
基于Top-k查询算法改进的储存与NSDL调度算法研究
2015-09-18 02:33陈钦荣刘顺来汕头职业技术学院汕头5504广州航海学院广州50000
现代计算机 2015年14期
陈钦荣,刘顺来(.汕头职业技术学院,汕头5504;.广州航海学院,广州50000)
基于Top-k查询算法改进的储存与NSDL调度算法研究
陈钦荣1,刘顺来2
(1.汕头职业技术学院,汕头515041;2.广州航海学院,广州510000)
针对Top-k查询算法的缺陷,提出一种基于磁盘存储的NSDL调度算法,并将NSDL算法扩展为近似的Top-k查询算法——ANSDL。对NSDL算法和传统DG算法进行I/O开销比较实验,从实验结果来看,NSDL算法具有更高的查询效率和查询精度,而ANSDL算法则在一定的条件下进一步提高NSDL算法的查询效率。
Top-k算法;调度策略;查询优化
1 Top-k查询算法
利用Top-k查询算法对数据集合中的记录进行检索时,不需要查询所有记录,即可获取检索结果,检索效率较高。Top-k查询算法根据返回结果的精度可以分为精确和近似Tok-k查询算法两类[1]。而根据存储结构的差异进行分类,可以将Top-k查询算法分为四类,分别为基于排序列表的Top-k算法、基于分层的Topk查询算法、基于视图的Top-k查询算法以及基于之配图的Top-k查询算法。当数据集的记录维数较高时,常用的Top-k算法的局限性会表现得十分明显,查询效率大幅度降低。以Onion为例[2],其时间复杂度为O(Nd/2),其中记录的个数为N,维数为d。可以看出,当其维数增加时,时间复杂度成指数增长状态。NRA算法的执行分为增长和收缩两个阶段,如果记录维数较高,则NRA增长阶段需要对更多的候选元组进行维护,直接影响Top-k算法的查询效率。通过对TA算法进行分析,发现TA算法在执行过程中,每对一条记录进行访问时,都需要更新门限值τ,频繁的门限值更新会浪费大量的性能。从相关的研究数据来看,TA查询算法在执行的过程中,通常已经获取到多个记录,但是由于τ的下降速度较慢,导致算法不能及时退出,仍然会继续循环搜索,浪费大量资源。在维数越高时,循环次数越多,所浪费的资源也更多,同时,多余的循环搜索还会对Top-k算法的响应时间产生较大的影响。
2 NSDL算法
基于支配图的Top-k算法提出了基于磁盘的存储和调度算法,但是该算法在很多情况下所划分的层过多,而每层中的记录较少,严重浪费内存空间的利用效率,进一步影响算法的效率[3]。针对该缺陷,本文提出了一种非严格支配的Top-k查询算法——NSDL。
2 .1NSDL算法层的定义
在NSDL算法中,以DG算法的层为基础,重新对DG算法各层之间的间距进行组织和记录。
定义记录层间距:如果DG算法中第i层用Li的形式进行表示,第j(j>1)层的记录用r进行表示。则可以利用Li以及Li与Lj层之间的层中支配记录数量来表示r与Li之间的距离。
似最大层定义:在多维空间结构中,对于一个给定的记录集合R,其生成的支配图为D。其第一个似最大层为D中第一个最大层以及与该最大层间距较小的多个记录的集合。第i个似最大层则是记录集合R-UJ=1…i-1Lj(i>1)所生成的支配图中第一个最大层以及与该最大层间距较小的多个记录的集合。
2.2存储结构设计
