
可追踪供应链中非确定性RFID数据处理方法
2015-10-10 07:53谢东肖杰郭广军江彤
中南大学学报(自然科学版) 2015年5期
谢东,肖杰,郭广军,江彤
可追踪供应链中非确定性RFID数据处理方法
谢东1, 2,肖杰3,郭广军4,江彤1
(1. 湖南人文科技学院计算机科学技术系,湖南娄底,417000;2. 中南大学信息科学与工程学院, 湖南长沙,410083;3. 湖南第一师范信息技术系,湖南长沙,410205;4. 娄底职业技术学院电子信息工程系, 湖南娄底,417000)
针对可追踪供应链应用系统中大量非确定性RFID数据不能被有效处理的问题,通过分析RFID应用的关键特征,根据非确定性数据的比例来调整滑动窗口,采用不同策略处理不同类型的非确定性数据,提出可处理各种类型非确定性数据的清洗方法;根据对象在供应链中出现的位置及其连续性来区分多读、漏读和不完整数据,基于对象在物流节点中移动路径对应的有向图进一步提出可适应对象分组和独立移动的处理算法。研究结果表明:提出的方法具有良好的清洗效果、存储效率以及查询性能,在不同参数条件下能有效地支持对象路径查询。
供应链;无线射频识别;非确定性数据
无线射频识别(RFID)技术[1]是对物体贴上具有唯一标示符的电子产品标签(electronic product code,EPC),再进行无线识别的方法,能自动被RFID阅读器识别并生成大量数据,被广泛应用于供应链管理(supply chain management, SCM)中[1]。RFID应用跨越多个企业来获取RFID对象的属性和位置数据,根据对象在不同时期的位置信息(数据血统)来追踪其历史轨迹和位置。尽管大多数RFID数据是精确的,但由于RFID阅读方位感知的敏感、干扰、阅读部件故障和一些环境因素,RFID原始数据往往是不完整、不精确甚至是错误的。非确定性RFID数据类型一般包括:1) 由于阅读角度、信号闭塞、信号盲区等因素,难以获取对象确定位置导致漏读数据;2) 由于不同的RFID阅读器可能存在交叉的阅读区域,同一个RFID对象可能被不同的RFID阅读器读取,从而具有不同位置的非一致性数据;3) 阅读器在阅读区域可能获取不存在的信号,这种信号被识别为并不存在的RFID对象,导致多读数据;4) 有源的RFID阅读器可能在不同时间间隔内频繁地读取没有移动的RFID对象,从而产生具有不同时间戳但具有相同位置信息的冗余数据;5)非完整数据表现为RFID对象数据没有出现在供应链中的某些位置,主要原因为假货在某个供应链节点进入供应链或RFID对象被偷。以上这些问题导致用户查询难以直接在非确定性RFID数据上进行操作。由于传统的ER模型难以表达RFID数据的时序性,Wang等[2]提出了DRER模型,将RFID数据分为基于事件和基于状态2种类型,并进一步考虑了移动阅读器,细化了应用场景并建模[3]。然而,这些工作涉及多个相关位置的路径查询,需要对存储数据进行多次自连接,导致效率较低,且没有考虑非确定性数据。基于时间平滑的策略[4]通过静态窗口来填补漏读数据,但无法根据数据的实时特性去灵活调整窗口大小。Jeffery等[5]提出了一种自适应时空平滑过滤器,但填补效果较差。谷峪等[6]通过监控物体所在小组的动态分析来实现数据清洗,但需要先进行数据清洗才能被RFID应用使用。粒子滤波[7]从能直接观测的明显状态(如RFID阅读器的位置)推测不能直接观测的隐藏状态(如物流对象位置),但重采样阶段会损失样本的有效性和多样性,导致定位不准。文献[8]和[9]分别采用高斯混合分布和时变的图模型来获取数据的非确定性,但在移动手持机环境下,仍然定位不准。上述方法均只针对漏读,未考虑不一致数据。基于可能世界语义的非确定性数据管理[10]。PCQA语义[11]建立非一致性数据[12]的所有可能世界语义和所有可能一致性的子集,但假定数据是独立的。