
基于压缩感知的单样本人脸识别*
2015-10-18 07:38徐志京上海海事大学信息工程学院上海201306
网络安全与数据管理 2015年12期
徐志京,叶 丽(上海海事大学 信息工程学院,上海 201306)
基于压缩感知的单样本人脸识别*
徐志京,叶丽
(上海海事大学信息工程学院,上海201306)
提出一种基于压缩感知的单样本人脸识别方法,通过局部邻域嵌入非线性降维和稀疏系数的方法产生冗余样本,则新样本包含了多种姿态和多种表情。将所有的新样本作为训练样本,运用改进后的稀疏表征分类算法进行人脸图像的识别。在单样本情况下,基于ORL人脸库和FERET人脸库的实验证明,该方法比原稀疏表征方法在识别率上分别提高了15.53%和7.67%。与RSRC、SSRC、DMMA、I-DMMA等方法相比,该方法同样具有良好的识别性能。
人脸识别;单样本;稀疏表征分类;局部邻域嵌入非线性降维
0 引言
人脸识别技术是一种通过分析比较人脸视觉特征信息进行身份鉴别的计算机技术[1]。人脸识别受表情、姿态等多因素影响,其仍是生物特征识别领域最困难的研究课题之一。同时,因样本采集成本大、存储空间受限等造成了单训练样本问题,这使得人脸内在特征的提取变得更加困难[2]。在人脸训练数据库中每人仅有一幅图像的情况下,多数传统方法的识别性能将严重下降。压缩感知[3](Compressed Sensing,CS)是近年来新兴的信号处理方法。利用压缩感知理论,WRIGHT J等人[3]提出了一种稀疏表示人脸识别算法(Sparse Representation-based Classification,SRC)。SRC方法在局部遮挡、噪声等问题上具有相当的鲁棒性。针对单样本问题,本文提出了一种基于压缩感知的单样本人脸识别方法。该方法首先利用局部邻域嵌入非线性降维和稀疏系数将一幅人脸图像扩展为姿态表情各不同的图像,将所有新的样本作为训练样本,最后采用改进的稀疏表征方法进行识别分类。
1 压缩感知理论与SRC算法改进
1.1压缩感知(CS)
CS作为一个新的理论框架,它能以远低于奈奎斯特频率对信号进行采样。
压缩感知理论主要包括三个方面的内容:
(1)信号x∈Rn的稀疏表示问题:x=Ψα。
(2)信号低速采样问题:y=Φx。Φ是M×N维的观测矩阵,与稀疏基Ψ的乘积要满足有限等距性质。确保在降低维数的同时原始信号的信息损失也最小。
(3)信号重构问题。从线性观测y=Aα中无失真地恢复信号(其中A称为CS信息算子,A=ΦΨ),它基于如下严格的数学最优化(Optimization)问题:
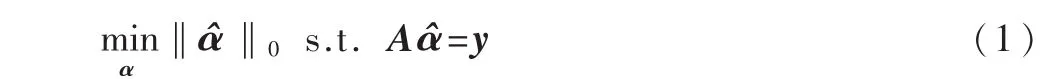
在信号足够稀疏下,基于L0和L1最小化等价的理论,可将L0范数转换成L1范数:
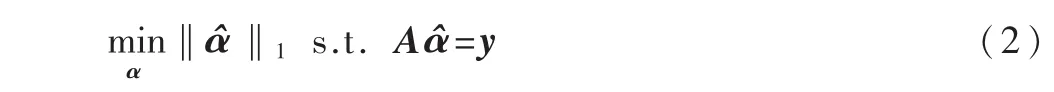
1.2SRC算法
SRC的基本思想是:将不同类别的样本组合成一个超完备字典,测试样本可由同一类的训练样本的线性组合来表示。算法可通过测试样本相对于超完备字典的稀疏表示系数区分出测试样本中所属类别。
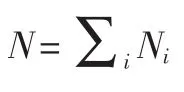
Ψ=[A1,A2,…,Ac]
则x可线性表示为:

