
基于AdaBoost算法的人脸人眼分类器的设计与实现
2015-09-27 08:23汪仕才冯桑呙腾
现代计算机 2015年29期
汪仕才,冯桑,呙腾
(广东工业大学机电工程学院,广州 510006)
基于AdaBoost算法的人脸人眼分类器的设计与实现
汪仕才,冯桑,呙腾
(广东工业大学机电工程学院,广州510006)
0 引言
AdaBoost算法最早由Freund和Schapire在1995年提出,随后在2001年Paul Viola[1]等在其基础上,通过引入“Haar”特征和“积分图”的思想,设计了级联式(cascaded)人脸检测器,使人脸检测的检测率和检测速度有很大提升。AdaBoost算法通过权重更新,能够“聚焦于”那些比较困难的样本,且算法简单、实时性好,检测速度快[2],在人脸检测中有着广泛的应用。例如,我国学者应用AdaBoost算法对ORL人脸库进行实验[3],还有采用肤色和AdaBoost方法相结合来进行人脸检测,并在此基础上结合人脸结构的边缘特征及AdaBoost方法对眼睛进行精确定位[4]。AdaBoost算法的准确性依赖于训练样本的数量,且大量增加样本数量还会增加训练时间[5],因此,本文尽量全面的选取驾驶环境下的人脸人眼样本,包括正脸、侧脸、戴眼睛和部分遮挡等情况,况且本文人脸检测系统的样本训练是在系统检测之外,这为进一步实现人脸的实时检测提供了可能。
1 Haar特征及其特征值的计算
1.1Haar特征及i其特征
在模式识别的研究中,Haar特征能描述特定走向的结构,特别是对边缘、线段等简单的图形结构比较敏感,能很好地表述人脸肤色和五官的信息,在优化特征的计算和分类器的架构后,可以使分类器的训练和检测速度得到极大的提高。Haar特征由白色或黑色的两种小矩形组成,分别排列成垂直、水平和对角线,即2-矩形特征、3-矩形特征和4-矩形特征三类[6],为了弥补Haar特征对于旋转后多角度等其他情况下的人脸检测的不足。在分类器的训练中,针对具体的检测要求,在三类基本Haar特征的基础上扩充了Haar特征集[7],如图1所示。

图1 扩充后的Haar特征集
AdaBoost算法中分类器的训练和利用分类器进行检测这两个过程,都需要通过计算Haar特征的特征值来实现。Haar特征的特征值反映的是图像中局部区域的灰度变化,Viola对其定义为:白色矩形和黑色矩形在图像子窗口中所对应区域的灰度级总和之差,其数学表达式可以定义为:

其中,N为构成特征的矩形个数,wi为第i个矩形的权重,Recsum(ri)为矩形所有像素点的像素值之和。
1.2积分图及Haar特征值的计算
如图2,对于图像内一点A,设其像素值为A(x,y)。若图像为彩色,则首先要按照人脸色彩空间将其转化为灰度取值。根据定义,该点的积分图为其左上角所有像素之和,即图中阴影部分,其定义式为:

其中,ii(x,y)表示积分图,表示原始图像,其值是该点的灰度值,值域为[0,255]。
下面就可以根据定义来计算矩形特征的特征值。以边缘特征为例,如图3所示,其中P(A)、P(B)分别表示区域A、B的灰度值和,ii(1)-ii(6)分别表示端点的积分图,该特征的特征值可以表示为:P(A)-P(B)=ii (1)-ii(6)-2ii(3)+2ii(4)+ii(5)-ii(6)。
2 人脸人眼分类器的设计
2.1分类器的训练流程分析
自AdaBoost算法被提出以来,已经有很多文献全面描述了如何使用该算法训练分类器(如文献[5]),本文主要关注AdaBoost算法训练分类器时程序的运行机制,为此本文设计的训练流程如图4所示。

图2 某点A的积分图
(1)创建Haar特征
Haar特征由函数icvCreateIntHaarFeatures()创建,函数有三个参数winsize、mode和Sysmetric。其中,Mode是使用的特征类型,决定使用基本的5种特征还是其他。当Symmetric的值为0时,表示创建所有特征;当Symmetric的值为1时,表示只创建Haar特征中心在目标左半部分的所有特征。

