
基于SVM算法的分类器设计
2015-10-14 07:16:50危傲
电子科技 2015年4期
危 傲
(西安电子科技大学 电子工程学院,陕西 西安 710071)
基于SVM算法的分类器设计
危 傲
(西安电子科技大学 电子工程学院,陕西 西安 710071)
介绍了支持向量机算法的基本思想、数据分类的概念,分析了传统支持向量机算法的一般特性。用Libsvm工具箱实现了基于SVM算法的分类器设计,并用公共数据库中的数据集对设计的分类器进行了测试,重点针对训练样本的选择、参数的影响选择与优化问题进行了研究。实验结果表明,在应用支持向量机算法做数据分类时,选择合适的训练样本和参数有利于提高分类器的准确度。
支持向量机;Libsvm工具箱;分类器
支持向量机(Support Vector Machine,SVM)作为基于统计学习的一种新的通用机器学习方法,其较以往方法表现出在理论和实践上的优势,较好地解决了小样本、非线性、高维和局部极小等问题,在模式识别、回归估计,分类等领域都得到了广泛应用[1-2]。支持向量机方法又称为核方法,这是因为核的展开和计算是这一方法的关键。但核函数的嵌入也成为支持向量机方法应用的缺点,如核函数选择缺乏理论指导,算法参数难以选择等。这给SVM在实际应用的推广带来了困难,如何得到合适且有效的核函数及其参数,是采用支持向量机算法进行数据分类的关键。
1 支持向量机算法
1.1 算法思想
支持向量机算法的主要思想可以概括为:(1)它针对线性可分情况进行分析,而对于线性不可分的情况,通过使用非线性映射算法将低维输入空间线性不可分的样本转化为高维特征空间使其线性可分,从而使高维特征空间采用线性算法对样本的非线性特征进行线性分析成为可能。(2)它基于结构风险最小化理论,在特征空间中建构最优分割超平面,使得学习器得到全局最优化,并在整个样本空间的期望风险以某个概率满足一定上界。
1.2 原理简介
支持向量机基于线性划分,但可以想象,并非所有数据均可线性划分。如二维空间中的两个类别的点可能需要一条曲线来划分其边界。支持向量机的原理是将低维空间中的点映射到高维空间中,使其成为线性可分的。再使用线性划分的原理来判断分类边界。在高维空间中,它是一种线性划分,而在原有的数据空间中,它是一种非线性划分[2]。

有约束问题,一般表达为
(1)
支持向量机对于非线性可分的情况,可使用一个非线性函数φ(x)将数据映射到一个高维特征空间,再在高维特征空间建立优化超平面,分类函数变为
(2)
通常无法了解φ(x)的具体表达,也难以知晓样本映射到高维空间后的维数和分布等情况,不能在高维空间求解超平面;b是分类阙值,可用任意一个支持向量求得,或通过两类中任意一对支持向量取中值求得。由于SVM理论只考虑高维特征空间的点积运算φ(xi)·φ(xj),而点积运算可由其对应的核函数直接给出,即K(xi,xj)=φ(xi)·φ(xj)用内积K(xi,xj)代替最优分类面中的点积,就相当于将原特征空间变换到了某一新的特征空间,得到新的优化函数
(3)
求解上述问题后得到的最优分类函数是
(4)
上式中的求和实际上只对支持向量进行。其中核函数K(xi,x)可有多种形式,常用的有
(1)线性核K(x,y)=(x·y)。
(2)多项式核K(xi,x)=(xi·x+1)d,d是自然数。
(3)Radial Basis Fuction(RBF)核(径向基核)
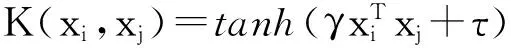
