
3DRS运动估计算法的FPGA实现
2015-10-20 09:13:10陈颖琪高志勇
电视技术 2015年3期
唐 坤,陈颖琪,陈 立,高志勇
(上海交通大学图像通信与网络工程研究所,上海200240)
目前在消费电子领域,随着视频技术的发展,所使用的视频格式从之前的标清提升到现在的高清、超高清视频格式,在用户获得越来越好的观看体验的同时,也给视频的传输和处理提出了新的挑战。视频格式提升,相应的数据率也提高了数倍,在带宽有限的情况下,往往在视频编码端对视频进行降采样,以降低图像帧率的代价降低了传输所用的带宽,这样带来的后果就是视频解码端获得的图像运动不连续,质量退化,帧率低。同时低帧率的视频在液晶显示器上播放将带来一系列观看体验的问题,例如卡顿。为了解决这一问题,可以对视频接收端对解码得到的视频采用插帧的方法,提高视频的帧率,也就是帧率上变换技术。
为了达到帧率上变换的目的,目前主流的做法是采用运动补偿内插法(Motion Compensated Interpolation,MCI)。MCI方法首先进行运动估计,估计出原始序列的真实运动矢量,从而获得正确的内插矢量,并产生内插帧。在众多的MCI方法中,三维递归搜索(3-Dimension Recursive Search,3DRS)方法[1]是运动估计矢量可收敛、计算复杂度低、硬件可实现的算法,因此被广泛应用于视频的帧率上变换的实时处理领域中。
3DRS算法是块匹配算法,其中心思想是利用图像的运动在空间和时间上的相关性,对每一个估计块使用其空间上的相邻块和时间上的相邻块已经获得的估计矢量来生成当前估计块的候选矢量,并筛选获得最佳的运动矢量,将其作为该估计块的预测矢量。但是3DRS算法使用单向搜索矢量,容易导致抖动,并且在某些运动序列情况下很难获取正确的预测运动矢量。
本文基于3DRS算法,利用视频运动的连续性[2],结合文献[3]中提到的双向运动估计搜索方法,对图像分块完成运动估计操作。
1 运动估计算法
3DRS算法使用单向运动估计搜索矢量,即运动矢量只使用前一帧的原始像素块来重建新的内插图像,这样容易导致视频处理时传递误差的累积,使得处理效果恶化,并且重建图像中对应原始图像完全静止的部分也可能会出现抖动[4]。
双向运动估计基于前后两帧原始图像的像素来重建新的图像,其处理如图1所示。
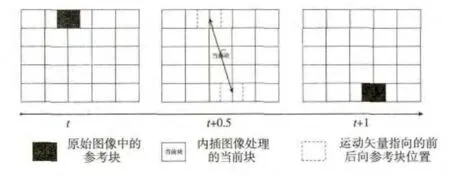
图1 双向运动估计示意图
对于内插图像的当前处理块,3DRS算法采用光栅扫描的顺序处理,并参考文献[5]中3DRS的空间和时间参考块的配置方案,如图2所示。
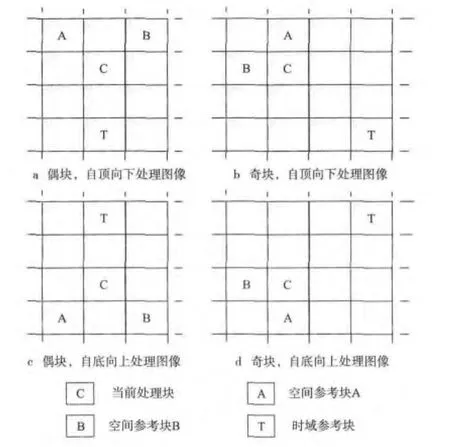
图2 DRS矢量选取方案
图2 中表示的3DRS矢量选取方案处理了4种情况,分别考虑了图像处理的方向(自顶向下处理图像和自底向上处理图像)和图像的位置(奇块和偶块,奇块和偶块的定义将在第2节中给出)。