理想条件下α=[0,0,…,0,αiT,0,0,…,0]T,该系数向量中除了与第i类有关的系数之外,其他元素都为0。
1.3基于SRC的改进算法
本文提出的算法采用了非常稀疏投影矩阵作为观测矩阵Φ,降低图像维度。参考文献[4]已证明非常稀疏投影矩阵不仅满足CS测量矩阵的必要条件,而且比高斯矩阵有更好的测量效果。在L1最小化问题上,利用对偶增广拉格朗日乘子算法寻求最优稀疏解。其原理是先将L1范数最小化问题式(2)转化为对偶问题:

其中B1∞={α∈Rn∶‖α‖∞≤1},对应的拉格朗日函数为:
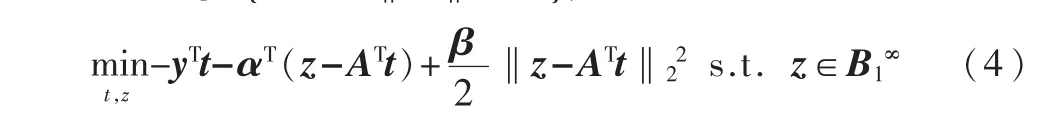
其中α是拉格朗日乘子,通过交替迭代α、t、z,求(4)式的极值,即保证了重构的精确度又降低了算法的运算度。最后为了更加精确地分类,利用加权残余确定类别。
算法步骤如下:
(1)输入C类N个训练样本,构成字典矩阵Ψ∈Rn×N。


(3)给定一个测试图像 x∈Rn。
(4)计算Yi=ΦAi,i=1,…,C,并计算测量矩阵Y=[Y1,Y2,…,Yc]=ΦΨ,其中Y∈Rn×N。
(5)计算新的投影样本y=Φx,并采用对偶增广拉格朗日乘子求得稀疏向量αˆ,使得Yα=y。
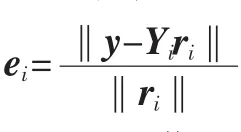
(7)若k=argmini(ei),则x属于第k类。
2 冗余样本的生成
单样本问题的难点是每个对象只有一个样本,这使得考虑类内差异的一些成熟算法识别率低。解决单样本问题的一个有效途径是增加与现实相符合的冗余样本。这种扩充训练样本个数的方法充分利用了一幅训练样本中的有用信息,便于进一步的识别分类。
2.1多姿态样本的生成
生成多姿态样本的方法是基于局部邻域嵌入非线性降维理论[5]的。具体方案步骤是:
(1)将所有人脸图像先进行小波变换,再表示为列向量形式。
(2)设输入的某姿态人脸图像为Ii,将其视为高维空间中的一点,而相同姿态训练集人脸图像Tin(包括N个图像)作为Io点的邻近点,再根据局部邻域嵌入非线性降维理论求解近邻点的权值。
“互联网+教育”可以使具有碎片式、复杂化特点的教育源配置达到最大优化和公开化,提升教育资源的共享程度,促进教育公平。“互联网 + 教育”可以将已有的优质教育资源的价值和作用发挥到最大化。通过互联网技术,一位优秀教师可以教授成千上万名学生,因此建立公办高校与民办高校教育资源共享平台,可以使民办高校与其他公办院校及优秀教师跨地区、跨时间的合作交流,不仅可以丰富资源的内容,减少成本,还可以缩小甚至消除民办高校与公办院校师资力量的差距,减小教育资源鸿沟。
(3)设目标姿态的训练集人脸图像Ton(包括N个图像),而待合成的目标姿态人脸图像为Io,然后利用步骤(2)中解出的权值反算出一个高维空间的点,即为目标角度人脸图像向量。
(3)将目标姿态人脸图像向量表示为矩阵形式,再进行小波逆变换。
这种方法能快速地生成多姿态样本,且克服现有的同类方法复杂、效果不佳的问题。图1是原人脸图像及其生成的多姿态样本,其中(a)为输入图像,(b)分别为生成的不同姿态图像,而(c)为真实图像。

图1 原人脸图像及其生成的多姿态样本
2.2多表情样本的生成