支持向量机的一个显著特点是,计算的复杂度程度与输入空间映射成的核空间的维数无关。因此,就没有了维数问题。换言之,人们在高维空间中进行设计,不必使用大量参数的显模式,其由空间的高维数决定。这也对扩展性产生了影响,而实际上SVM具有较好的扩展性。
支持向量机的一个局限是,直到目前为止也没有最佳方法选择核函数,这仍是一个未解决的问题。但通常而言,径向基核函数不会有过大偏差,对大部分分类问题的效果不会有较大差异,故是首选。
1.3 支持向量机的一般特性
(1)SVM学习问题可表示为凸优化问题,因此可利用已知的有效算法发现目标函数的全局最小值。而其他分类方法都采用一种基于贪心学习的策略来搜索假设空间,这种方法一般只能获得局部最优解。(2)SVM通过最大化决策边界的边缘来控制模型的能力。尽管如此,用户必须提供其他参数,如使用核函数类型和引入松弛变量等。(3)通过对数据中每个分类属性引入一个哑变量,SVM可应用于分类数据。(4)SVM一般只能用在二类问题,对于多类问题效果不佳。
2 基于SVM的分类器设计
2.1 分类器原理
数据分类是数据挖掘中的一个重要题目。数据分类是指在已有分类训练数据的基础上,根据某种原理,经训练形成一个分类器;然后使用分类器判断测试数据的类别[5]。
基于SVM的分类器是一种基于分类边界的方法。其基本原理是:若训练数据分布在二维平面上的点,按照其分类聚集在不同的区域。基于分类边界的分类算法的目标是,通过训练找到这些分类之间的边界。对于多维数据,可将其视为N维空间中的点,而分类边界就是N维空间中的面,称为超面。线性分类器使用超平面类型的边界,非线性分类器使用超曲面。
线性划分如图1所示,可根据新的数据相对于分类边界的位置来判断其分类。一般首先讨论二分类问题,然后再拓展到多分类问题。
2.2 基于SVM算法的分类器的实现步骤
(1)将数据集转化为SVM支持的格式。(2)数据预处理,将数据集的分类属性值归一化并选择训练集和测试集。(3)选择核函数类型。(4)采用交叉验证和网格搜索方法寻找最优的参数c和gamma。(5)用最优化的参数训练出分类器。(6)用设计的分类器进行测试[3-6]。
3 实验与结果分析
实验以Matlab为开发平台[7],用Libsvm工具箱设计了一个简单的分类器,并用公共数据库中的数据集为训练样例和测试样例,重点对其从训练集的选择方法,参数的选择与优化方面进行测试与验证。
3.1 数据集的划分
为方便结果的可视化,本文测试数据集的特征向量为二维,共包含210个样例,其中前100个为正例,后110个为反例。将数据集按3种方法划分出训练集和测试集。取参数c=16,g=0.01,然后分别对这其进行测试,测试结果如表1所示。

表1 3种数据集划分方法的测试结果
从实验结果可看出,前两种均分法不佳,这是因训练集包含的正反例涵盖不全,导致一些特例分类错误。第3种分法涵盖较均匀且全面,分类效果最佳,为方便验证算法参数的影响,本实验选择第3种分法进行测试验证。
3.2 参数c和g的优化
剖宫产术后疼痛主要分为腹部的切口痛、子宫的宫缩痛以及炎性疼痛。切口痛来源于腹部伤口的创伤性刺激,经脊髓后角,传递到中枢神经系统,呈持续存在状态。子宫收缩时,神经末梢受压,子宫下段及会阴部扩张,产生宫缩痛,为短暂间断发作的绞痛。同时,子宫收缩可导致局部血管缺血,组织缺氧,释放炎症介质,导致炎性疼痛。剖宫产术后疼痛以宫缩痛更为明显,疼痛一般在术后12h内达到高峰,24h内持续处于较高水平[2]。
