
一种基于节点性能的Hadoop动态调度策略
2015-09-28 06:10吴平平殷其雷
现代计算机 2015年8期
吴平平,殷其雷
(四川大学计算机学院,成都 610064)
一种基于节点性能的Hadoop动态调度策略
吴平平,殷其雷
(四川大学计算机学院,成都610064)
0 引言
近年来,随着互联网应用的飞速发展,越来越多的网络服务和商业应用被部署在云计算环境中,需处理的数据的规模越来越大,这导致了云计算[1]的迅速发展。云计算是一种新兴的分布式的商业计算模型。其中,最出名的大规模数据处理解决方案是MapReduce[2]编程模型。MapReduce编程模型是Google公司在2004年提出的[3],被广泛应用于分布式抓取、分布式排序、日志分析、构建倒排索引、机器学习等应用中。Hadoop[4]作为云计算的一种开源实现,也被广泛应用于Yahoo!、FaceBook、Amazon等公司[5]。Hadoop主要由MapReduce编程模型和HDFS分布式文件系统组成。
目前,Hadoop的MapReduce默认的任务调度策略仅考虑同构环境,这就导致目前的Hadoop在异构环境下的不同硬件平台时不能根据硬件性能和机器运行时的性能动态调整各个节点的任务分配量。另外,Hadoop的参数在集群启动之前在配置文件中进行配置,这样在集群在其启动之后不能根据节点的运行时性能动态的改变配置文件并使其生效[6]。本文就是在Hadoop默认的任务策略之上,提出一种基于节点性能作为指标的动态任务调度策略。该策略根据节点的CPU使用率和内存使用率作为评价节点运行时性能的依据,根据节点的运行时性能好坏动态调整节点的任务分配数,从而达到集群中各节点运行在较好状态的效果,进而缩短Hadoop集群的任务整体响应时间。
1 Hadoop默认的调度策略
1.1默认调度策略
Hadoop的MapReduce采用了Master/Slave架构,它由Client、JobTracker、TaskTracker和Task四部分组成[7],在整个集群中,JobTracker只有一个,有多个Task-Tracker。应用程序提交任务到JobTracker,由JobTracker进行任务的分配与调度。在JobTracker中,会在offerservice方法中启动调度器(默认为FIFO调度器),调度器根据配置文件配置和集群的实时情况调度和分配任务。
TaskTracker会周期性地通过HeartBeat将本节点上资源的使用情况和任务运行信息汇报给JobTracker,同时也接受来自JobTracker发来的命令并且执行它们。TaskTracker使用slot等量划分本节点上的资源量。一个Task只有获取一个slot之后才有机会运行,而Hadoop调度器的作用就是将各个TaskTracker上空闲的slot分配给Task使用。slot分为Map slot和Reduce slot两种,分别给 Map Task和 Reduce Task使用。TaskTracker通过slot数目来限定Task的并发度。