谢东[14]在可能世界语义基础上发展了一种可扩展的非确定性数据处理平台,在高层应用上能直接对非确定性数据进行处理,但这些方法都没有考虑漏读数据。以上工作均没有考虑所有类型的非确定性数据,在这些数据形成的海量可能世界实例上难以有效地进行涉及多个相关位置的路径追踪。本文作者考虑所有类型的非确定性数据,在基于一阶逻辑的非一致性数据处理方法[15]和非确定性RFID数据模型[16]等工作基础上,通过分析RFID对象的关键特征,提出一种非确定性数据处理方法,根据漏读与多读、冗余和非一致性数据的比例来调整滑动窗口,采用不同策略处理漏读、多读、冗余、非一致性和非完整性(假货与对象被偷)数据,并根据对象在供应链中出现位置及其连续性来识别多读、漏读和非完整数据;通过建立表达对象路径的有向图,进一步提出可适应对象分组和独立移动的处理算法,处理后的数据在不同参数条件下能有效地支持包括跟踪、追踪、聚集、循环和长路径等对象路径查询。
1 非确定性RFID数据的处理方法
1.1 基于RFID的供应链
基于RFID的供应链流程如图1所示。其中,可能是一个多读数据,但并不存在;被重复读取,在没有改变位置的情况下将生成冗余数据;被漏读,需要根据相关信息来推断它的位置;被2个阅读器同时读取,具有2个不同的位置;假货在供应链中游加入;在仓库被偷;特别地,多读、假货与对象被偷类似,都不存在于供应链的某些位置。

图1 基于RFID的供应链
RFID应用是类似的,具有非确定性、不同位置的时序相关性、相同位置的对象相关性和粗粒度。基于这些特点,本文给出了如下定义。
定义1 RFID阅读。RFID阅读是一个具有唯一EPC的RFID对象tagID在timestamp时间点被阅读器读取,表示为rd=(tagID, timestamp,readerID)。
定义2 RFID数据流。RFID数据流是多个具有唯一EPC的RFID对象tagID在timestamp时间点被readerID阅读器读取,表示为=(rd, rd, …, rd),其中rd=(tagID, timestamp, readerID)。
本文总结了几类基本实体:具有唯一EPC的RFID对象、阅读器和位置。这些实体产生的数据分为部署数据、阅读数据和概略数据。部署数据在RFID应用部署时就被获取,这些数据相对稳定、确定,如位置和阅读器数据等;阅读数据为RFID阅读器读取的数据;概略数据为通过处理阅读数据后生成的面向用户查询的数据。
1.2 处理框架
图2所示为非确定性RFID数据的处理框架。RFID阅读器从多个数据流读取EPC数据,根据已存在阅读数据的非确定性比例来指定一个滑动窗口;然后根据已有的阅读数据推断读取的数据是否存在漏读数据,存储RFID对象的EPC、位置和时间戳到RFID数据库中(其中,非一致性、多读和冗余数据也需要被存储到RFID数据库中),并进一步修改非一致性数据,清洗多读和冗余数据。

图2 非确定性RFID数据处理框架
滑动窗口显著地影响冗余、非一致性、多读和漏读数据的比例。若选择大的窗口,则能获取RFID对象更多的信息,但容易导致更多的冗余、非一致性和多读数据产生;若选择小的窗口,则可以减少冗余、非一致性和多读数据的产生,但容易产生更多的漏读数据。SMURF[5]难以有效地确定一个自适应的窗口,本文提出1个滑动窗口策略去调整冗余、非一致性、多读和漏读数据的比例。
不同比例下的滑动窗口如图3所示。当漏读频繁发生时(从1到2),Stream A趋向于有1个更大的窗口;而当冗余、非一致性和多读现象频繁发生时(从2到3),Stream C趋向于有1个更小的窗口;Stream B是相对适中的,趋向于平衡2类阅读。根据漏读比例,小窗口需要适当放大。根据冗余、非一致性和多读比例,大窗口需要适当减小。采用如下公式调整滑动窗口:
1.3 数据推断
阅读数据(,) 一般可生成反映RFID对象状态的存储形式(,,in,out),其中[in,out]表示EPC在位置的停留时间。不同非确定性数据处理的推断规则如下:
定义3 推断规则(INFERRING RULE)被采用模式(PATTERN)-条件(CONDITION)-操作(ACTION)形式:
其中:为非确定性数据类型;为该类型属于何种具体情况;为执行的推断操作。
推断不同类型的非确定性数据如图4所示。
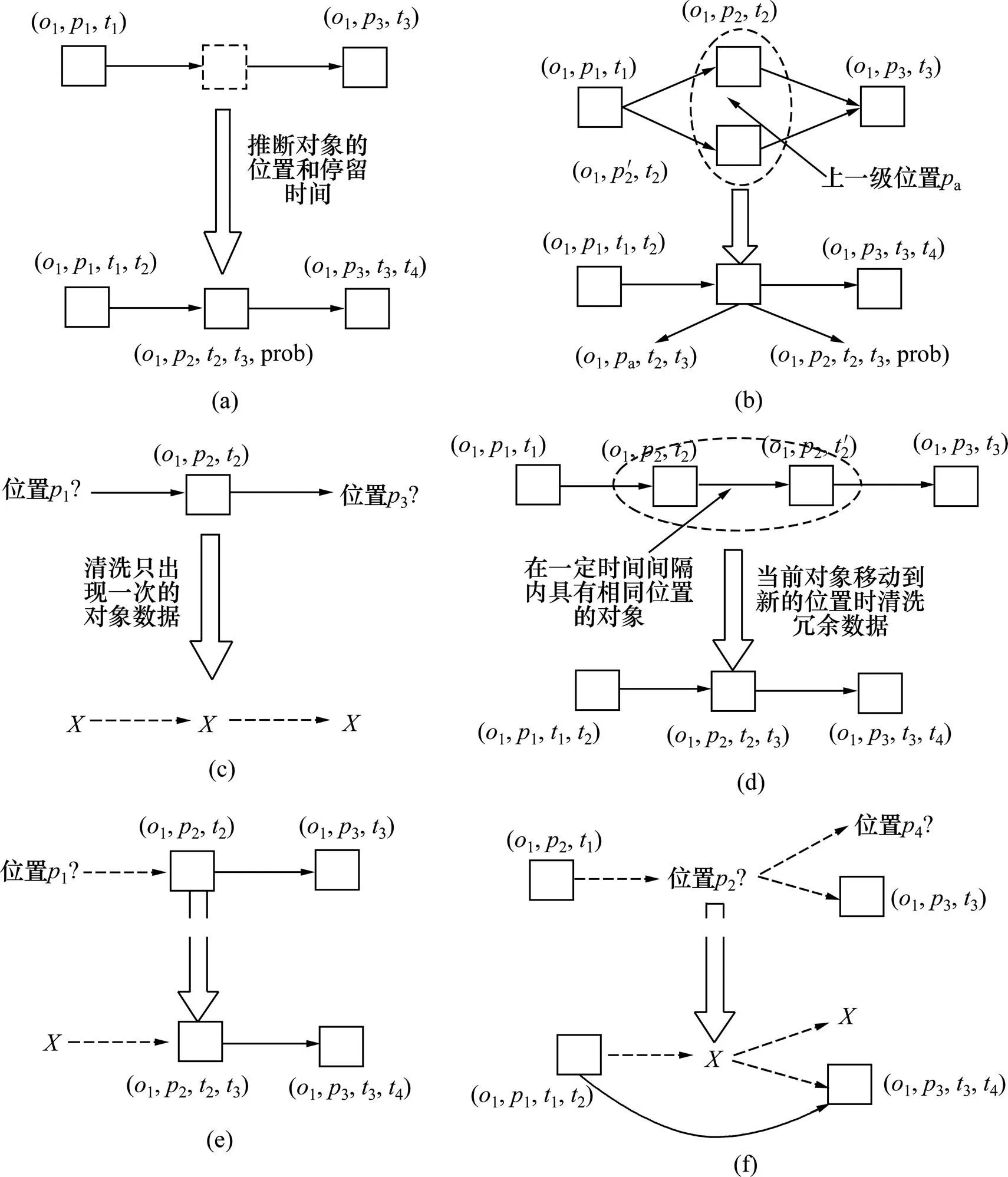
(a) 漏读数据;(b) 非一致性数据;(c) 多读数据;(d) 冗余数据;(e) 非完整性数据(假设);(f) 非完整性数据(对象被偷)
1) 漏读数据。对象1通过位置1,2和3,但在位置2时未检测到。可以根据RFID对象的移动历史和位置关系来推断,若与对象1一起的其他RFID对象从位置1到3必须通过位置2,则可以推断对象1也通过了位置2,并获得在位置2的停留时间及概率,如(1,2,2,3,)。
2) 非一致性数据。对象1从1到3,可能被2个不同的阅读器读取,从而形成具有2个不同位置2和′2的非一致性数据。可以采用2种方法推断:一种是类似于漏读数据的推断,根据RFID对象的移动历史和位置关系来推断,如(1,p,2,3,);另一种是根据RFID应用的粗粒度特点,把包含2个不同位置2和2的上一级位置a代替当前非一致性位置,如 (1,a,2,3)。
3) 多读数据。不存在的对象1在位置2被读取,且1也不会在其他位置出现,可以表示为->->。但如果一个RFID对象在离开生产线后马上被偷,由于被偷RFID对象也与多读数据一样都只出现1次,那么可能被误认为是多读数据,因此,需要进一步区分。多读数据需要被定期清洗。
4) 冗余数据。位置没有改变的RFID对象在不同的时间间隔内被读取,如对象1在时间戳2和′2上被读取2次。由于1可能在下一个位置被漏读,推断其漏读位置需要最近的位置信息,因此,需要保存最近的位置信息,直到对象1到达新的位置为止。
5) 非完整性数据(假货)。假货在供应链中下游混入正常的产品中,但假货不会出现在生产线上。如假货1出现在位置2和3,但1没有在位置1出现,表示为->2->3。在供应链中只出现1次的假货没有意义,假货进入零售商上游就必须被读取2次,而直接进入零售商则不需要贴EPC。由于假货实际存在,出现2次以上假货数据不会被清洗,此外,克隆假货的EPC可能出现在生产线上,因此,克隆假货和正品可能同时出现在供应链中或者不同时出现,该EPC可能形成2条历史轨迹,克隆假货形成的历史轨迹在位置上往往不连续。
6) 非完整性数据(对象被偷)。图4(f)显示RFID对象在某一位置被偷,被偷对象可能重新进入该供应链,也可能永远丢失。如对象1出现在位置1,但对象1在位置2被偷,因此,对象1在位置2没有被读取,1的轨迹可以表示为1->->(永远丢失),或者重新在位置3进入,表示为1->->3。
1.4 多读、漏读和非完整性数据的区分
由于多读、漏读和非完整性数据都是在供应链中某些节点缺乏位置信息,而它们的处理方法不同,因此,需要区分这些数据。这些数据难以在阅读器读取时就立即区分。例如,对象1出现在位置1,对象1可能是多读或者假货。
图5所示为多读、漏读和非完整性数据在供应链中可能出现的位置。漏读数据可能出现在除生产线的任何位置;假货只出现了供应链的中下游,不可能进入生产线,假货也不会直接进入零售商,否则假货无需贴上EPC,可直接销售给消费者;RFID对象不可能在生产线上被偷,若被偷则一定发生在被贴签之前,对象被偷可能发生在除生产线上的其他位置,也可能被偷后重新进入供应链;多读数据可能发生在供应链的任意位置,在生产线上的非确定性数据只可能存在多读数据。

图5 多读、漏读和非完整性数据在供应链中出现的位置
图6所示为多读、漏读和非完整性数据的3种情况。
1) 情况A显示1个阅读数据只出现生产线上,这可能是多读或者对象在离开生产线后马上被偷。由于RFID对象在生产线写入产品参数,因此,可以推断多读数据没有相关参数,而被偷数据有相关参数。