令c=2-5,2-3,…,215,g=2-15,2-13,…,23,采用交叉验证和网格搜索的方法寻找最优的参数bestc和bestg,搜索结果如图2所示。得出最好的参数bestc=23 170,bestg=0.000 244 14,对应的准确率为96.666 7%(58/60)。最优的参数bestc和bestg对应的可视化分类结果如图3所示。
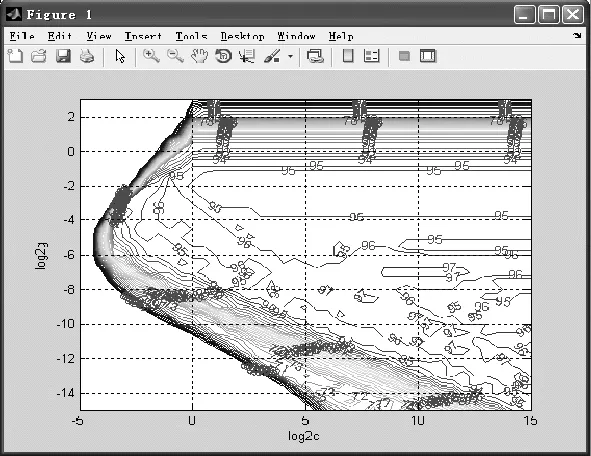
图2 交叉验证和网格搜索结果
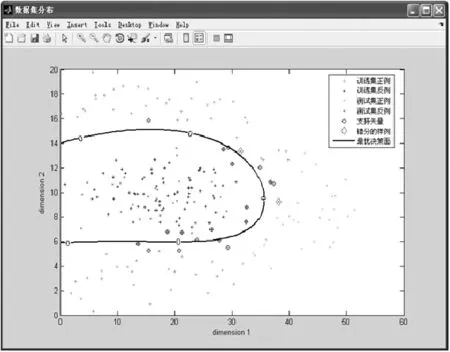
图3 最优参数bestc和bestg的实验结果
3.3 参数c的选择及影响
固定选取g=0.000 244 14,测试不同参数c值对应的分类准确度,测试结果如表1所示。

表1 g=0.002 441 4情况下不同c值对应的分类准确度
参数c的值在变化过程中的一些典型值对应的分类结果如图4所示。

图4 参数c值在变化过程中一些典型值对应的分类结果
从测试结果可以看出,惩罚因子c决定了有多重视离群点点来的损失,随着c值的增大,对目标决策函数的损失也越大,此时则暗示非常不愿放弃这些利群点,如果继续将c值增大,增大到无穷大时,只要稍有一个点离群,目标决策函数的值就会变为无限大,使问题无解,这样分类器的分类效果则会很差。
惩罚因子c不是一个变量,整个分类器优化过程中,c是一个必须事先制定的值,制定这个值后,解得一个分类器,然后用测试数据查看结果,若不理想,则更换c值再得到一个分类器,再看效果,如此则是一个参数寻优的过程,最终可以求出分类器效果最好的c值。根据对这些离群点的重视程度来选择合适的c值,如果对离群点不是很重视,则可选择个小的c值,若这些离群点重要,则应选择较大c值。
3.4 参数g的选择及影响
固定选取c=23 170,测试不同参数g对应的分类准确度,测试结果如表2所示。
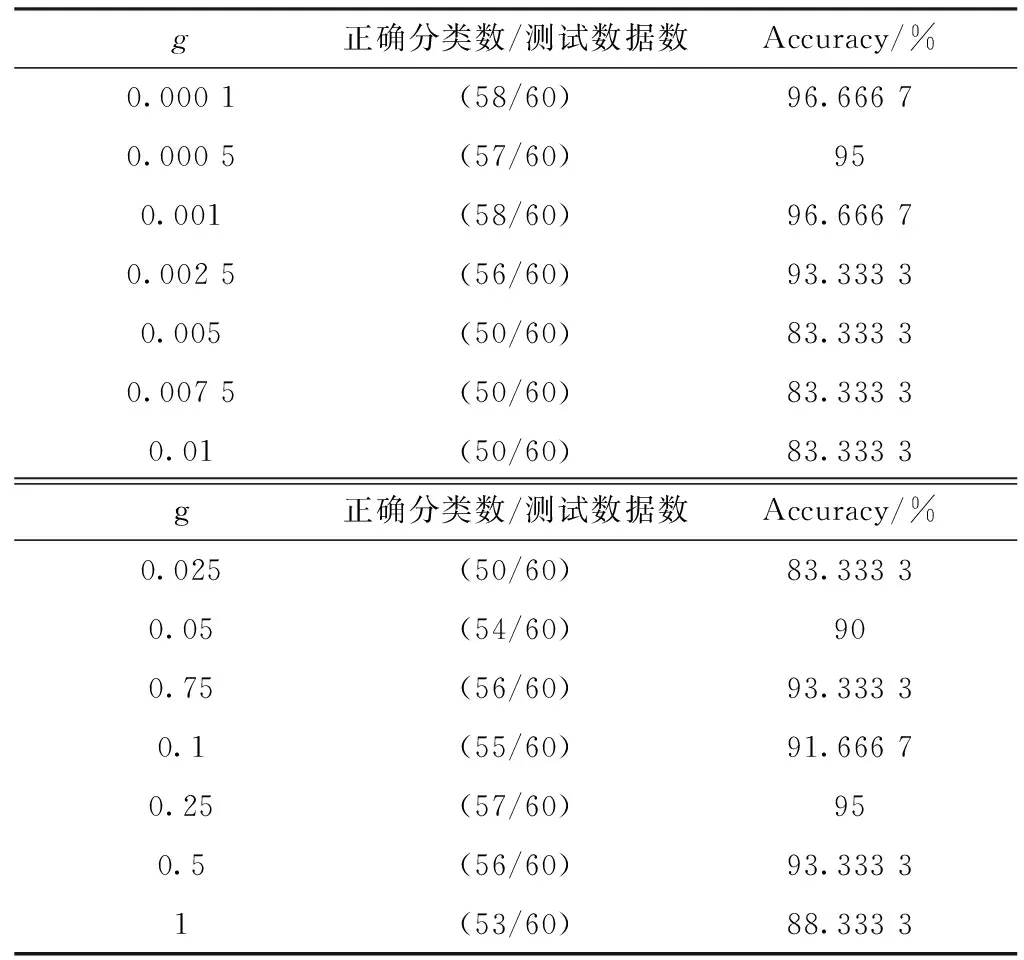
表2 c=231 70情况下不同g值对应的分类准确度
参数g在变化过程中典型值对应的分类结果如图5所示。

图5 典型g值对应的分类结果
gamma参数是选择径向基函数作为kernel后,该函数自带的参数。隐含地决定了数据映射到新特征空间后的分布。从实验结果中虽然无法直接观测到数据映射到新特征空间后的分布情况,但是通过支持向量的变化可以看出gamma参数对分类器的影响,随着gamma参数的增大,分类器的支持向量越多越分散,说明数据映射到新特征空间后的分布也越复杂,从而使目标决策函数越复杂,影响分类器的分类效果。因此可以通过选择不同的gamma参数值来观测分类器的效果,逐步优化gamma参数,最终选择出最优值。
4 结束语
用公共数据库中的数据集作为训练样例和测试样例,对设计的基于SVM算法的分类器进行了实验,研究了SVM算法中主要参数c和gamma的物理意义。从实验结果可看出,在将SVM算法应用于数据分类时,参数c和gamma对结果的影响仍不容忽视,因此在应用时,应选择合适的参数c和gamma类优化分类效果。
[1] Tom M Mitchell.机器学习[M].曾华军,张银奎,译.北京:机械工业出版社,2003.
[2] Crist Anne.支持向量机导论[M].李国正,王猛,曾华军,译.北京:电子工业出版社,2004.
