
一种鲁棒的多态人脸识别算法
2015-10-14 07:11:59赵继东李晶晶
电子科技大学学报 2015年2期
赵继东,李晶晶,鲁 珂,吴 跃
一种鲁棒的多态人脸识别算法
赵继东,李晶晶,鲁 珂,吴 跃
(电子科技大学计算机科学和工程学院 成都 611731)
如何处理人脸识别中的多态性一直是人脸识别领域的一个难题。传统的图嵌入算法忽视了同类中多态子类间的同属关系,而且也没有恰当地处理异类间的区别信息。该文提出一种鲁棒的图嵌入人脸识别算法,该算法可以恰当地模拟同类中的多态间关系,而且能在局部流形结构与全局区别信息间实现平衡。基于多个公开数据库的人脸识别实验证明了该方法的有效性。
人脸识别; 图嵌入; 流形学习; 多态信息
与大多数图像识别任务一样,人脸识别也经常面临“维数灾难”[1]问题,这时最常见的处理办法是使用降维技术。特征选择和子空间学习是两种经常使用的降维技术。
主成分分析(principal component analysis,PCA)、Fisher判别式分析(fisher discriminant analysis, FDA)、保局投影(locality preserving projections,LPP)[2]是3种典型的子空间学习算法。尽管PCA和FDA已经在很多应用领域成功使用,但它们处理非线性数据的效果却不太理想。在面对非线性数据时,具有流形学习能力的LPP明显优于PCA和FDA。尽管上述3种方法的原理有所不同,但可以把它们统一在一个通用的图嵌入框架下[3]。为了更好地保留标记信息,文献[4-6]提出了基于FDA的一些图嵌入方法,它们在存在标记样本集的一些场合具有优异的性能。在图像识别领域,多态图像(人脸、交通信号、手写文字等)识别[7-9]一直是一个研究热点。在多态人脸识别环境中,可以把同一类别人脸中具有同一模态的样本称为一个多态子类,如暗光、遮挡、侧脸可以为3个不同的模态。由于忽视了同类中多态子类间的同属关系,而且也没有恰当地处理异类间的区别信息,上述基于FDA的图嵌入算法在处理多态人脸识别中会遇到困难。
特征选择和子空间学习在降维应用上各有所长,近年来提出的稀疏表示方法[10-12]结合了二者的优点,成为一个研究热点。一些稀疏表示算法[12]在处理遮挡人脸识别任务时表现优异。由于稀疏表示算法可以有效地整合具有良好分类能力的特征,因而应该特别适合用于多态人脸识别任务。
受到统一图嵌入框架、基于FDA的图嵌入算法、以及稀疏表示方法的启发,本文提出一种鲁棒的多态图嵌入算法(robust multimodal graph embedding,RMGE)。为了更好地模拟多态人脸识别环境中的数据集特征,本文设计了一种新型的图结构。这种图结构可以更好地保留同类中多态子类间的同属关系,且对异类间的区别信息也进行了更有效地保留。另外,通过在子空间映射时引入稀疏子空间学习技术,该算法可以更好地提取多态数据中的区别特征。
1 图结构设计
