
电子资源防恶意下载系统研究∗——以华东师范大学为例
2015-10-23 08:08:06汪志莉
图书馆学刊 2015年1期
刘 莉 冯 骐 汪志莉
(1.华东师范大学信息化办公室;2.华东师范大学图书馆;3.华东师范大学教育信息技术系,上海 200062)
近年来,随着教育信息化的迅猛发展,为了更好地服务于全校师生的教学科研管理和生活,本校图书馆作为文献资源存储和传播中心,购买了大量的国内外电子资源。这些电子资源一般通过3种方式提供给师生:①建立电子资源的校内镜像;②采用本地镜像索引+包库的方式;③账号许可方式。
目前图书馆引进的电子资源大部分是采用第三种方式,有两种实现途径:①图书馆从电子资源提供商那里直接购买使用账号,远程连接到电子资源服务器上进行使用;②将校内IP地址段和账号进行绑定,直通免身份认证方式。
但是,目前基于这两种方式的电子资源访问,本校和其他很多高校都碰到了类似的困扰——电子资源恶意下载,即电子资源提供商对于电子资源的访问有严格的监控和限制,当同一IP地址一段时间内或并发下载超过一定数量时,就会进行警告,甚至封杀IP地址(段)、进行法律诉讼。一旦学校收到警告信,或者IP地址遭到封杀,就将产生很大的恶劣影响,一是严重影响学校的国内外形象和声誉,二是有可能因此大幅增加下一年度的购买成本。
由于本校电信出口进行了地址映射(NAT),所有校园网地址映射成一个(段)IP地址,所以对于某些以单个IP单位时间内下载数量进行判定的数据库恶意下载的误判、警告频率和恶劣影响更大,而且给恶意下载源的控制和追溯带来了更大的挑战。
1 恶意下载的现状
虽然几乎每所图书馆都已经发布了《数据库使用版权公告》,但随着电子资源总量的日益增加和使用量的递增,电子资源恶意下载现象仍呈现日益增长的态势。
清华大学图书馆发布《违规使用电子资源的处理情况》,例举了2003~2013年所有违规下载行为。浙江大学图书馆2011~2013年先后发布了9条、5条、7条关于违规下载的通告,这些恶意下载,导致学校部分IP被封;除此以外,很多其他高校也发布了“违规下载通告”。
本校也面临同样的问题,例如APS journals,2011年以来先后收到7封违规下载邮件,ACS也收到6封违规下载邮件,还有中国知网、申报等也有诸如此类的违规下载通告。
以上数据显示,如何防范和应对电子资源恶意下载已经成为全国各大高校图书馆共同面临和研究的课题。根据学校自身特点和借鉴兄弟院校成功经验,高校应从制度规范、意识教育和技术防范3个方面来逐步解决此问题。图书馆作为电子资源的管理部门,应加强电子资源的制度规范建设,经常性地对师生进行合理合法的使用意识教育。而高校信息化办公室作为技术管理部门,应该发挥自身硬件及软件的技术优势,对读者的下载进行实时监控,采取有效措施,减少甚至免除恶意下载造成的影响,提高电子资源的服务质量。笔者主要从技术角度探讨电子资源防恶意下载的应对措施。