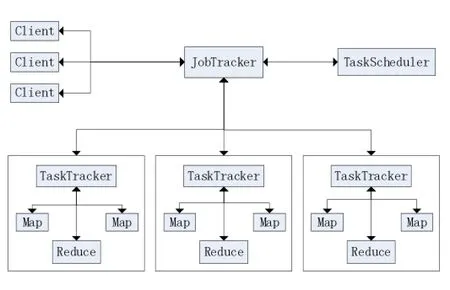
图1
1.2默认调度策略中存在的问题
Hadoop默认的策略采用了静态的任务分配策略,每个节点实现配置好可用的slot总数,这些slot数目一旦启动后无法再动态修改。但是实际应用场景中,不同作业对资源的需求具有较大的不同,静态配置slot数目可能会导致节点上的负载过高或者过低。
从对MapReduce的Task分配过程的分析可知,Hadoop默认的任务调度策略是建立在同构的假设之上的,当JobTracker分配相应的任务时,并不考虑节点处理能力的高低,每个节点同时执行的任务量不会因为性能的不同发生改变。因此在异构环境下,节点硬件性能和运行时性能有一定的差异,会出现以下不足:
(1)性能较差的TaskTracker负载过重,性能较好的节点的资源利用效率低下[8]。Hadoop原来的分配策略默认地认为各节点性能相同,在给各节点分配任务的时候并没有考虑到各个节点的性能差异,相同的任务量对每个节点产生的负载因各个节点自身的性能高低而不同。造成性能较低的节点负载过重,从而一直处于过载状态,使响应时间延长,从而导致整个集群的响应时间变长。
(2)不能考虑运行时节点的性能。实际应用中,有些任务在运行时需要的CPU和内存较多,因此同样数目的任务可能使节点的负载过重,造成响应时间延长。
2 基于节点性能的Hadoop集群动态调度算法
2.1算法的描述
基于以上分析,本文提出一种能够根据节点性能动态改变TaskTracker的分配任务的改进策略,该策略根据节点的性能动态调整分配给节点最大任务数,从而能够让性能较好的工作节点分配更多的任务,进而加快响应时间。算法流程如图2所示。
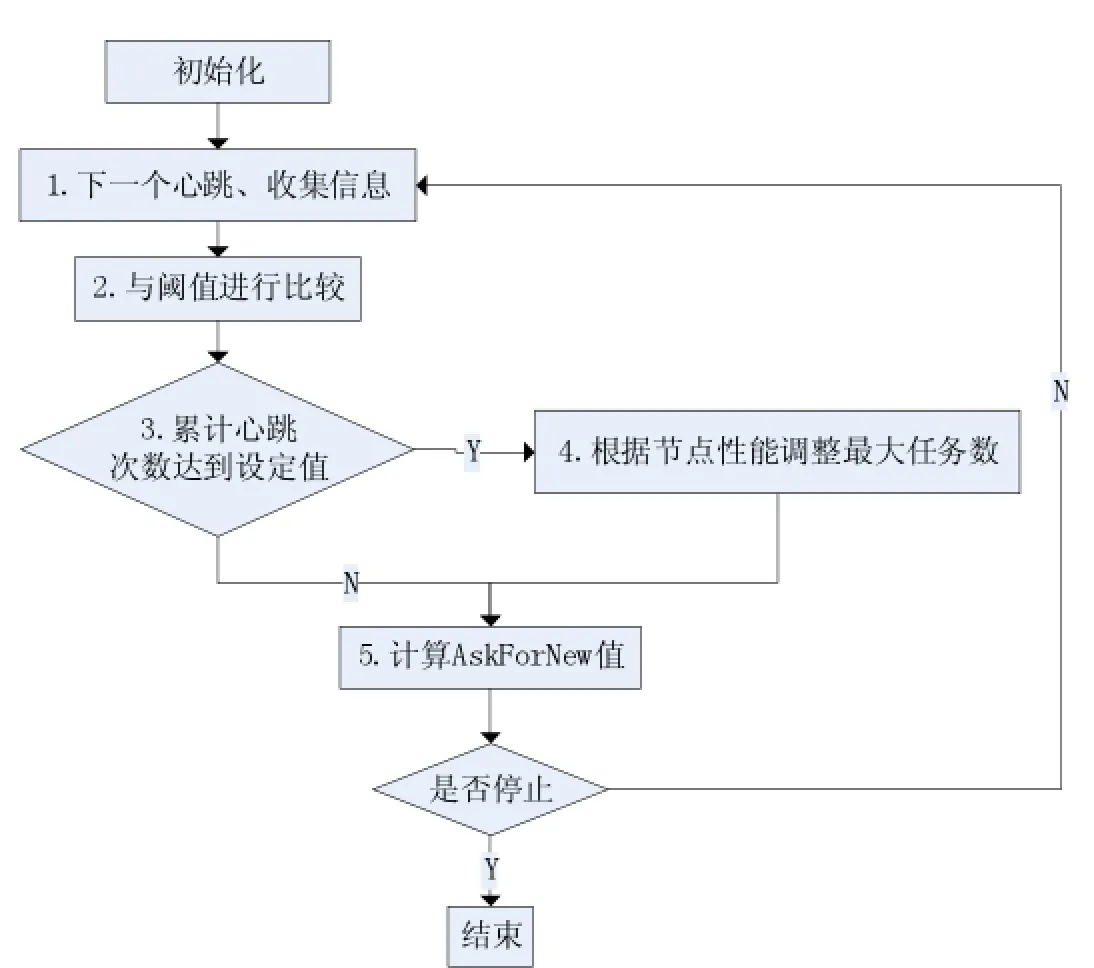
图2
(1)TaskTracker每间隔一个心跳周期,通过Hadoop自带的 LinuxResourceCalculatorPlugin采 集CPU利用率和内存利用率信息并初始化一些数据。
(2)将CPU利用率和内存利用率分别与各自的设定值进行比较,判断该节点在该心跳周期中是否为较好的状态。
(3)判断心跳计数,当达到设定的值时则进行(4);否则进入(5)。
(4)根据性能评估函数确定该节点的最大任务分配数的调整。
(5)计算AskForNew值,判断是否可以向该节点分配任务。
2.2算法的实现
本算法采用Java语言实现,通过在TaskTracker类的transmitHeartBeat方法中加入算法并将修改的代码与增加的代码放入Hadoop工程源码中,使用Eclipse平台中集成的Ant进行编译生成jar包。算法的实现如下:
输入:节点的CPU使用率、内存使用率信息
MAX,MIN:分别表示最大和最小的任务数
MaxTasksNum:初始化为2
T:心跳计数间隔
a:判断T次心跳中节点性能为较好的数目阈值
