
一种AMP架构下的处理器负载均衡改进方法
2015-11-17 11:56:52蒋建军刘彤
山东农业大学学报(自然科学版) 2015年1期
蒋建军,刘彤
1.上海电机学院电子信息学院,上海200240
2.武汉理工大学信息工程学院,湖北武汉430070
3.北京天融信网络安全技术有限公司,北京100085
一种AMP架构下的处理器负载均衡改进方法
蒋建军1,2,刘彤3
1.上海电机学院电子信息学院,上海200240
2.武汉理工大学信息工程学院,湖北武汉430070
3.北京天融信网络安全技术有限公司,北京100085
在多核异构方式下,由于数据流大小差异很大,在检测处理器检测数据流时耗时较长,导致了检测处理器之间的负载处于不均衡状态。同时,在网络处理器和检测处理器之间由于是固定任务分配,不可能做到完全均衡。针对存在的这些缺陷,提出了循环工作队列方法,可以动态感知处理器负载均衡态势,改进了检测处理器均衡方法,进一步提高了检测处理器的性能发挥,解决了网络处理器和检测处理器之间无法均衡的问题,提升了系统的整体性能。
IPS;AMP构架;异构方式;检测处理器;负载均衡
近几年,入侵防御系统IPS(Intrusion Prevention System,入侵防御系统)[1]产品已成为安全产品市场的热点,不仅保持了每年100%以上的市场增长率,而且应用领域不断扩大,应用技术也逐步普及。与传统的IDS[2]旁路接入不同,IPS产品采用在线工作方式,即对接收的数据进行检测,然后按照其目的转发,这与安全网关类产品如防火墙、VPN(Virtual Private Network,虚拟专用网)[3]等非常相似。这种工作方式决定了IPS产品除了要有准确的检测能力,还要有与应用网络相适应的性能要求。
实际上自IPS产品诞生以来,一直采用协议识别和攻击特征模式匹配等成熟技术,困扰其应用范围的主要是性能要求。目前的防火墙达到千兆线速、4 G、甚至10 G转发能力已属平常,但IPS要实现这一性能绝非易事。在IPS中不仅需要检查数据报文的头部,还要针对具体的应用协议检查数据报文的内容,这就使得在IPS中五元组相同的数据报文也不能“加速处理”,也就是说在IPS处理数据报文的整个路途中没有“捷径”,IPS需要对流经自身的每一个报文进行逐一检测。这样IPS成为CPU[4]资源的主要耗费者,其性能很大程度上取决于硬件处理器的处理能力。
近年来多核处理器的发展为利用并行处理技术提升IPS产品性能提供了广阔的空间,由于处理器计算能力的提升对IPS检测全路径都是有效的,所以从理论上讲内核数量与性能提升成正比。但是理论不等于实践,实际性能的提升主要取决于IPS对各个处理器均衡的利用,即发挥每一个处理器的最大计算能力。
1 现有处理器工作架构
1.1 同构方式与异构方式
在多核并行计算环境中一般有两种处理器工作构架,一种是SMP(Symmetrical Multiprocessing,对称多处理)[5]方式,也称为同构方式,SMP方式顾名思义就是将多个内核平等看待,每个内核担负的工作都相同,且每个内核上都运行一套IPS系统,这样从数据接收、连接建立、数据检测到数据发送都是并发执行的,相当于多个IPS系统在同时运行。这种架构比较简洁,各个处理器内核负载均衡,但是因为所有内核都担负相同的工作,势必产生对共享资源(内存数据、文件描述符、I/O[6]设备等)的大量争用,为处理这些并发与同步使用的大量锁机制,又严重制约了性能发挥,更严重的是随着内核数量的增多,并发与同步的消耗达到一定的量级,性能不但不会增长反而会有所下降。
另一种为AMP(Asymmetric Multi-processing,非对称多处理)[7]方式,也称为异构方式,如图1所示为AMP方式示意图(以4核为例)。
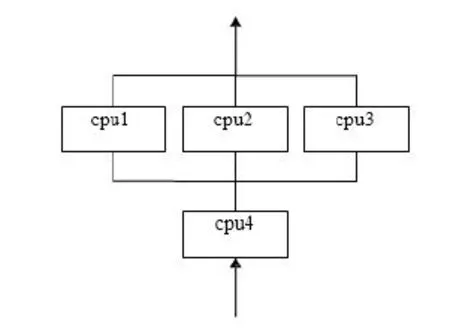
图1 AMP方式示意图Fig.1 Schematic diagram of AMP
AMP方式就是将多个内核区别看待,可以运行不同的操作系统也可以在相同的操作系统上运行不同的任务,各个处理器内核按照任务划分,各负其责,规避共享资源的竞争,做到“术有专攻”,从而提升IPS产品的综合性能。完整的操作系统往往比较庞大,耗费资源较多,效率也较低。拿出几个物理内核,在其上建立一种简易的系统环境(有时候直接叫做“裸核”环境),在这个“洁净的空间”内运行单一任务(比如收发数据、模式匹配等)往往可以获得极高的性能,这是AMP方式的特点,也是其优势。虽然AMP构架比较复杂,但因其性能提升非常有效,目前已被广泛应用。