2) 情况B显示普通假货的EPC在生产线上没有信息,而克隆假货在生产线上有相关信息,但缺乏连续位置信息。这是因为RFID对象在供应链中移动是连续的,具有相邻的连续位置信息,而克隆假货是突然出现在供应链中,因而缺乏相邻的连续位置信息。
3) 情况C显示RFID对象出现超过1次,但没有出现在某些位置。这可能是因为RFID对象在某些位置被漏读或者被偷的RFID对象重新进入供应链。漏读的RFID对象一般消失在离散的位置,而被偷的RFID对象一般消失在连续的位置,且被偷的RFID对象将脱离原来的分组。因此,可以通过位置的连续性和分组情况来区分这2类情况。
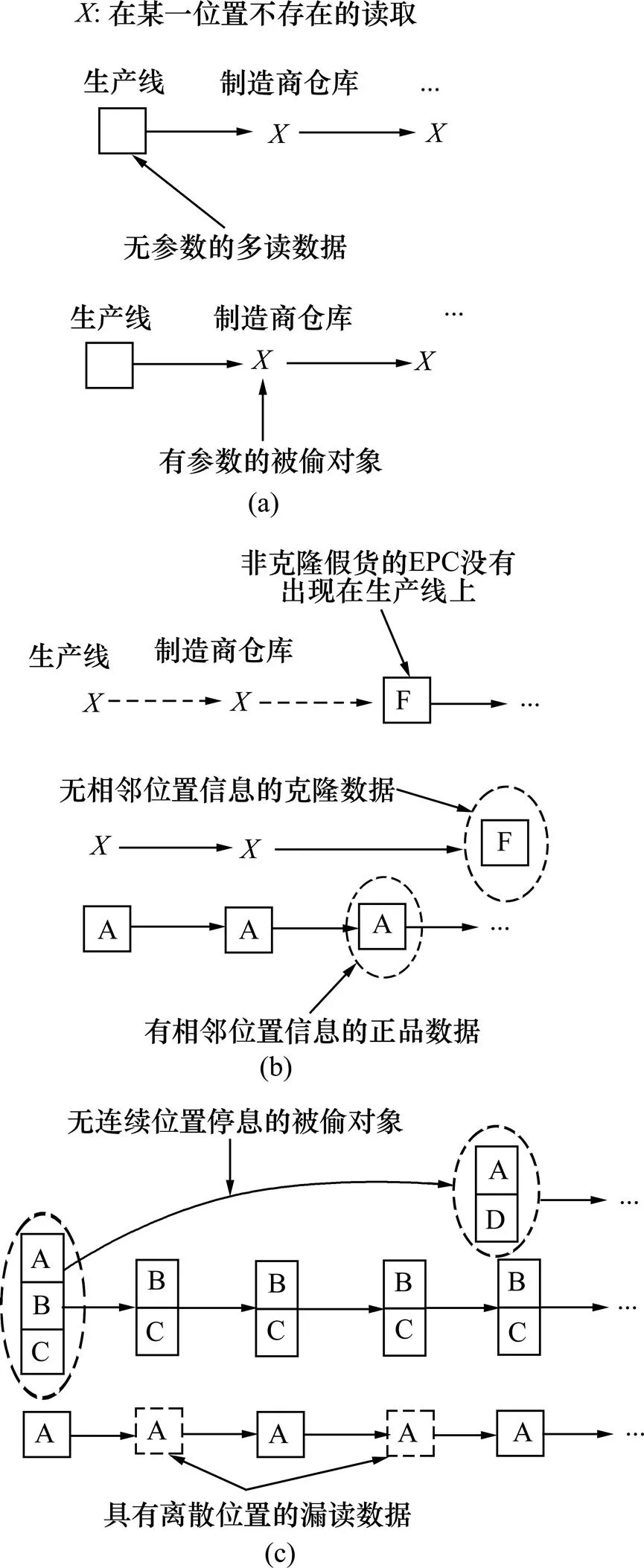
(a) 情况A;(b) 情况B;(c) 情况C
1.5 数据模型
本文采用如下的模型存储非确定性数据(图7)。在部署数据中,(,,)存储阅读器的EPC、名字和所有者;(,)存储RFID对象的EPC和类型;(,,)存储位置ID、名字、上一级位置ID;(,)存储业务类型。在阅读数据中,(,)通过和生成,存储RFID对象的原始数据;为了区分非确定性数据,非克隆假货、克隆假货、被偷对象与正常对象的值分别为2, 1, 0和NULL。在概要数据中,(,in,out,,)存储阅读器在一定时间间隔内的业务活动;(,)存储路径序列;(,in,out)存储在一定时间间隔内的位置;()存储对象的路径序列。
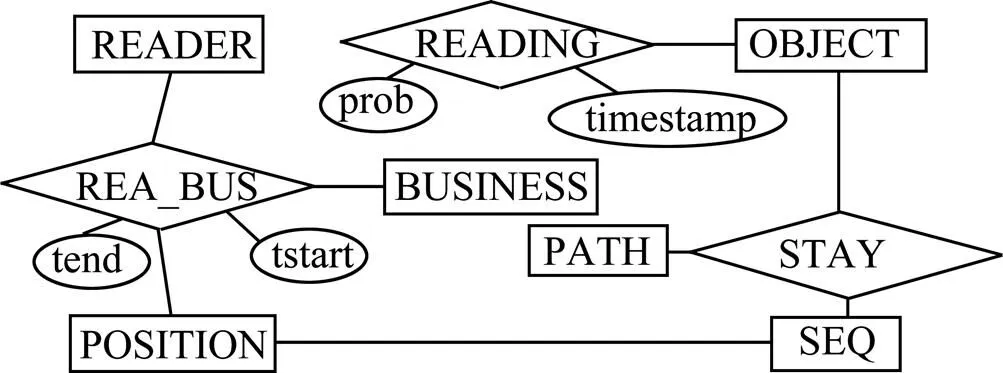
图7 数据模型
1.6 算法
基于提出的框架和规则,本文提出了基于有向图(定义1)的非确定性数据处理算法。
定义4 一个从上游到下游的供应链可表示为有向图<,,>,其中表示为的物流节点,表示为一对物流节点<,>之间的对象移动,表示为对象移动的权重。根节点为对象的制造商,每个节点是其前驱节点的子节点,也是其后续节点的父节点。
图8中的有向图显示边<12>和<13>的权重分别为1和2,表示从1到2和从1到3的概率(即出现漏读和非一致性数据的可能性),概率为前驱节点出发经过该有向边的历史移动对象与该前驱节点出发的总历史移动对象的比例。
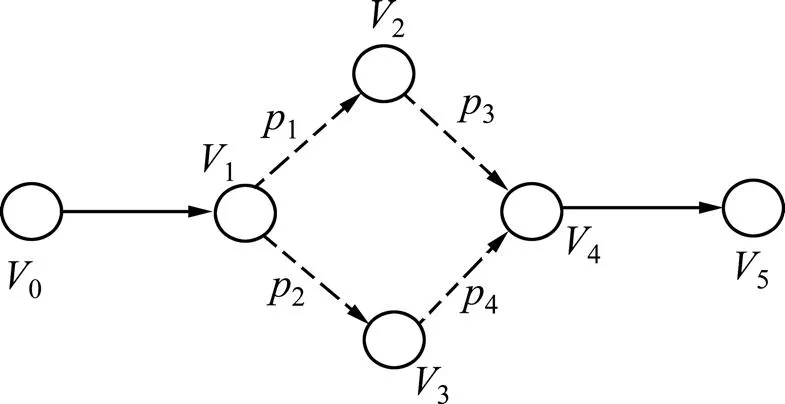
图8 表示对象移动的有向图
根据图4(a)和4(f),算法1处理多读、冗余、非完整性、漏读和非一致性数据,调用算法2,建立有向图和路径序列。算法1再根据阅读器出现的位置,对清洗多读和冗余数据,并标记假货和被偷对象的数据;根据有向图中从父节点到子节点的路径权重,在给定阈值条件下标记和处理漏读和非一致性数据,插入漏读数据到或者通过聚集更高层次的时间间隔和位置修改非一致性数据;最后,计算滑动窗口尺寸。
算法1首先调用算法2,由于中的元组数等于中的元组数,算法2在第1步开始的循环次数为,因此,算法2的时间复杂度为()。在第3步开始的外循环次数为,在第17和24步开始的内循环次数均为路径长度(3~22)。由于内循环EPC不可能同时满足第17和24步开始的2个条件,因此,第3步开始的循环的时间复杂度为(),最后得到算法的时间复杂度为((+1))。
算法1 main
Input:;阈值;用户可接受的非确定性数据的比例;可调整的时间间隔;非确定性数据比例的调整参数和
Output: 清洗多读和冗余数据;标记非完整性数据;修改漏读和非一致性数据;滑动窗口尺寸w
Begin
1. Builddirectedgraph (EPC);
2. ra ← 0;t ← READING元组数;
3. For RADING中EPC do
4. If EPC 在节点上只出现一次
5. 删除多读数据;
6. Else if EPC在同一节点出现2次以上
7. 删除所有时间戳较晚的冗余数据;
8. Else if EPC没有出现在根节点
9. 区分EPC为非克隆假货;
10. Else if EPC出现在根节点且有完整路径,但路径的相邻节点不连续