图3 用积分图计算边缘特征的特值

图4 HaarTraining训练分类器的流程图
(2)载入正样本
正样本的载入函数为icvGetHaarTrainingData FromVec(),包含四个指针参(CvHaarTrainingData*Data,CvIntHaarClassifier*cascade,constchar*Filename,int*consumed)和两个整型参数(int first,int count)。其中,程序第一次运行到此时可以取出count个正样本,在程序后续运行到此时,只有被正确分类的样本才能读取到。consumed参数表示查询过的正样本总数。此外,积分图像的计算通过函数调用icvGetAuxImages来实现。
(3)载入负样本
负样本的载入函数为icvGetHaarTrainingData FromBG(),其中,程序第一次运行到此时可以取出count个负样本,在程序后续运行到此时,只有被分类错误的样本才能读取到。acceptance_ratio=((double)count)/consumed_count,即虚警率,记录的是实际取出的负样本数与查询过的负样本数之比。如果虚警率达到预设值,则训练停止。另外,积分图像的计算也通过函数调用icvGetAuxImages来实现。
(4)计算Haar特征值
Haar-like特征值由函数icvPrecalculate计算,包含data、HaarFeatures和numprecalculated三个参数。numprecalculated的计算公式为:
numprecalculated=(int)(((size_t)mem)*((size_t)1048576)/(((size_t)(npos+nneg))*(sizeof(float)+sizeof (short)))
其中,mem是内存大小,1048576(即1024×1024)表示1M字节。sizeof(short)为保存一个特征值需占用的字节数,sizeof(short)表示对特征值排序后保存一个排序序号需占用的字节数。
(5)训练一个强分类器
训练强分类器的函数为:icvCreateCARTStageClassifier(),每一级强分类器的收敛条件为在开始训练时设定的参数minhitrate和maxfalsealarm。单个强分类器的训练流程如图5所示。
(6)将级联强分类器信息写入XML文本
强分类器信息需要保存到临时文件AdaBoost-CARTHaarClassifier.txt中,该功能由函数icvSaveStage-HaarClassifier负责,然后,函数cvSave(xml_path,cascade)读取临时文件中的级联强分类器信息,并将其保存到xml文件中。至此,整个训练部分完毕。
(7)测试分类器的性能
调用icvGetHaarTrainingDataFromVec()、icvGetH-aarTrainingDataFromBG()函数,分别测试检出率和虚警率。

图5 单级强分类器训练流程图
2.2利用OPenCV训练分类器
OpenCV中提供了许多机器学习算法,包括K均值、决策树、AdaBoost算法等,而且还提供了训练分类器的方法。我们可以利用用OpenCV提供的程序来训练得到一个分类器,训练主要分为以下三个步骤:
(1)准备样本库
考虑到在真实的驾驶环境中,驾驶员的头部不可避免的经常会左右晃动、上下调整、扭头看后视镜等,本文从实验室模拟驾驶环境、户外真实驾驶环境以及MIT-CBCLFaceDatabases人脸数据库中,挑选修改包含人脸样本的2706张图片,制作得到驾驶员人脸标准样本库。其中,在创建人脸、人眼正样本的过程中,首先要将得到的图片进行筛选,剔除去那些不适合于做样本集的图片:
①人脸不清晰;
②人脸正面旋转角度过大(>20°),人脸左右偏转角度过大(>45°)[8];
③人脸五官不全或者五官被遮挡;
④驾驶员佩戴的眼镜反光太强烈;
⑤在实际驾驶环境中出现的概率并不高的图片等等。
而人眼样本除了按要求截取和剔除一些不符合训练要求的人眼样本外,还要分别截取得到部分左眼睁开/闭合样本、部分右眼睁开/闭合样本和部分佩戴眼镜的人眼睁开/闭合样本。
负样本集是指不包含目标样本的其他任意图片。本文研究的人脸检测是应用在驾驶环境中,所以负样本的选取主要截取来自驾驶室内的背景,特别是一些容易与人脸区域相混淆的图片,当然也适当选取一些自然、生活、交通场景的图片。为了增大负样本的差异性,负样本在选取时尽量不重复。
(2)创建样本描述文件;
建立好正负样本集后,接下来分别将正负样本集进行编码描述,以便训练程序执行时有序地调用。正样本集的描述文件,用于描述正样本的文件名,包括:绝对路径或相对路径、正样本的数量、正样本在图片中的位置、正样本的大小,其描述文件的格式为:[filename][#of objects][[xy width height][…2nd object]...]。负样本集的描述文件需要生成一个包含了所有负样本文件名和绝对/相对路径名的文件就行。具体创建步骤如图6所示。

