
基于大数据的企业财务预警研究
2015-09-19 01:42朱建明
中央财经大学学报 2015年6期
宋 彪 朱建明 李 煦
一、引言
财务危机风险预警是一个世界性的问题和难题[1]。从20世纪30年代开始,比较有影响的财务预警方法已经有十几种,但这些方法在经济危机中能够真正预测企业财务风险的很少,还没有查到这方面的有力证据。究其原因,大多数模型中,财务指标是主要的预测依据。但财务指标往往只是财务发生危机的一种表现形式,甚至还有滞后反应性、不完全性和主观性[2]。更为严重的是在基于财务指标预警模型建立过程中,学者们往往都假设财务数据是真实可靠的,但这种假设忽略了财务预警活动的社会学规律,为财务预警模型与现实应用的脱节埋下了伏笔。许多学者建立了结合非财务指标的模型,但所加入的能够起到作用的非财务指标都是依靠试错方法引入的,即都是在危机发生之后,才能够使指标得以确认以及引入模型,下一次经济危机的类型不同,之前建立的财务预警模型便会无法预测甚至可能发生误导。因此靠试错引入的非财务指标具有一定的片面性,忽视了这些指标间的相互作用和相互关系,无法顾及这些指标是否对所有企业具有普遍适用性。
个人网上搜索、发布或者关注行为,以及各种论坛、博客、媒体发布的企业相关信息往往在不经意间透露了一些企业真实的管理状态和走势信息,而且涵盖的范围非常广泛。根据大数据的思维范式[3],可否把这些信息,通过大数据的处理技术量化后引入到财务风险预警模型当中?基于大数据的财务风险模型是否能够在稳定性、有效性等方面具有一定的改善?这些问题的本质将是当前大数据技术破解财务风险预警难题的一个重要契机。
二、理论基础、文献回顾
风险理论认为,经济活动之所以存在风险,原因在于经济环境存在不确定性。在财务危机预警过程中,为了更准确地预测企业的财务风险,有效的途径就是尽可能寻找全面的可以反映企业自身状况和所处经济环境的指标。
目前主流的财务预警研究方法依然是用财务指标构建模型。“几乎所有的研究都集中于寻找最佳的公开财务指标来预测财务危机”[4]。基于财务指标建模的支持者往往利用实证研究能够得出较高的判别率。如Altman在样本公司破产前一年预测准确率是95%[5],Deakin的准确率为97%等等。由于财务信息存在滞后性、灰色性和短期性等明显缺点,许多学者已经认识到根据财务指标预测财务风险的局限。Johnson针对Altman的论文使用的预测方法指出:即使比率确实能够提供目前企业状态的信息,它们也并不包含企业的替代战略以及管理层和投资者面临的经济状况,比如企业合并和推迟付款[6]。Ohlson将国民生产总值、价格指数引入了财务风险预测模型中[7]。EllMoumi等研究发现,企业董事会的结构和构成可以用于解释财务危机的发生[8]。Campbell等发现低股票收益率和高股票波动率将增大企业的财务风险[9]。这些研究都各自证明了所提出非财务变量的预警有效性,但在具体操作中,数据的获取难度限制了非财务指标在财务预警方面的系统研究,提出的变量没有统一的标准,也没有考虑变量之外的影响因素,反映不出企业对某一非财务指标敏感程度。企业危机发生后,发现最终导致预警失败的,往往是研究者们未曾考虑过的因素。同时,多数研究者更关注危机发生的根源,以求毕其功于一役,却忽略了财务预警这一行为本身的社会性。简单认为明确了危机发生的原因,就可以进行准确的预测,事实上财务危机每次发生的原因都在变化。奥斯特罗姆的研究指出,信任、声誉与互惠机制来自于人际网络[10]。企业危机的发生,起源于企业所有的相关人在社会网络中的相互作用。大数据技术的出现,使从社会网络角度获得关注会计主体更多一些的细节信息成为可能。所谓大数据:一般认为具有4V特征的数据可以称之为大数据,如果从广义的角度拓展,其实大数据是一种思维范式。
