
基于Hadoop平台下Skyline查询算法优化研究
2015-11-07 08:52王志力王彦丽李广庆
中国科技信息 2015年24期
王志力 王彦丽 李广庆
基于Hadoop平台下Skyline查询算法优化研究
王志力 王彦丽 李广庆
本文利用云计算下Hadoop平台搭建实验环境,在每个存储数据的节点上对数据建立R-树索引,将操作分散到分布式索引集群的各个节点上,同时采用云计算下现有优秀的Hadoop平台调度算法,提高Map/Reduce性能,通过设计和改进一种基于索引并行的近邻NN(Nearest Neighbor,最近邻)算法。通过实验测试,体现算法的优越性和渐进性,从而减少I/O的读取次数和CPU的计算成本,最终实现数据的查询处理优化目的。
Skyline查询算法在实际应用中确实表现出不错的查准率和查全率,目前很多改进的Skyline查询算法查询效率都不是很高,所以面对海量数据时,查询算法主要改进查询时间效率,渐进性,负载平衡和数据容错性处理等方面。目前主要从数据库存储方式方面设计Skyline查询算法,大多是在数据节点上建立索引达到查询优化的目的。
Skyline计算
Skyline计算应用于很多不同领域的数据集,比如集中式数据库、时空数据库、数据流、分布式数据库和属性数据分类数据中。Skyline算法主要偏向于个人偏好查询,在数据库中搜索不被支配的点。一个点所以支配另外一个点是因为第一个点至少肯定有一项要比另外一个点要好,该算法主要根据用户的选择和喜好找到适合的语义。Skyline计算在数据领域的定义:在一个数据集中D={s1,s2,s3,…sn},其中各数据点可表示为Si={p1,p2,…,pn},i=1,2,3,…n-1,n。对于任何一个pi∈D,pi∈(0,1),对于pi来说,数据的属性值越小越好。查询对象数据集合中所有不被其他点支配的点组成的集合谓Skyline查询;其中每个点称之为SP。本文中的Skyline查询优化算法采用索引技术,减少Skyline计算中SP点和点之间的比较次数,然后尽可能的找到最合适的SP点。
最近邻的Skyline查询算法
基于索引的Skyline算法是指在输出用户自己要查询的SP点前,首先建立分布式数据结构,通过利用用户建立的索引,尽量减少Skyline计算过程中点和点比较的次数,优先找出最可能得SP点。一般的Skyline查询算法比较次数的最好情形为O(kn),最坏复杂度为O(kn2)。最近邻算法(NearestNeighbor,简称NN)是对数据对象构建R-树索引,求出距离最近的点,对该点进行数据分区,构建矩形区,同时递归调用算法来计算,直到分区中不含有任何Skyline查询结果为止。NN算法的是在数据集中找到的k个最近的邻居,根据分类属性统计,统计出的结构按照分类属性来赋值。因此在类别决策时,只与极少量的相邻样本有关。NN算法主要靠极少的邻居样本进行分类,它更应用于类别比较多的数据。
Hadoop平台上NN算法查询优化研究
改进NN查询算法
Skyline查询改进后使用分枝界定法。首先采取R-树遍历,然后再访问MBR分配到各层。从根结点N开始,对所有的结点离根节点N的距离进行计算,分片采用升序方式存储在内存堆栈中,如果结点不被SP中的点支配,继续遍历其孩子结点,若孩子结点被SP支配,那么放弃这个结点,否则继续存储在内存堆栈中,如此循环下去直到找到叶子结点并且不被SP支配,那么这个点一定是Skyline点。把这个点存储在表中。循环如此,直到堆栈为空。在每次查询过程中需要执行多次Skyline查询,多次遍历R-树。
改进后的算法采用一种相互Skyline查询,在查询过程中利用局部查询得到Skyline集合来尽量减少SP点,提高搜索效率,减少I/O开销。当数据量非常大的时候,可能出现错误不能保证查询正常进行,运行故障监测和任务迁移,在查询过程中找到发生的故障,将故障中的任务迁移到副本,尽量保证查询的正常执行。图1是M=2阶R-树,图2是M=2阶R-树在二维空间上的表现形式。
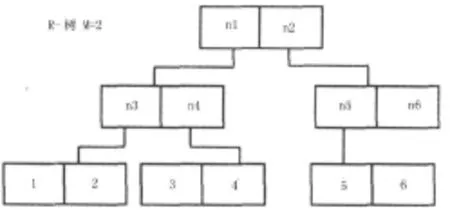
图1 M=2阶 R-树
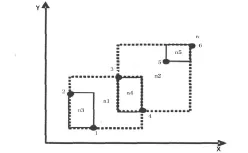
图2 R-树二维空间上的表现形式
具体步骤如下。
(1)将根所包含的结点n1升序放入堆D1中,同时将根所包含的结点n2升序置入堆栈D2中。
