
基于密度的优化初始聚类中心K-MEANS算法研究
2015-09-21 01:30何佳知谢颖华
网络安全与数据管理 2015年19期
何佳知,谢颖华
(东华大学 信息科学与技术学院,上海 201620)
0 引言
随着“信息爆炸”时代的到来,数据挖掘领域得到人们越来越多的关注。聚类分析作为数据挖掘的重要分支,属于无监督的机器学习方法[1]。基于物以类聚的思想,聚类分析把样本点划分为子簇,使得同一簇中的对象尽可能相似,而不同簇的对象尽可能相异[2]。目前,聚类已根植于许多应用领域,包括商务智能、图像模式识别、WEB搜索、生物学和安全等[3]。
K-means算法是目前聚类分析领域中基于划分的热门研究课题,具有理论可靠、算法简单、收敛速度快、能有效处理大数据的特点[4]。但它也存在一些不可避免的问题[5]:(1)聚类数目k需要预先确定,经验的缺乏导致对k的数值很难界定;(2)聚类结果随初始聚类中心的不同而变化,容易陷入局部最优解;(3)对局部极值点敏感,严重影响聚类结果的准确性。
本文提出一种基于密度优化初始聚类中心的方法,使其尽可能有代表性地反映数据的分布特征。利用数据集样本的点密度,对样本集划分高低密度集,选取高密度集合中的k个相距较远、密度最大的样本作为初始聚类中心,避免初始聚类中心位于同一类簇的缺陷,同时对噪声点进行单独处理,减小其对聚类结果的影响。
1 K-means算法介绍及相关研究
K-means算法是基于划分的聚类算法之一,基本思想[6]是:从包含n个对象的数据集中随机选取k个样本点作为初始聚类中心,对于剩下的每个对象,计算其与各个聚类中心的距离,将它分配到最近的聚类,并重新计算聚类中心,再将所有的样本点依据最近距离原则分配到相应的聚类簇中,不断地迭代直到分配稳定,即聚类误差平方和E收敛。
K-means算法简单,且适用于大规模数据量,但初始聚类中心的选取直接影响算法的聚类结果,算法的迭代次数依赖于初始聚类中心和实际聚类中心的偏差,因此,选取一组合适的初始聚类中心非常重要[7]。很多国内外学者从不同角度对该算法聚类中心的选取进行了改进。陆林华[8]对遗传算法进行优化,将遗传算法的全局搜索能力与K-means算法的局部搜索能力相结合;KAUFMAN L等[9]提出一种启发式方法,估计数据点的局部密度,并以此启发选择初始聚类中心;袁方等[10]提出给予样本相似度和通过合适权值来初始化聚类的方法;Huang J[11]提出一种变量自动加权方法,ALSABTI[12]利用k-d树结构改进K-means算法;汪中[5]等人采用密度敏感的相似性度量计算数据对象的密度,启发式地生成初始聚类中心;韩凌波[13]等人通过计算每个数据对象的密度参数选取k个处于高密度分布的点作为初始聚类中心;赖玉霞[14]等人采用聚类对象分布密度方法,选择相互距离最远的k个处于高密度区域的点作为初始聚类中心;王赛芳[15]等人通过计算点密度来选取初始聚类中心。
2 基于密度改进的K-means算法
传统的K-means算法对初始聚类中心敏感,聚类结果随不同的初始中心而波动。随机选取的初始聚类中心有可能是一些孤立点或噪声点,或者不同类簇的初始聚类中心位于同一个类簇,导致聚类结果可能偏离样本的真实分布,得到错误的聚类结果,使聚类的收敛速度缓慢甚至难以收敛。选取相距较远的样本作为初始聚类中心,可避免初始聚类中心位于同一类簇的缺陷,但对噪声点敏感;参考文献[11-12]解决了噪声点的问题,但由于涉及到密度调节系数或噪声调节系数,聚类结果直接依赖于参数的选择。主观性强,如果参数选择不好,聚类结果将变得很差。
