
采用Lucene.Net与盘古分词器的网上书城站内搜索方法
2015-10-19 14:08:45马军杨维明周民
电脑知识与技术 2015年20期
马军 杨维明 周民


摘要:该文针对网上书城对信息实时性与准确性高的要求,提出了使用lucene与盘古分词器相结合的站内搜索系统解决方案。通过分析lucene内置分词器与盘古分词器的性能差异,选择了针对中文开发的盘古分词器,提高了搜索的准确性;通过采用“生产者与消费者”多线程模式与“单例”设计模式相结合的方法,实现了数据的实时更新。实验结果证明了设计方案的有效性。
关键词:lucene;盘古分词;网上书城;站内搜索
中图分类号:TP393 文献标识码:A 文章编号:1009-3044(2015)20-0184-04
站内搜索是指对网站内部信息的精确检索和资源挖掘, 它为用户提供准确、快速的站内信息检索服务,站内搜索效果直接决定着网站商品的销量。现有的网上书城网站大多采用链接google和baidu网站的方法实现搜索,不利于数据的实时更新,此外,还存在着书籍信息准确性不高的缺点。
Lucene是目前最流行开源检索工具包之一, 已经在许多搜索项目中得到了应用。盘古分词也是一个比较成熟的中文分词组件,而且采用多元分词技术,可以很好的实现对中文的分词。因而本文针对中小网上书城提出了一个基于lucene.net与盘古分词的站内搜索技术方案,提高网站的竞争力。
1 站内搜索方案设计
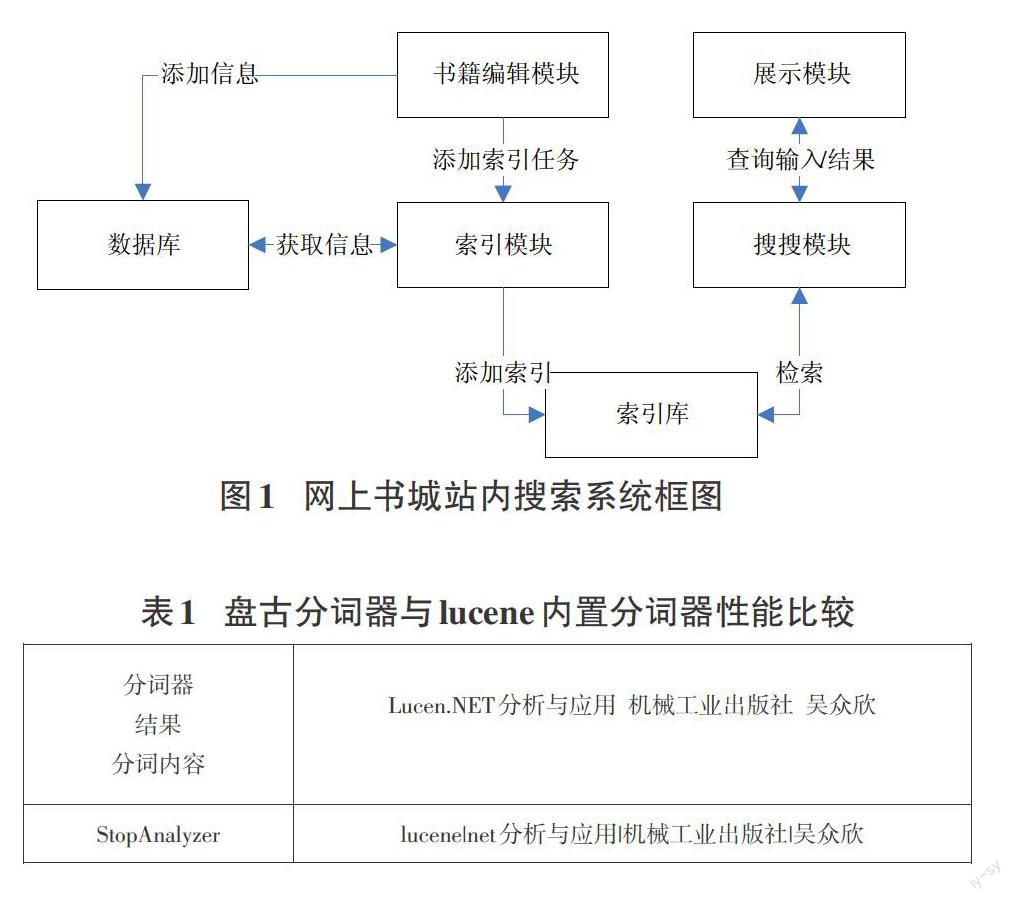
网上书城站内搜索系统框图如图1所示。
本文提出的站内搜索方案将系统分为书籍编辑模块、索引模块、检索模块和展示模块4个部分。书籍编辑模块主要负责收集书籍的信息并且转换为纯文本信息,即lucene可识别的信息。索引模块主要针对数据库创建和维护索引库,即每当增加或修改书籍的信息到数据库时,就更新索引库。 检索模块主要针对用户输入的关键字进行分析,然后查询索引库找到相关联书籍,并且按相关性程度排序。展示模块主要负责接受用户输入的关键字,并展示搜索的结果中书籍的信息以及如何展示。根据搜索结果,可以定制个性化的展示。
图1 网上书城站内搜索系统框图
2 盘古分词器性能分析
盘古分词是一个中英文分词组件。它的作者通过分析比较中文分词的一元分词、二元分词,多元分词和精确分词的性能,得出多元分词适用性更强。但采用多元分词产生了一些问题,第一,多元分词和搜索引擎结合得到较多的匹配结果,同时也增加了索引文件的大小;第二,由于将一些单词进行了拆分,搜索结果的排序会受到影响。为了克服这两个缺点,盘古分词提出了多元分词的冗余度(Redundancy)和多元分词结果的权重级别(Rank)的概念。盘古分词支持3级冗余。比如“湖北大学”,冗余度为0、1、2时,分词结果分别是“湖北大学”、“湖北,湖北大学,大学”、“湖北,湖北大学,大,大学,学”。盘古分词将多元分词出来的单词根据其词长,词的间隔以及未登录词的取舍等条件给定了不同的权重。在搜索时对分解出来的关键字,我们指定权重来影响搜索结果,以实现结果有效排序。比如搜“湖北大学”时,可以将“湖北大学”设置较高的权重,而“大学”和“湖北”设置较低权重,则包含“湖北大学”的记录就优先于包含“湖北”或“大学”的记录,这样就解决了排序问题。