(2)首先对最近距离节点n1操作:移出栈中的n1,将n1的2个孩子(n3,n4)插入堆栈D1中,然后在对n3节点进行扩展,由于n3的两个孩子结点(1、2)结点不被S1支配,将(1、2)插入堆栈D1里,移出最小距离的1,2,因为1和2是叶子的结点并且同时不被S所能支配,于是1、2就被放入Skyline点的固定列表S中。这样我们就得到了局部的skyline点。通过用S1中的点与后面堆D1中的结点比较要被扩展后的结点n4,如果n4被S中的已经插入的点支配,所以n4移除,当堆栈D1为null时,S1中的点确认为全局的Skyline点。
(3)同样的道理,对于(2)中的可以操作:将(5、6)插入堆D2中,这样我们就得到了局部的Skyline点。通过用S2中的点与后面堆D2中的结点比较要扩展的是结点,当堆D2为空时,S2中的点就是局部所有的Skyline点。
(4)我们将S1中的全局Skyline点(1,2)与S2中的局部Skyline点(5,6)进行比较交集,得出S=(1,2)。
(5)局部Skyline查询找到点的时候不断的更新这个查询点,全局Skyline查询则不需要。
当数据量非常大的时候,容易出现局部Skyline集合发生故障,比如堆过大,线路中断等情况。在算法执行过程中协调者一直在监测整个查询过程,局部Skyline计算过程中周期性地保存中间结果和计算状态至可靠节点。
(1)协调者接收查询请求后,将查询请求运行;
(2)协调者把发送查询后接收所有返回局部Skyline集合放入Sn中;
(3)如果有未返回的局部Skyline集合,协调者发送消息探测等待看是否发生故障,如果未发生故障,则合并所有局部Skyline数据集;把所有的局部合并成全局Skyline集合;
(4)协调者将全局Skyline集合返回给用户,查询成功,退出;
(5)否则记录故障,找到故障写入访问记录文件RecordFile;
(6)检查RecordFile的status是否完成;若是完成则继续查询执行(2),否则取出SP(dn),通过比较数据副本的负载平衡,用state记录副本节点的忙闲,堆D(n)中等待该副本节点的运行者,Time记录副本节点最近一次更新的时间;
(7)查找空闲副本,重新发送请求,找到合适数据副本的节点继续执行(3)。
算法分析
通过分支界定法,局部查询算法,查询次数算法执行访问结点的数目(N)小于s*h(h为R-树的高度),减少了SP点的访问次数。算法所需的堆中结点的数目应小于(s-1)*N。不符合的SP点直接支配剪掉,不影响后续查询。
算法实验评估
本文实验环境在百兆局域网中的5台PC机中运行,配置为:处理器:IntelCorei3-3210M(2.5GHz/ L33M),内存容量:2GB,硬盘容量:80GB,操作系统为WindowsXP。准备多台服务器,虚拟机VMware的安装,下载安装软件并分别在5台机器上安装。由于5台机器的D盘剩余空间都较大,统一在D盘安装VMwareWorkstation软件,分配空间10G。设置1台Master机,4台Slave机。安装Linux系统中的Ubuntu的iso文件。Jdk采用Jdk1.6.0版本和Hadoop采用版本hadoop-0.20.2。
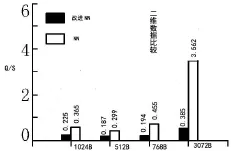
图3 二维数据的查询比较

图4 三维数据的查询比较
第一组实验R-树采用页面尺寸设置为512B,768B,1024B,3072B,本实验在二维和三维数据上进行测试。采用JAVA语言来进行编译。图3是二维数据的查询比较,图4是三维数据上的数据查询比较。改进的NN算法在查询成本上原有的NN算法开销和时间比较低。
第二组实验对比访问次数,经过比对如下表1,改进的NN算法比NN算法索引维护少,并且高的访问次数并不一定有高的查询成本,因为查询成本除了I/O成本还包括CPU计算成本。

表1 改进前后的比对
通过改进NN算法,我们通过三组实验验证了改进的NN算法的有效性,不仅可以减少I/O的访问次数,而且减少内存占用,减少CPU运行时间。R-树对数据集进行索引,利用全局和局部查询算法来尽可能减少SP点,保证算法的渐进性。达到了预期的查询效果。
10.3969/j.issn.1001-8972.2015.24.024
猜你喜欢
计算机工程与科学(2022年11期)2022-11-17
电子制作(2022年1期)2022-01-28
电子制作(2021年14期)2021-08-21
网络安全和信息化(2019年8期)2019-08-28
计算机系统应用(2019年2期)2019-04-10
小型微型计算机系统(2018年3期)2018-03-27
军事运筹与系统工程(2017年1期)2017-07-31
空间控制技术与应用(2010年2期)2010-12-11
电子竞技(2009年14期)2009-09-07
智能计算机与应用(2007年4期)2007-08-25