在NSDL算法中,利用记录的相似性特点可以增加每一层总的记录数量,但是这可能导致每一层中的记录数量过多而影响算法效率。对此,通常需要对每一层的记录数量设置一个阈值,在对记录进行分层操作的过程中,如果单层的记录数量超过所设置的阈值,则需要对该层进行分页操作,而不会对该层的空间进行扩展。这样就可以在单层记录数量过大的情况下以页为单位将单层的所有记录一次性加载到内存中。为了保证对第一层记录检索的有效性,采用排序列表的形式对第一层记录进行排序。首先给定一个查询表T,其中有N个记录,每个记录具有m个属性,这些属性分别用A1,A2,…,Am进行表示。每个列存储一个列文件Ci(ID,Ai,Li),其中的ID为记录标识号,Ai用于表示记录的第i个属性,Li则用于表示记录的i+1个属性的出现位置。当属性Ai的位置为记录的最后位置时,则Li的位置为记录第一个属性的位置。
给定一个记录集S,当该记录集中的属性数量为m时,则列文件的数量也为m,以降序方式对列文件中的数据进行排列,为了更加详细的了解记录中第一层的存储结果,下面以表3种的记录存储结果进行分析。
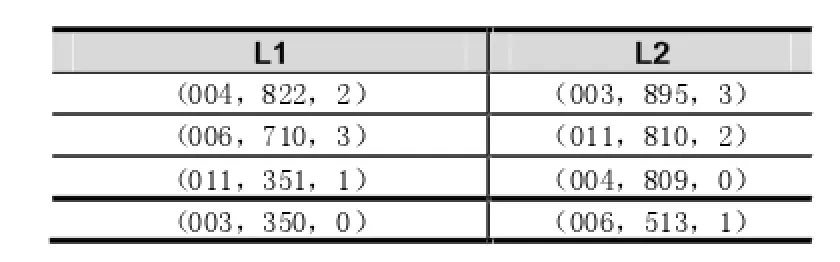
表1 NSDL第一层记录存储结果
通过记录增加下一个属性的位置,可以快速查询到第一层中的记录,通过实验来看,该存储结构大大提高了对第一层记录进行检索的效率。
2.3NSDL算法流程描述
NSDL算法以分层结构为基础,通过“似最大层”[4]的概念对每层中的记录进行分配,从而有效控制每层中记录的数量,避免传统DG算法单层记录数过大而影响算法效率的问题。NSDL算法的具体流程如下:
在算法中,以数据集的辅助表(辅助表结构如图1所示)和Top-k算法的查询数作为输入数据;以查询的结果作为输出数据。
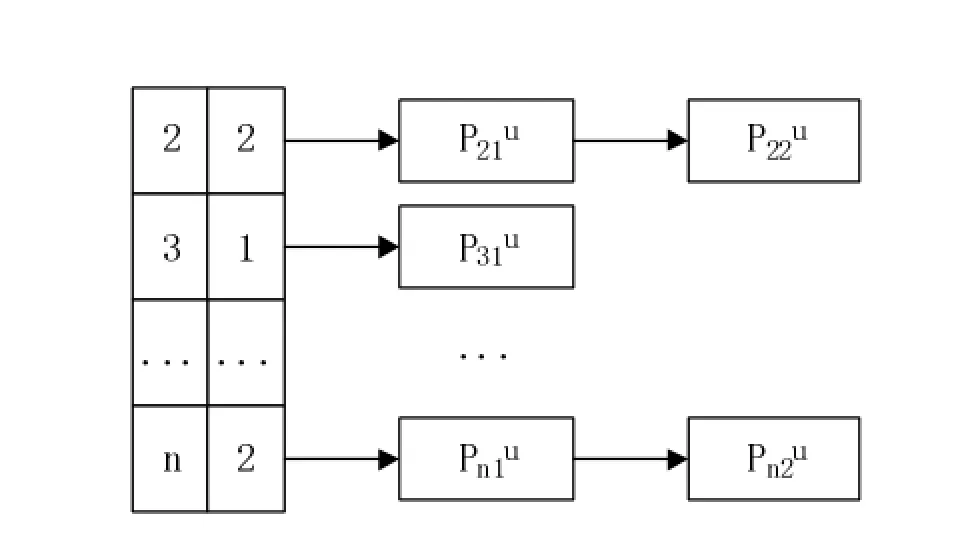
图1 AT辅助表
(1)将第一层记录加载到内存中。
(2)采用FTDT算法第一层记录进行查询,找出k个查询结果,并将所有结果按照记录分数非增长排序的方式存入到结果集RS中,同时假设RS中的最小分数为min,记录为r。
(3)设定一个标志字段flag,并对flag赋值,使得flag=true。
N=1
While flag
N=N+1;L=1;flag=false
从辅助表中取出第N层页数信息,并使number=第N层页数
While number
定义Pu为第N层第L页记录数量的上限
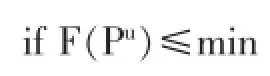
退出循环
将第N层第L页中的所有记录加载到内存中,并对所有记录进行查询,记录为c
计算c的分数f(c),if f(c)>min,则flag= true,并从RS中移除记录r,同时将记录c存入RS中,并更新min
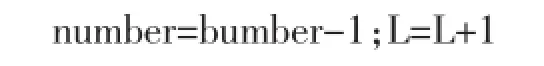
返回RS
首先,将第一层中的所有记录加载进内存,使用DG算法对内存中所加载的记录进行查询,同时找出满足设计条件的k个记录,按照非增长排序的方式将查询结果的记录分数进行排序并存入RS中。假设RS中的最小分数为min,记录为r。然后从辅助表的第N层中获取该层分页的数量number。将该层第一页的记录上限分数Pu与min进行大小比较,如果Pu<min,则说明该层中的记录都不能存入RS中,并终止算法,返回RS。如果Pu>min,则将该层第一页中所包含的记录加到到内存,对该页的所有记录c进行遍历,并计算其分数F(c),然后将F(c)与min进行大小比较,如果F(c)>min,则将记录r从RS中移除,并将c插入到RS中,更新min,同时也说明算法需要对N+1层进行查询。如果该页中的每条记录c,都满足F(c)≤min,则说明该页中的记录都无法放入RS中,继续对下一页的记录进行比较分析。如果第N层,每页中都不存在能够插入RS中的记录,则终止查询算法,并返回RS。如果第N层中有记录插入RS中,则继续对第N+1层进行访问。