为了说明盘古分词优于lucene内置分词器,做了如下表格的对比。从表中可以看出,StopAnalyzer针对非字母字符拆分文本,然后小写英文字母,再过滤掉停用词;KeywordAnalyzer将整个文本当作一个词处理;SimpleAnalyzer和StopAnalyzer类似;WhitespaceAnalyzer根据空格拆分词汇单元;StandardAnalyzer按每个汉字拆分词,PanGuAnalyzer按有意义的中文词语分词,显然效果最佳。因而本文选择盘古分词器,提高搜索的准确性。
分词比较的结果如下表1所示。
表1 盘古分词器与lucene内置分词器性能比较
[分词器
结果
分词内容\&Lucen.NET分析与应用 机械工业出版社 吴众欣
\&StopAnalyzer\&lucene|net分析与应用|机械工业出版社|吴众欣\&KeywordAnalyzer\&lucene分析与应用 机械工业出版社 吴众欣\&SimpleAnalyzer\&lucene|net分析与应用|机械工业出版社|吴众欣\&WhitespaceAnalyzer\&lucene.NET分析与应用|机械工业出版社|吴众欣\&StandardAnalyzer\&|lucene|分|析|与|应|用|机|械|工|业|出|版|社|吴|众|欣\&PanGuAnalyzer\&|lucene|分析|与|应用|机械|工业出版社|吴众欣\&]
3 站内搜索的实现
3.1 书籍编辑模块
为了可以批量添加书籍信息,使用XML存储书籍信息。网站管理员使用后台管理界面添加或修改书籍信息。本文从XML读文件信息的使用.NET内置操作XML文件的库函数。管理员输入的书籍信息是纯文本格式,无需解析。
本文从XML文件获得纯文本信息的核心代码如下:
//创建一个XML对象
XMLDocument doc=new XMLDocument();
//加载指定的XML文档
doc.Load(@"E:\books.xml");
//创建读取器
XMLNodeReader reader=new XMLNodeReader();
//读取节点的信息
While(reader.Read())
{
Switch(reader.NodeType)
{
Case XmlNodeType.Element
If(reader.Name="title")
bookTitle=reader.Value;
...