针对上述局限性,本文提出一种基于点密度优化初始聚类中心选取的方式。在样本点空间中,一般认为高密度区域的点会被低密度区域的点分割,而噪声点往往处于低密度区域。同时,在以欧氏距离作为相似性度量标准的情况下,相互距离远的k个样本点往往比随机选取更具有代表性。因此,在划分出含有噪声点的低密度区域后,本文在高密度区域选取k个相互距离超过某阈值,且密度最大的样本点作为初始聚类中心,即改进K-means算法中的随机选取初始聚类中心。
2.1 基本定义
设给定含有 n个样本点的数据集合 X={xi|xi∈R,i=1,2,…,n},k 个聚类类别 Cj(j=1,2,…,k,k<n),k 个初始聚类中心 ncj(j=1,2,…,k)。 有如下定义:
定义1任意两个样本点间的欧氏距离
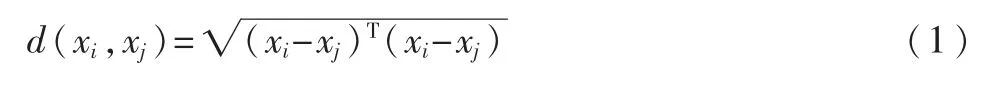
定义2 聚类中心(每个聚类簇的样本点的均值)

定义3聚类误差平方和
聚类误差平方和是数据集所有对象与它所在簇的聚类中心的平方误差的总和。聚类误差平方和越大,说明对象与聚类中心的距离越大,簇内的相似度越低,反之亦然。聚类误差平方和应尽可能小,从而使生成的结果簇尽可能紧凑和独立。

定义4点密度
对数据集 X中的样本点 x,以 x为圆心,r(r>0)为半径的球域内所包含的样本点的个数称为x的密度,记为D(x),即
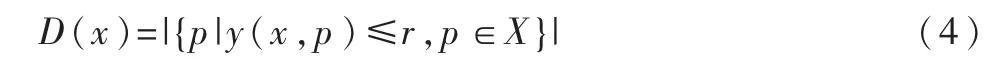
式中,y(x,p)表示样本点 x与 p的距离。通过比较,本文选择以欧氏距离作为距离度量,即 y(x,p)=d(x,p),r为设定的距离阈值。D(x)越大,样本点所处区域密度越高。
定义5噪声点
对于数据集 X 中的样本点 x,若 D(x)<αMD(x),则称x为噪声点。其中,MD(x)为所有样本点的密度平均值,即

2.2 初始聚类中心的优化算法
基于密度优化初始聚类中心的基本思想是:首先计算样本集中每个样本点的密度 D(x),并通过与整个样本集平均密度MD(x)的比较,将其划分给高密度集 M或低密度集N。选取集合M中密度最大的样本点作为第一个初始聚类中心nc1,将其从集合M中剔除;接着从集合M中选取与nc1距离超过距离阈值r,且密度最大的点作为第二个初始聚类中心nc2,以此类推,直到选取了k个初始聚类中心。
基于密度优化初始聚类中心算法的具体步骤如下:
输入:聚类簇的数目k以及包含n个对象的数据集X
输出:初始聚类中心集合nc,高密度集M和低密度集N
(1)根据式(1),计算样本集两两样本点间的距离,构造距离矩阵D;
(2)根据式(4)和式(5),计算样本集中每个样本点的密度 D(x),以及整个样本集的平均密度 MD(x);
(3)根据 MD(x),对样本点进行划分,依次归类进高密度集M或低密度集N;
(4)选取M中密度最大的样本点作为第一个初始聚类中心 nc1,并将其放入集合 nc中,即 nc=nc∪{nc1};
(5)选取下一个初始聚类中心nc2,并将其放入集合nc 中,即 nc=nc∪{nc2}。 其中,nc2应满足:①d(nc1,nc2)≥r;②D(nc2)=max{D(x)|x∈X-nc};
(6)重复步骤(5),直到选取 k个初始聚类中心。
2.3 噪声点的处理