生成多表情样本的方法是基于稀疏表征的。保证所有图像大小统一,图像中眼睛、鼻子、嘴巴在各自图像中的同一个固定位置。在训练集中选取与训练样本具有相同表情的人脸图像作为变换基,使该变换基能近似地线性表示测试图像,求解出稀疏表示系数。同时选取包含目标表情的人脸图像组成数组。最后利用该数组和稀疏表示系数重构出目标表情人脸。
该方法因为没有复杂的提取人脸特征的步骤,从而算法的复杂度也相对降低了。图2是同一张人脸生成的多表情的人脸图像,其中(a)为输入的高兴的人脸测试图像,(b)~(f)分别为生成的生气、厌恶、害怕、伤心、惊讶的人脸图像,而(g)为真实图像。
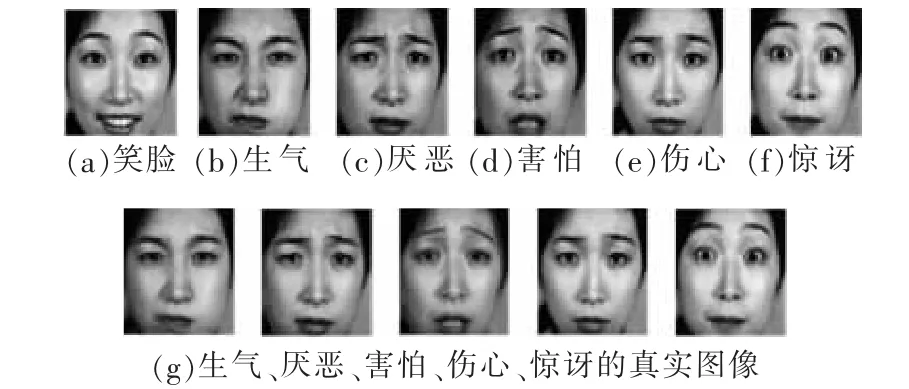
图2 原人脸图像及其生成的新样本
3 实验设计及仿真结果
本文实验是基于ORL、FERET人脸数据库的。选取每个人的一幅图像作为训练样本,剩余的人脸图像作为测试样本。实验前统一将图像数据的大小修改为48×48。在单样本情况下,本文首先分别基于姿态库和表情库对单幅训练样本采取上文的方法扩充样本个数,以生成多姿态多表情的新图像,然后将原训练样本和新样本作为训练集,最后采用改进的稀疏表征算法进行识别分类。
3.1ORL人脸库
ORL人脸库是由40个人的灰度图像构成的,共有400张图片。图3描绘了使用不同个数冗余样本下的识别率。

图3 不同个数冗余样本下的识别率
从图3中可以看出,冗余样本的个数不够多时,识别率也偏低。随着冗余样本个数的增加,识别率大幅度增高,但当冗余样本达到8个时,识别率增长缓慢,几乎平缓。原因是训练样本太少时,样本的内蕴特征太少,此时冗余样本个数是影响识别效果的主要原因。但随着冗余样本个数的不断增加,造成大量的冗余信息,而冗余样本集与原始数据集的数据分布有不一致的地方,此时增加冗样本的个数对识别率作用不大。
将本文的算法与SRC算法、参考文献[6]、[7]中的方法进行比较,表1为比较结果。从表1可以看出,本文所提出的方法识别率高于原SRC方法15.53%,也比参考文献[6]、[7]中的算法具有更好的识别性能。

表1 单样本情况下本文方法与原SRC等方法的识别率比较
3.2FERET人脸库
FERET人脸库的1 400幅图像共有200个人,每人7幅人脸图像。图4描绘了基于FERET人脸库使用不同个数冗余样本下的识别率。
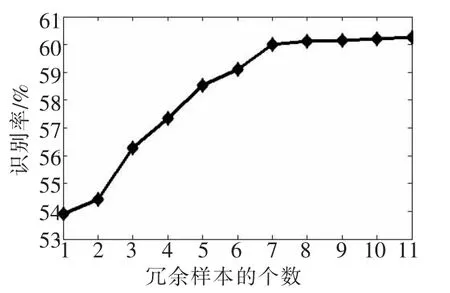
图4 不同个数冗余样本下的识别率
[7-9]就单样本人脸识别问题也做了大量的研究。通过表2可以看出,本文方法应用在FERET人脸库上的单样本人脸识别率比原SRC方法提高7.63%,也比DMMA等算法具有更好的识别性能。表2为本文方法应用在FERET人脸库上的单样本人脸识别率。
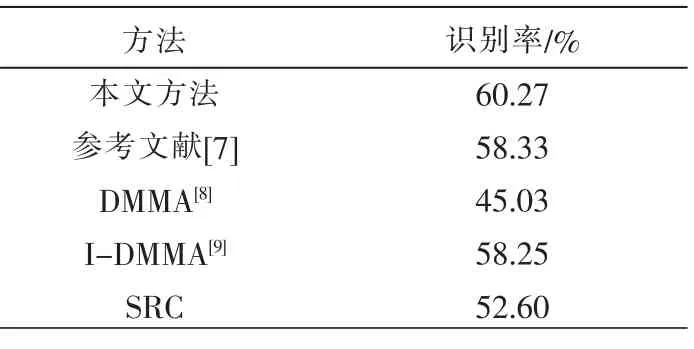
表2 单样本情况下本文方法与原SRC等方法的识别率比较
4 结论
针对人脸识别研究的单样本问题,本文提出了一种基于CS的单样本人脸识别算法。经对比实验表明,该方法不仅充分利用单个样本的特征信息,生成新的图像,而且很大程度上提高了单样本情况下的识别率,为单样本人脸识别技术提供了新的方法。
参考文献
[1]王明军.基于压缩感知的人脸识别算法研究[D].西安:西安电子科技大学,2012.
