
一种面向地震数据的两级索引
2015-10-19 07:22谷文彦潘昌森中国科学技术大学自动化系安徽合肥230026
网络安全与数据管理 2015年18期
谷文彦,李 俊,潘昌森(中国科学技术大学 自动化系,安徽 合肥 230026)
一种面向地震数据的两级索引
谷文彦,李 俊,潘昌森
(中国科学技术大学 自动化系,安徽 合肥 230026)
地震数据处理中的数据读取具有块小量大的特点,常规磁盘所用的数据读取方式,其处理速度缓慢。设计了一种基于FastDFS的分布式地震数据存取系统。该系统将数据分块存储在硬盘上,在FastDFS中建立基于炮号和道号的两级索引结构,并选取Trie树作为一级索引,AVL树或红黑树作为二级索引,提高了系统读取速度。实验结果表明,该地震数据存取系统减少了相应的查询响应时间,提高了系统存取性能。
地震数据;两级索引;Trie树;红黑树;AVL树
0 引言
随着地震勘探技术快速发展,地震数据规模不断增加。数据显示,地震道集数按每三年翻一番的速度增长,2014年单文件已经突破16 000道[1-2],这些数据量一般在TB甚至PB级别。当今PC集群的计算性能有了很大提高,但相应的集群存储相对滞后,地震数据存取效率越来越成为地震资料处理的瓶颈。采用共享网络文件系统NFS存取地震数据,制约了海量地震数据存取的效率[3]。并行文件系统Lustre[4]在存取地震数据I/O性能上优于NFS[3],它采用RAID存储数据,拥有高性能的顺序读取效率,但每次需要读取整个条带的数据,随机读取效率低。
地震数据处理程序请求的数据不一定连续存储在文件中。处理程序在随机请求数据时只需要文件中的若干道数据,却要读取整个文件,读取效率就会很低。为此,本文提出一种快速存取地震数据的方法,该方法将地震文件的数据分块存储,并建立以炮号和道号为关键字的两级索引结构。通过实验表明,加入索引后,在满足存取需求的同时,减少了查询时间和数据传输开销,提高了系统的存取效率。
1 地震数据
1.1 地震数据格式
勘探地球物理协会(Society of Exploration Geophysicists,SEG)制定的 SEGY地震数据格式是最常用的数据格式,SEGY文件结构如图1所示。

图1 SEGY格式
标准的SEGY格式包括3个部分:(1)3 200B的E-BCDIC文件头,保存一些地震数据整体性的描述信息;(2)400B的二进制头文件,用来保存描述SEGY文件的信息,如文件数据格式、采样点数目、采样时间、测量单位等;(3)实际地震勘探数据,每道数据前面会有240B的道头信息,保存该道数据对应的位置坐标、采样点数、炮号、道号等信息。
1.2 数据格式的改进
地震数据道头主要是记录道的信息,对用户分析数据没有作用,每次读取地震数据还要把道头数据也读出来,效率很低。本文将道头和数据体分开存储,并在两者之间加入关键字索引信息。用户每次读取数据,只要指定数据关键字,就可以通过索引查找到该数据存放的具体位置。这种方式下用户每次读的有效数据增多,效率有所改善。
2 两级索引结构
2.1 FastDFS介绍及两级索引结构
FastDFS充分考虑了冗余备份、负载均衡、线性扩容等机制,解决了大容量存储、高并发访问等问题。与现有的类Google FS相比,FastDFS的架构和设计的独到之处体现在轻量级、分组方式和对等结构[5]。跟踪器(Tracker)作为中心节点,提供负载均衡和任务调度;存储节点(Storage)则直接利用文件系统存储文件。FastDFS不对文件进行分块存储,上传文件时,文件ID由存储节点生成并返回给客户端,文件ID中包含文件所在组名、相对路径和文件名。存储节点可以直接根据文件名ID来定位数据。因此FastDFS中不需要存储索引信息。
本系统为支持顺序读取和随机读取地震道数据,对SEGY文件格式进行改进,将道头和数据块分开存储,在两者之间建立二级索引。考虑到跟踪器负责管理数据,因此将数据块的位置信息存储在跟踪器上,客户端读数据时,可以根据跟踪器上存储的信息直接找到存储数据的存储节点,而跟踪器上的信息就是本文提出的一级索引。综上所述,两级索引中一级索引记录数据块所在存储节点号,二级索引记录数据块具体位置。系统框架如图2所示。

