
高性能分布式搜索引擎Solr的研究与实现
2015-10-14 06:39:38朱志祥张康益
电子科技 2015年4期
赵 璞,朱志祥,张康益
(西安邮电大学 计算机学院,陕西 西安 710061)
高性能分布式搜索引擎Solr的研究与实现
赵 璞,朱志祥,张康益
(西安邮电大学 计算机学院,陕西 西安 710061)
针对信息资源不断膨胀传统搜索技术无法达到高效、可靠的服务需求问题。设计并实现了一中基于Solr的高性能分布式搜索。系统通过使用Zookeeper管理集群,实现搜索模块分布式,利用Solr做索引处理,在多节点上并行创建索引,并将SolrCloud与Mongodb数据库的搭建连接,通过测试表明,系统展现了SolrCloud对数据库搜索功能的提高效果。
Solr;SolrCloud;Zookeeper;Mongodb
随着大数据时代的到来,如何利用一种高效的查询工具从浩如烟海的信息中可以快速、简单、精确地找到所需要的信息。搜索引擎技术在这种背景下应运而生。
现在,对于解决这个需求已经出现了很多搜索引擎的雏形。这些雏形为用户和其它的 Web 服务提供访问。但是他们无法做到高覆盖率、高准确度、大并发量、快速响应等需求。而分布式搜索引擎策略,完全可以高效地解决这方面需求。分布式搜索引擎策略就是当用户登录到任何一台服务器时,除了本地资源的检索服务器可以为客户端提供搜索服务,也可以自动连接到其它服务器,发出搜索请求,并将检索后的结果合并汇总反馈给最终用户。在这种方式下,用户只需登录到任何一台服务器,就可从不同的服务器获取所需资源。用户检索和获取这些资源的方式就如同检索和访问相同的服务器。
因此,研究在大数据环境下的分布式搜索引擎就显得尤为重要。本文提出基于Solr的高性能分布式搜索模型,模型创新之处在于,引入Zookeeper管理集群,将搜索构建成并行的分布式处理,将索引分成独立的集群组,搜索时通过相应的路由规则定位至索引信息所在的集群组,减少索引搜索时间,提高搜索性能。
1 开源搜索引擎Solr
1.1 Solr简介
Solr是一个高性能,采用Java5开发,基于Lucene的全文搜索服务器。同时对其进行了扩展,提供了比Lucene更丰富的查询语言,实现了可配置和扩展,并对查询性能进行了优化,并且提供了一个完善的功能管理界面,是一款优秀的全文搜索引擎。
1.2 Solr体系架构
Solr的完整体系架构如图1所示,上层由管理员接口、HTTP请求管理器和索引更新处理器 3 大模块组成。中间层为Solr的核心层,Config模块负责整个系统的配置,Schema负责索引参数的加载与解析,Analysis模块负责查询请求的分析,Concurrency模块负责提供建立索引和读取索引的并发控制,Caching负责文档缓存。架构的底层为全文索引工具Lucene,另外,索引复制(Replication)功能是一个独立模块,用于支持分布式索引和检索[1]。
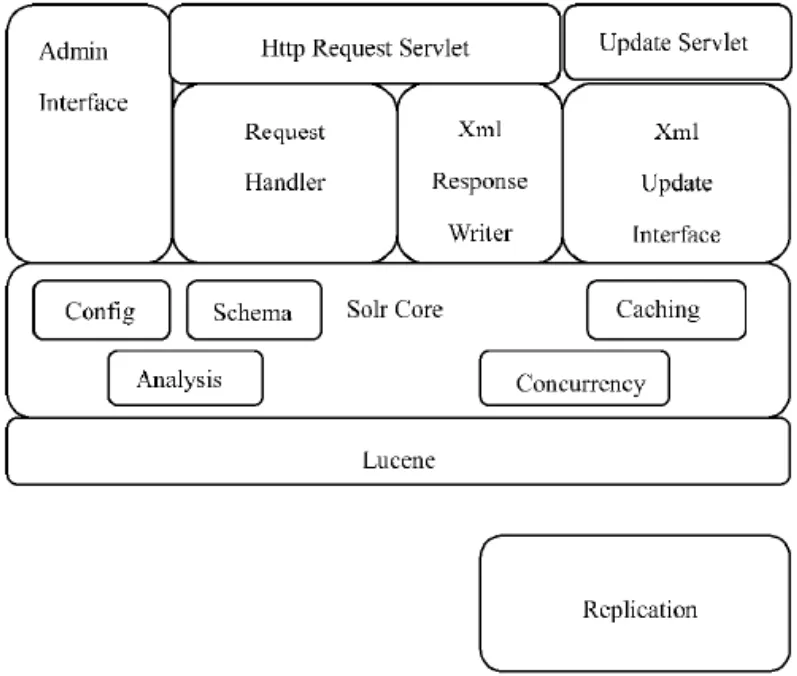
图1 Solr体系架构
1.3 Solr与SolrCloud
SolrCloud是基于Solr和Zookeeper的分布式搜索方案,它的主要思想是使用Zookeeper作为集群的配置信息中心。它有几个特色功能:(1)集中式的配置信息。(2)自动容错。(3)近实时搜索。(4)查询时自动负载均衡。(5)自动分发的索引和索引分片。(6)事务日志。
SolrCloud的索引和实体对照如图所示。这是拥有3个Solr节点的集群。Collection是SolrCloud集群中逻辑意义上的完整索引。它通常被划分为一个或多个Shard,它们使用相同的Config Set。如果Shard数超过一个,它就是分布式索引,SolrCloud通过Collection名称被引用,而无需关心分布式检索时需要使用的Shard相关参数。Shard即是Collection的逻辑分片。每个Shard被分为一个或多个replicas,通过选举确定Leader。选举可以发生在任何时间,但通常他们仅在某个Solr实例发生故障时才会触发。一个Solr中包含一个或多个Solr Core,每个Solr Core可以独立提供索引和查询功能,每个Solr Core对应一个索引或Collection的Shard,Solr Core的提出是为了增加管理灵活性和共用资源。在SolrCloud中有所不同的是它使用的配置在Zookeeper中,传统的Solr core的配置文件是在磁盘上的配置目录中。