[2]Wang Jie,PLATANIOTIS K N,Lu Juwei,et al.On solv-ing the face recognition problem with one training sample per subject[J].Pattern Recognition,2006,39(9):1746-1762.
[3]WRIGHT J,YANG A Y,GANESH A,et al.Robust face recognition via sparse representation[J].IEEE Transactions on Pattern Analysisand Machine Intelligence,2009,31(2):210-227.
[4]方红,章权兵,韦穗.基于非常稀疏随机投影的图像重建方法[J].计算机工程与应用,2007,43(22):25-27.
[5]马瑞,宋亦旭.基于局部线性嵌入非线性降维的多流行学习[J].清华大学学报(自然科学版),2008,48(4):583-586.
[6]Chang Xueping,Zheng Zhonglong,Duan Xiaohui,et al. Sparse representation-based face recognition for one training image per person[A].Advanced Intelligent Computing Theories and Applications[C].Berlin Heidelberg:Springer,2010:407-414.
[7]单桂军.基于虚拟样本扩张法的单样本人脸识别算法研究[J].科学技术与工程,2013,13(14):3908-3911.
[8]Lu Jiwen,Tan Yap-peng,Wang Gang.Discriminative multimanifold analysis for face recognition from a single training sample per person[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2013,35(1):39-51.
[9]NABIPOURM,AGHAGOLZADEHA,MOTAMENIH. Multimanifold analysis with adaptive neighborhood in DCT domain for face recognition using single sample per person[C]. 2014 22nd Iranian Conference on Electrical Engineering(ICEE),IEEE,2014:925-930.
Compressive sensing-based face recognition for single sample
Xu Zhijing,Ye Li
(College of Information Engineering,Shanghai Maritime University,Shanghai 201306,China)
This paper proposes a kind of face recognition method with one training image per person,which is based on compressed sensing.There are two methods——nonlinear dimensionality reduction by locally linear embedding and sparse coefficients,by witch redundant samples can generate.These new samples with multi-expressive and multi-gesture can be treated as training samples.Finally,the improved SRC algorithm can be applied to face recognition.Experiments on the well-known ORL face database and FERET face database show that the proposed method is respectively about 15.53%and 7.67%,more accurate than original SRC method in the context of single sample face recognition problem.In addition,extensive experimentation reported in this paper suggests that the proposed method achieves higher recognition rate than RSRC,SSRC,DMMA,and I-DMMA.
face recognition;single sample;sparse representation-based classification(SRC);nonlinear dimensionality reduction
TP391.41
A
1674-7720(2015)12-0035-03
2015-01-26)
徐志京(1972-)男,工学博士,副教授,主要研究方向:航运信息采集与处理、水声信号处理与通信、压缩感知理论及应用。
国家自然科学基金(61404083);航空科学基金( 2013ZC15005 ) ;上海海事大学校基金( 20120108 )
叶丽(1991-)女,硕士研究生,主要研究方向:图像分析与视频处理。
猜你喜欢
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
计算机工程(2020年3期)2020-03-19
科技创新与应用(2020年6期)2020-02-29
中国听力语言康复科学杂志(2019年3期)2019-06-24
动漫星空(2018年9期)2018-10-26
中国交通信息化(2018年3期)2018-06-13
北京理工大学学报(2016年6期)2016-11-22
电视技术(2016年9期)2016-10-17
系统工程与电子技术(2016年7期)2016-08-21