图2 两级索引框架
2.2 I/O操作流程
(1)写数据
Client写数据的数据头中包含炮号、起始和终止道号及数据块大小等信息,以便跟踪器和存储节点构建索引。写数据块过程中同一炮号不同块的数据分布在不同的卷组内,以实现负载均衡。写数据前 Client向跟踪器询问可存储新数据块的存储节点,数据写入存储节点后,该存储节点会根据数据块信息(数据块所属的炮号、起始道号、终止道号)和位置信息构建二级索引。跟踪器会根据存储节点报告的信息构建一级索引,流程如图3所示。
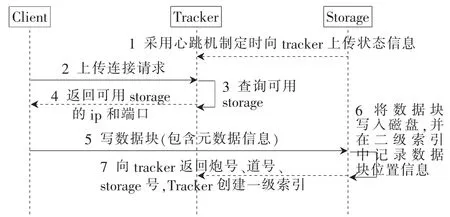
图3 写流程
(2)读数据
Client从存储节点读数据时,命令需要包含炮号、起始和终止道号。Client首先查询跟踪器上的一级索引,找到数据块所在的存储节点,然后Client向该存储节点读数据,存储节点则根据二级索引查询数据具体位置,并读出数据返回给Client。读数据流程如图4所示。

图4 读流程
3 两级索引实现
3.1 一级索引
存储采用共炮存储,即同一炮的多道数据合并后作为一个数据块存储在存储节点上,数据块名格式为:炮号_起始道号_终止道号,且以此数据块名形成的字符串作为一级索引的key值,value值是该数据块所在存储节点的信息。用户要查询第100炮的第0~99道的数据,就会首先生成100_0_99这个字符串,然后去一级索引中查找,返回存储数据的存储节点。
一级索引采用 Trie树,Trie树利用字符串的公共前缀来降低查询时间以达到提高效率的目的。Trie树的插入、删除和查找都很简单,用一个循环就可以解决,第i次循环找到前i个字符。以静态开辟个数组来实现这棵字符树,本文每个节点的子节点有11种情况(0~9和_),需要对每个节点开辟一个大小为 11的数组。
3.2 二级索引
红黑树[6]在每个节点上增加一个颜色位,可以是Red或Black,通过限制从根到叶子路径中各节点着色方式来维持平衡,有4种平衡方法[7]。红黑树正是用这种非严格的平衡来换取增删节点时旋转次数的降低,性能比普通二叉树高。
[8]中说明当操作仅限于插入和检索时AVL树是平衡二叉搜索树中最有效的方法,在查找和排序上有很重要的应用。AVL树左右子树高度差超过1,会被认为是不平衡的,由于AVL树的这种平衡条件,使树的深度不会过深。参考文献[9]、[10]中阐述了可能导致AVL树失去平衡的4种可能,及相应的4种旋转方法。
Client查到存储节点后通过炮号、起始道号向该存储节点查寻二级索引,找数据具体位置。
本文分别采用红黑树和AVL树作为二级索引,力求寻找一个性能更佳的二级索引结构。通过炮号及道号来唯一标识数据块,于是本文把炮号和起始道号组成的联合体组合成一个唯一长整形数,代码如下。以此作为该二级索引key值,对应的value值为该数据块的位置信息。
二级索引关键字结构代码:

4 实验与结果
4.1 实验环境
本实验集群由5台服务器组成,1台client、1台跟踪器和3台存储节点。每台服务器CPU均为2.33GHz,内存为4GB,操作系统是CentOS6.4。
4.2 实验和结果
本文提出的地震数据存取系统是基于FastDFS修改而来的。一级索引采用Trie树,二级索引加入AVL树的版本命名为AVLFS,加入红黑树的版本命名为RBFS。每道数据32KB,将100道数据作为一个数据块。采用以下两种方法进行测试:(1)写入相同数据块,测试读取速度随着读的有效数据大小变化的关系;(2)读取有效数据一定,测试速度随着写入数据量变化的关系。
实验1写入200炮的数据,每炮100个数据块,一共20 000个数据块。读取分布在不同数据块中的道,测试结果如图5所示。
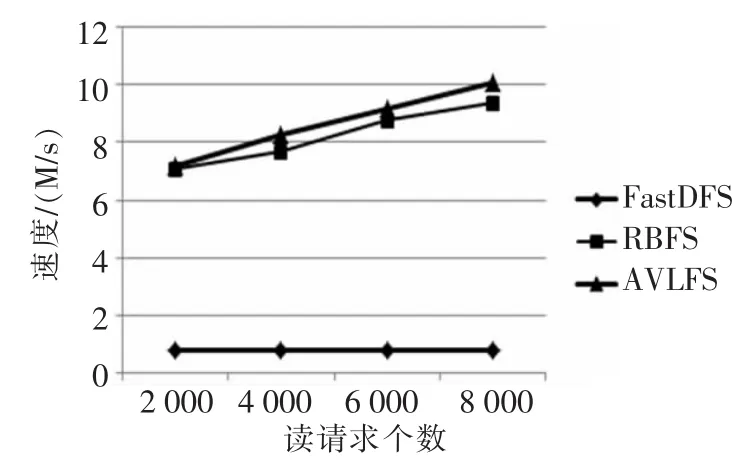
图5 速度随读请求的变化关系
实验2 读取8 000道地震数据,这8 000道数据分布在不同数据块,结果如图6所示。