2.4NSDL执行效率分析
在NSDL算法中,CPU时间和I/O调用时间同时构成了响应Top-k查询的时间[5]。
CPU时间定义:利用NSDL查询出Top-k结果集需要处理的记录条数计算CPU时间。
I/O时间定义:利用NSDL查询出Top-k结果集的I/O调用次数计算I/O时间。
如果利用NSDL_TotalCost(k)来表示NSDL算法查询出最终k个记录所花费的时间,则NSDL_TotalCost(k)=CPU_Cost*Tcpu+IO_Cost*Ti。
其中,Tcpu用于表示平均处理每条记录所占用的CPU时间,Tio表示每次调用I/O所消耗的平均时间,CPU_Cost和IO_Cost则分别用于表示处理记录的数量以及I/O调用的次数。
在NSDL算法中,每层和每页的记录数是影响算法效率的最主要因素,这两个因素会直接影响I/O调用的次数。因此,针对不同的实验环境,需要对这两个因素设置不同的值。NSDL算法中最好的情况是在第一层结构中直接检索到结果,同时第二层第一页的记录分数上限小于min。此时,算法在执行的过程中,只需要调用第一层记录,I/O调用次数最少;而当算法在访问到第i层时,该层中某一页或者某几页中存在记录被插入到记录集中,则需要对AT表进行查询,如果第i+1层中仍然存在有效记录,则需要继续进行访问,直到i+ 1层中的记录均无法满足条件,才能终止算法,这时I/O的调用次数达到最大,算法的效率也降到最低。
2.5近似NSDL算法----ANSDL
在大多数情况下,精确的Top-k检索过程需要花费较长的时间,查询的代价也很高,尤其是在高维海量数据的查询中,这种时间花费会表现得更加明显。另外,用户所使用的聚合函数通常难以清楚地表达出具体的检索要求,例如用户在利用搜索引擎检索网页的过程中,有时所得到的结果并非用户最满意的网页。而在部分情况下,用户对检索性能具有极高的要求,而对结果的精确性的要求则一般,因此,就产生了近似的Top-k检索。
通过前文的分析发现,当k值较小时,NSDL算法只需要对第一层进行遍历即可得到查询结果。因此,提出了一种近似的Top-k查询算法——ANSDL算法,该算法主要是通过NSDL算法存储结构第一层的记录集响应Top-k查询,可以将其查询结果近似作为对整个记录集的Top-k查询结果。
(1)ANSDL算法描述
ANSDL算法是在NSDL的基础上进行扩展所实现的一种算法,因此与NSDL算法的分层结构相同。ANSDL算法中,将关于数据集上的辅助表以及Top-k的查询数作为输入数据,并输出查询结果。
NSDL算法对层进行划分的思想是基于Skyline算法的,对于Top-k查询,响应查询结果的记录必然在第一层中。利用记录层间距扩展第一层的记录,使记录集一次性全部加载到内存中。ANSDL算法主要是对第一层的记录进行Top-k查询,并将查询结果近似作为整体数据集的Top-k的查询结果。通过分析发现,当k值越小时,算法的精度越高,其属于基抽样的近似Top-k查询算法,算法的精度主要受到样本容量以及k值的影响。
3 NSDL算法效率比较实验
3.1实验环境搭建
NSDL算法和DG算法均通过C#语言实现[6],开发平台为Microsoft Visual Studio 2012。运行主机配置:Intel 4核处理器,主频2.5GHz,内存4GB,Windows 7 64位旗舰版操作系统。实验从68维USCensus记录集中取前5维不同的记录组合成新的记录集,然后从USCensus记录集中取出不同的5维记录插入到新记录集,使新记录集的记录数量达到40万条。