2 电子资源防恶意下载系统的研究现状
鉴于恶意下载的不良影响,各大高校也结合自身情况,对文献下载流量统计与监控进行研究与实施。例如,清华大学图书馆建立了“电子资源访问管理与控制系统”[1];上海交通大学图书馆联合校网络中心建立了“高校电子资源访问管理控制系统”[2];南京航空航天大学信息学院提出了“一种带约束特性的网络信息下载监考模型”以及“基于使用控制模型的防恶意下载系统”[3]。
国内各大高校陆续提出了适合自身的电子资源访问管理与控制系统,本校也结合自身网络环境和电子资源情况,提出解决问题的方案,并逐步付诸实施。
3 电子资源防恶意下载系统的研究思路
恶意下载通常具备以下特征:利用下载工具或多线程进行下载;同一IP地址(段)的单位时间内的下载总量或者并发超出电子资源服务提供商设置的阈值。
基于恶意下载的行为特性,通常采取基于流量分析和基于数据报文分析两种方式来进行防恶意下载的研究。
3.1 基于流量分析(网络层)
在校园网出口处,针对数据库所提供的IP地址(段)的特定端口,进行流量分析与跟踪。当异常流量出现时(如,短时大量80端口的连接请求),采取风险控制措施(中断该连接或者封禁IP地址)。
基于流量分析方式处理简单,仅需处理IP数据报头,系统负荷小,易于实现。但是由于模糊定量,无法精确判断,造成误判率较高。此种方式下,应该参考各电子资源提供商的警告阈值,合理设置,可以采取将阈值降低的方式,以降低对恶意下载的漏判率。
3.2 基于数据报文分析(应用层)
在校园网出口处,将所有出入的数据报文镜像,然后在应用层对数据进行分析控制。即:分析应用层的http报文中的url后缀字段,分离出http下载报文和http访问请求报文。根据电子资源数据库指定的地址段,对目的地址属于该范围的下载报文的特定后缀进行统计分析,如果其单位时间内的下载报文次数超过规定的阈值(参考各数据库规定),则对其进行风险控制措施(封禁IP或中断其连接及警告)。基于数据报文分析中的数据统计分析通常采用将抓包采集到的数据,做初步分析之后录入数据库进行查询分析或者文本方式存储在本地,通过搜索引擎建立索引的方式进行文本查询,数据库中仅保存索引。文本方式对系统负荷小,但性能取决于搜索引擎的优化。
基于数据报文分析方式判断精确,误判率较低。但由于要实时处理长字符串(http报文),处理复杂,因此系统负荷较大。
4 电子资源防恶意下载系统设计
2010年,本校已经进行了电子资源防恶意下载系统的探索尝试,通过部署在校园网出口处的上网行为审计设备进行电子资源数据库的访问统计分析与追溯。该设备将所有校园网出口的流量进行了镜像,如图1所示。