11. 区分EPC为非克隆假货;
12. Else if EPC出现在根节点但没有出现在后续节点
13. 区分EPC为被偷对象;
14. Else if EPC 没有出现在某一节点
15. ra ++;
16. 区分EPC为漏读数据;
17. For i =1 to 路径长度l do
18. {W ← 第i个漏读节点路径的权重;
19. If W ≥ TV
20. STAY ← EPC的漏读节点;
21. Else 通过聚集上级AT和AP修改EPC在STAY的模糊路径节点位;}
22. Else if EPC在同一时间出现在2个位置
23. 区分EPC为非一致性数据;
24. For i ← 1 to 路径长度l do
25. {W ← 第i个非一致性节点路径的权重;
26. If W ≥ TV
27. 修改EPC的非一致性节点到STAY;
28. Else通过聚集上级AT和AP修改EPC在STAY的非一致性路径节点位;}
29. }
30. ra2 ← ra/t;
31. ra1 ← 1 – 已清洗的READING元组数/t - ra2 ;
32. sw ← adj*(m*(acra–ra1)–n*(acra–ra2)) ;
End
算法2 Builddirectedgraph
Input: EPC
Output: 有向图;SEQ
Begin
For i ← 1 to STAY中的元组数do
{parent ← EPC的根节点;
node = EPC在parent的子节点;
If node is NULL then
{node ← new node;
node.loc ← EPC.loc;
node.tin ← EPC.tin;
node.tout ← EPC.tout;
parent的子节点 ← node;
}
加入node.path到PATH;
W ← parent到node边的权重;
W ← PATH;
}
End
2 实验评价
2.1 实验环境
本文考虑了所有类型的非确定性数据,与以往工作的实验数据不可能一致,因此,无法将本文方法与以往方法进行比较。
实验评价环境中采用CPU为Core i2 2.00 GHz,内存为2 Gb RAM的机器,操作系统为Windows 7,数据库为MYSQL5.6。由于缺乏通用的RFID测试数据,本文根据1个食品物流模型[17]生成数据,并建立相应的查询进行测试。
对象被生成在进口市场和农产品供应商等根节点,再通过分组或个别运输形式移动到下一个位置。采用有向图并考虑分组因素去生成对象数据,分析分组因素对查询性能的影响。有向图的每个节点表示某一位置的一组对象,边表示对象在位置之间的移动。一般地,靠近根节点的对象移动往往是更大的组,靠近叶子的对象移动往往是更小的组。分组的尺寸表示为,表示为一起移动的对象数量。本文根据有向图中给定的随机地生成数据,对应有向图中的边,表示对象移动。
由于非确定性数据大部分是漏读数据,考虑如下影响因素:漏读、冗余和多读数据比例,用户指定的位置和时间间隔层次(基于这2个层次的路径序列将自动聚集),不同数据规模,实验参数见表1。

表1 实验参数
2.2 数据处理
根据不同参数比较清洗后的存储规模。设置漏读数据比例=(0.500, 0.250, 0.100, 0.500, 0.025),冗余和多读数据比例分别为G=(0, 0.333, 0.500, 0.666, 0.750),对象数量分别为1 000,2 500,5 000,7 500,10 000的数据规模为=(3 800, 31 700, 135 000, 427 500, 975 000)。本文在表中清洗冗余和多读数据,计算漏读数据且存入该表,也标注假货和被偷对象等非完整性数据,并修改非一致性数据。