b:判断T次心跳中节点性能为较差的数目阈值
Performance:数组记录T次心跳中节点的性能信息
Cthre,Mthre:分别表示CPU阈值和内存阈值并初始化
输出:AskForNew,MaxTasksNum
S0:/*初始化节点和参数信息*/
S1:/*TaskTracker通过 Hadoop自带的 LinuxResource-CalculatorPlugin得到节点CPU利用率CpuUsage、内存利用率MemUsage信息;获取 Performance、HeartBeatCount、Max-TasksNum、MinTasksNum,其中Performance为记录性能状态的数组,性能较好对应的位置1,较差置为0*/
cpuUsage=getCpuUsageOnTT();
memUsage=1-getAvailablePhysicalMemoryOnTT()*1.0/ getTotalPhysicalMemoryOnTT();
S2:/*将CPU利用率与设定的阈值Cthre比较,内存利用率与设定的阈值Mthre比较,如果CpuUsage小于Cthre并且MemUsage小于Mthre则使Performance的对应位置为1并且HeartBeatCount数加1,否则使Performance的对应为置为0并且使HeartBeatCount数加1*/
/*如果CPU利用率和内存利用率满足一下条件,则认为是性能较好的状态*/

S4:/*根据Performance中记录的历史对节点进行评估,如果Evaluate(Performance)等于1并且MaxTasksNum<MAX,则另 MaxTasksNum加 1并且将Performance数据元素都置0,HeartBeatCount置0;
如果Check(Performance)等于false并且MaxTasksNum>MIN,则另MaxTasksNum减1并且将Performance数据元素都置0,HeartBeatCount置0
*/
/*对前 T次心跳间隔中统计的节点信息进行评估,并动态改变最大任务数*/

S5:/*将该节点正在运行的任务数 RunningTasks与MaxTasksNum进行比较,如果 RunningTasks小于 Max-TasksNum则另AskForNew置为true,即可以向该节点分配任务;否则将AskForNew置为false*/

3 实验与结果分析
3.1实验平台与参数
本文使用Hadoop-1.0.0进行了实验环境的搭建并对所提出的改进策略进行实现并仿真。将改进的源代码使用Eclipse集成的 Ant编译生成jar包hadoopcore-1.0.0.jar并部署到Hadoop集群中的各个节点上,采用Hadoop自带的WordCount基准测试程序。实验集群共有7台机器,其中一台用作JobTracker节点,另外6台用作TaskTracker节点,每台机器的网络带宽为100Mbps。具体配置如表1所示。