聚类过程中,本文将数据样本划分为高密度集和低密度集,其中,低密度集就是噪声点集合。选取完k个初始聚类中心后,首先对集合M中的样本点进行K-means聚类,得到k个聚类和k个聚类中心。接着依据最小距离原则,将集合N中的噪声点分配到各个聚类中,完成所有样本点的分配聚类。由于避免了噪声点对聚类过程的参与,减少了其对聚类中心的影响,改善了聚类效果。
3 实验结果与分析
为了验证本文算法的有效性,选用MATLAB语言编程环境,对 UCI数据集进行测试,并与参考文献[5,12,14]及传统K-means算法的聚类结果进行比较。对算法聚类结果的评价标准包含很多种,本文采用两种度量指标:聚类准确率和聚类时间。利用聚类准确率来度量算法的有效性,利用聚类时间来度量算法的执行效率。
3.1 数据集描述及参数设定
UCI数据集是国际上专门用来测试机器学习、数据挖掘算法的公共数据库,库中的数据都有确定的分类,因此可以用准确率来直观地反映聚类算法的质量。在此,本文选择数据库中的Iris、Wine、Balance-scale、Hayes-roth以及New-thyroid 5组数据作为测试数据,如表1。
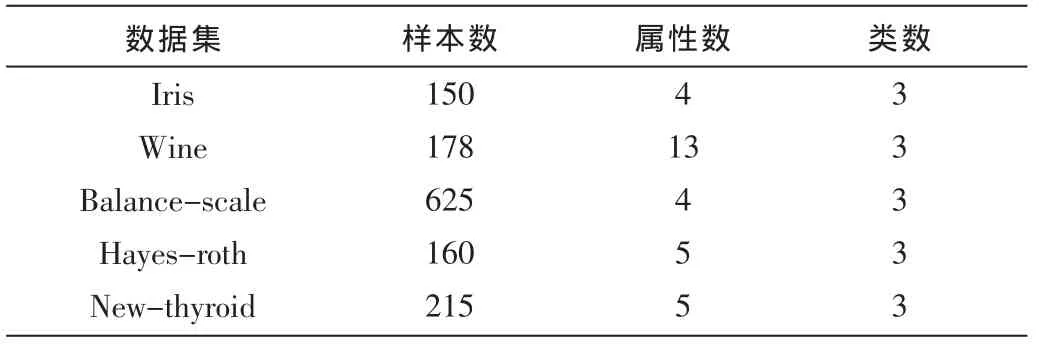
表1 UCI数据描述
3.2 实验结果
根据经验,将改进算法的密度球域半径r设为样本点两两间的平均欧式距离;噪声点划分阈值 0<α≤1,一般取值为1。所有算法均在表1给出的数据集上进行实验,所有评价结果均为在数据集上实验执行100次后取平均值。表2为选取五种不同初始聚类中心情况下算法在UCI数据集上的聚类准确率的比较,表3为各算法的聚类时间比较。
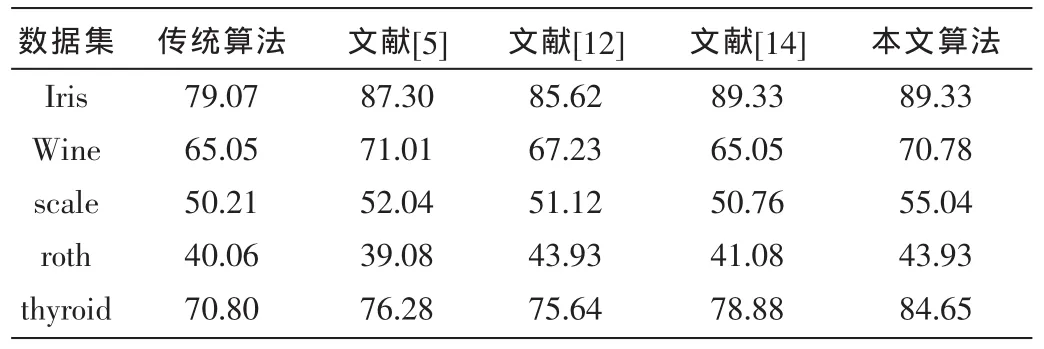
表2 各算法在UCI数据集上的聚类准确率比较(%)

表3 各算法在UCI数据集上的聚类时间比较 (s)
由表2聚类准确率的比较可知,在Iris数据集上,本文算法的聚类准确率与参考文献[14]中的算法一致,高于传统 K-means算法和参考文献[5,12];在 Wine数据集上,本文算法的准确率略低于参考文献[5],但高于参考文献[12,14]及传统 K-means;在 Hayes-roth数据集上,本文算法的聚类准确率与参考文献[12]一致,高于参考文献[5、14]及传统算法;而在其他数据集上,文本算法的聚类准确率高于其他四种算法。由此可见,本文算法相较于其他算法,聚类准确性更高。
由表3各算法聚类时间的比较可知,传统K-means算法的运行时间最短;本文算法的聚类运行时间优于参考文献[12,14],具有更快的收敛速度;但与参考文献[5]相比,在Scale和Wine数据集上,本文算法的聚类速度略有逊色。就总体时间分析而言,本文的算法优于其他算法,但不如传统K-means算法的速度快。这是因为改进后的算法增加了选择初始中心这一环节,造成了一定的时间损耗,但优化后的初始聚类中心能更好地表达数据的分布特征,有效缩短聚类过程,因此在一定程度上又能减少时间的损耗。
以上结果表明,相较于其他优化初始聚类中心的K-means算法,本文算法不仅可以获得更好的聚类效果,同时也能缩短聚类时间。
4 结束语
K-means算法应用广泛,但由于其过分依赖于初始化,聚类结果随初始中心的变化而波动,难以保证优良的性能。本文基于密度,有效改进了初始中心点的选取,克服了传统算法敏感且聚类效果容易陷入局部最优的缺陷,同时在一定程度上避免了噪声数据对聚类结果的影响。实验结果证明,该算法能大大提高聚类的准确性。
