
基于Neo4j处理大数据中元数据溯源的研究
2015-09-28 06:11靳永超吴怀谷
现代计算机 2015年8期
靳永超,吴怀谷
(1.西华大学数学与计算机学院,成都 610039;2.成都大学信息科学与技术学院,成都 610106)
基于Neo4j处理大数据中元数据溯源的研究
靳永超1,2,吴怀谷2
(1.西华大学数学与计算机学院,成都610039;2.成都大学信息科学与技术学院,成都610106)
0 引言
随着信息技术的高速发展和大量数据以各种形式的出现,企业的需求也在不断地改变。如何构建一个随着需求改变而平滑变化的大数据平台,是大数据领域面临的一个重大考验。一个平台扩展N个应用,将是未来大数据平台扩展性的重要体现,传统的各种信息系统往往是通过文档来适应需求的变化,但是仅仅依靠文档还是远远不够的。所以在大数据平台中元数据管理将是其核心的一部分,成功的元数据管理系统必须把整个平台业务的工作流、数据流和信息流有效地管理起来,使得系统不依赖特定的开发人员[1],从而提高系统的扩展性和全局性。在大数据平台中,像数据模型、任务模型、需求模型等模型池的定时调度,以及ETL中大量的数据源定义、映射规则、转换规则、装载策略等这些元数据都需要一个完整的管理。一个项目,从数据源到最终目标表,多则达上百个ETL过程,少则也十几个。这些过程之间的依赖关系、出错控制以及恢复的流程处理,都需要一个追根溯源的功能,通过最终形态的数据结构,追溯到整个大数据处理中,元数据的更改历史记录。所以大数据的元数据管理系统如何设计已经关系到大数据平台能否高效推送数据变更,任务变更和大数据平台突破瓶颈能否进一步发展的问题。
1 大数据平台中的元数据
大数据处理中,尤其是大数据平台构建中,结构化数据、半结构化数据和非结构化在整个平台中迁移、转换和装载。例如像关系型数据向数据仓库Hive、HBase、HDFS之间转换,列族HBase数据库向Hive,分布式文件存储HDFS向Hive相互之间数据迁移,而传统的ETL只针对关系型数据库之间转换,根本满足不了现有的各种需求,在海量数据面前查询、统计、更新效率很低,异构数据源的管理的利用效率低。所以,针对大数据平台需求,必须设计一个满足各种结构数据之间相互迁移,异构数据源之间高效利用的元数据管理系统,并且能够对元数据进行追踪溯源和版本管理。
1.1构建大数据平台中元数据模型池
数据建模是一个发现数据元素、探寻面向数据的结构的过程,探索当前关联方式及定义方式来进行需求调用,而其建立的模型称为数据模型。数据模型可用于各种目的,从高层的概念数据模型到物理数据模型。从面向对象的角度来看,在概念上,数据模型是指采用“实体.关系”方法描述数据及其数据之间关系的模型,即指用实体、属性及其关系对企业运营和管理中涉及的业务概念和逻辑规则进行统一定义、命名和编码。数据模型是一组概念的集合,这些概念描述了系统的数据结构、动态特征和完整约束条件,这就是数据模型的三要素。数据结构是组成数据库的对象的集合,是对象和对象间联系的表达和实现,是对系统静态特征的描述。数据操作是数据库中数据可执行的操作集合,是对系统动态特性的描述。数据完整性约束是一组完整性规则的集合,规定了数据库状态以及状态变化所满足的条件,以保证数据的正确性、有效性和数据模型建模方法的基本原理相容性。而在大数据平台中,我们构建一个元数据模型池,以供整个平台按照需求进行模型设计和模型调用。
模型池:预测模型算法、Sqoop数据迁移、Storm数据模型算法、spark数据模型、数据库连接管理模型。Sqoop基于MapReduce计算框架,支持Hive、MySQL、Oracle、HDFS、Impala、HBase之间相互数据迁移。每种数据模型,保存入模型池以启动数据同步进行增量抽取任务。
1.2异构数据源连接管理
传统的数据源的元数据主要有:源系统地址、网络连接、访问方式;计算机系统、操作系统;源数据库链接说明。在大数据平台中主要是对异构数据源和同构数据源进行连接管理,例如对 Oracle、Hive、MySQL、HDFS、Impala进行连接管理以供元数据管理系统调用。这是大数据平台ETL处理的第一步情况,也是贯穿整个大数据任务调度的一个关键点。
1.3大数据平台中各种数据库的元数据获取
传统关系型数据库的元数据主要有:分区设置、索引、数据库管理系统层次的安全性特权与授权;视图定义;存储过程与 SQL管理脚本;数据库管理系统备份状态、备份程序及备份安全性。而大数据不仅仅是关系型数据库,还有基于列族的HBase,基于文件的MongDB,HDFS,数据仓库Hive,Impala等NoSQL,获取这些元数据才能够使得大数据平台满足各大数据库之间数据相互迁移,数据清洗,数据装载。
2 基于Neo4j来设计元数据溯源方案
2.1Neo4j原理