}
}
3.2 索引模块
索引库相当于关系数据库,非常关键和重要,直接决定搜索的响应速度与准确性。针对网上书城,书籍关键信息包括书名、出版社、作者、出版时间、书籍简介等,因此在建立索引库的时候一定要包含这些关键信息,方便用户快速查询,其它信息可根据需求添加。
为了实现网上书城实现实时的数据更新,本文采用“单例设计模式”和“生产者与消费者”多线程模型相结合的方式。主线程创建单例管理器,整个程序中是唯一的,保证了数据更新数据的一致性。同时主线程扮演生产者的角色,当添加或修改书籍的信息时,主线程(生产者)就会调用管理器,向任务列表新增任务,不用关心任务是否执行了。整个网站一旦运行,主线程(生产者)调用管理器创建消费者线程并启动该线程。消费者线程就会循环的检测任务列表,如果有任务,就执行索引任务,向索引库中添加或修改书籍信息,否则,可根据需要设置该线程休眠的时间,防止占用cpu,造成浪费。索引系统原理框图如图2所示。
图2 索引系统原理框图
具体索引功能使用lucene提供的核心类IndexWriter、Direcrtory、Analyzer、Document、Field实现索引。IndexWriter这个类负责创建新索引或打开已有索引,以向索引中添加、删除或更新被索引文档的信息。Direcrtory类描述了lucene索引存放位置。它是一个抽象类,它的子类负责具体指定索引的存储路径。Analyzer这个类负责分词,它是一个抽象类,需要具体类实现它。Document类似于关系数据库的记录,是一些字段(field)的集合。Field类似于关系数据库的字段。索引建立过程:创建IndexWriter类,指明索引库位置以及使用的分词器;创建一个文件记录类Document;把要记录的字段加入Document;把Document写入到索引库并且关闭索引。
核心代码如下:
//单例索引管理器
public class IndexAdministration
{
//创建单例
public static readonly IndexAdministration Instance=new
IndexAdministration();
//私有化构造器
Private IndexAdministration(){}
//创建索引任务列表
private List
//启动消费者线程
public void StartComsumeThread()
{Thread threadIndexWork = new Thread(IndexWork);
threadIndexWork.Start();}
//执行索引任务
private void IndexWork(){...}
//添加索引任务,生产者调用
public void AddTask(IndexTask task){ ...tasks.Add(task);...}
//删除索引任务,生产者调用
public void RemoveTask(IndexTask task){...tasks.Remove(task)...}
}
执行索引任务的核心代码:
private void IndexWork()
{
while(ture)
{...
//若无任务,睡眠
if (tasks.Count <= 0){ Thread.Sleep(3 * 1000);continue;}
//创建或打开索引目录
FSDirector IndexDirectory=FSDirectory.Open(
new DirectoryInfo(indexFilePath),new NativeFSLockFactory());
//创建索引写入器对象,参数1:索引库位置,参数2:分词器(盘古分词),参数3:更新或添加
IndexWriter writer=new IndexWriter(IndexDirectory, new PanGuAnalyzer(),isUpdate);
//创建Document对象
Document doc=new Document();
//添加字段到Docment对象中,根据需要添加必要的字段
doc.Add(new Field("title",bookTitle,Field.Store.YES,
Field.Index.ANALYZED));
...
//将doc添加到索引库
writerAddDocument(doc);
//关闭写入器
writer.Close();
//关闭索引库
IndexDirectory.Close();
}
}
3.3 检索模块
lucene检索功能使用lucene提供检索的核心类IndexSearcher、Term、Query、TopScoreDocCollector实现。IndexSearcher类用于搜索使用IndexWriter类建立的索引库,它是连接索引的核心,以只读的方式打开索引库。Term对象是检索功能的最基本单元,包含域名和域文本值。Query是抽象父类,它有很多具体子类,最基本的子类TermQuery,用来匹配指定域中包含特定项的文档。TopScoreDocCollector是一个简单指针容器,指向匹配查询条件的前N个搜索结果,N可以根据需要选择,方便分页展示。
检索过程:打开索引库FSDirectory;创建一个搜索器IndexSearcher指向索引库;创建一个查询类Query的子类并对输入的内容进行分词;组装查询类,lucene提供多种查询类,根据需要选择;通过调用搜索器的Search方法执行查询,将结果放到TopScoreDocCollector指针容器;根据需要获得查询结果的文档内容。
核心代码
//打开已创建的索引库,
FSDirectory IndexDirectory=FSDirectory.Open(
new DirectoryInfo(indexFilePath),new NoLockFactory());
//创建搜索器
IndexSearcher indexSearcher = new IndexSearcher(IndexDirectory);
//创建Query的一个实现类,根据需要创建
PhraseQuery query = new PhraseQuery();
//对输入内容进行分词
List
//组装查询条件,根据需要设置
foreach(string word in cutWords){ query.Add(new Term("bookTitle", word));}
...