[1]毛国君,段立娟,王实,等.数据挖掘原理与算法[M].北京:清华大学出版社,2005.
[2]朱明.数据挖掘[M].合肥:中国科学技术大学出版社,2002.
[3]Han Jiawei,KAMBER M.数据挖掘概念与技术[M].范明,孟小峰,译.北京:机械工业出版社,2000.
[4]谢娟英,郭文娟.基于样本空间分布密度的初始聚类中心优化 K-均值算法[J].计算机应用研究,2012,29(3):888-890.
[5]汪中,刘贵全,陈恩红.一种优化初始中心点的K-means算法[J].模式识别与人工智能,2009,22(2):300-302.
[6]莫锦萍,陈琴,马琳,等.一种新的 K-Means蚁群聚类算法[J].广西科学学院学报,2008,24(4):284-286.
[7]柯良文,王靖.基于用户相似度迁移的协同过滤推荐算法[J].微型机与应用,2014,33(14):71-74.
[8]陆林华,王波.一种改进的遗传聚类算法[J].计算机工程与应用,2007,43(21):170-172.
[9]KAUFMAN L,ROUSSEEUW P J.Finding groups in data:all intro-duction to cluster analysis[M].New York: Wileys,1990.
[10]袁方,孟增辉,于戈.对K-means聚类算法的改进[J].计算机工程与应用,2004,40(36):177-178,232.
[11]HUANG J Z,NG M K,HONGQIALLG R,et al.Automated variable weighting in K-means type clustering[J].IEEE Trans on Pattern Analysis and Machine Intelligence,2005,27(5):657-668.
[12]ALSABTI K,RANKA S,SINGH V.An efficient K-means clustering algorithm[C].IPPS/SPDP Workshop on High Performance Data Mining.Orlando,Florida,1998:9-15.
[13]韩凌波,王强,蒋正峰,等.一种改进的 K-means初始聚类中心选取算法 [J].计算机工程与应用,2010,46(17):150-152.
[14]赖玉霞,刘建平.K-means算法的初始聚类中心的优化[J].计算机工程与应用,2008,44(10):147-149.
[15]王赛芳,戴芳,王万斌,等.基于初始聚类中心优化的K-均值算法 [J].计算机工程与科学,2010,32(10):105-107.
猜你喜欢
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
国际比较文学(中英文)(2019年1期)2019-11-12
铁道通信信号(2019年6期)2019-10-08
井冈山大学学报(自然科学版)(2019年4期)2019-09-09
雷达学报(2017年6期)2017-03-26
东方教育(2016年4期)2016-12-14
互联网天地(2016年1期)2016-05-04
智能系统学报(2015年4期)2015-12-27
中国校外教育(下旬)(2014年10期)2014-11-20