维克托·迈尔-舍恩伯格认为,大数据在分析过程中需要全部数据样本而不是抽样[11],目标上关注相关性而不是因果关系。人机互动产生的数据是大数据最主要的来源。这些人们在互联网世界里留下的各种“数据足迹”,并不是有意识地留下的数据,而是机器之间相互处理交互时沉淀下来的数据,从社会学角度来看,获得的数据无意识性越强,或者说人为主观参与度越小,这种数据就越客观,也越接近事物的本质,危机的爆发总是具有出乎意料的特征,具备更强无意识度的信息对危机的预测具有更重要的意义。
目前利用从互联网获得的大数据进行研究,一般从分析群体情绪和网民行为规律来实现。对网络上公众的情绪进行分析是一项高难度工程,国外在相关方面取得了一系列进展,美国印第安纳大学的约翰·博伦(Johan Bollen)等人对Twitter进行研究,将实验中获得的“冷静”情绪指数后移3天,可以和道琼斯指数获得惊人的一致。同时该研究还测试了一个基于自组织模糊神经网络的股市预测模型,当模型仅输入股市数据时,模型可以达到73.3%的准确率,而在加入“冷静”的情感信息后,准确率明显上升至86.7%。麻省理工的张雪等人,根据情绪词将推文标定为正面或负面情绪[12]。结果发现,无论是如“希望”的正面情绪,或是“害怕”、“担心”的负面情绪,其占总推文数的比例,都预示着道琼斯指数、标准普尔500指数、纳斯达克指数的下跌。美国佩斯大学的亚瑟·奥康纳,发现Facebook上的粉丝数、Twitter上的听众数和Youtude上的观看人数,都和股价密切相关。品牌的受欢迎程度,还能预测股价在10天、30天之后的上涨情况①New study finds link between social media popularity and stock prices http://www.famecount.com/news/new-study-finds-link-between-social-mediapopularity-and-stock-prices-242652.。Tobias Preis等人研究发现,当特定的关键词在某一时间内被大量搜索时,在股票市场上可能有买入或者卖出的行为发生[13]。
三、基于大数据的企业危机预警模型
从在线信息获取的企业相关大数据,其内容可以包含导致企业财务危机方方面面的因素,甚至包含人们尚未认识到的危机根源。大数据体现了群体智慧的特征,有价值的信息密度非常低,这使一些人为的修改在群体行为的均衡下,信息的价值往往不受太大的影响,可以避免仅依靠信息提供者而受到蒙蔽的现象。大数据信息比以往通过公司公告、调查、谈话等方式获得的信息更为客观和全面,而且这些信息中可以囊括企业在社会网络中的嵌入性影响。
在社会环境中,企业存在的基础在于相关者的认可,这些相关者包括顾客、投资者、供应链伙伴、政府等等。考虑到企业的经营行为,或者企业关联方的动作都会使企业的相关者产生反应,进而影响到网络上的相关信息。因此本文把所有网民看作企业分布在网络上的“传感器”,这些“传感器”有的反应企业的内部运作状态,有的反应企业所处的整体市场环境,有的反应企业相关方的运行状态等等。由此构建基于大数据进行企业财务预警的模型:
大数据企业财务预警系统不排斥财务报告上的传统指标,相反,传统的财务指标应该属于大数据的一部分。互联网上网民对企业的相关行为,包含了线下的人们和企业的接触而产生对企业的反应,这些反应由于人们在社会网络中角色的不同,涵盖了诸如顾客对产品的满意度、投资方的态度、政策导向等各种可能的情况。所有这些信息通过线下向互联网映射,在互联网中通过交互作用,由网民的情绪形成了相关企业的企业网络舆情。