3.2NSDL算法与DG算法I/O调用次数比较分析
在采用DG算法进行查询时,记录共分为41层,在试验过程中,NSDL算法每层记录的上限控制在20000以下,因此共分为20层。图2中给出了不同k值下,NSDL算法与DG算法的I/O调用次数情况,从图中的结果来看,当检索结果k的数量不断增加时,采用NSDL算法所调用的I/O次数基本保持不变,而采用DG算法时,I/O调用次数不断增加。
3.3NSDL算法与DG算法耗时比较分析
在实验过程中,NSDL算法相对于DG算法每层中的记录数量均更少,因此忽略了CPU获取k值的时间,因此,只需要对I/O耗时进行计算。如图3所示,图中给出了不同k之下,NSDL算法与DG算法的耗时情况。从图中的数据来看,当K值较小时,DG算法具有更高的查询效率,这主要是由于NSDL算法需要消耗更长的I/O载入时间。而随着k值的不断增加,NSDL所消耗的I/O时间基本保持不变,而DG算法则需要不断消耗CPU时间,因此,当k值超过一定范围后,NSDL的查询效率会随着k值的增加不断上升。
3.4ANSDL算法的精度实验
在实验过程中,通过选择三种不同的第一层记录数量进行实验,分别将第一层的记录控制为5000条、10000条和20000条。实验结果如图4所示。
3.5NSDL算法与ANSDL算法耗时对比
NSDL算法中每次记录控制为20000条,ANSDL算法中第一层的记录控制为20000条。如图5所示,给出了两种算法的I/O调用时间。从图中的结果来看,ANSDL算法效率为NSDL算法查询效率的1倍左右。通过对图4和图5进行综合分析可以发现,在k值保持不变的情况下,ANSDL算法具有更高的查询效率,同时还保证了较高的查询精度。
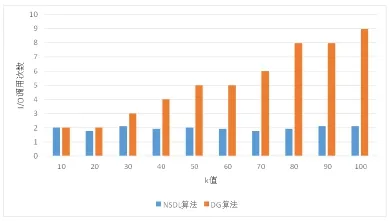
图2 不同k值下NSDL算法与DG算法I/O调用次数对比
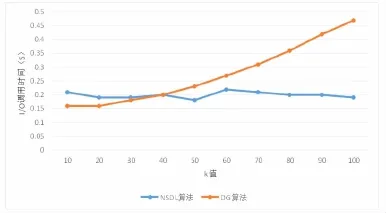
图3 不同k值条件下NSDL算法与DG算法I/O调用时间对比
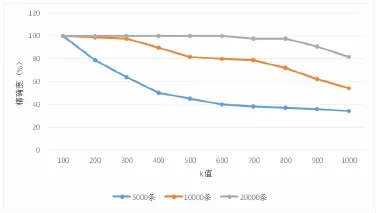
图4 ANSDL算法不同记录条数下精度随k值的变化情况
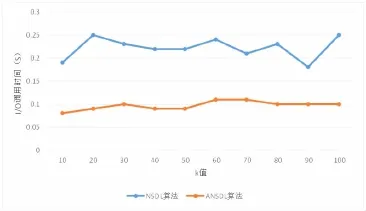
图5 NSDL算法与ANSDL算法耗时对比
4 结语
目前,常用的数据库查询优化策略和技术种类较多,Top-k算法因为其特点而被广泛应用,但是在应用过程中,存在一定的局限性。对此,本文提出了一种基于磁盘存储的调度算法NSDL,通过实验分析,NSDL因为可以忽略CPU耗时,因此,在应用过程中,具有更高的查询效率。另外在NSDL提出了近似Top-k查询算法ANSDL算法,该算法可以在一定的条件下进一步提高NSDL算法的查询效率。本文所提出的算法利用“似最大层”的概念对数据集进行分层,对每层记录进行有效的组织,并通过“辅助表”优化I/O调度,从而控制I/O调度次数,大大提高数据库的查询效率,这对相关研究工作的开展具有重要意义。
[1]李文凤,彭智勇,李德毅.不确定性Top-K查询处理[J].软件学报,2012(06):1542~1560
[2]慈祥,马友忠,孟小峰.一种云环境下的大数据Top-K查询方法[J].软件学报,2014(04):813~825