AMP构架的难点在于需要仔细权衡各个内核的任务分担,否则会造成内核负载不均衡,影响性能发挥。目前普遍采用的方法是将处理器内核分为两类,一类叫作网络处理器,用于处理网络数据报文的接收和发送,另一类叫做检测处理器,用于进行IPS检测。网络处理器接收到网络数据报文后,根据其五元组建立连接(数据流),然后用hash[8]算法将连接平均地定位到唯一的检测处理器上,这样实现负载均衡,即将数据流平均地分配到检测处理器上,同时保障将同一个数据流分配到同一个检测处理器上,保障一个数据流始终由一个检测处理器处理。
1.2 现有工作构架的技术缺陷
如图2所示为原有的处理器负载均衡方法示意图,该方法的缺陷是,虽然数据流被相对均衡地分配到检测处理器上,但是因为不同的数据流中包含的数据报文个数、报文大小、报文内容都差异很大,这直接导致检测处理器检测数据流的速度不相同,如有的报文比较小甚至不包含应用层数据,无须进行IPS检测,可以快速地处理完毕,而有的数据报文是http协议[9]且包含丰富的uri[10]信息,有大量的IPS规则需要逐一匹配检测,势必耗时较长。这导致了检测处理器之间的负载实际上处于不均衡状态,影响了性能发挥。另一方面,在网络处理器和检测处理器之间是固定任务分配,而网络处理与检测处理两种工作不可能正好均衡,这也影响了整体性能的提升。
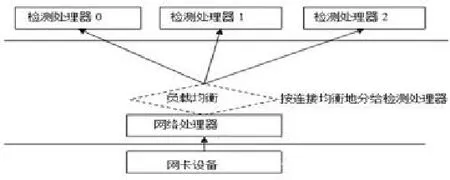
图2 原有的处理器负载均衡方法示意图Fig.2 The original processor load balance method diagram
2 一种改进的处理器负载均衡方法
为解决上述问题,提出了一种改进的处理器负载均衡方法,以最大限度地发挥处理器计算能力,如图3所示为改进的处理器负载均衡方法。
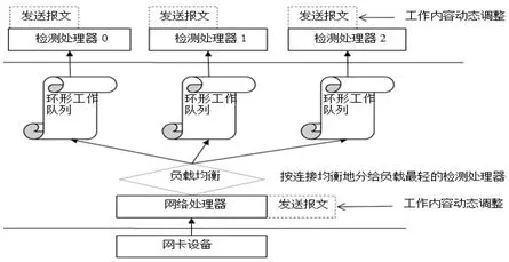
图3 改进的处理器负载均衡方法示意图Fig.3 Improved processor load balance method diagram
主要方法如下:
(1)建立环形工作队列,动态感知处理器均衡态势。
(2)在检测处理器之间进行数据流重定向
(3)在网络处理器与检测处理器之间进行工作任务动态调整。
2.1 建立环形工作队列
(1)为每个检测处理器创建一个普通的队列数据结构,并建立队列头和队列尾指针。
(2)网络处理器接收到数据报文后,需要提交检测处理器检测时,将该数据报文的报文信息(包括协议类型、所属数据流、报文大小等信息,但不包含数据报文本身)加入到队列尾部,队列尾可以循环从头开始,但不能超过队列头。
(3)检测处理器从队列头中依次取出报文信息,根据该信息对数据报文内容进行IPS检测处理,处理后队列头依次后移,队列头也可以循环从头开始,但不能超过队列尾。
2.2 动态感知处理器均衡态势
(1)定时依次检查每一个循环工作队列的队列头和队列尾。
(2)如果队列头尾距离很远,说明队列中积压了很多待处理数据报文,该检测处理器负载较重。当头尾距离等于队列数据结构长度时,说明队列已满,该检测处理器负载已达到极限,已无法再接收数据报文。
(3)如果队列头尾距离很近,说明队列中没有积压的待处理数据报文,该检测处理器负载较轻。当头尾距离等于零时,说明队列为空,该检测处理器没有负载,处于“吃不饱”状态。
(4)通过不断地检查各个检测处理器的负载情况,就能够有效地动态感知到处理器均衡态势。
2.3 在检测处理器之间进行数据流重定向
(1)网络处理器接收到数据报文,根据其五元组建立连接,再根据连接确定其捆绑的检测处理器。
(2)利用循环工作队列动态感知该检测处理器的负荷,如果负荷较重,则重定向连接到其它的检测处理器上。此时负载均衡方法由原来的“按连接均衡地分给检测处理器”改进为“按连接均衡地分给负载最轻的检测处理器”。
2.4 在网络处理器与检测处理器之间进行工作任务动态调整
(1)将一些报文后续处理工作(如记录日志、报文转发等)独立出来,使得它们既可以在网络处理器上运行,也可以在检测处理器上运行。
(2)正常情况下,这些独立的工作由网络处理器负责,检测处理器由开关控制,默认关闭。
(3)利用循环工作队列动态感知检测处理器的负载,如果发现所有检测处理器负载均很轻,则打开开关,使得检测处理器参加后续报文处理工作,增加检测处理器负载,同时减轻网络处理器负载,在两种处理器之间进行工作任务动态调整。
3 一个具体实施实例介绍
以四核处理器为例,详细说明一种改进的处理器负载均衡方法的具体处理流程,是如何以最大限度地发挥处理器计算能力的。
3.1 建立环形工作队列
分别为检测处理器0、检测处理器1和检测处理器2创建一个普通的队列数据结构,队列长度为512,即最大可以缓存512个报文信息,同时分别建立队列头和队列尾指针。
环形工作队列的工作方式是,当网络处理器接收到数据报文后,根据其源地址、目的地址、源端口、目的端口查找连接,如果查找不到需要新建立一个连接结构,然后将报文协议类型、报文大小、报文数据地址、连接句柄(指向连接结构的指针)等信息组成一个报文信息结构,加入到队列尾部,队列尾可以循环从头开始,但不能超过队列头。