参考块的最佳运动矢量将作为当前处理块的参考矢量,本文将图2中的3个候选矢量进行处理扩充后获得10个候选矢量,如下所示:
1) 零运动矢量;
2) 空间中值失量;
3) 空间矢量A;
4) 空间矢量A+小抖动;
5) 空间矢量A+大抖动;
6) 空间矢量B;
7) 空间矢量B+小抖动;8) 空间矢量B+大抖动;9) 时间矢量;10)动量矢量。
上述候选集合中,空间和时间矢量利用了图像运动在空间和时间上的连续性,大抖动矢量有利于加速收敛,小抖动矢量有利于保持矢量场的平滑性,动量矢量代表了物体运动的惯性,零运动矢量的作用在于快速恢复最佳矢量,空间中值矢量有利于保持矢量场的平滑性。
算法通过对10个运动估计候选矢量对应的像素块做SAD(绝对值差和),并筛选出SAD值最小的运动估计矢量,将其作为当前处理块的最佳运动矢量。
2 硬件设计方案
2.1 总体框架
3DRS运动估计算法硬件设计的总体框架如图3所示。
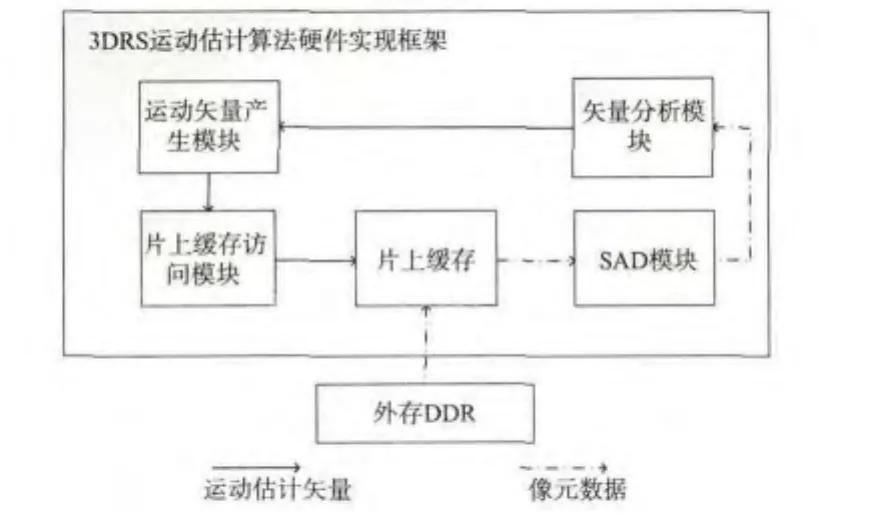
图3 算法硬件结构
每个块处理开始时,由运动矢量产生模块根据当前块的位置产生出10个候选矢量,片上缓存访问模块安排候选矢量依次访问片上缓存,由片上缓存取出对应的像元数据后发送给SAD模块,进行SAD计算,最后由矢量分析模块根据SAD计算结果筛选出最佳的运动矢量,并将结果存入运动矢量产生模块,更新其存储的最佳运动矢量。
硬件实现框架中的各个模块设计功能如下:
1)运动矢量产生模块:维护图像中块处理的顺序,根据块在图像中的位置,产生对应的10个运动估计候选矢量,并存储最佳运动矢量;
2)片上缓存访问模块:接收运动候选矢量,并安排其访问片上缓存;
3)片上缓存:存储像元数据,接收运动矢量,并在约定时钟周期内取出数据发送给SAD模块,同时访问外存DDR,更新缓存内容;
4)SAD模块:接收像元数据,计算其SAD值(绝对值差和);
5)矢量分析模块:接收SAD结果,筛选出最优运动矢量,并发送给运动矢量产生模块。
2.2 块组设计
传统的3DRS算法都是按行的扫描顺序来处理图像,例如光栅扫描[1]或者曲线扫描[6]。而本设计采用块组的扫描处理方法,可以大幅度减少带宽开销。
块组组成及数据更新方式如图4所示。
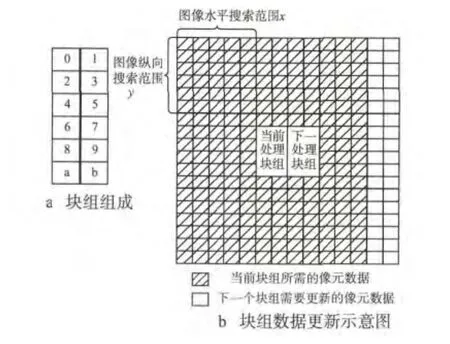
图4 块组组成及数据更新示意图
图4 a表示块组的组成,按照标号顺序来依次处理块,标号为偶数的称为偶数块,标号为奇数的称为奇数块。图4b表示块组的数据更新,中间表示当前和下一处理块组位置,黑色虚线表示当前处理块组的搜索区,右边白色块区表示处理下一个块组时需要更新的数据区域。
