
实际工作场景中oracle数据库数据快速倒换方法
2015-11-07 05:32应天职业技术学院
电子世界 2015年14期
应天职业技术学院 谢 芳
实际工作场景中oracle数据库数据快速倒换方法
应天职业技术学院 谢 芳
本文通过设立实际工作场景,提出一种切实可行的将oracle数据库中数据按照某种原则搬到新的数据库中,通过此种方法实现的数据倒换可在主机上形成一个脚本,启动脚本后数据自动倒换。在实际应用中,有利于提高工作效率。
oracle数据库;数据倒换
1 引言
一个比较大的实时系统,经过调研、立项、设计、开发、测试、验收之后,往往会面临更大的挑战:割接上线。割接上线中,一个非常重要的准备就是数据倒换。数据倒换,简而言之,就是将生产库中的数据按照某种原则搬到新的数据库中,是系统正确运行的基础,其重要性不言而喻。而且非常特别的是,它的数据量很大,时间紧张,有必要进行经过充分的准备。
在本文中,我们将设立一个场景,并基于这个场景进行讨论倒换的方法,之后对于性能进行一些更细致的研究。通过研究,能达到在主机上有一个脚本,启动脚本,那么数据就可以实现这样的倒换。将具有一定的普适性。
2 场景介绍
oracle数据库之间数据倒换在此利用存储过程(procedure)来实现数据倒换。情景如图1:
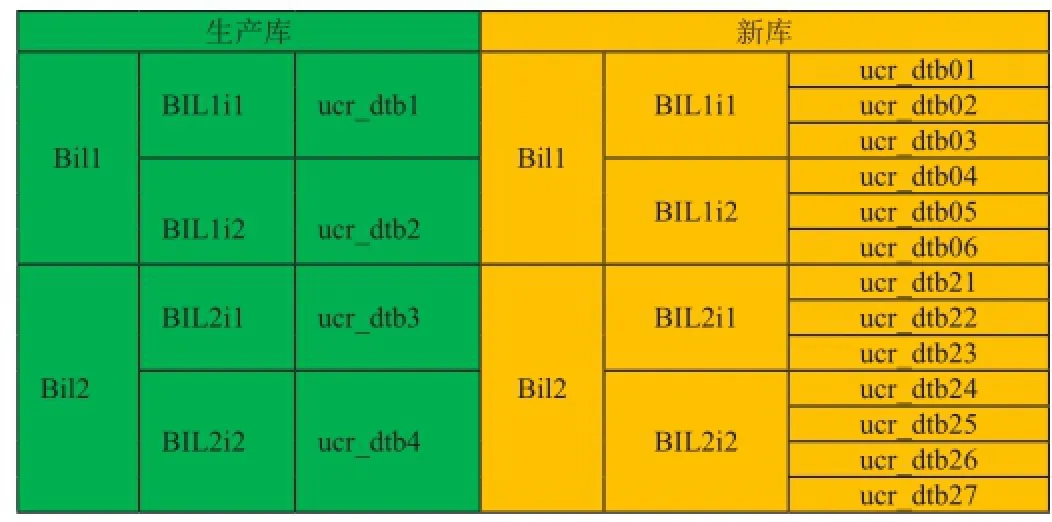
图1 工作场景示意图
生产库有2个库,4个节点,4个用户;而新库有2个库,2个节点,13个用户。
新库之所以会做出这样的变动,是因为随着在线用户的变多,数据量变大,所以需要将数据进行拆分。
3 实现方法
为了实现这样的目标,我们需要考虑如下技术的可能性:
(1)启动脚本,脚本来执行存储过程,并带入存储过程所需要的参数;
(2)存储过程能够从生产库取数据,并根据拆分原则,拆分到新库中;
3.1 脚本
对于第(1)点,首先构建一个执行存储过程的函数,保存为脚本,执行的时候直接进行调用。
executeProcedure()
{
DB_USER=$1 #参数1
shift
DB_PASSWD=$1 #参数2
shift
DB_SERVER=$1 #参数3
shift
PROCEDURE_NAME=$1 #参数4
shift
PROCEDURE=${PROCEDURE_NAME}"("
while [ "$#" -ne "0" ]
do
PROCEDURE=${PROCEDURE}$1"," #存储过程本身的参数
shift
done
PROCEDURE=${PROCEDURE}":v_resultcode,:v_errinfo)"
${ORACLE_HOME}/bin/sqlplus ${DB_USER}/ ${DB_PASSWD}@${DB_SERVER} << !!!