当索引documents时,SolrCloud会传递它们到此Shard对应的leader,leader再分发它们到全部Shard的replicas。Replica就是Shard的一个拷贝。每个Replica存在于Solr的一个Core中。一个命名为“test”的collection以numShards=1创建,并且指定replicationFactor设置为2,这会产生2个replicas,也就是对应会有2个Core,每个在不同的机器或者Solr。一个会被命名为test_shard1_replica1,另一个命名为test_shard1_replica2,它们中的一个会被选举为Leader。

图2 索引和Solr实体对照图
2 SolrCloud索引Mongodb数据库的实现
在具体实现SolrCloud索引Mongodb数据库的过程中,本文用到了Mongodb数据库的一个插件mongo-connector,通过使用mongo-connector,将Mongodb内的数据文档复制到已经搭建好的SolrCloud系统,并不断地在系统上执行更新保持Mongodb数据库和SolrCloud系统内数据同步,这是一种方便实用的方法。
2.1 安装外部Zookeeper
Solr默认是用内置的Zookeeper,为便于管理和维护,建议使用外部Zookeeper。首先将下载好的Zookeeper-3.4.6.tar.gz解压缩安装,进入Zookeeper-3.4.6文件夹,创建data 和log。拷贝Zookeeper配制文件zoo_sample.cfg重命名zoo.cfg。在其中加上dataDir路径,clientPort和server信息。在data文件夹中建立myid文件内容为1。
2.2 Solr集群安装
(1)将Solr-4.8.0.tgz解压缩安装,Solr-4.8.0/dist/Solr-4.8.0.war 复制到/SolrCloud/Solrhome 并重命为Solr.war。
(2)将apache-tomcat-7.0.52.tar.gz解压缩安装,配置tomcat,将solrhome的路径加进tomcat。
(3)将Zookeeper和Tomcat关联。
2.3 连接Mongodb数据库
(1)解压缩安装mongo-connector。
(2)修改Solr文件配置。
(3)建立链接,进入mongoconnector,输入命令
python connector.py-m 10.10.10.51:30000-t http://10.10.10.61:8080/Solr/-o oplog_progress.txt-n test.test-u_id-d./doc_managers/Solr_doc_manager.py
至此,整个安装过程完毕。打开Solr1主页查看Solr管理页面,发现到已经有索引在建立,并且后台在不断更新数据。在SolrCloud与Mongodb建立连接后,具体创建索引过程如图3所示,首先mongo-connector将文档从Mongodb数据库中提交给任一Replica,如果它不是Leader,则会把请求转交给与之相同Shard的Leader,Leader把文档路由给本Shard的每个Replica。如果文档基于路由规则并不属于本Shard,Leader会把它转交给对应Shard的Leader,对应Leader会把文档路由给本Shard的每个Replica。

图3 创建索引过程
2.4 搜索性能测试
在Solr的管理页面,可以找到搜索栏。输入要搜索的内容,Solr会显示出搜索时间和检索到的数量,这是最直接体现搜索性能的指标。通过图4不难发现,Solr可以在79 mV的时间内检索到2 783 097个数据,提高了Mongodb数据库自我检索能力。
3 结束语
通过实现该系统,可以看到,分布式搜索引擎Solr对于数据索引速度的提升非常明显,尤其在数据量较大时,高并发分布式索引的速度是一般索引的数倍速度。就本系统而言,仅处于实验阶段,文中并没有对搜索数据具体准确度进行测试,后续将用大量数据测试来检验该系统准确度,并对系统界面进行优化,实现友好的用户操作界面。

图4 SolrCloud检索Mongodb数据库运行结果
[1] 李戴维,李宁.基于Solr的分布式全文检索系统的研究与实现[J].计算机与现代化,2012,(11):171-176.