几种监督图嵌入算法[7-8]均试图获得一个具有较强分类能力的子空间。LDE(local discriminant embedding)[7]使用一般的近邻方法构造类内图和类间图。LFDA(local fisher discriminant analysis)[8]用近邻方法构造类内图,但使用全连通方法构造类间图。CGE(constraints graph embedding)[13]把局部保留矩阵和强制约束矩阵结合在一起获得降维子空间。在多态人脸识别任务中,由于同类中多态子类间经常距离较远,因此简单地使用近邻来保留数据局部流形,可能会使得这些子类的同类属性在子空间中丢失。另外,这些方法也并没有考虑如何在保留局部流形和保留类间区别信息间达到平衡。
1.1 图结构设计规则
谱图理论[14]指出,利用邻接图、数据对之间的邻接关系可以在低维空间中得到保留。针对多态人脸识别任务设计一个鲁棒的图嵌入算法的关键是构造一个适当的图结构。当类内图的邻接边过多或过少时,数据局部流形不能很好地保留;另外,当类间连接边过多时,将会破坏类内图的紧凑性。为构造一个适合多态人脸识别的图结构定义了以下3个构图规则。
规则 1 在每个多态子类里使用近邻方法连接近邻点。
该规则可以基于预定义的认知语义,有效保留每个多态子类内的流形结构,且避免了在子类间产生混淆。
规则2 在同类中每一对多态子类间中连接距离最远的两点。
该规则强制将多态子类从最远端进行连接,可以使类内图尽量紧凑,同时又避免了破坏多态子类内的局部流形结构。
规则3 为每一类搜索个异类间近邻点(由近到远,每一个异类搜索一对近邻点)进行类间连接。
该规则在类间图里连接适当多的异类对,只会在同一异类对间出现最多一条边,也没有采用极端的全连通形式。
用几组人脸图像数据来说明本文设计的图结构。在图1中,使用具有正脸、侧脸、遮挡3个模态的类人脸数据和只具有遮挡模态的类人脸数据。图1a~图1d的4个子图分别表示原始数据、CGE的近邻图、LDE/LFDA的类内图、RMGE的类内图。其中,图1b表示CGE是在所有数据中用近邻方法构造类内图;图1c表示LDE和LFDA都是在同类中用近邻方法构造类内图;图1d表示RMGE是在同类的每个多态子类中先用近邻方法连接近邻点,然后在每一对多态子类间中连接距离最远的两点。为统一表示,对于类内图,对每个算法均取近邻参数1=2。
a. 原始数据 b. CGE的近邻图
c. LFDA/LDE类内图 d. RMGE类内图
图1 类内图构建对比示意图
在图2中,本文使用具有正脸、侧脸两个模态的类人脸数据、侧脸模态的类人脸数据、正脸模态的类人脸数据来表示类间图构造。为统一表示,在类间图中,对每个算法均取近邻参数2=2。图2a~图2d的4个子图分别表示原始数据、LFDA的类间图、LDE的类间图、RMGE的类间图。图2b表示LFDA的类间图使用全连通方式构建,该子图只表示了类中1个点的类间连接情况。图2c表示LDE的类间图使用无差别的近邻方式构建,该子图表示了类中2个点的类间连接情况,显然,、间这时没有连线。图2d表示RMGE的类间图使用由近及远逐类的近邻方式构建,对于类,2=2时,将只有两条边分别连接-、-中两对异类近邻点。