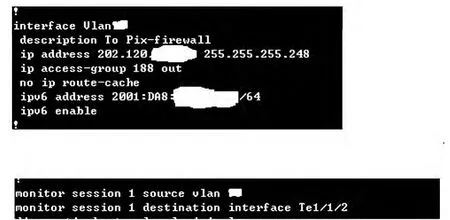
图1 流量镜像配置
由于上网行为审计设备旁路在校园网出口,仅对流经校园网出口的网络流量进行了镜像,而且定制功能尚不完善,所以该功能目前仅用于供图书馆进行访问统计分析和恶意下载的事后追溯,无法进行控制和防护。
图2 现状
在借鉴学习了诸多其他兄弟院校的解决方案后,本校也积极做了进一步的研究和尝试。由于基于网络流量的方式存在误判率较高的问题,因此笔者选择基于数据报文的方式来进行电子资源防恶意下载系统的研究与探索,以期对电子资源的访问下载进行有效的管理以及合理的使用。
基于数据报文的电子资源防恶意下载系统的技术方案包括系统网络架构、软件架构和技术实施方案3部分。
4.1 系统网络架构方案
电子资源防恶意下载系统的网络架构与以前的实现方法类似,即在校园网络出口处将所有流量镜像给抓包服务器,或者抓包服务器、应用服务器合并串联在校园网出口处,如图3所示。
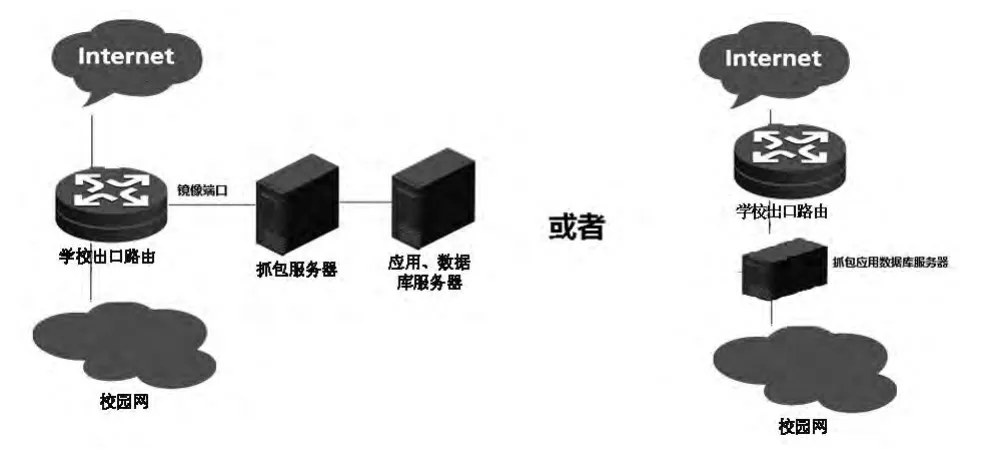
图3 系统网络架构
4.2 系统软件架构及技术方案
电子资源的下载大多采用HTTP方式和FTP方式。由于数据库提供商一般不会提供BT方式,所以本方案对此暂未考虑。对于控制下载行为及下载计数,首先需要分析应用层网络数据包的包头,分析包头中哪些是下载的数据包。对于HTTP方式的下载,需要分析每个HTTP请求及响应的参数,根据HTTP协议response的Content-Type来判断响应的类型,如果是规定的文件类型,则记为一次下载。对于FTP方式的文件下载,可以通过监听tcp协议的21号端口,如果21端口有数据传输,则记为下载。
本方案实现中的难点是对于某些特定的下载,资料链接在A网站,而存储在B网站,于是真正的下载需要跳到B网站进行,此时需要人工创建或者自动建立A网站和B网站之间的关系。关系创建之后,所有B网站的下载可视为A网站的下载。
本电子资源防恶意下载系统自下而上可分为网络数据包抓取系统、解析HTTP tcp/ip数据包系统、下载规则对比、下载规则管理平台、统计报表系统。本解决方案的软件架构如图4所示。
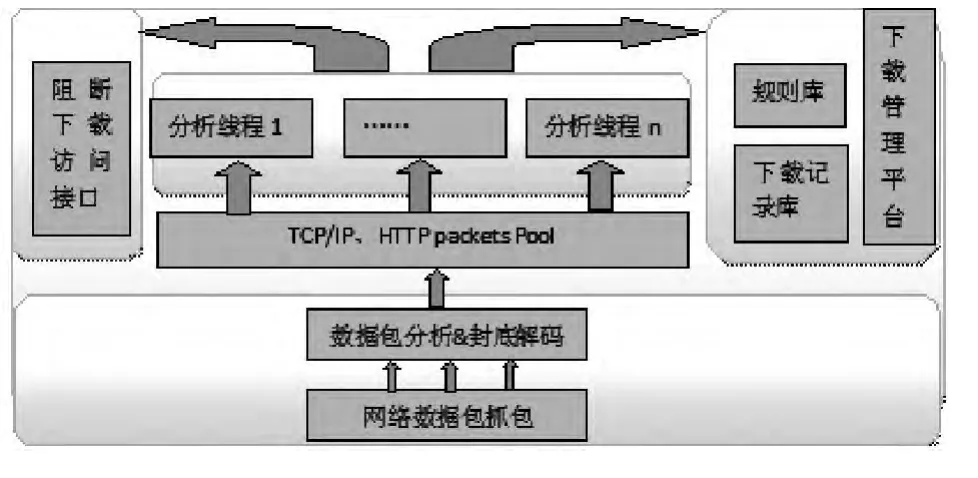
图4 系统软件架构
电子资源防恶意下载系统使用C语言和Java语言编写,运行在LINUX平台,也可以运行在Windows平台。电子资源防恶意下载系统要求HTTP数据包抓包率达到100%,每个数据包的分析过滤响应时间小于10ms,才能保证每一个可能的恶意下载都纳入监控之中。因此,网络数据包抓包程序和数据包分析协议解码程序由C语言编写,C语言在速度和执行效率上要高于Java等其他语言。
4.2.1 网络数据包抓包程序