检测处理器从队列头中依次取出报文信息,根据该信息对数据报文内容进行IPS检测处理,处理后队列头依次后移,队列头也可以循环从头开始,但不能超过队列尾。
3.2 在检测处理器之间进行数据流重定向
实现过程如下:
(1)网络处理器接收到数据报文,进行初步分析,非TCP/UDP报文[11]不处理直接转发,对于TCP/UDP报文根据其五元组(源地址、目的地址、源端口、目的端口、协议)[12]计算hash值,再根据Hash值查找连接,如果查找到连接直接进行(4)。
(2)对于没有查找到连接的,需要新建立一个连接结构,一个连接结构实际上对应一个数据流。
(3)对连接的hash值除以cpu个数减1,然后取余,得到的值在0~2之间,这个值就是这个连接对应的检测处理器序号,将序号记录到连接结构中,这样不用每次都计算。
(4)取出连接中记录的检测处理器序号,找到其一一对应的环形工作队列,检查环形工作队列的头尾指针,如果头尾指针差距小于512则说明队列未满,直接进行(6)。
(5)队列已满则继续检查下一个处理器的环形工作队列,如果未满,则更改连接中的检测处理器序号,将连接重定向到新的检测处理器。如果所有检测处理器的环形工作队列均满,则只能放弃检测,直接转发该连接。
(6)生成一个报文信息结构,包含报文协议类型、报文大小、报文数据地址、连接句柄(指向连接结构的指针)等信息,从队列尾部加入环形工作队列,等待检测处理器检测。
3.3 将发送报文工作独立出来
(1)将发送报文部分程序独立成一个模块,使得网络处理器可以调用,同时检测处理器也可以调用。当网络处理器调用发送报文模块时,该模块代码是在网络处理器上运行的,占用网络处理器负载。当检测处理器调用发送报文模块时,该模块代码是在检测处理器上运行的,占用检测处理器负载。
(2)设置一个开关,正常情况下处于关闭状态。该开关关闭时由网络处理器调用发送报文模块,检测处理器不调用。开关打开时正好相反。
3.4 工作任务动态调整
在网络处理器与检测处理器之间进行工作任务动态调整,方法如下:
(1)设置一个定时器,定时检查各个检测处理器的环形工作队列。
(2)如果所有环形工作队列均队列头与队列尾相等,则说明检测处理器负载较轻,此时打开开关,在网络处理器与检测处理器之间进行工作任务动态调整。
4 结论
改进后的技术方案,与现有技术相比,具有以下优点,改进后的办法提出了循环工作队列方法,可以动态感知处理器负载均衡态势。改进了检测处理器均衡方法,进一步提高了检测处理器性能发挥。解决了网络处理器和检测处理器之间无法均衡的问题,实现了系统整体性能的提升。
[1]Kivity A,Kamay Y.kvm:the Linux virtual machine monitor.In 2007 Ottawa Linux Symposium,2007:225-230
[2]Ashoor,Asmaa Shaker.Difference between Intrusion Detection System(IDS)and Intrusion Prevention System(IPS). Communications in Computer and Information Science,v 196 CCIS,Advances in Network Security and Applications-4th International Conference,2011:497-501
[3]Chen Fei;Wu Kehe.The research and implementation of the VPN gateway based on SSL.Proceedings-2013 International Conference on Computational and Information Sciences,ICCIS 2013,2013:1376-1379
[4]陈晓娇,哈力木拉提·买买提.一种基于HMM的维吾尔文联机手写识别的方法[J].计算机工程与应用,2013,49(24):1 75-178
[5]胡亮,解男男,努尔布力,等.基于智能规划的多步攻击场景识别算法[J].电子学报,2013,41(9):1753-1759
[6]陶文君,胡斌.一个可抵抗临时指数泄露的密钥协商协议形式化安全模型[J].计算机科学,2013,40(11):97-102
[7]张思亮,李广霞.子空间聚类在入侵检测中的应用[J].计算机安全,2013,12:2-6
[8]王文迪,汤文.基于Hash索引的高通量基因序列比对并行加速技术研究[J].计算机研究与发展,2013,50(11):2463-2471