综合图1、图2可以发现,RMGE的图结构在类内图的紧凑性及类间图连接边的分布均衡性方面,明显要优于CGE、LFDA、和LDE。在类内图中,通过多态子类间最远点对的连接,RMGE可以在保持局部流形结构的同时尽量强制多态子类靠近,而LFDA和LDE均不具有该特点。在类间图中,RMGE最多只在一对异类间有一条连接边,从而比LFDA和LDE可以用更少的类间连接保留更多的类间区别信息,这种特点在类别数目较多时可以更有效地在保留类内局部流形与保留类间区别信息间取得平衡。另外,与文献[15]的方法相比,RMGE工作在全监督模式,而且连接的是多态子类间的最远点对而不是最近点对。显然,RMGE近邻图的参数1、2的选择将直接影响算法的性能,本文在后面第4节将讨论这一问题。
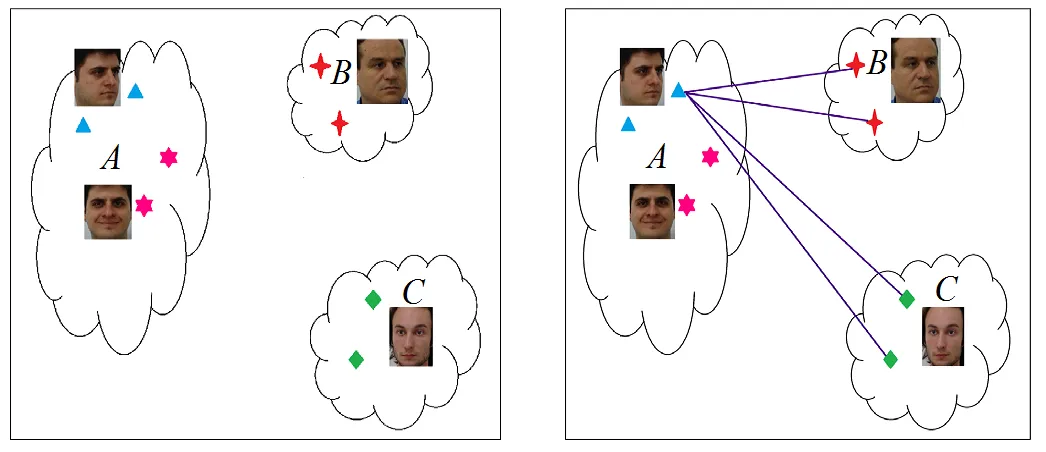
a 原始数据 b LFDA的类间图
c. LDE类间图 d. RMGE类间图
图2 类间图构建对比示意图
1.2 基于图结构的可视化实验
本文使用一个直观的简单实验来验证RMGE的图结构更适合用于多态人脸识别任务。选用4类人脸数据,每类选取10个样本,分别来自正脸、侧脸、遮挡3个模态。对于CGE,设置=4;对于LFDA,设置=3;对于LDE和RMGE,设置1=2,2=3。使用不同算法得到的图像数据3维可视化结果如图3所示。
从图3可以看出,由于使用全局近邻而且没有类间图,CGE的可视化呈现为一个较混杂的球形分布。对于LFDA,由于使用全连接的类间图,图像的可视化显示类间区别清晰,但类内紧凑性被严重破坏。对于LDE的可视化结果,类内分布较紧凑,但由于类间连接容易重复在最近邻的两类间,使得其他异类间的点在降维后容易出现混杂。对于RMGE,其可视化结果明显优于其他3种算法。
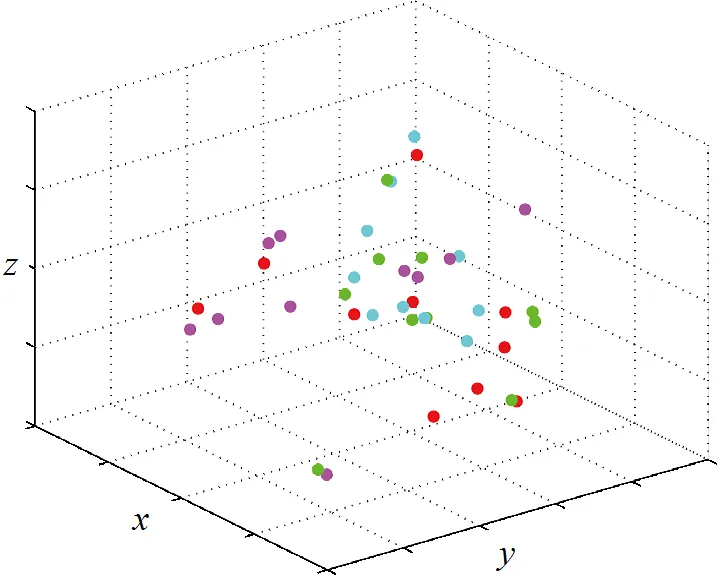
a. CGE可视化效果
b. LFDA可视化效果
c. LDE可视化效果
d. RMGE可视化效果
图3 三维可视化实验对比示意图
2 优化的图嵌入算法
基于前面设计的图结构,可以通过通用的图嵌入框架得到嵌入映射矩阵,然后获得一个低维子空间。但为了更适合多态人脸识别环境,将稀疏子空间学习方法结合到图嵌入过程中,使低维子空间能够更好地提取多态图像的类间区别特征,从而对多态人脸图像具有更强的分类识别能力。下面先对基本图嵌入进行说明,然后介绍如何将稀疏子空间学习结合到图嵌入过程中,最终获取一个优化的子空间模型。
2.1 基本图嵌入
按照本文的构图规则,可以构造一个类内图{G,W}和一个类间图{G,W}。设=[1,2, …,y]T是基于图的低维映射向量,按拉普拉斯规则[16],可以得到:
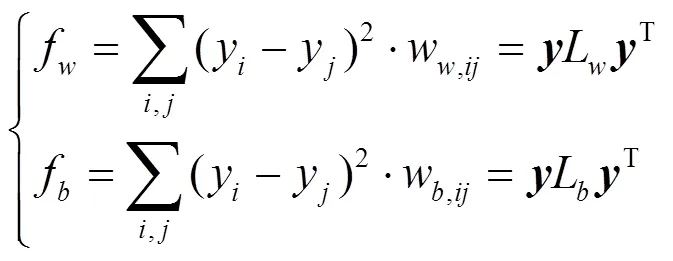
式中,L、L分别是类内图和类间图的拉普拉斯算子。显然应该最小化类内距离并最大化类间距离,以得到更好的图嵌入子空间,按照基于FDA的LPP框架[4-5],可以得到目标函数为:
(2)
设是转换矩阵,是图像数据的原始特征表示,则=T。式(2)可以表示为:
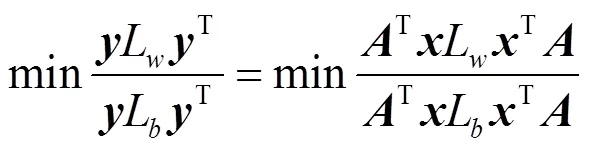
然后,转换矩阵可以通过求解得到:
(4)
2.2 优化图嵌入
对于多态人脸识别任务,多态性经常表现为人脸角度、光照、遮挡等变化因素,因此要求映射子空间能尽量从多态的原始数据中保留那些对分类最有用的特征。由于稀疏子空间学习可以将降维映射和特征选择结合起来,因此,期望通过它能得到一个优化的子空间模型。本文主要参考投影矩阵列稀疏方法。类似的优化方法也在文献[8,14]中被使用。首先,转换矩阵可以通过下式实现稀疏特性:

这样,中只有少量的元素是非零的。因此,那些使得最能接近它的低维表示的特征将得到保留。为了使得尽量稀疏,可以增加一个正则项:
(6)
可以将式(3)变形为:
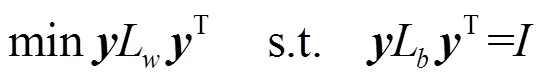
结合等式(5)~式(7),可以得到优化的目标函数为:
(8)

然后可以得到:
(10)
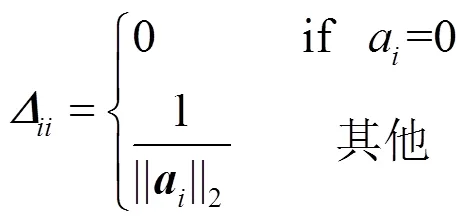
其中,

(12)
于是,优化的目标函数可以用如下方法求解:首先是定值,通过式(12)可以求解出;然后将代入式(10)可以得到更新后的;重复上述两步,直到和收敛。
3 实验结果
本文将通过以下实验来验证RMGE的有效性。本文对以下算法进行对比测试:
1) CGE算法[13],CGE通过把类别标志作为附加的强制约束来实现监督学习,在全监督模式下,该算法类似于有监督的LPP算法。
2) LDE[4]和LFDA[5],两种典型的基于FDA框架的LPP算法,其原理本文前面已作介绍。
3) SRLP[17],该算法直接用一个基于稀疏表示的矩阵来替换LPP的转换矩阵。
4) LSIR[18],该算法基于逆向回归框架,应用kNN方法来保留数据集的局部结构。
本文选取了多态性比较明显的两个人脸数据库(CMU PIE, UCSD/Honda)来进行比较试验。CMU PIE包含68类共41 368幅人脸图片,UCSD/Honda是一个包括15类,每类两段人脸视频的数据库。
为了增加比较实验的可信度,测试了多个类别数(=4, 5, 6, 7, 8, 9, 10, 11,12)的情况。对于CMU PIE,随机选择训练集后剩余的图像构成测试集;对于UCSD/Honda,训练集直接被用作测试集。本文在实验中用最近邻分类器来判定人脸类别,实验结果如图4所示。
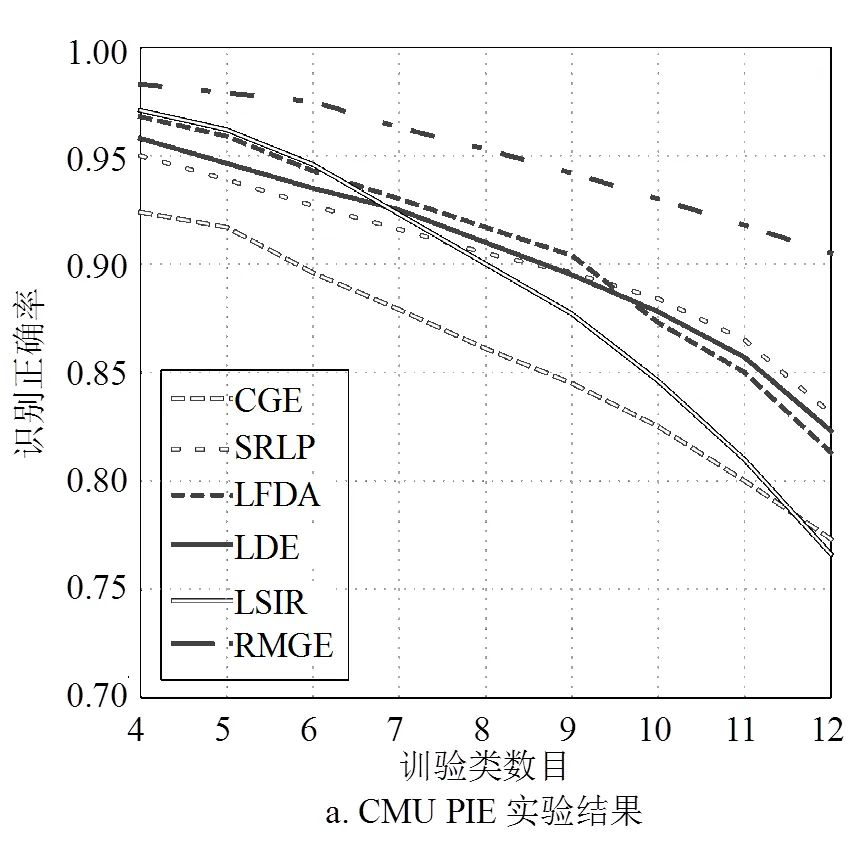
通过图4可以发现:
1) RMGE和SRLP的识别效果明显优于CGE,证实了稀疏表示和本文提出的图结构对于多态人脸识别的助益。与RMGE相比,SRLP仅仅使用了稀疏转换矩阵,而没有涉及近邻图结构的改善,因此其识别效果不如RMGE。
2) 由于在子空间学习时同时考虑类内结构和类间信息,LDE和LFDA可以在类别数较少时获得优于SRLP的效果,甚至接近RSGE。但类别数较大时,不合理的类间连接会破坏类内图的紧凑性,从而使得这两种方法的效果急剧降低。相比LDE,LFDA的全连接方式在类别数增大时表现会更差。
3) 对于LSIR来说,逆向回归方法在类别数较少时效果很好,准确率只略低于RMGE,但类别数增加后,LSIR算法的准确率下降比其他算法更剧烈,证明其不适合类别数较多的多态人脸识别任务。
通过两个数据库的比较实验,证实了RMGE在多态人脸环境下的识别效果明显优于其他方法。这种优势应该主要来源于其独特的近邻图结构,该结构能很好地保留原始数据的多态结构;另外,利用稀疏子空间学习来优化图嵌入过程也应该对算法性能的提升有一定帮助。
4 总 结
本文提出一种鲁棒的图嵌入人脸识别算法RMGE,对于多态人脸识别任务,该算法可以恰当地模拟同类中的多态间关系,而且能在局部流形结构与全局区别信息间实现平衡。与现有的一些典型监督图嵌入算法相比,由于有更恰当的图结构并在子空间学习时引入了稀疏表示方法,该算法能明显提升多态人脸识别的准确率。
[1] DUDA R O, HART P E, STORK D G. Pattern classication[M]. 2nd ed. [S.l.]: John Wiley and Sons, 2000.
[2] HE X F, NIYOGI P. Locality preserving projections[C]// NIPS. Cambridge, MA, USA: MIT, 2003: 159-167.
[3] YAN S C, XU D, ZHANG B Y, et al. Graph embedding and extensions: a general framework for dimensionality reduction[J]. IEEE Trans Pattern Anal Mach Intell, 2007, 29(1): 40-51.
[4] CHEN H T, CHANG H W, LIU T L. Local discriminant embedding and its variants[C]//CVPR. Piscataway, NJ, USA: IEEE, 2005: 846-853.
[5] SUGIYAMA M. Local fisher discriminant analysis for supervised dimensionality reduction[C]//ICML. New York, USA: ACM, 2006: 905-912.