图1 大数据企业财务预警原理
在具体处理过程中,可以对网络舆情信息进行语义分析,通过情绪指标对舆情进行量化,形成各种行为的一个融合后的综合性指标,具体数据处理过程如图2所示。

图2 大数据企业财务预警数据处理机制
起到企业“传感器”作用的网民,由于在线下和企业有着各种各样的角色关系。这些角色和企业的相互作用会产生不同的反应,从而刺激这些角色对企业产生不同的情绪。群体的情绪通过映射到互联网,才使这些信息能够被保存下来并被我们获取,这些不同的情绪经过网络上交互过程中的聚集、排斥和融合作用,最后会产生集体智慧,这些群体智慧能反应企业的某种状态。
因此得出如下命题:
命题1:引入企业相关网络大数据信息正面情绪指标的财务风险预警模型可以提高预警的有效性。
命题2:引入企业相关网络大数据信息中性指标的财务风险预警模型可以提高预警效果。
命题3:引入企业相关网络大数据信息负面情绪指标的财务风险模型可以提高预警效果。
命题4:引入企业相关网络大数据信息正面和负面交互影响指标的财务风险模型可以提高预警效果。
命题5:引入企业相关大数据产生频次指标的财务风险预警模型可以提高预警的有效性。
四、研究样本、研究变量和研究设计
(一)研究样本
利用聚焦网络爬虫,收集了从2009年1月1日到2013年12月31日的关于60家企业的所有相关全网网络数据,包括新闻、博客、论坛等信息,经过在线过滤删重,最终获得有效信息共7 000万余条。来自网络的上市公司相关大数据主要是非结构化的文本信息,而且包含大量重复信息。为了验证大数据反映的相关情绪能够有效提高财务风险预警模型的性能,首先要把这些信息进行数值化处理,过滤掉大量无效数据,并且进行基于财经领域词典的文本情绪倾向计算。同时对相关上市公司的有效信息进行频次统计,以便验证大数据有效信息频次对财务风险预警模型的影响。考虑到不同行业的财务特征并不相同,而制造业在上市企业中所占比例最大,正常企业的数量远大于具有危机风险的企业。研究中把制造业作为模型研究的样本企业,将会使模型在实际应用中具有更好的代表性。
在沪深两市的危机企业中,危机企业的数量远远小于正常企业。如果按照资产规模1∶1配对抽样,会破坏样本的随机性,导致模型效果虚高,夸大了模型的预测精度[14],同时以资产规模为配对原则缺乏有力的理论依据,本文后面对资产规模进行检验也发现在对危机的判断中并不显著。因此本文将危机企业和正常企业按1∶2的方式进行随机抽样配比(注意不是配对)。共搜集60家企业,其中危机企业20家,正常企业40家。危机企业样本来源于2012、2013年被沪深两市特别处理的工业制造业企业,2012年危机企业11家,正常企业22家,2013年危机企业9家,正常企业18家。筛选采用的标准是:上市以来首次被处理,上市时间已经超过5年,因为连续两年亏损而被特别处理。正常企业的样本采用随机抽取,在沪深两市中上市超过5年,上市以来从未被特殊处理的工业制造业企业。样本企业的财务指标的采集和计算源自RESSET瑞斯金融研究数据库。
(二)研究变量
财务危机预警模型主要有两个核心的工作:一个是预警指标的确定;一个是预警模型算法的选择。前者是财务预警信息的深层次挖掘,后者是预警算法技术的应用,两者同时对企业财务危机预警的精度产生影响。也就是说,财务危机预警模型的效果不仅取决于模型的学习和泛化能力,也取决于选择的财务预警模型输入和输出变量。
财务风险预警理论的研究一直缺乏系统的经济理论支持,在实际预警工作中没有特别直接的理论基础。因此现阶段的预警工作多数从实际数据出发,采用经验研究的方法,用试错的方法,逐一考察变量的组合在实际样本数据中的表现,筛选出突出判别能力的变量组合来构建最终的预测模型。
财务指标方面的变量选取参考目前财务危机预警大量的研究成果,选出32个变量作为备选考察变量,如表1所示。

表1 财务指标

续前表
其中X1~X5是反映企业偿债能力的指标,X6~X12是反映企业盈利能力的指标,X13~X14是反映企业现金流量的指标,X15~X16为反映资本结构的指标,X17到X28是反映企业成长能力的指标,X29~X32是反映企业营运能力的指标。
输入变量由假设形成的5个变量结合财务指标变量构成。关于输出变量,考虑企业发生财务危机风险的界定,学者的观点并不统一,多数学者都采用将ST作为企业陷入财务危机,具有财务风险的标志。这样的界定标准符合我国的现实情况,而且便于学者间的成果相互比较,因此把ST作为模型输出变量。
(三)研究方法
研究过程分为3个部分,第一个部分,确定有效的财务变量指标,建立基于财务指标的财务危机预警模型。第二部分,加入大数据变量,考察模型在加入大数据变量的基础上对模型效果的影响,如图3所示。

图3 模型验证过程图
(四)模型的构建
构建模型前的数据处理:对引入模型的各项指标进行显著性检验和多重共线性分析。
1.财务指标的正态分布检验
在进行显著检验之前,需要考察样本的分布情况,并以此来确定使用哪种方法来进行预警指标的差异显著性检验。运用SAS软件来进行财务指标分布情况的考察。采用Shapiro-Wilk正态分布检验。Shapiro-Wilk检验适用于样本量小于2 000的正态分布检验,适用于探索连续型随机变量的分布。对选取的企业各个财务指标进行检验,结果如表2所示。

表2 正态分布检验
根据Shapiro-Wilk判定原理,多数财务指标不服从正态分布,只有X3、X4、X15、X16、X18服从正态分布。这个结果和国外对财务指标的实证研究分析结果大致相同。对不服从正态分布的财务指标的差异显著性检验要采用非参数的检验方法,而对服从正态分布的财务指标使用参数T检验方法。
2.财务指标的差异显著性检验
采用Wilcoxon rank-sum检验法,对2个独立样本进行非参数检验。找出对分辨ST公司和非ST公司没有贡献的财务指标。检验结果见表3。

