期)2016-10-21