由图4b可得当处理同一个块组的不同块时,不需要额外更新数据,只有当处理块组变化时才需要更新数据。那么平均到每个块的相对更新数据量为(图像格式为YUV4 228 bit)
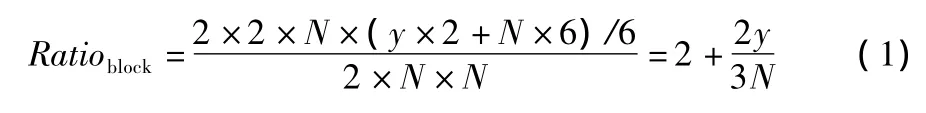
式中:Ratioblock表示更新数据相对于块大小的倍数;N表示块大小为N×N;y表示搜索区竖直方向大小。
2.2.1 带宽分析
3DRS运动估计算法的带宽需求体现在片上缓存的更新数据上。该操作需要访问外存DDR,并以块组为单位来更新数据。
式(1)给出了平均每个块更新数据量相对于块本身大小的倍数,则处理完一帧所需要更新的数据量为
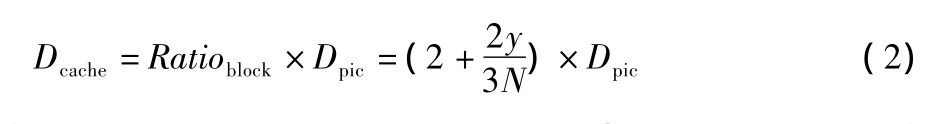
式中:Dpic表示一帧图像的数据量。而考虑传统的光栅扫描或者曲线扫描方式,其更新一帧的数据量为
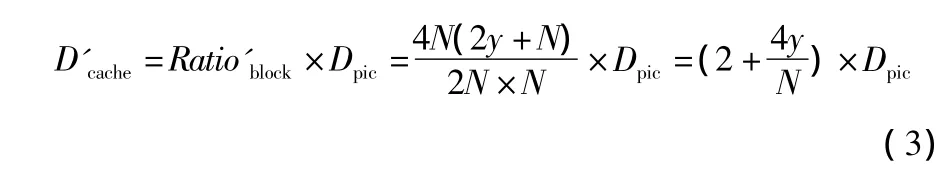
采用块组的处理方法后,系统带宽相对于传统处理方式节省带宽的百分比为
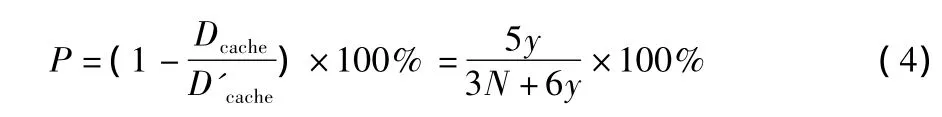
在设计中,若分块大小为32×32,搜索范围设定为192 pixel×108 pixel,则由式(4)可得节省带宽约73%。
2.3 片上缓存
考虑搜索范围为192 pixel×108 pixel,图像为4 228 bitYUV格式,片上缓存数据存储及更新方式如图5所示。
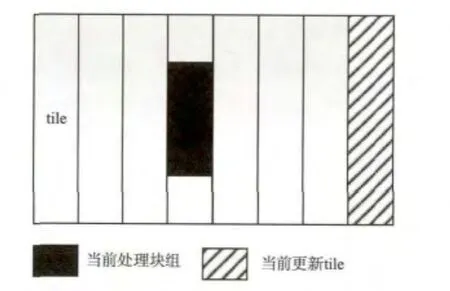
图5 片上缓存数据存储及更新方式示意图
图5 中tile是片上缓存的一个分割单元,其宽度等于一个块组的宽度,高度等于块组高度加上竖直搜索区。图中白色区域为当前处理块组所需要使用的像素区域。而斜体方块区域表示更新数据存储区域。
片上缓存在一个块组处理过程中的工作内容包括两方面:接收运动矢量,在当前搜索范围内找到匹配的像素块,并输出给SAD计算模块;更新下一个块组所需的像素值到更新数据存储区域。
2.3.1 RAM组织
RAM是片上缓存存储数据的主体,设计中采用单口RAM(双口RAM由于有双通道逻辑以及安全保护措施,因此面积比单口RAM大许多,不予采用)。
每次运动估计矢量访问片上缓存,需要前后帧共2×32×32 pixel的Y数据,处理该数据设计时钟越短,所需RAM片数越多,后端SAD处理模块越大,在设计中约定16拍处理一个运动估计矢量(既能满足系统的时钟约束,同时也减少了设计所需的面积)。
在此约束下,采用128 bit位宽的RAM,前后向各8片RAM,每拍输出2×32×2 pixel的Y数据,RAM的组织方式见图6。
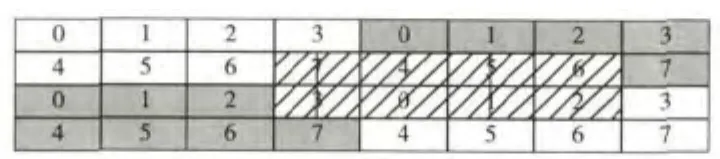
图6 RAM组织方式