图6 创建样本描述文件的步骤
在DOS命令窗口下,设置参数调用CreateSamples程序,Createsamples的命令行参数设置及其含义如下表1所示。
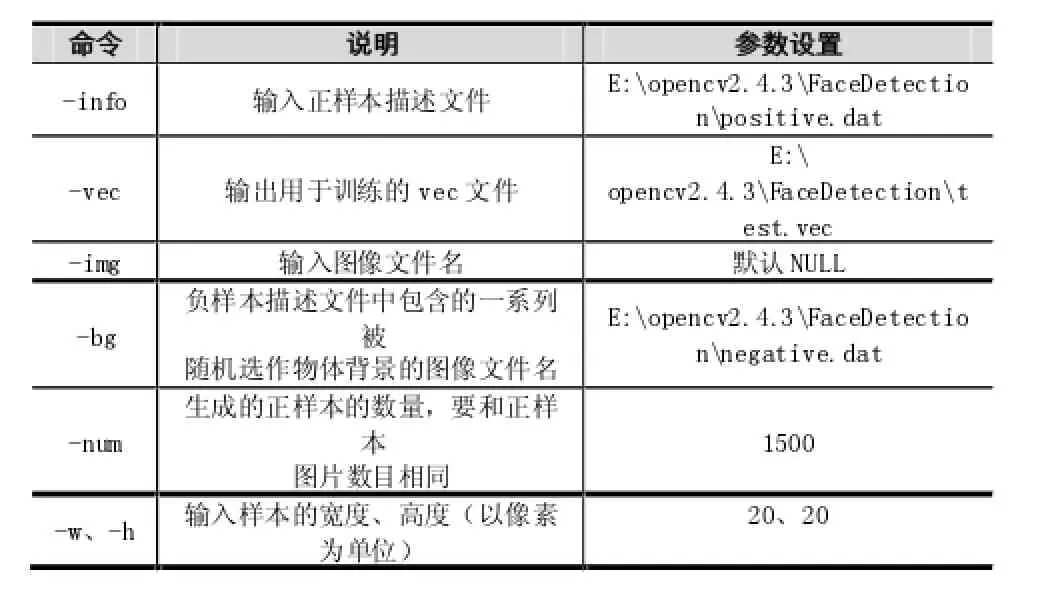
表1 CreateSamples程序的命令行参数及其设置
(3)训练分类器
编写一个批处理程序来启动HaarTraining训练程序,并提供必要的参数信息。其中,分类器、正样本vec文件和负样本描述文件的路经设置与启动Create Samples程序时的设置类似,除此之外,还要设置训练分类器的级数、决定用于阶段分类器的弱分类器的个数和计算时的可用内存大小等,这些参数设置对分类器的识别率和检测速度有重要影响,具体设置如表2所示。

表2 HaarTraining程序的命令行参数及其设置
3 分类器的测试与分析
3.1实验设备的选择
由于本课题旨在将疲劳检测技术向实用化推广,因此必须模拟车载环境。本文的车载实验和视频采集主要是利用家用普通车型完成。考虑到车型的不同,驾驶空间和环境的改变会对驾驶员的舒适感等带来变化,本文分别采用两款大小和配置不同的实验车型,两款实验用车的相关参数如表3所示。除此之外,我们还选择带红外补光夜视功能的宏普达行车记录仪采集视频,同时选择型号为T420的移动PC,作为该实验的处理器。

表3 实验用车的相关参数比较
3.2实验结果分析
本文基于VS2010和OpenCV2.4.3平台,编写程序对人脸检测算法和人眼定位算法进行联合测试,以验证训练得到的分类器的鲁棒性。测试程序运行后反馈的结果窗口如图7所示。

图7 人脸检测和人眼定位算法联合测试程序的界面
本部分的测试实验选择了10位不同的测试者,其中男性8名,女性2名,分别在白天和黑夜两种光照环
境下进行实验。测试结果如表4所示。