不同的参数对集群的响应时间有一定的影响。本文中,对于Hadoop默认策略的参数配置采用Hadoop的默认的配置文件中的值。改进的策略中的参数初始化配置如表2所示。
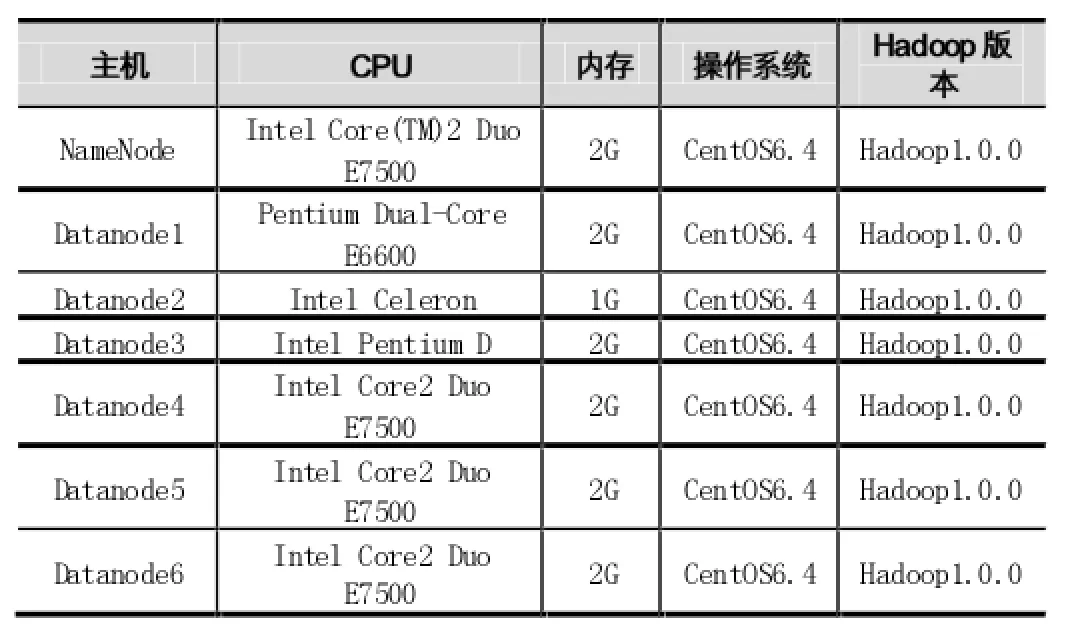
表1 集群配置

表2 改进策略参数配置
3.2实验与分析
实验分别使用Hadoop默认的任务分配调度策略和改进分配调度策略对1.3GB、2.6GB、3.9GB、5.2GB的文件进行WordCount基准测试。WordCount在运行时需要将数据装入内存和使用CPU计算,适用于测试本改进策略。为了减少实验结果的随机性,本实验每组分别测试了3组数据并取平均值作为最终的测试结果。实验结果如表3所示。从表中可以看出,改进的策略相对于原始分别缩减了7s、12.3s、14.7s、19.7s。
通过计算可知,随着任务量的增大,改进的策略相对于默认的策略的响应时间缩减得更多,如图3所示。这说明随着任务量的增大,改进算法算法比较稳定,能够更好地提高集群的响应效率。
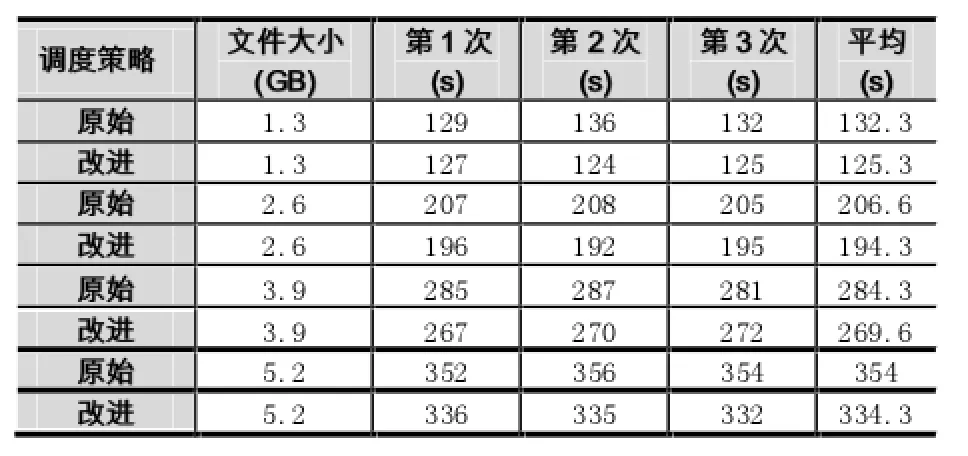
表3 Hadoop默认策略和改进策略的响应时间对比
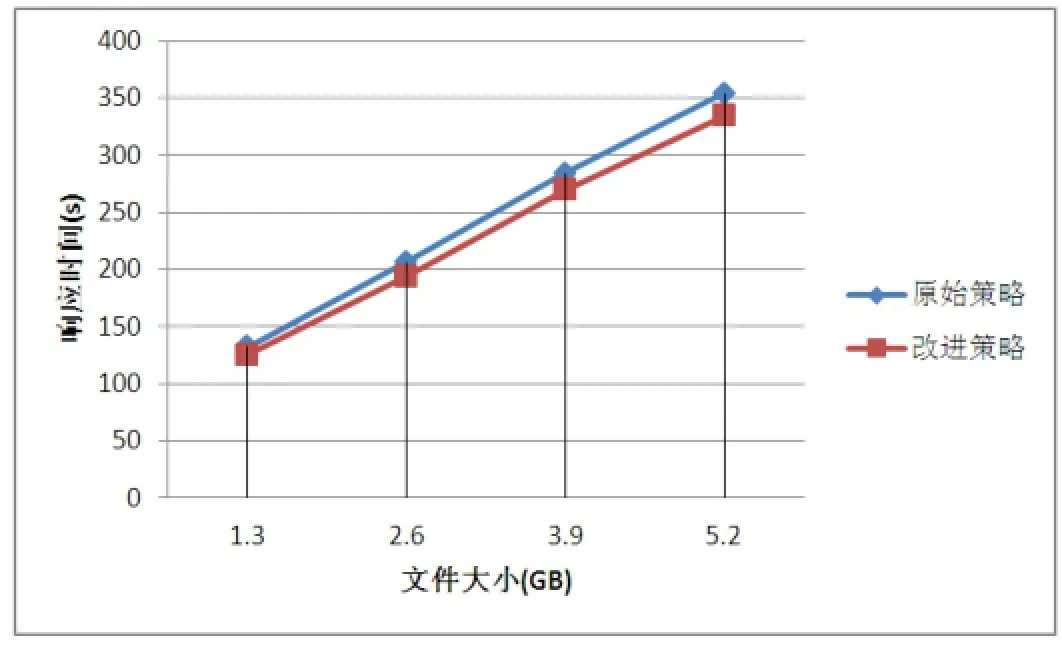
图3 不同任务量的响应时间对比
4 结语
本文通过考虑节点影响性能的CPU和内存等因素,分析了Hadoop默认任务调度策略的局限性,提出了一种基于节点性能的动态调度策略。从实验中可以看到,该策略能够降低任务的响应时间,并且随着任务量的增大,能够更好地减少响应时间。
[1]刘鹏云.计算2版.北京电子工业出版社
[2]Jeffrey Dean,Sanjay and Ghemawat.MapReduce:Simplified Data Processing on Large Clusters.Communications of the ACM.Page 107~113,Volume 51,Issue 1,2008.1
[3]谷歌实验室.http://labs.google.com/papers/mapreduce.htm
[4]Hadoop官网.http://hadoop.apache.org
[5]雅虎开发者.https://developer.yahoo.com/hadoop
[6]栾亚建等.Hadoop平台的性能优化研究.计算机工程,2010(14)
[7]董西成.Hadoop技术内幕.机械工业出版社
[8]郑晓薇等.基于节点能力的Hadoop集群任务自适应调度方法.计算机研究与发展,2014(03)
Hadoop;Node Performance;Scheduler Strategy
A Hadoop Dynamic Scheduling Strategy Based on the Node Performance
WU Ping-ping,YIN Qi-lei