Neo4j是一个基于图论算法、完全兼容ACID的图形数据库。低层数据以一种针对图形网络进行过优化的文件格式保存在磁盘上。由于Neo4j的图形结构导致其数据结构不是必须的,而且可以完全没有,它在数据建模方面针对常见的复杂领域数据集,如CMS里的访问控制可被建模成细粒度的访问控制表,类对象数据库的用例等进行图形数据建模。常常被用于基因分析、社交网络数据建模、深度推荐算法等领域。由于Neo4j是自适应规模的,而且它的图遍历执行速度是常数,与图大小无关,所以其读性能可以达到每毫秒遍历2000多节点关系,在处理图关系时候完全是事务性的,这就保证了图数据库操作的完整性和准确性。相比关系型数据库其性能更突出,而最为主要的一点是Neo4j面向分析的图形数据库。
2.2数据建模存储
在大数据平台的元数据池中,建模之后的数据模型都以JSON格式展现出来,基于Neo4j进行模型存储,就要对其调用方式最小颗粒度进行分析、对其使用范围进行规范、对其调用方式进行分析然后确定存储方式。Neo4j存储时候主要进行节点Label标签定义、节点属性定义、节点与节点之间关系定义。定义Label,主要是为了标示一个节点集合,为所属节点的属性定义某些限制,增加索引。Label机制提供的是一种对节点进行分组的方法,建立在分组上的管理需要采用TraversalDescription遍历API机制来实现,进而在该集合上执行建立索引、定义约束和查询等操作。定义节点属性,按照首先创建空节点方法,添加属性。而在创建的节点之间按照自己定义的关系语义来两两节点之间创建有向图关系。
如图1所示:这是基于Neo4j实现Storm两张表进行Join操作最后导入HDFS中的数据模型存储。
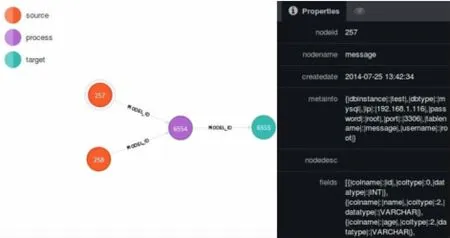
图1 Neo4j存储的Storm的Topology模型
2.3元数据版本维护
针对元数据的不断更新、补缺、变换,传统元数据管理系统没有版本维护功能,很难完整地记录所有的更改历史记录,也很难在某个时间戳的时间节点上进行统计和查询。在大数据平台中,如果对元数据的追加和元数据的更新做一个版本维护的话,数据量太大很少有人去愿意这样做,而我们基于Neo4j做元数据版本管理,针对图关联,以及最短路径算法对其进行高效存储和快速查询。与数据模型不同的是大量元数据我们存储进入Neo4j图形数据库,采取嵌入式离线存储方式,其内部采取MapReduce,可以快速存储上亿节点,把每条元数据设计为最小颗粒度进行节点存储,一旦某条记录被改变,不用去删除节点,只需要在节点之后扩展一个加入时间戳的新节点,并建立有向图关系,在查询时候可以根据需求,对每一个修改时间段进行版本维护,可以快速实现不同版本之间全表对比,而且可以对修改的元数据很快速地遍历修改过程和修改详情。
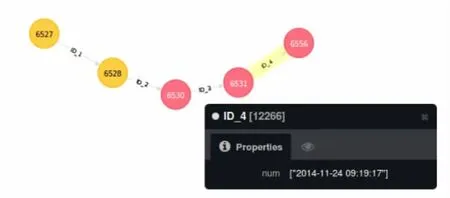
图2 元数据版本管理
如图2所示:按照我们的设计方案,某元数据经历5次改变,甚至元数据都改变了Label,实现了跨集合之间版本管理和全表对比。
2.4元数据溯源
基于异构数据源的连接管理和数据源版本管理的基础之上,我们需要对元数据的每一条信息,例如数据库的表字段,进行数据溯源,在整个大数据平台数据处理中,一旦某元数据做了更新和变换,我们都能通过最终形式的表现追溯到这个字段的整个遍历历史详情,我们采用Neo4j进行有向图扩展,每次元数据更改我们会基于这个节点对其进行节点扩展,其中两个节点之间关系类型设计为修改标示符,在新增节点加入修改时间戳,以利于遍历节点时候,能够记录修改时间,以及做时间段修改数量统计和遍历详情管理,数据源的每一个表一个Label,每一个字段一个节点,节点中属性就是Value,外加连接节点信息。这种设计模式,可以最小粒度来溯源以及管理整个元数据,在大数据平台整个元数据这种粒度调用管理,可以任意调取,以及实现不同的推送功能和将来扩展的应用。元数据溯源节点遍历主要是对最短路径算法和Dijkstra算法的实现。
最短路径算法如下所示:

这种最短路径算法,针对数据模型的深入和节点关系的出入度,而Dijkstra解决有向图中任意两个顶点之间的最短路径问题,这种算法在元数据溯源和版本维护中可以快速查找作业流程和全表对比。

3 结语
本文基于Neo4j对大数据平台的元数据进行溯源设计。通过Neo4j构建数据模型池,生成数据模型图以供平台调用,而对元数据的连接管理和任务调度过程以图形进行关联,进而对元数据进行版本管理和溯源,对整个大数据平台的ETL模块进行流程监控,流程回溯和全局掌控,并且对平台内部扩展功能模型进行流程关联和任务调度流程记录。大数据的元数据溯源实现并且大大地提高了大数据平台的推送能力和扩展N个大数据应用的能力,在未来大数据发展中,进一步提高平台扩展性和推送能力将是大数据平台自适应发展的一个核心发展方向。