WHENEVER sqlerror EXIT sql.sqlcode
SET SERVEROUTPUT ON
VARIABLE v_resultcode NUMBER;
VARIABLE v_errinfo VARCHAR2(2000);
BEGIN
:v_resultcode := 0;
BEGIN
DBMS_OUTPUT.enable;
${PROCEDURE}; #执行存储过程
DBMS_OUTPUT.put_line('v_res:='||:v_resultcode);
DBMS_OUTPUT.put_line('v_err:='||:v_errinfo);
EXCEPTION
WHEN OTHERS THEN
:v_resultcode := -1;
:v_errinfo := SQLERRM;
return;
END;
COMMIT;
END;
/
exit;
!!!
return 0
}
通过以上代码己完成,脚本来执行存储过程,并带入存储过程所需要的参数。如果想加以利用,还需要考虑输出日志等问题。
有了这个函数,就可以在主机上通过输入数据库的用户名、密码、server、存储过程名、存储过程参数,来调用数据库某用户下的存储过程了。如果将这样的命令整合在一起,就可以用一个脚本调用不同数据库上、不同用户下的不同存储过程了,通过这样的处理,工作效率就会大大提高。
3.2 过程
如果不需要拆分可用Insert …select…语句就可以实现这个功能。需要拆分时将ucr_dtb4下的用户根据路由表tf_f_user_cataloG表拆分到ucr_dtb25、ucr_dtb26、ucr_dtb27三个用户下。可以将上述语句进行改造达到功能:
Insert
When n_channel_no>0 and n_channel_no<=3333 into ucr_dtb25.tablename values(…)
When n_channel_no>=3334 and n_channel_no<=6666 into ucr_dtb26.tablename values(…)
When n_channel_no>=6667 and n_channel_no<=9999 into ucr_dtb27.tablename values(…)
Select …
Decode(select channel_no from tf_f_user_cataloG b where b.user_id=a.user_id,null,mod(user_id,10000) , select channel_no from tf_f_user_cataloG b where b.user_id=a.user_id) as n_channel_no
From ucr_dtb4.tablename@dblink4 a;
这段语句中的几点解释:(1)如果when语句比较长,在调试存储过程时,会看不到这个语句,所以可以将各个when语句依次放入数组元素中,select语句也放入一个数组元素中,最后将它们拼接起来执行。这样的话将对调试非常有利。(2)如果路由表tf_f_user_cataloG表中的数据量非常大,例如超过1亿,那么全表扫描将是一个灾难。这里提供两个思路,首先,将这个表进行拆分,建多张表,语句中调用哪个表,可以通过存储过程的入参来决定。其次,在这张表上建立关联索引。这样一来速度可以提高几百倍。
如果存储过程和脚本都己经具备,接下来要考虑的问题就是执行的问题了。可能需要频繁的关注主机上的各种资源,尤其是CPU、Network等。
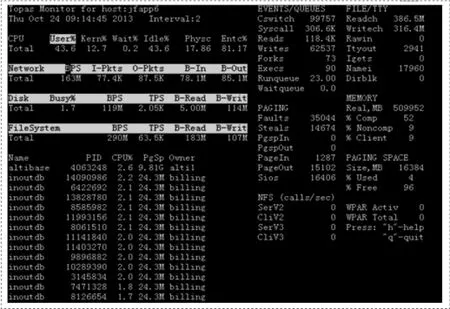
可以关注上图中的数据吞吐量,来确定存储过程的执行是否正确。也可以在oracle数据库上通过如下语句来确认,存储过程的启动与否,该语句的执行效率通常来讲是可以接受的:
select Name
from v$db_object_cache
where locks>0 and pins>0 and type=’PROCEDURE’;
4 结论
通过本文提供的oracle数据库的数据倒换方法可以将大量的数据快速的倒换到新的数据库中,为上线割接做好充分的数据准备,具有普适性,有一定的实用价值。
[1]杨九菊.Oracle数据库流复制技术研究[J].信息与电脑(理论版),2011(03).
[2]王新伟.基于Oracle数据库的逻辑数据同步技术在实践中的应用研究[J].电子技术与软件工程,2015(08).
[3]陈惠敏,李晓玲.Oracle实例剖析[J].软件导刊,2010(05).
[4]史小玲.Oracle动态SQL之本地动态SQL的使用[J].科技信息,2010(10).
[5]王海翔.Oracle数据库软件研究[J].现代商贸工业,2010(11).
猜你喜欢
作文小学中年级(2022年11期)2022-11-25
课堂内外(小学版)(2020年11期)2020-12-04
新世纪智能(语文备考)(2020年4期)2020-07-25
商品与质量(2019年34期)2019-11-29
测控技术(2018年5期)2018-12-09
中学生(2017年19期)2017-09-03
中学生(2017年1期)2017-03-24
信息安全研究(2016年4期)2016-12-01
语文知识(2014年4期)2014-02-28
中国信息化·学术版(2013年1期)2013-05-28