(College of Computer Science,Sichuan University,Chengdu 610064)
1007-1423(2015)08-0042-05
10.3969/j.issn.1007-1423.2015.08.010
吴平平(1987-),男,湖北随州人,研究生,研究方向为计算机网络与信息安全
2015-02-10
2015-02-28
针对Hadoop默认的任务调度分配算法不能根据集群中节点的性能进行动态的调整任务的问题,提出一种基于节点性能的动态任务调度策略。该策略根据节点的CPU使用率和内存使用率作为评价节点运行时性能的依据,根据节点的运行时性能好坏动态调整节点的任务分配数,从而达到集群中各节点运行在较好状态的效果。实验显示,该策略使集群的总任务完成时间缩减,有效提高集群的性能。
Hadoop;节点性能;调度策略
殷其雷(1991-),男,硕士,研究方向为计算机网络与信息安全
The default task scheduling algorithm of Hadoop can not adjust the assignment of task according to the performance.Proposes a dynamic task scheduling strategy based on the node performance.The strategy uses the node CPU utilization and memory utilization as the basis of evaluating the node's runtime performance,then adjust the task number dynamic according to the basis,so each node in a cluster can work in the good state.Experiments results indicate that the strategy makes the total completion time of task clusters reduced significantly and improve the performance of the cluster.
猜你喜欢
中国煤炭(2020年2期)2020-01-21
军事运筹与系统工程(2019年4期)2019-09-11
电脑报(2019年31期)2019-09-10
当代陕西(2019年13期)2019-08-20
中国化肥信息(2019年6期)2019-01-19
电子制作(2018年11期)2018-08-04
消费导刊(2017年24期)2018-01-31
中国交通信息化(2017年3期)2017-06-08
知识就是力量(2017年2期)2017-01-21
印制电路信息(2015年6期)2015-12-30