由于漏读数据比例与冗余和多读数据比例是对立的,因此,采用5组数据比例来表示,组1为(=0.5,G=0),组2为(=0.25,G=0.333),组3为(=0.1,G=0.5),组4为(=0.05,G=0.666),组5为(=0.025,G=0.75)。漏读数据比例从0.500 下降为0.025,冗余和多读数据比例从0 提高为0.75。由图9可知:没有清洗过的数据在不同和G下呈线性增长。由于漏读数据被推断计算后插入,而冗余和多读数据在被清洗,被清洗的数据规模在不同和G下是相同的。更高的G可能显著地增加尺寸。但更小的G可能导致更多的漏读,而影响漏读推断准确率。因此,根据滑动窗口调整G为更小值,且调整为合适的值。
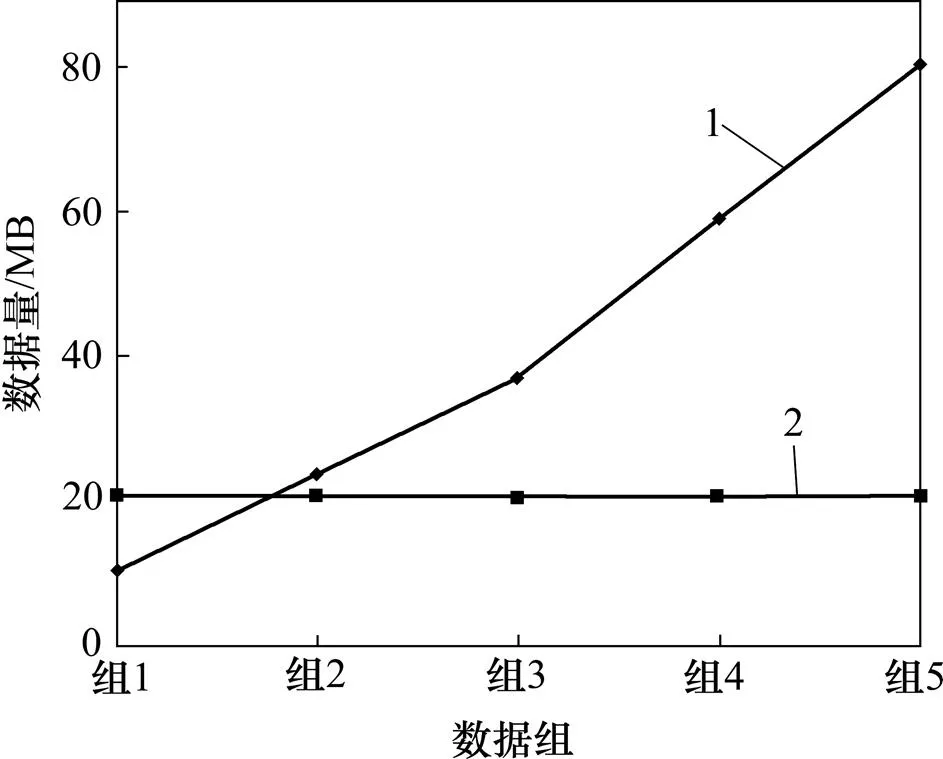
1—未清洗数据;2—清洗数据
图10所示为不同的数据规模,参数为=0.1,G=0.5。根据对象数量(1 000,2 500,5 000,7 500,10 000)分别生成数据进入表,对应的路径长度分别为(3−4),(3−7),(3−9),(3−17),(3−22) (每500个对象有相同的路径长度)。由于G=0.5和长路径可能导致更多的冗余数据,没有清洗过的数据规模明显地大于被清洗过的数据规模。生成的数据将进入表,和。由于表只存储单一对象对应元组的一系列完整路径序列(一一对应中的对象),表只存储在2个可调整的时间间隔的位置,表只存储基于有向图的有限路径,因此,用户可以通过查询更小尺寸的表,有效地获取对象的完整路径。
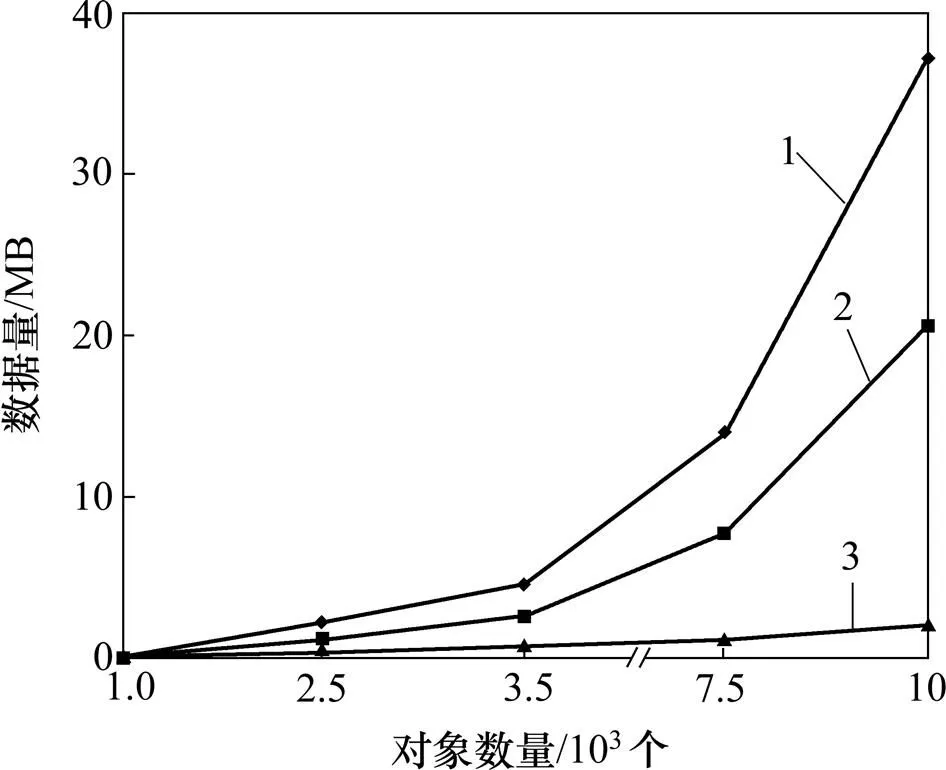
1—未清洗数据;2—清洗数据;3—路径数据
文献[17]给出的最小路径为3,最大路径为9。考虑循环和长路径问题,延长了最大路径长度到17或22。一般地,大多数路径长度为3~9,特别是3~6。本文设置5个系列的路径长度:3~4(每5 000个对象有相同路径长度);3~7(每2 000个对象有相同路径长度);3~9(每1 500个对象有相同路径长度,第9层为1 000个对象有相同路径长度);3~17(从第3层到第9层每1 300个对象有相同路径长度,从第10层到第17层每90个对象有相同路径长度);3~22(从第3层到第9层每1 300个对象有相同路径长度,从第10层到第22层每90个对象有相同路径长度)。不同的数据规模(=10 000,=3 600,A=3,=0.1,G=0.5)如图11所示。由图11可知:没有清洗的和清洗过的数据规模在路径长度增加时显著增加,而路径数据规模随路径长度增加稍微增长。表明更长的路径会显著地影响数据规模,但对路径数据规模影响不大。
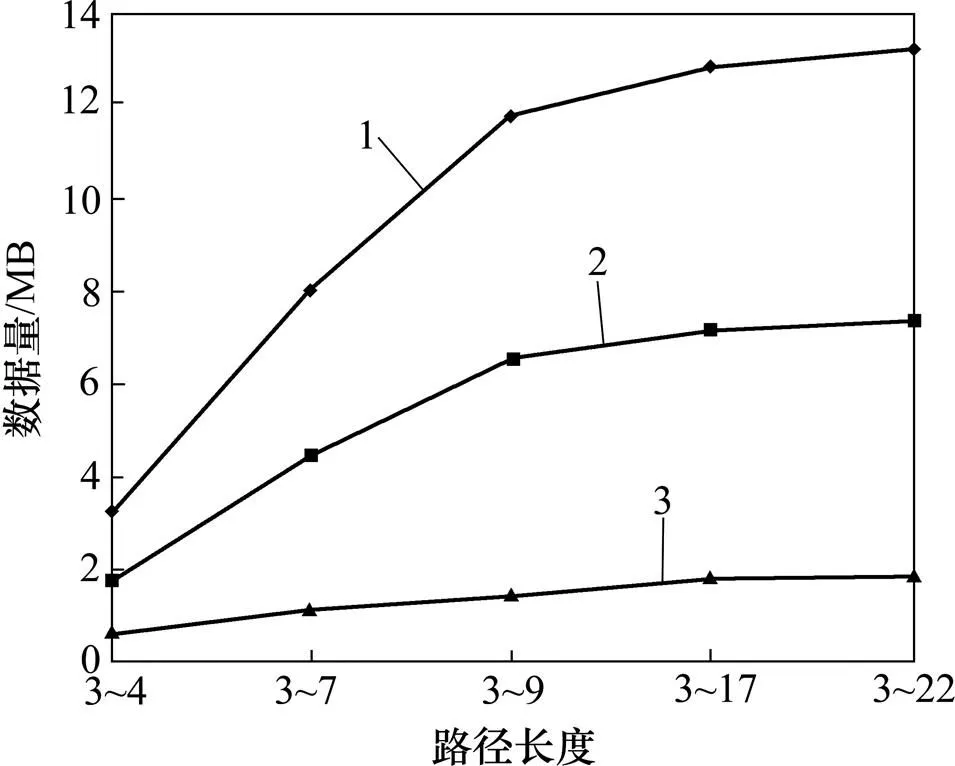
1—未清洗数据;2—清洗数据;3—路径数据
考虑到对象在很短的时间内不可能从一个位置移动到另一个较远的位置,因此,每一个位置将对应一个合适的时间间隔,如时间间隔=60对应于位置间隔A=2。不同的和的数据规模(=10 000,=3−22,=0.1,G=0.5)如图12所示。由图12可知:路径数据规模随和A的增加而减少(被清洗数据的规模不随和A的改变而改变)。路径数据规模的减少对降低路径查询的负载是非常有效的。
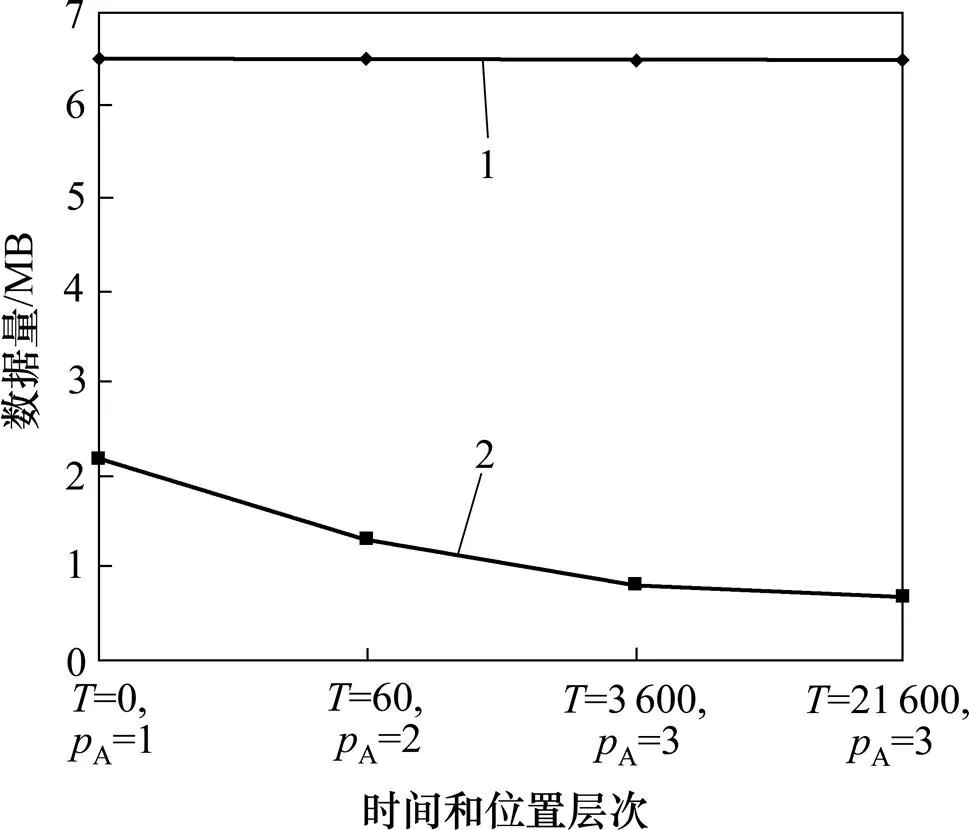
1—未清洗数据;2—清洗数据
2.3 查询
由于没有清洗过的数据不适合于进行查询评价,本文采用算法清洗数据和聚集,并给定查询进行比较。Q1为跟踪查询,Q2,Q3,Q6和Q7为追踪查询。其中Q4和Q5为聚集查询,Q6为非完整性数据查询,Q7为循环和长路径查询。
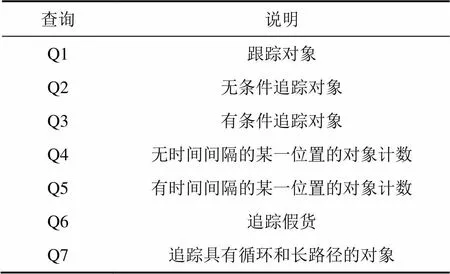
表2 测试查询
在表中存储对象EPC及其路径序列,Q1和Q2不需要连接多个表去获取路径信息。尽管Q3需要连接2个表去获取路径信息,但存储时间间隔和位置信息的表已经被显著地压缩。聚集查询Q4和Q5需要连接2个表,但相当多的类似数据也通过聚集压缩,也能显著地改善查询性能。由于查询假货涉及到表,和,Q6连接这3个表区分非克隆假货和克隆假货。循环和长路径查询也涉及表,和,Q7需要连接这3个表获取细节的路径信息。