表3 差异显著性检验
检验结果发现财务指标 X1、X2、X5、X8、X11、 X13、 X14、 X29、 X32的 Pr>Chi-Square都小于0.05,通过显著性检验,而其余指标因为没有通过显著性检验被剔出。
采用T检验方法,对样本进行参数检验,检验结果如表4所示。

表4 T检验
发现 X4、X15、X16的 Pr>|t|都小于0.05,通过显著性检验,而X3、X18被剔出。
其中X1、X2、X4、X5是反映企业偿债能力的指标;X8、X11是反映企业盈利能力的指标;X13、X14是反映企业现金流的指标;X15、X16是反映企业资本结构指标;X29、X32是反映企业营运能力的指标。
3.财务指标的多重共线性检验
从数据中看出有一定的多重共线性,如表5所示。

表5 多重共线性检验
存在多重共线性的模型用于预测时,往往不影响预测结果。
对大数据指标的检验,命名积极情绪指数P1,中性情绪指数P2,消极情绪指数P3,频次指数C1,交互情绪指数P1_P3。根据分布状态分别进行显著性检验,见表6。

表6 显著性检验
可以发现P1和C1显著。
从表7可以发现,样本数据中,p2,p3,p1_p3不显著。

表7 T检验
4.选用的模型
支持向量机(Support Vector Machine,SVM)是Vapnik等人在多年研究统计学习理论基础上提出的,是一种新型机器学习方法。支持向量机凭借统计学习理论,奠定了坚实的基础,其设计源于结构风险最小原则和有限样本假设,在过学习、局部收敛、高维灾难等问题方面克服了传统机器学习(如神经网络)的缺陷,支持向量机在学习能力和泛化性能方面具有不可比拟的优势。SVM分类方法基于结构风险最小化理论,在特征空间中建构最优分割超平面,使得学习器得到全局最优化,基本原理如图4。

图4 SVM超平面图
图4中黑点和白点代表两个类别样本,H表示超平面,H1,H2是平行于超平面的直线,分别表示两个类别中离超平面最近的样本。H1与H2的距离称为分类间隔(margin)。能将两个类别正确分开,并使分类间隔最大的平面即最优分类平面。SVM超平面可用方程表示为:H:ω·x+b=0,对于样本(xi,yi)i=1,2,3…,n进行最优分类超平面构造,用如下规划问题表示:

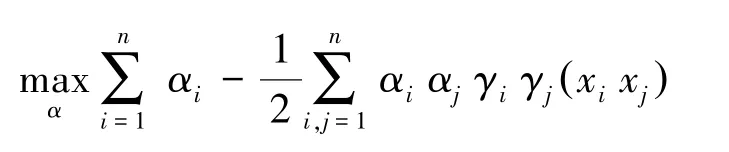

sgn(·)代表一种符号函数,b表示阈值。
线性不可分的情况,一般进行非线性变换,通过把样本转化为在高维特征空间使其线性可分。一般处理过程中采用核函数K(x,xi)来实现样本变换,引入常数C(C>0)使最优分类问题转化为二次规划问题:


在企业财务预警模型的应用中,假设预警指标有m个,即SVM的输入为m维变量,判别企业是否危机的指标为n个,即SVM的输出为n维变量。取p个企业数据作为研究总体S= {xi,yi|i=1,2,3…,p)}x∈Rm,y∈Rn。对于总体S,取出一部分作为训练数据,另一部分样本作为验证数据。因此,企业财务预警问题的本质即针对训练样本空间,寻求最优分类面,继而确定核函数和参数,从而获得问题的决策函数。该决策函数的学习能力可以通过训练数据检验,泛化预测能力一般根据验证数据检验。在复杂社会环境中,企业与利益相关者形成了复杂的社会网络,各者之间存在着各种各样的关系,企业的物流、信息流和资金流等存在不确定性,种种因素决定了企业财务危机具有复杂性的特征。所以预测上市公司财务状况模型的输入变量,与预警输出变量是非线性关系,因此引入满核函数进行非线性映射处理。通常而言,RBF核是合理的首选。这个核函数将样本非线性地映射到一个更高维的空间,与线性核不同,它能够处理分类标注和属性的非线性关系。并且,线性核是RBF的一个特例(Keerthi and Lin 2003),因此,使用一个惩罚因子C的线性核与某些参数(C,γ)的RBF核具有相同的性能。同时,Sigmoid核的表现很像一定参数的RBF核(Lin and Link 2003)。RBF函数:通过选择核函数和其他参数,经过训练得到企业财务危机预警的非线性支持向量机模型,其决策函数为:

选择SVM模型,以BP神经网络为对比对象,SVM具有一定的优势:首先,SVM无需考虑太多的参数,只有惩罚函数和核函数,而BP神经网络的控制参数较多。如隐藏层的数量、节点的数量、学习的速率等等,这些参数一般凭经验选择。获得最优预测效果的参数组合相对很困难。其次,支持向量机的学习训练,能够保证获得的全局的最优解是唯一的。而BP神经网络,训练的结果无法确保唯一性。因此在比较不同指标引入预测模型效果的时候,BP算法不易确定不同指标对结果的影响。
(五)实证研究和结果分析
为了确保模型在应用过程中有稳定的预警能力和能够满足大数据的程序处理,对SVM所选择的核函数处理非线性关系能力和SVM并行算法进行测试。
在matlab环境中构建具有非线性关系的散点如图5,其中可以看到两种类型的散点各900个,由于目标是测试核函数在支持向量机中的有效性,所以在选择散点时,无需考虑散点的具体含义,即这些散点没有具体的经济意义,但从散点分布上可以看出具备一定的非线性可区别关系。
SVM选择RBF核函数,其中C=1,sigma=0.1,对上述散点进行分类,即利用SVM对散点进行边缘划线区分,分类结果如图6所示。从图中可以直观看出,选择RBF核函数,虽然边缘附近有一些区分误差,但总体上可以对具有非线性区别关系的变量进行很好的区分,因此该核函数应该能够满足引入大数据指标的财务预警模型应用。

图5 随机散点图

图6 SVM分类结果图
将相关指标具体数值引入模型,通过SVM模型得到的结果如表8以及图7所示。

表8 效果对比情况
从图7中左图可以看出,当采用财务指标进行财务预测时,根据t-3年的数据,正常企业中有8个被误判,判正率达到63%,ST企业中有2个被误判,判正率达到81%。通过图7中右图可以看出,采用融入积极情绪的指标进行预测时,根据t-3年的数据,正常企业中有5个被误判,判正率达到77%,ST企业中有2个被误判,判正率达到81%。

图7 t-3年效果比较
从图8中左图看出,采用财务指标进行预测,根据t-2年的数据,正常企业中有2个被误判,判正率达到90%,ST企业中有1个被误判,判正率达到90%。通过图8右图可以看出,采用融入积极情绪的指标进行预测时,根据t-2年的数据,正常企业的判正率达到95%,ST企业的判正率达到90%。

图8 t-2年效果比较
虽然中性情绪、负面情绪和交互情绪指标都不显著,但有一定现实意义,因此逐个带入t-2年模型,中性情绪和负面情绪对已经加入大数据指标的模型没有影响,结果发现交互情绪对已经引入大数据指标的模型预警效果有所提高,如表9。

表9 效果对比表
从图9(详见下页)左图可以看出,正常企业的判正率达到95%,ST企业的判正率达到90%,当加入交互情绪指标后,正常企业的判正率没有变化,ST企业的判正率达到100%。大数据模型在预测有效度上有很大程度的提高,在实验样本中T-2期和T-3期的判正率均比财务指标模型要高一些。针对实验样本来说,T-3期的大数据指标引入的影响更大一些,T-2期的大数据指标引入的影响就逐渐变小。这说明,引入大数据指标的预测模型在中短期内有一定程度的提高,同时在长期预测能力方面,明显高于财务指标模型。
五、结论
本文以网民为企业传感器,利用网络在线的大数据信息,依靠大数据涵盖范围广泛、体现群体智慧和不易被修改的特点,引入了大数据指标建立财务预警模型。通过对2012、2013年60家企业进行全网信息的过滤和爬取,进行了企业相关大数据信息指标的整理,通过与财务指标的结合,对研究假设进行实际数据验证,发现引入大数据指标的财务预警模型,相对财务指标预警模型,在短期内对预测效果有一定提高,从长期来看,对预测效果有明显提高,大数据指标在误警率和漏警率上比财务指标表现明显要好,从而验证了在复杂社会环境中,依靠大数据技术加强信息搜寻是提高财务预警有效性的重要路径这一观点。

图9 t-2年含交互情绪比较
猜你喜欢
中学生数理化·高一版(2021年2期)2021-03-19
现代经济信息(2020年36期)2020-11-26
今日农业(2019年12期)2019-08-13
领导决策信息(2018年16期)2018-09-27
消费导刊(2018年8期)2018-05-25
数学学习与研究(2017年3期)2017-03-09
商(2016年32期)2016-11-24
企业技术开发·中旬刊(2016年10期)2016-11-12
火控雷达技术(2016年3期)2016-02-06
航天返回与遥感(2014年4期)2014-07-31