[9]王丽娜,刘炎,何军.基于IPSec和GRE的VPN实验仿真[J].实验室研究与探索,2013,32(9):70-75
[10]Richard Deal.Cisco VPN完全配置指南[M].北京:人民邮电出版社,2012:67-74
[11]应宇锋,王桢珍,王晓云.MPLS VPN技术在WLAN接入分组域中的应用与研究[J].软件,2012,33(9):74-76,80
[12]Wendell Odom,Rus Healy,Denise Donohue.CCIE routing and switching[M].北京:人民邮电出版社,2009:350-380
An Improved Method to Optimize the Load Balance of Processor under AMP Pattern
JIANG Jian-jun1,2,LIU Tong3
1.School of Electronic Information,shanghai Dianji University,Shanghai 200240,China
2.School of Information Engineering,Wuhan University of Technology,Wuhan 430070,China
3.Beijing Topsec Network Security Technology Co.,Ltd.,Beijing 100085,China
In the heterogeneous multi-core mode,the data stream size difference is very big,in the detection of the processor detects data stream is time-consuming,so as to lead to the load detection between processors is actually not equilibrium state. Because it is a fixed task allocation between network processor and detection processor,it is not possible to completely balance.Aiming at these defects,this paper proposed the circular queue method to perceived the load balancing situation of dynamic processor,and to improve the equalization method of the detection processor,to further improve the detection processor performance,to solve that the network processor and detection processor cannot balance problems,to improve the overall performance of the system.
Intrusion prevention system;Asymmetric Multi-Processing framework;heterogeneous;detection processor;load balance
TP3
A
1000-2324(2015)01-0096-05
2013-05-10
2013-05-19
上海市科委基金资助(14511108003)
蒋建军(1967-),男,上海市人,副教授,硕士,主要研究方向:信息技术、网络、虚拟化技术及应用.E-mail:Jjjiang@189.cn
猜你喜欢
现代装饰(2022年4期)2022-08-31 01:41:24
今日农业(2021年9期)2021-07-28 07:08:36
汽车维修与保养(2020年11期)2020-06-09 05:42:22
小学生学习指导(低年级)(2020年4期)2020-06-02 09:09:26
软件(2020年3期)2020-04-20 00:58:44
成都信息工程大学学报(2018年4期)2019-01-23 06:57:18
信息安全研究(2018年12期)2018-12-29 11:01:56
军营文化天地(2018年2期)2018-12-15 17:39:08
电脑与电信(2018年12期)2018-03-23 02:37:36
产品可靠性报告(2017年7期)2017-09-05 09:49:12