不同分组的执行情况如图13所示,参数为= 10 000,=3−22,=3 600,A=3。由图13可知:方法在Q3~Q7的执行时间随着分组的增加而减少。这是因为Q1和Q2只需要查询表获取路径信息,因而Q1和Q2的执行时间没有改变。Q3的执行时间随的增加而减少,这是因为更大的分组可以显著地压缩以获取路径信息。尽管Q4和Q5需要连接2个表进行聚集,随着的增加,在参数=3 600和A=3条件下的压缩比也显著地增加。类似地,Q6和Q7需要连接3个表(,和)去追踪假货和具有循环和长路径的对象,压缩比随着的增加而增加。
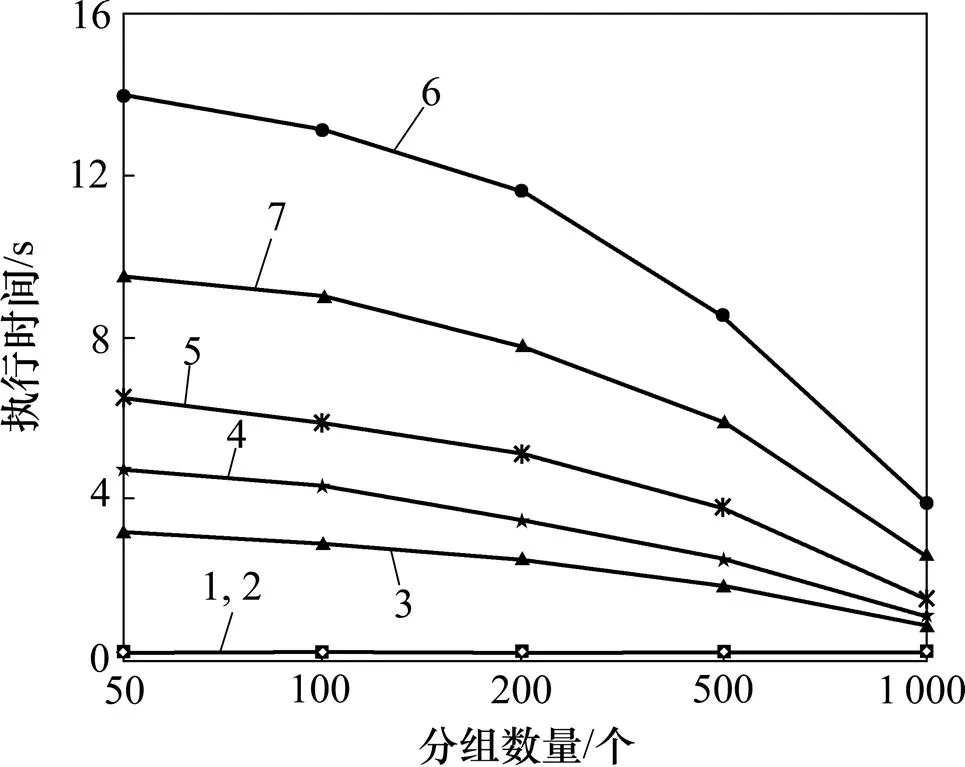
1—Q1;2—Q2;3—Q3;4—Q4;5—Q5;6—Q6;7—Q7
Q1~Q7在不同数据规模时的评价如图14所示,测试参数=200,=3~22,=3 600,A=3。数据规模显著地影响Q3~Q7的执行时间。由于Q3~Q7需要连接多个表,其执行时间随的增加而显著增加。而Q1和Q2只查询表,数据规模的变化对其执行时间影响很小。

1—Q1;2—Q2;3—Q3;4—Q4;5—Q5;6—Q6;7—Q7
由于RFID阅读器是在连续的时间段内而不是相同的时间戳读取对象标签,聚集时间间隔和位置,忽略了具体的时间戳和位置,可以显著地改善存储和查询的有效性。图15所示为在不同聚集层次下的查询执行时间。本文设置4组不同的聚集层次:Ⅰ组(=0,A=1),Ⅱ组(=60,A=2),Ⅲ组(=3 600,A=3),Ⅳ组(=21 600,A=4),由这4组聚集层次评价查询Q1~Q7。其中,Ⅰ组(=0,A=1)是没有聚集的,因而对Q3~Q7是无效的。随着聚集时间间隔和位置间隔的延长,Q3~Q7的执行时间显著减少。

1—Q1;2—Q2;3—Q3;4—Q4;5—Q5;6—Q6;7—Q7
一般的路径长度为3−9[17],因此,考虑大部分对象的路径长度为3−9,设置了4组不同的路径长度1=3~5,2=3~9,3=3~17,4=3~22来评价Q1~Q7。若路径长度超过9,则实验设置10%的对象的路径长度为10~22 (每个长度的对象数量相对平均),设置90%的对象的路径长度为3~9(每个长度的对象数量相对平均)。图16所示为Q3~Q7在不同路径长度的执行时间。由图16可见:Q3~Q7的执行时间随着路径长度的增加而显著增加。这是因为短路径包含大量可以被压缩的相同路径信息,而长路径包含大量难以压缩的不同路径信息。由于具有路径长度10~22的对象较少,执行时间的增幅趋缓。
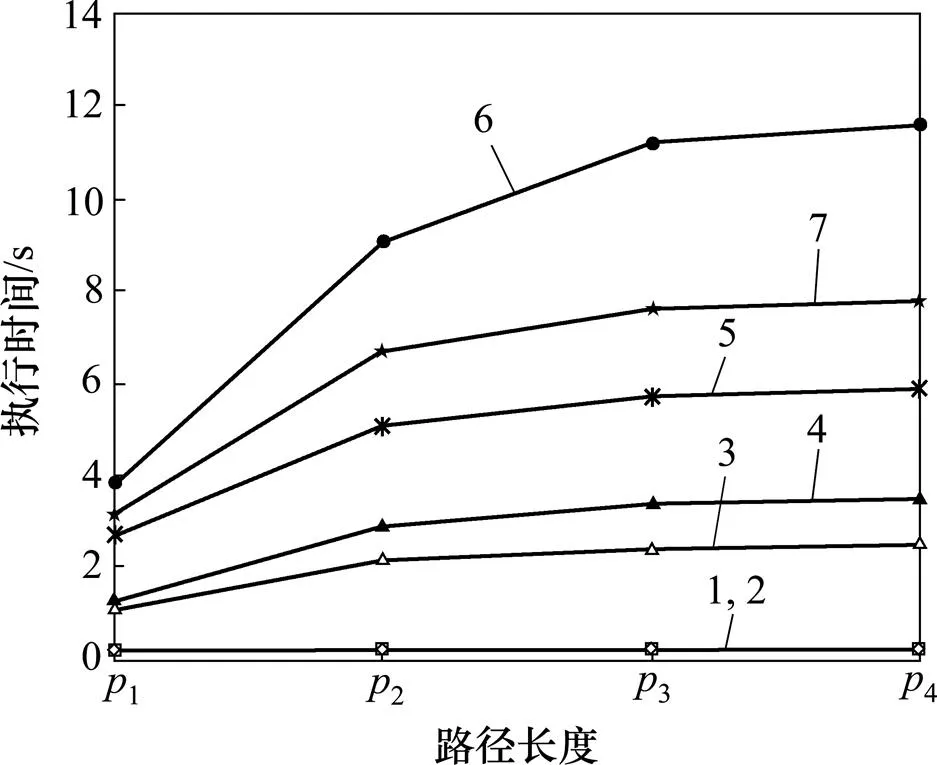
1—Q1;2—Q2;3—Q3;4—Q4;5—Q5;6—Q6;7—Q7
在以上实验中,Q6和Q7的执行时间较长,但由于这2类查询相对较少,因此,查询性能也是可以接受的。
3 结论
1) 考虑了所有类型的非确定性数据,通过分析RFID对象的关键特征,根据漏读与多读、冗余和非一致性数据的比例来调整滑动窗口;提出了一种非确定性数据处理方法,采用不同策略处理漏读、多读、冗余、非一致性和非完整性(假货与对象被偷)数据,并根据对象在供应链中出现位置及其连续性来识别多读、漏读和非完整数据。
2) 处理后的数据在不同参数条件下具有良好的清洗效果、存储效率以及查询性能,能有效地支持对象路径查询。
3) 下一步的工作将建立对象移动的主路径和子路径,进一步压缩数据来提高存储和查询性能。
[1] Ilic A, Andersen T, Michahelles F. Increasing supply-chain visibility with rule-based RFID data analysis[J]. IEEE Internet Computing, 2009, 13(1): 31−38.