[6] CAI D, HE X F, HAN J. Semi-supervised discriminant analysis[C]// ICCV. Piscataway, NJ, USA: IEEE, 2007: 1-7.
[7] ZENG Q S, LAI J H, WANG C D. Multi-local model image set matching based on domain description[J]. Pattern Recognition, 2014, 47(2): 694-704.
[8] LU K, DING Z, GE S. Sparse-representation-based graph embedding for traffic sign recognition[J]. IEEE Transactions on Intelligent Transportation Systems, 2012, 13(4): 1515- 1524.
[9] SHARMA A, JACOBS D W. Bypassing synthesis: Pls for face recognition with pose, low-resolution and sketch[C]// CVPR. Piscataway, NJ, USA: IEEE, 2011: 593-600.
[10] ZOU H, HASTIE T, TIBSHIRANI R. Sparse principal component analysis[J]. Journal of Computational and Graphical Statistics, 2006, 15(2): 265-286.
[11] GU Q Q, LI Z H, HAN J W. Joint feature selection and subspace learning[C]//IJCAI. Menlo Park, USA: AAAI, 2011: 1294-1299.
[12] WRIGHT J, YANG A Y, GANESH A, et al. Robust face recognition via sparse representation[J]. IEEE Trans Pattern Anal Mach Intell, 2009, 31(2): 210-227.
[13] HE X F, JI M, BAO H J. Graph embedding with constraints[C]//IJCAI. Pasadena, CA, USA: AAAI, 2009: 1065-1070.
[14] CHUNG F R K. Spectral graph theory[M]. [S.l.]: American Mathematical Soc, 1997.
[15] LU K, DING Z, ZHAO J. Locally connected graph embedding for semisupervised image classification[J]. Journal of Electronic Imaging, 2012, 21(4): 43-52.
[16] BELKIN M, NIYOGI P. Laplacian eigenmaps and spectral techniques for embedding and clustering[C]//NIPS. Cambridge, MA, USA: MIT, 2001: 585-591.
[17] TIMOFTE R, GOOL L V. Sparse representation based projections[C]//Proceedings of the British Machine Vision Conference. [S.l.]: BMVA, 2011: 1-12.
[18] WU Q, LIANG F, SAYAN M. Localized sliced inverse regression[J]. Journal of Computational and Graphical Statistics, 2010, 19(4): 843-860.
编 辑 黄 莘
A Robust Multimodal Face Recognition Algorithm
ZHAO Ji-dong, LI Jing-jing, LU Ke, and WU Yue
(School of Computer Science and Engineering, University of Electronic Science and Technology of China Chengdu 611731)
It is always a difficult problem in face recognition on how to process the multimodal information (e.g. variation in lighting or orientation). Traditional graph embedding algorithms neglect congener correlation between different multimodal clusters of the same class (i.e. subject) and do not properly incorporate discriminative information between classes. In this paper, a robust graph embedding face recognition algorithm is proposed. It properly captures multimodal structure within one class and also realizes a balance between local manifold structures and the global discriminative information. Experiments in several public databases demonstrate that the proposed algorithm can achieve better performance than the state-of-arts reported in recent literatures.
face recognition; graph embedding; manifold learning; multimodal information
TP391.4
A
10.3969/j.issn.1001-0548.2015.02.020
2014-08-29;
2014-11-05
国家自然科学基金(61273254,61371183)
赵继东(1976-),男,副教授,主要从事图像处理及计算机视觉等方面的研究.
猜你喜欢
系统工程学报(2021年4期)2021-12-21 06:21:08
数学年刊A辑(中文版)(2021年4期)2021-02-12 01:21:02
无线互联科技(2020年22期)2021-01-11 13:52:34
弹箭与制导学报(2020年2期)2020-09-01 02:08:56
新世纪智能(高一语文)(2020年12期)2020-06-01 08:14:20
传感器与微系统(2018年7期)2018-08-29 00:44:42
数学物理学报(2018年1期)2018-03-26 08:16:37
自动化学报(2017年4期)2017-06-15 20:28:55
中国医药导报(2015年27期)2015-02-28 22:08:01
中国神经精神疾病杂志(2013年1期)2013-03-11 20:23:33