图6 速度随写数据块数量的变化关系
图5显示,与FastDFS相比,加入两级索引的地震数据存取系统在随机读的速度上有了8~10倍的提升,随着数据块请求数的增加,速度也有所提升,这是由于多磁盘并发读取使得速度有所增加。图6中随着写数据块个数的增多读取速度几乎没有影响,这说明索引性能没有随着写数据块个数增加而降低。通过图5、图6,还可得出二级索引采用AVL树在读取速度上优于红黑树,主要是AVL树比红黑树更加平衡,查询效率更快。
5 结论
本文提出一种能够快速存取地震数据的方法,该方法将数据分块存储,并建立两级索引结构。实验表明,加入两级索引后满足了对地震数据随机读取的要求,同时减少了查询时间和数据传输开销,系统读取速度有很大提高。针对查询操作,AVL树优于红黑树索引,而地震数据存取就是一次存储,多次读取,故本系统最终选择AVL树作为二级索引。本文后续工作将会对两级索引进行进一步优化。
参考文献
[1]张捷.石油勘探地震数据的处理和成像问题[R].合肥:中国科学技术大学地球物理研究所,2013.
[2]赵改善.我们需要多大和多快的计算机[J].勘探地球物理进展,2004,27(1):23-28.
[3]杜吉国,孙孝萍,陈继红,等.Lustre并行文件系统在地震数据处理中的应用[J].物探装备,2013,23(5):294-299.
[4]Lustre[EB/OL](2015-03-31).http://wiki.lustre.org/index.php/Main_page.
[5]余庆.分布式文件系统 FastDFS架构剖析 [J].程序员,2010(11):63-65.
[6]Rudolf Bayer.Symmetric binary B-Trees:data structure and maintenance algorithms[J].Acta Informatica,1972,1(4):290-306.
[7]THOMAS H C,CHARLES E L,RONALD LR,et al.算法导论[M].潘金贵,顾铁成,李成法,等,译.北京:机械工业出版社,2006.
[8]BAER J L,SCHWAB B.A comparison of tree-balancing algorithms[J].Communication of the ACM,1977,20(5):322-330.
[9]ELLIS C S.Concurrent search and insertion in AVL Trees[J]. IEEE Transactions on Computers,1980,29(9):811-817.
[10]CHAUHAN S,THAKUR S,RANA S,et al.A brief Study of balancing of AVL Tree[J].International Journal of Research,2014,1(11):406-408.
A two level index for seismic data
Gu Wenyan,Li Jun,Pan Changsen
(Department of Automation,University of Science and Technology of China,Hefei 230026,China)
Read data in seismic data processing has a characteristics of small piece and large number,and for the conventional disk read mode,its processing speed is slow.This paper designed a distributed seismic data access system based on FastDFS.This system stored the data in hard disk based on block,and established two level index structure based on the shot number and gather number in FastDFS.It selected Trie tree as the primary index,AVL tree or red-black tree as the secondary indexes,to improve the reading speed of the system.The experimental results show that the seismic data access system created in this paper has reduced the query response time,and can improve the performance of system access.
seismic data;two level index;Trie tree;red-black tree;AVL tree
TP316.4
A
1674-7720(2015)18-0026-03
谷文彦,李俊,潘昌森.一种面向地震数据的两级索引[J].微型机与应用,2015,34(18):26-28,35.
2015-04-20)
谷文彦(1988-),男,硕士研究生,主要研究方向:网络软件开发、嵌入式软件开发。
李俊(1973-),男,博士,副教授,硕士研究生导师,主要研究方向:网络传播与控制。
潘昌森(1990-),男,硕士研究生,主要研究方向:网络软件开发、大数据。
猜你喜欢
机械工业标准化与质量(2022年6期)2022-08-12
太阳能(2022年3期)2022-03-29
装备制造技术(2020年2期)2020-12-14
河南科技学院学报(自然科学版)(2020年2期)2020-05-22
太阳能(2020年3期)2020-04-08
当代工人·精品C(2019年2期)2019-05-10
计算机应用与软件(2017年7期)2017-08-12
中华手工(2017年2期)2017-06-06
中国卫生(2015年12期)2015-11-10
中外会展(2014年4期)2014-11-27