[3]韩希先,杨东华,李建中.TKEP:海量数据上一种有效的Top-K查询处理算法[J].计算机学报,2010(08):1405~1417
[4]周帆,李树全,肖春静,吴跃.不确定数据库中概率Top-k和排序查询算法[J].计算机应用,2010(10):2605~2609
[5]孙永佼,袁野,王国仁.P2P环境下面向不确定数据的Top-k查询[J].计算机学报,2011(11):2155~2164
[6]卢鑫,陈华辉,董一鸿,钱江波.MapReduce框架下的不确定数据Top-k查询计算[J].模式识别与人工智能,2013(07):695~704
Top-k Algorithm;Scheduling Policy;Query Optimization
Research on the Improved Storage and NSDL Scheduling Algorithm Based on Top-k Query Algorithms
CHEN Qin-rong1,LIU Shun-lai2
(1.Shantou Polytechnic,Shantou 515041;2.Guangzhou Maritime Institute,Guangzhou 510000)
Top-k query algorithms for its high efficiency has been widely applied,but its efficiency with the increase in size of data,shows a larger decline.Aiming at the Top-k query algorithms defects,puts a NSDL scheduling algorithm based on disk storage,and the NSDL algorithms for Top-k query algorithms that approximate,ANSDL.Compares NSDL and traditional I/O overhead DG algorithm,judges from the results,NSDL algorithms with higher efficiency and precision,and ANSDL algorithms under certain conditions to further improve the NSDL query efficiency.
1007-1423(2015)14-0028-05
10.3969/j.issn.1007-1423.2015.14.007
陈钦荣(1970-),男,广东饶平人,本科,计算机实验师,研究方向为计算机及应用技术
刘顺来(1971-),男,广东饶平人,硕士,副教授,研究方向为计算机及应用技术
2015-04-16
2015-05-10
猜你喜欢
智能建筑电气技术(2022年2期)2022-02-06
商用汽车(2021年4期)2021-10-13
数学物理学报(2020年6期)2021-01-14
商品与质量(2019年34期)2019-11-29
中学生数理化·中考版(2017年12期)2017-04-18
信息安全研究(2016年4期)2016-12-01
专利代理(2016年1期)2016-05-17
中国信息化·学术版(2013年1期)2013-05-28
质量与标准化(2010年5期)2010-05-03
质量与标准化(2010年3期)2010-05-03