网络数据包抓包程序采用Libpcap作为底层抓包库。Libpcap是unix/linux平台下的网络数据包捕获函数包,这个抓包库提供了一个高层次的接口可以捕获所有网络上的数据包,并充分考虑到应用程序的可移植性。
4.2.2 数据包分析封底&解码程序
数据包分析封底&解码程序,负责解析HTTP和TCP/IP数据包并将结果放到Pool中。
对于每一次下载,需要根据TCP协议解析TCP协议包头得到源端口和目标端口;根据IP协议解析IP协议包头得到源IP地址和目标IP地址。然后,再解析HTTP协议请求响应Header,如图5所示。
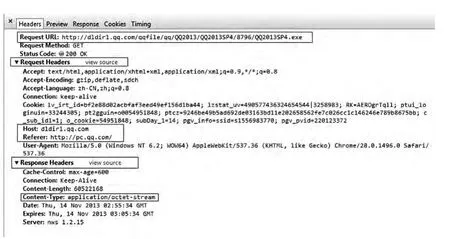
图5 HTTP请求响应Header
根据HTTP 请求头,取到字段(host,URL,Referer,Request Date,Content-type,Response Date,Response,Contentstype,payload)。最后,把TCP/IP和HTTP协议解析得到的所有有用字段放入Pool中,供规则对比程序调用数据。
4.2.3 分析线程流程
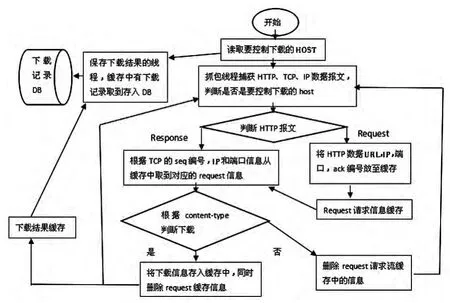
图6 数据分析线程流程
①首先通过数据包抓包程序和分析程序抓取IP、TCP和HTTP数据报文。
如果是数据包HTTP的Request,则将数据包中的RequestURl、REFERER、HOST及HTTP协议对应的TCP报文的端口、ack号及IP报文的IP地址等信息放到内存中缓存Pool中(TCP封装的http协议报文中,HTTP的Request数据报文TCP的ack编号和Response对应的TCP报文的seq编号相同。根据这个编号及IP地址、端口建立Request和Response的对应关系)。对于跨站下载方式,真正的下载链接在其他网站,可以通过HTTP报文中的REFERER字段来判断是否是控制网站发出的请求。
如果数据包是Response报文类型,取到TCP报文的端口、seq和IP报文中的IP地址信息,根据这些信息从内存中缓存Pool取出请求信息,能取出说明是要控制下载的网站的请求的URL。然后取到HTTP协议报文对应的content_type,根据content_type判断请求的URL是否是下载的文件类型。如果是,再从HTTP response报文Content_Disposition中取到下载的文件名,将下载信息存到内存缓存中,由另外保存下载的线程存入数据库中。
常见属于下载文件content_type类型有application/octetstream、application/pdf、application/msword、application/x-xls、application/vnd.ms-excel、application/x-ppt和application/zip。