图6 中标号0~7的RAM为一组RAM(前向有一组RAM,后向也有一组RAM),同组RAM共用地址,水平和竖直方向复制RAM的组织方式即可。图中虚线填充区域表示运动矢量需求数据的一种形式,黑色实线框表示实际取数。
RAM深度为
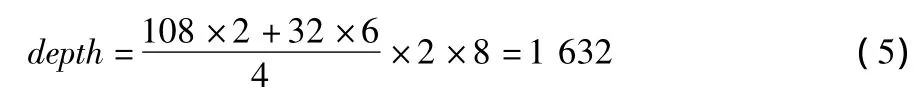
式中:第一项表示tile的高度除以RAM的行数,因子2表示YUV像素的数据率是单通道Y像素数据率的2倍(其中UV信息仅用于重建图像),因子8表示总计8个tile。
系统所需RAM的总容量为
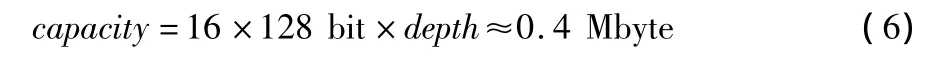
2.3.2 RAM取数与更新
由图6可知一组RAM位宽512 bit,保证了一组RAM取数可以拼凑出所需的32 pixel数据,因此对于一个运动估计向量,取数过程如下:
1)接收运动矢量,根据该运动矢量计算出RAM取数的基址以及每片RAM取数的地址偏移;
2)每拍取出2×512 bit×2的数据,并更新RAM取数基址,取数操作持续16拍完成;
3)将前级获得数据拼接后得到2×256 bit×2的数据,输出到SAD模块。
一组RAM的数据水平位宽为512 bit,与块组的水平位宽相等,因此对于数据更新而言,其过程更加简单,步骤如下所示:
1)由当前块组坐标计算出下一个块组坐标,并计算其需更新数据在外存DDR中的基地址;
2)一次从外存DDR中读取512 bit数据,存入RAM,并更新外存访问基地址和RAM地址;
3)反复从DDR中读取数据,直到tile更新完成。
3 硬件实现结果
采用Virtex6-760芯片,M2N2G64TU8HG5B-AC内存(容量 2 Gbyte,频率为 400 MHz),使用 Verilog 语言[7],对设计进行了验证和实现。
使用ISE工具综合得到的3DRS运动估计模块的结果如表1所示。
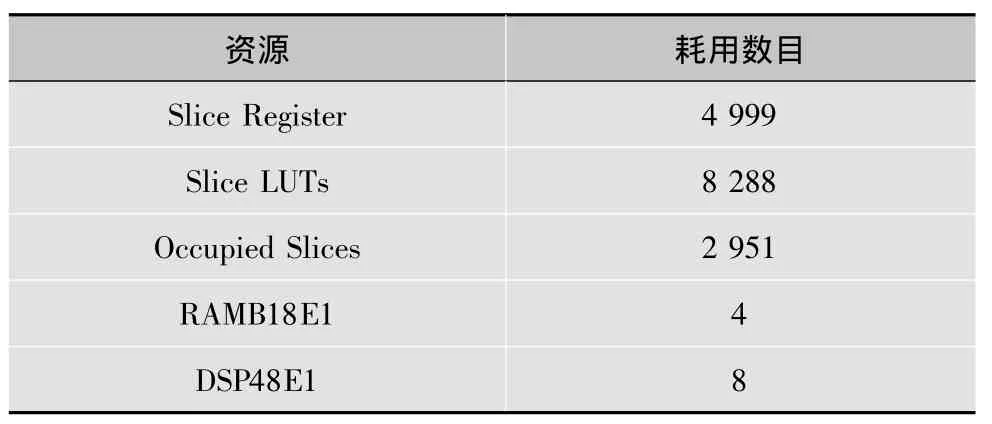
表1 系统FPGA综合结果
此外,设计综合频率可达75.4 MHz,每秒可处理高清视频60帧,处理超高清视频15帧。
另外,使用Cadence公司的RC工具在65 nm条件下对系统代码进行综合,作为ASIC设计的参照结果,其综合面积如表2所示。

表2 系统硬件综合面积(TSMC 65 nm)
同时系统的FPGA验证平台及结果可见图7。

图7 FPGA验证平台及连接方式
FPGA验证平台,HDMI输入由计算机显卡输出,视频经处理后通过子板输出到显示器上,如图4a所示。图4b中FPGA验证板右侧为HDMI输入输出子板,左侧为代码下载器。
4 小结
本文给出了3DRS运动估计算法的一种实现方法,在硬件设计上对带宽作了针对性的优化设计,并给出了详细的片上缓存组织与设计,最后使用Xilinx公司的V6 FPGA验证了整个系统。