表4检测率实验结果
综合测试结果表明,本文驾驶员人脸检测算法的检测率和实时性都达到了较高的水平,算法的平均耗时约为80ms,白天的检测率达到93.7%,夜晚的检测率达到90.3%,同时,也说明本文样本集的选择和分类器的训练是成功的,达到了设计的预期效果。另外,在测试中发现,人脸在一定偏转角度内(左右偏转≤45°、正面旋转≤20°)、镜片反光效应以及部分特征丢失时,算法还是可以检测到人脸的,但是镜片反光效应却对人眼的定位造成了一定的影响,因此不利于疲劳检测。
[1]Paul V,Michael J..Robust Real-time ObjectDetection.TR CRL 200I/01,Cambridge UK:Cambridge Research Laboratory,2001.
[2]谢欢.基于AdaBoost算法训练分类器的研究及其在人脸检测中的应用[D].天津:天津工业大学,2010,17-18.
[3]曹珍.在人脸检测中对AdaBoost算法的应用研究[J].内蒙古:赤峰学院学报(自然科学版),2014,30(3):17-19.
[4]李维维等.基于AdaBoost算法的人脸疲劳检测[J].哈尔滨:自动化技术与应用,2014,33(2):46-48.
[5]陆伟春等.基于AdaBoost算法的快速人脸检测研究[J].云南:云南民族大学学报,2014,23(3):218-22.
[6]Viola P,Jones M.Rapid Object Detection Using a Boosted Cascade of Simple Features[C].Proc.IEEE Conf.on Computer Vision and Pattern Recognition,Kauai,HI.2001,1:511-518.
[7]Lienhart R,Maydt J.An Extended Set of Haar-like Features for Rapid Object Detection[J].IEEE ICIP,2002,1:900-903.
[8]徐镇辉等.基于眼睛定位及AdaBoost算法的平面旋转人脸检测[J].黑龙江:佳木斯大学学报,2013,31(5):718-721.
Face Categorizer;AdaBoost Algorithm;Face Detection;Eyes Orientation
Design and Implementation of Face and Eye Categorizer Based on AdaBoost Algorithm
WANG Shi-cai,FENG Sang,GUO Teng
(School of Electro-machanical Engineering,Guangdong University of Technology,Guangzhou 510006)
1007-1423(2015)29-0055-06
10.3969/j.issn.1007-1423.2015.29.014
汪仕才(1986-),男,湖北黄冈人,硕士,研究方向为驾驶疲劳预警系统的研究
冯桑(1973-),男,海南琼海,博士后,副教授,研究方向为汽车智能控制与辅助驾驶技术、汽车安全及人机工程学
呙腾(1987-),男,湖南岳阳,硕士研究生,研究方向为疲劳驾驶检测、汽车智能控制、模式识别
2015-09-22
2015-10-10
人脸检测和人眼定位是检测驾驶疲劳的首要工作,而人眼准确定位和检测速度直接影响后续疲劳检测的实时性和鲁棒性。基于AdaBoost算法检测速度快,泛化能力强等特点,通过建立针对驾驶环境下的人脸、人眼样本集,深入研究驾驶员的人脸人眼识别问题。实验证明,AdaBoost级联分类器不仅能够准确检测人的正脸,而且对于侧脸、戴眼睛和部分遮挡也有很高的识别率。
人脸分类器;AdaBoost算法;人脸检测;人眼定位
Face detection and eyes orientation are the primary task of detecting driver fatigue,and the real-time and robustness of the following fatigue detection is directly influenced by the accurate orientation of human eyes and the speed of detection.Studies the recognition problem of driver's face and eyes further through establishing the sample database of face and eye under the driving environment,which is based on the features of fast detection speed and strong generalization ability of AdaBoost algorithm.Experimental results show that the AdaBoost cascade classifier can not only accurately detect frontal faces,but also have very high recognition rate for a face in profile or with glasses and the partially occluded face.
猜你喜欢
数学物理学报(2021年6期)2021-12-21
数学物理学报(2021年5期)2021-11-19
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
数学物理学报(2021年3期)2021-07-19
烟台大学学报(自然科学与工程版)(2021年1期)2021-03-19
快乐语文(2019年9期)2019-06-22
中学生数理化·八年级物理人教版(2018年11期)2019-01-31
动漫星空(2018年9期)2018-10-26
优雅(2016年12期)2017-02-28