[1]宋杰,郝文宁,陈刚等.基于MapReduce的分布式ETL体系结构研究[J].计算机科学,2013,40(6):152~154
[2]Ian Robinson,Jim Webber,and Emil Eifrem.Graph Databases[M].US:O'Reilly Media,2013
[3]宋青,汪小帆.最短路径算法加速技术研究综述[J].电子科技大学学报,2012,2(41):177~178
[4]戴磊,马小平,姜代红.基于优化Dijkstra算法的物流配送系统设计[J].微电子学与计算机,2011,10(28):34~35
[5]方圆,杜祝平,周功业.基于对象存储的新型元数据管理策略[J].计算机工程,2012(3):25~27
[6]White T.Hadoop:The Definitive Guide[M].US:O'Reilly Media,2012
[7]Jin X J.Trident Storm and Flow Calculation Experience[J].Journal of Programmers,2012(10):99~103
[8]陆嘉桓.大数据挑战与NoSQL数据库技术[M].北京:电子工业出版社,2013
Big Data;Metadata;Provenance;Neo4j
Research on the Process of Metadata Provenance in the Big Data Based on Neo4j
JIN Yong-chao1,2,WU Huai-gu2
(1.College of Mathmatic and Computer,Xihua University,Chengdu 610039;2.College of Information Science Technology,Chengdu University,Chengdu 610106)
1007-1423(2015)08-0061-04
10.3969/j.issn.1007-1423.2015.08.014
靳永超(1987-),男,陕西宝鸡人,硕士,研究方向为云计算、大数据处理
2015-02-12
2015-03-12
在大数据处理中,针对大量的结构化数据、半结构化数据,数据以不同形式被迁移、转换、装载,整个流程的数据和元数据都得不到很好掌控和集中管理,没有办法追根溯源,这对整个大数据平台自适应的推送能力和扩展能力产生极大影响。提出一种基于Neo4j图形数据库来对大数据的元数据进行溯源的方法,以使得整个大数据处理过程中对元数据进行全局掌控,流程监控和流程回溯。
大数据;元数据;溯源;Neo4j
吴怀谷(1975-),男,四川成都人,博士,教授,研究方向为云计算体系结构、移动应用体系结构和分布式信息系统
In the process of big data,as for the large number of structured data,semi-structured data,the data is migrated,transformed,and loaded in different forms.The whole process of the data and metadata are hard to control and centralize management.And there is also no way to track back these data,so it affects this push capability and scalability of the whole large data platform.Proposes a method which is based on Neo4j graphics databases to provenance to the metadata,in order to global control,flow monitoring and flow provenance the processing of the data.
猜你喜欢
中央民族大学学报(自然科学版)(2018年3期)2018-11-09
计算机与生活(2018年3期)2018-03-12
中国科技期刊研究(2017年2期)2017-05-14
财经(2017年2期)2017-03-10
财经(2016年15期)2016-06-03
财经(2016年3期)2016-03-07
财经(2016年6期)2016-02-24
党政干部学刊(2015年7期)2015-12-24
浙江大学学报(工学版)(2015年2期)2015-05-30
土木建筑工程信息技术(2013年4期)2013-10-17