[3] Chih-wei Hsu,Chang Chihchung,Lin Chih Jen.A practical guide to support vector classification[M].Korea:Seoul University,2010.
[4] 徐义田.基于SVM的分类算法与聚类分析[J].烟台大学学报,2004,17(1):9-13.
[5] 杨铁建.基于支持向量机的数据挖掘技术研究[D].西安:西安电子科技大学,2005.
[6] 魏蕾,何东健,乔永亮.基于图像处理和SVM的植物叶片分类研究[J].农机化研究,2013(5):12-17.
[7] 徐金明,张孟喜,丁涛.Matlab实用教程[M].北京:清华大学出版社,2008.
Design of a Classifier Based on the SVM Algorithm
WEI Ao
(School of Electronic Engineering,Xidian University,Xi’an 710071,China)
The basic idea of the Support Vector Machine(SVM) algorithm and the concept of data classification is introduced.An analysis of the traditional SVM general characteristics is also made.A classifier based on the SVM algorithm is designed with Libsvm toolbox,and is tested by data set from public databases.The paper focuses on the selection of training samples,as well as the effect and optimization of parameters.The experimental results show that suitable training samples and parameters help to improve the accuracy of the classifier.
SVM;Libsvm toolbox;classifier
2014- 08- 27
危傲(1989—),男,硕士研究生。研究方向:SVM机器学习。E-mail:barry_weiao@hotmail.com
10.16180/j.cnki.issn1007-7820.2015.04.007
TP
A
猜你喜欢
数学物理学报(2022年4期)2022-08-22 04:08:00
新高考·高一数学(2022年3期)2022-04-28 07:02:46
中学生数理化·高一版(2021年2期)2021-03-19 08:32:06
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
中央民族大学学报(自然科学版)(2018年3期)2018-11-09 01:16:34
电子测试(2018年1期)2018-04-18 11:52:35
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
新高考·高二数学(2015年11期)2015-12-23 18:17:44