[2] 王小森.基于Solr的搜索引擎的设计与实现[D].北京:北京邮电大学,2011.
[3] Otis Gospodnetic,Erik Hatcher.Lucene in Action中文版[M].北京:电子工业出版社,2007.
[4] Solr Wiki.Welcome to the Apache Solr Wiki [EB/OL].(2013-11-11)[2014-09-01]http://wiki.apache.org/solr.
[5] Solr.Apache Solr [EB/OL].(2011-01-10)[2014-09-01] http://lucene.apache.org/solr.
[6] Introducing Mongo Connector.MongoDB[EB/OL].(2012-08-10)[2014-9-11]http://blog.mongodb.org/post/29127828146/introducing-mongo-connector.
[7] 傅巍玮,李仁发,刘钰峰,等.基于Solr的分布式实时搜索模型研究与实现[J].电信科学,2011(11):51-56.
[8] 张新生.基于Solr的分布式搜索引擎研究[D].武汉:华中科技大学,2012.
[9] 孙进.基于Slor的个性化搜索引擎设计与实现[D].北京:北京化工大学,2012.
[10]李雪利.基于Solr的企业搜索引擎的研究与实现[D].杭州:浙江理工大学,2013.
Research on and Implementation of a High-performance Distributed Search Engine Solr
ZHAO Pu,ZHU Zhixiang,ZHANG Kangyi
(School of Computer Science,Xi’an University of Posts and Telecommunications,Xi’an 710061,China)
The traditional search technology cannot provide efficient and reliable services for users because of the increasingly expansion of information resources.This paper designs and implements a distributed search with good performance based on Solr.By using Zookeeper cluster management,the search modules are distributed within the system.using the Solr for index processing,indexes are created parallel on multiple nodes.And the construction of the SolrCloud and Mongodb is connected.Tests show that the SolrCloud can improve the database search function.
Solr;SolrCloud;Zookeeper;Mongodb
2014- 09- 24
赵璞(1987—),男,硕士研究生。研究方向:大数据处理。E-mail:zhaopu568@foxmail.com。朱志祥(1959—),男,博士,教授。研究方向:信息安全和云计算。张康益(1988—),男,硕士。研究方向:航天测控。
10.16180/j.cnki.issn1007-7820.2015.04.020
TP311.123
A
1007-7820(2015)04-073-03
猜你喜欢
中国新闻周刊(2021年26期)2021-07-27 04:02:12
军事运筹与系统工程(2019年4期)2019-09-11 06:39:58
电子制作(2018年11期)2018-08-04 03:25:40
中国交通信息化(2017年3期)2017-06-08 06:09:28
知识就是力量(2017年2期)2017-01-21 18:29:36
信息安全研究(2016年4期)2016-12-01 06:06:54
Asian Pacific Journal of Reproduction(2015年1期)2015-12-22 12:09:35
中国卫生(2015年12期)2015-11-10 05:13:38
新疆大学学报(自然科学版)(中英文)(2014年2期)2014-11-06 07:49:12
技术经济与管理研究(2014年11期)2014-03-11 17:02:44