//创建存储查询结果的指针容器
TopScoreDocCollector collector = TopScoreDocCollector.create(100, true);
//查询,第一个参数:查询条件,第二个:过滤条件,第三个:指针容器
indexSearcher .Search(query, null, collector);
//从指针容器中获得结果,第一个参数:结果的起始位置,第二个:获取数量
ScoreDoc[] documents = collector.TopDocs(startIndex,Count).scoreDocs;
//从搜索结果中获取Document
for (int i = 0; i < documents .Length; i++){
//得到文档编号,lucene内部分配的,为了降低内存,结果只有编号
int documentId = documents [i].doc;
/根据id找到Document
Document doc = searcher.Doc(docId);
//获取Document的具体内容,根据需求获取所需内容,便可以展示给用户了
string bookTitle= doc.Get("title");
....
}
分词函数:
List
//存放分词结果的集合
{List
//调用分词器分词
TokenStream ts = analyzer.ReusableTokenStream("", new StringReader(words));
Token token;
while ((token = ts.Next()) != null)
//添加到分词结果
{results.Add(token.TermText());}
//关闭分词器
ts.Close();
return results;}
3.4 展示模块
展示模块主要用来展示查询到匹配的结果。lucene并没用提供展示内容的接口函数,需要我们自己设计如何展示内容,由于本文是针对网上书城开发的站内搜索,所以选择一网页的形式展现。
本文使用.NET平台设计展示网页。实现思路:首先在展示页面拖放一个Reapter控件,其次把搜所到数据转换成一个集合listResult,然后将listResult绑定到Reapter数据源便可显示了。
为了更好的客户体验,像百度、Google、360搜索一样,将结果中的关键字用特殊的颜色标出,醒目的提示用户。本文使用盘古分词的高亮插件 PanGu.HighLight.dll实现。
4 实验结果与分析
基于上述设计与实现方法创建了一个虚拟的系统,进行实验验证。
使用vs2010平台搭建,lucene.net版本3.0.3,盘古分词版本2.3.1。
首先向索引库中添加1000本书的信息,其中两本书如表2所示。
表2 待搜索的书籍信息
[书名\&作者\&简介\&设计模式\&GOF4\&可复用面向对象软件的基础\&面向对象的程序设计\&Grady Booch\&面向对象分析与设计,纤细介绍了,面向对象原则\&]
输入“面向对象”,根据简介搜索,两本书都可搜出,且排在前两位,说明准确性高,及相关性设计合理。如图3所示为搜索结果截图。
图3 输入“面向对象”的搜索结果
其次输入“lucene”进行搜索,没有任何结果。说明索引库中没有这本书的信息。添加如表3的信息。
表3 添加的书籍信息
[书名\&作者\&简介\&lucene实战\&Erik Hatacher\&lucene实战这本书,从基础讲起,并运用大量例子说明使用方法,很实用。\&]
添加书籍信息后,立刻输入“lucene”,根据书名进行搜索,搜到了这本书,如图4所示为搜索结果截图。说明了实时性高。
图4 输入“lucene”进行搜索的结果
5 结束语
本文针对网上书城对数据更新实时性高与书籍信息准确性高的要求,提出了使用lucene与盘古分词器相结合的站内搜索系统解决方案。分析了盘古分词器的性能优势,选择盘古分词器,提高了搜索的准确性;采用“生产者与消费者”多线程模式与“单例”设计模式相结合的方法,实现了数据的实时更新。并通过实验验证了该方案的有效性。该方案主要针对中小型网上书城而设计的,对大型网上书城大数据不适应,这也是下一步继续研究探索的方向。
参考文献:
[1] 邱哲, 符滔滔, 王学松. 开发自己的搜索引擎Lucene+Heritrix[M]. 北京: 人民邮电出版社, 2010.
[2] 吴众欣, 沈家立. Lucene分析与应用[M]. 北京: 机械工业出版社, 2008.
[3] 李天平. 项目中的.NET[M]. 北京: 电子工业出版社, 2012.
[4] Martin Fowler. 重构改善既有代码的设计[M]. 北京: 人民邮电出版社.
[5] 周海松, 刘建明, 李龙. 基于Lucene的垂直搜索引擎研究与实现[J]. 桂林电子科技大学学报, 2014, 34(3): 226-229.
[6] 李永春, 丁华福. Lucene 的全文检索的研究与应用[J]. 计算机技术与发展, 2010, 20(2): 12-15.
[7] 朱学昊, 王儒敬, 余锋林, 唐昱. 基于 Lucene的站内搜索设计与实现[J]. 计算机应用与软件, 2008, 25(10): 6-9.
[8] 李建林. 基于Lucene的Web搜索引擎的研究[D]. 兰州: 兰州理工大学, 2010.
[9] 阴晓昱. 基于Lucene 多核并行索引方法的设计与实现[D]. 上海: 上海交通大学, 2010.
[10] 胡鹏飞. Lucene与中文分词技术的研究及应用[D]. 北京: 北京交通大学, 2010.