4.2.4 数据下载规则比对
协议分析程序分离出需要控制的协议包,根据规则库定义的规则进行对比。程序在启动时把所有网站的下载规则包括每个网站最后的时间、下载次数都读到内存中。当有一个HTTP或TCP的数据包到达时,和内存中的规则库比较,如果达到该网站规则的下载的最大次数,通知阻断下载的接口,同时更新该网站下载次数,记录该网站的下载记录。如果没有达到允许的下载次数,则只记录该网站的下载记录。数据下载规则比对流程如图7所示。
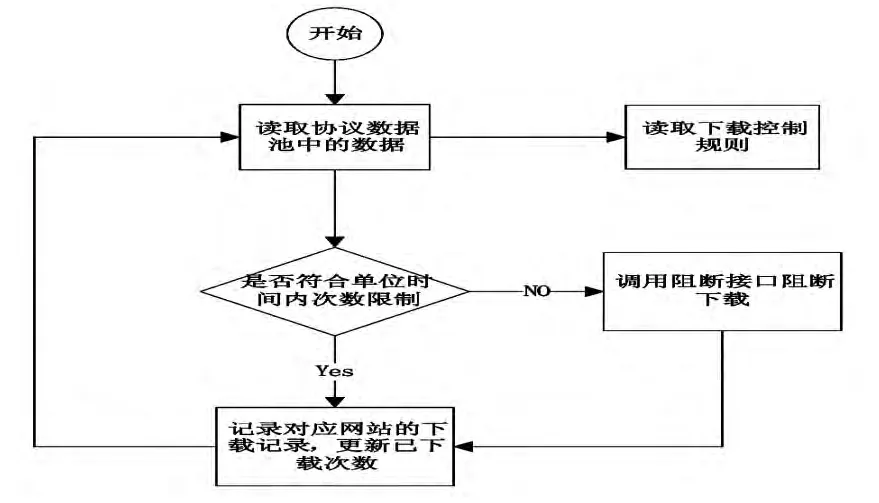
图7 数据下载规则比对流程
4.3 模拟实现
电子资源防恶意下载系统使用C语言和Java语言编写,在Windows平台下进行了模拟实现。运行环境:JDK1.6、GCC;数据库:Mysql 6.1;应用服务器:Tomcat6.36。模拟实现效果如图8所示。
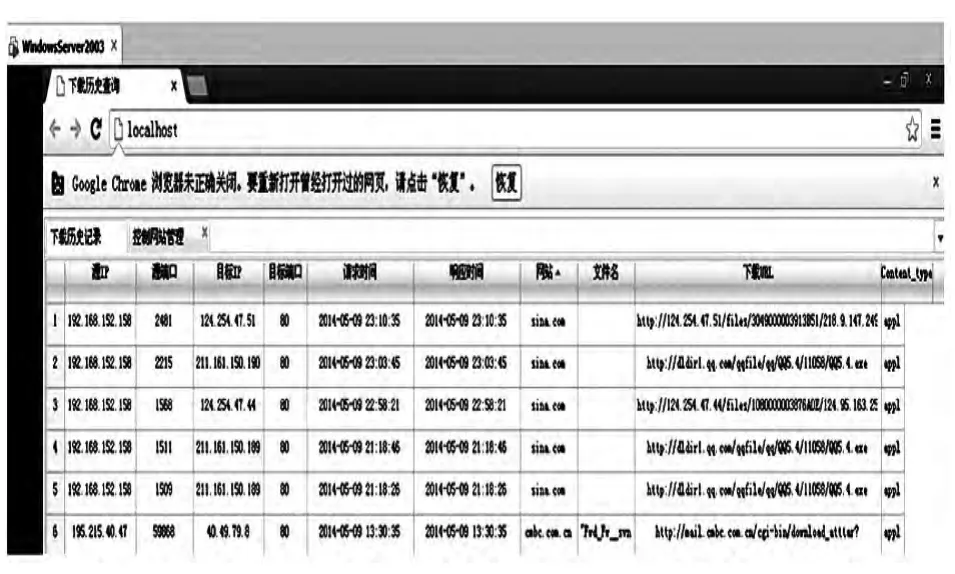
图8 模拟实现效果
5 总结与展望
随着电子资源的不断增加,恶意下载形势日益严峻,我们必须根据本馆的实际情况,积极面对这一挑战。笔者基于数据报文方式进行了一定的研究探索和模拟实现,控制下载次数的统计要求HTTP数据包抓包率100%,每个数据包的分析过滤响应时间小于10ms,这样才能保证监控到每一次下载。学校总出口流量比较大,需要软件结合性能强大的硬件才能更加完善,因此下一步需要加强硬件的支撑,完善阻断功能,才能更好地防范恶意下载。
[1] 邹荣,等.电子资源访问管理与控制系统的设计与应用[J].图书情报工作,2010(1).
[2] 施晓华,钱吟,谢锐.高校电子资源访问控制系统的设计和应用[J].计算机应用研究,2011(3).
[3] 刘大伟,等.基于使用控制模型的防恶意下载系统[J].计算机工程,2009(23).
猜你喜欢
汽车电器(2022年9期)2022-11-07 02:16:24
甘肃教育(2020年18期)2020-10-28 09:05:54
铁道通信信号(2020年4期)2020-09-21 09:15:24
铁道通信信号(2020年11期)2020-02-07 01:02:20
中国外汇(2019年11期)2019-08-27 02:06:30
电子制作(2019年10期)2019-06-17 11:45:26
电子制作(2017年8期)2017-06-05 09:36:15
黑龙江电力(2017年1期)2017-05-17 04:25:16
铁道通信信号(2016年8期)2016-06-01 12:10:21
电子设计工程(2015年17期)2015-02-27 12:08:04