该算法在FPGA上实现了高清的实时处理,优点是设计频率为74.5 MHz,易于实现;并且采用了块组的处理方法,大大降低了系统的带宽需求。缺点是片上缓存面积较大,存在优化的余地。一个可行的优化方案是加入压缩模块,对输入片上缓存的视频数据进行压缩,再对输出像元缓存的视频数据进行解压缩,这样可以有效减少片上缓存的面积。
[1] DE HAAN G,BIEZEN PWA C,HUIJGEN H,et al.True-motion estimation with 3-D recursive search block matching[J].IEEE Trans.Circuits and Systems for Video Technology,1993,3(5):368-379.
[2]李珂,高志勇,陈立.基于运动连续性的帧率上变换算法[J].电视技术,2013,37(11):61-65.
[3]贾茜,肖进胜,易本顺.基于三维递归搜索的多级运动估计视频帧率上转换方法[J].电子与信息学报,2012,34(10):2336-2341.
[4]徐洪峰,孙为平,丁玉琴.一种改进的三维递归搜索视频去隔行算法[J].计算机应用,2007,27(5):1153-1155.
[5]毛韧,陈颖琪,高志勇,等.基于运动连续性的帧率上变换算法[J].电视技术,2012,36(19):23-26.
[6] AL-KADI G,HOOGERBRUGGE J,GUNTURS,et al.Meanderingbased parallel 3DRSalgorithm for the multicore era[C]//Digest of Technical Papers International Conferenceon Consumer Electronics(ICCE).Las Vegas:IEEE Press,2010:21-22.
[7]夏宇闻.Verilog HDL数字设计与综合[M].2版.北京:电子工业出版社,2012.
猜你喜欢
艺术家(2023年8期)2023-11-02 02:05:28
成都信息工程大学学报(2022年3期)2022-07-21 09:35:30
中学生数理化(高中版.高考理化)(2022年5期)2022-06-01 06:27:42
小哥白尼(军事科学)(2022年2期)2022-05-25 13:19:30
中学生数理化·高一版(2021年11期)2021-09-05 12:21:24
红领巾·萌芽(2019年8期)2019-08-27 15:30:15
现代防御技术(2016年1期)2016-06-01 12:13:28
CHIP新电脑(2016年3期)2016-03-10 14:22:03
新高考·高一物理(2016年1期)2016-03-05 22:47:39
文理导航·教育研究与实践(2015年12期)2015-12-04 00:49:23