[2] WANG Fusheng, LIU Shaorong. Temporal management of RFID data[C]// Proceedings of the International Conference on Very Large Data Bases. New York: Association for Computing Machinery, 2005: 1128−1139.
[3] WANG Fusheng, LIU Shaorong, LIU Peiya. A temporal RFID data model for querying physical objects[J]. Pervasive and Mobile Computing, 2010, 6(3): 382−397.
[4] Rizvi S, Jeffery S R, Krishnamurthy S, et al. Events on the edge[C]// Proceedings of the International Conference on Management of Data. New York: Association for Computing Machinery, 2005: 885−887.
[5] Jeffery S R, Garofalakis M, Franklin M J. Adaptive cleaning for RFID data streams[C]// Proceedings of the International Conference on Very Large Databases. New York: Association for Computing Machinery, 2006: 163−174.
[6] 谷峪, 于戈, 胡小龙, 等. 基于监控对象动态聚簇的高效RFID数据清洗模型[J]. 软件学报, 2010, 21(4): 632−643. GU Yu, YU Ge, HU Xiaolong, et al. Efficient RFID data cleaning model based on dynamic clusters of monitored objects[J]. Journal of Software, 2010, 21(4): 632−643.
[7] 王永利, 钱江波, 孙淑荣, 等. AMUR: 一种RFID数据不确定性的自适应度量算法[J]. 电子学报, 2011, 39(3): 579−584. WANG Yongli, QIAN Jiangbo, SUN Shurong, et al. AMUR: An adaptive measuring algorithm of underlying uncertainty for RFID data [J]. Acta Electronica Sinica, 2011, 39(3): 579−584.
[8] Tran T T L, Peng L P, DIAO Yalei, et al. CLARO: Modeling and processing uncertain data streams[J]. The VLDB Journal, 2012, 21 (5):651-676.
[9] NIE Yanming, Cocci R, ZHAO Cao, et al. SPIRE: Efficient data inference and compression over RFID streams[J]. IEEE Transactions on Knowledge and Data Engineering, 2012, 24(1): 141−155.
[10] ZHOU Aoying, JIN Cheqing, WANG Guoren, et al. A survey on the management of uncertain data[J]. Chinese Journal of Computers, 2009, 32(1): 1−16.
[11] LIAN Xiang, CHEN Lei, SONG Shaoxu. Consistent query answers in inconsistent probabilistic databases[C]// Proceedings of the International Conference on Management of Data. New York: Association for Computing Machinery, 2010: 303−314.
[12] Arenas M, Bertossi L, Chomicki J. Consistent query answers in inconsistent databases[C]// Proceedings of the Symposium on Principles of Database Systems, 1999: 68−79.
[13] Chen L, Tseng M, Lian X. Development of foundation models for internet of things[J]. Frontiers of Computer Science in China, 2010, 4(3): 376−385.
[14] 谢东. 非确定性关系数据处理研究[R]. 长沙: 中南大学信息科学与工程学院, 2010: 30−55. XIE Dong. Research on uncertain relational data processing[R]. Changsha: Central South University. School of Information Science and Engineering, 2010: 30−55.
[15] XIE Dong, CHEN Xinbo, ZHU Yan. Tackling polytype queries in inconsistent databases: theory and algorithm[J]. Journal of Software, 2012, 7(8): 1861−1866.
[16] XIE Dong, Sheng Q Z, MA Jian-gang. A temporal-based model of uncertain RFID data[C]// Proceedings of the International Conference on Computer Science & Education. New York: Association for Computing Machinery, 2012: 847−850.
[17] Bowersox D J, Closs D J. Logistical management[M]. New York: McGraw-Hill, 1996: 55−80.
Methods for processing uncertain RFID data in traceability supply chains
XIE Dong1, 2, XIAO Jie3, GUO Guangjun4, JIANG Tong1
(1. Department of Computer Science and Technology, Hunan University of Humanities, Science and Technology, Loudi 417000, China; 2. School of Information Science and Engineering, Central South University, Changsha 410083, China; 3. Information Technology Department, Hunan First Normal College, Changsha 410205, China;4. Department of Electronics and Information Engineering, Loudi Vocational and Technical College, Loudi 417000, China)
Considering that massive uncertain radio frequency identification (RFID) data cannot be efficiently processed in application systems of traceability supply chains, key features of RFID applications were analyzed, and different smoothing windows were adjusted according to different rates of uncertain data. Different types of uncertain readings were obtained by employing different strategies, and the methods for efficiently and effectively processing various types of uncertain data were put forward. The methods distinguish between ghost, missing and incomplete data according to their appearing positions and their continuities in supply chains. The processing algorithms that are suitable to group and independent moving of objects were proposed based on the directed graph, which corresponds to moving paths of
objects in logistics nodes. The results show that the proposed methods provide good cleaning effects, storage efficiencies, and query performances, and also efficiently support path-oriented queries of objects under different parameters.
supply chain management; radio frequency identification (RFID); uncertain data
10.11817/j.issn.1672-7207.2015.05.017
TP311
A
1672−7207(2015)05−1688−11
2014−05−14;
2014−07−20
湖南省自然科学基金资助项目(12JJ3057);湖南省重点建设学科(计算机应用技术)资助项目(2011−2015);湖南省科技计划项目(2013NK3090);湖南省教育厅科研基金资助项目(13A046) (Project(12JJ3057) supported by the Hunan Provincial Natural Science Foundation; Project(2011−2015) supported by the Construct Program of the Key Discipline “Computer Application Technology” in Hunan Province; Project(2013NK3090) supported by the Hunan Provincial Science and Technology Plan; Project(13A046) supported by the Research Foundation of Education Committee of Hunan Province)
谢东,博士,副教授,从事物联网与数据管理研究;E-mail: dong.xie@hotmail.com
(编辑 赵俊)
猜你喜欢
社会科学战线(2022年7期)2022-08-26
电子设计工程(2022年15期)2022-08-17
社会科学战线(2022年3期)2022-06-15
法律方法(2021年3期)2021-03-16
英语世界(2020年10期)2020-11-06
英语世界(2020年2期)2020-03-08
中华建设(2019年7期)2019-08-27
计算机应用(2017年8期)2017-10-21
瞭望东方周刊(2017年29期)2017-08-09
青年与社会(2016年18期)2016-10-25
