
基于PCFG模型的哈萨克语句法分析
2015-09-18 02:33:37尚文清古丽拉阿东别克于智娟新疆大学信息科学与工程学院乌鲁木齐830046国家语言资源监测与研究中心少数民族语言中心哈萨克和柯尔克孜语言基地乌鲁木齐830046
现代计算机 2015年14期
尚文清,古丽拉·阿东别克,牛 娜,于智娟(1.新疆大学信息科学与工程学院,乌鲁木齐830046;2.国家语言资源监测与研究中心少数民族语言中心哈萨克和柯尔克孜语言基地,乌鲁木齐830046)
基于PCFG模型的哈萨克语句法分析
尚文清1,2,古丽拉·阿东别克1,2,牛娜1,2,于智娟1,2
(1.新疆大学信息科学与工程学院,乌鲁木齐830046;2.国家语言资源监测与研究中心少数民族语言中心哈萨克和柯尔克孜语言基地,乌鲁木齐830046)
为了实现哈萨克语的句法分析,研究概率上下无关文法,结合哈萨克语自身的语法特征得到哈萨克语的概率上下无关文法,获取哈萨克语PCFG参数,结合自底向下的Viterbi算法进行句法分析的歧义消除,进而实现一种有自学习能力的哈萨克语句法分析器,哈萨克语句子分析达到不错的效果。实验结果显示,PCFG模型可以适用于到哈萨克语的句法分析研究。
概率上下无关文法;哈萨克语;句法分析;句法树;Viterbi算法
现代哈萨克语短语识别及其语块库构建技术研究(No.61063025)、现代哈萨克语句法分析与树库构建关键技术研究(No.61063062)
0 引言
句法分析是将句子描述成分析树的一个过程,它是自然语言处理中的一个基本问题[1],如机器翻译、信息获取、自动文摘等都要依赖句法分析。从上世纪50年代开始人们对自然语言处理至今,语言的研究层次主要分为词法分析、短语分析、句法分析语义分析和语用分析,句法分析一直是自然语言研究中的阻碍。目前各种语言(如英语、汉语等)在句法分析方面都取得了很好的研究成果,句法分析的方法主要为基于规则和统计的方法。近些年,基于统计学习模型的句法分析已经是研究者们的热点[1]。
哈萨克语语言处理方面,目前已经完成了对哈萨克语的词法分析的研究、哈萨克语基本名词短语自动识别和动词短语自动识别等相关工作并且已经取得了很好的效果。哈萨克语在句法方面的工作才刚刚起步。本文首先简要介绍了PCFG(Probabilistic Context Free Grammar)模型,对模型中的三个问题进行了相应的解决;重点描述了哈萨克语的PCFG文法的获取方法、过程及对Viterbi算法过程的描述;然后通过对哈萨克语的分析结果进行分析;最后,对哈萨克语的句法分析下一步的研究方向提出了一些想法。
1 PCFG模型
1.1PCFG的原理
CFG(Context Free Grammar)是获取语言中句法规则的一种方式[2]。它包括了终结符(如)、非终结符(如NP)、开始字符(如S)、规则的产生式集合(如S→NP)。使用CFG对句子进行分析可以得到不同的分析结果。PCFG把概率引入上下文无关文法,将统计方法和规则方法进行了有效的融合,具有十分重要的意义,概率上下无关文法通过为每条产生式规则指派一个概率值,扩展了一个上下无关文法的描述体系,即A→姿,p(A→姿)并且满足ΣA→姿P(A→姿)=1。它是最简单最常用的概率语法模型[3],通过判定概率只返回一个分析结果。
1.2PCFG的三个问题
(1)对于一个语法G,句子S的分析概率为P(S,G)。P(t,G)是分析的句子S中的句法分析树t的概率,它为所有施用规则概率之积,其中t∈S。句子S的分析概率如公式(1)所示。

(2)句子S有多个分析结果,最优树的概率为P(s),使用公式(2)选择概率最大的分析树为最优树。
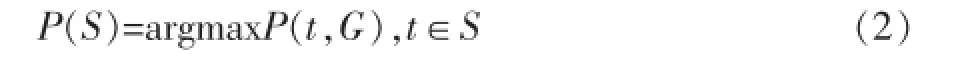
Viterbi算法[4]是使用动态规则算法找到句子中最可能的句法分析树,不管它找到多少子树,它只选择概率最大的一个。如:韦特比变量γij(A)为非终结符Α经由某一推导而产生wiwi+1…wj的最大概率,Ψ(A)为最佳推导。其中动态规则公式为:
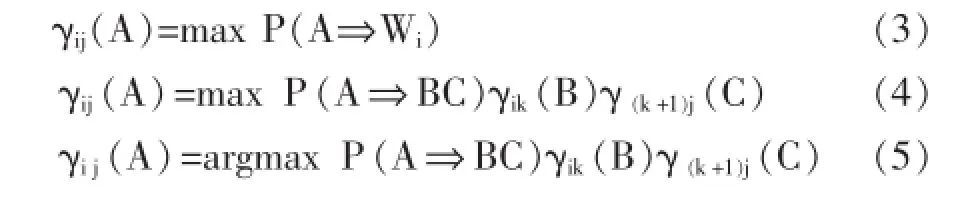
(3)一个已知的句子,语法规则的概率设定可以使用EM算法在未标注的句子上训练PCFG参数,也可以从树库中进行PCFG估计。
2 哈萨克语概率上下无关文法的获取和分析算法
从未标注句子中训练PCFG参数[5]依赖于初始设定的参数,本文使用从树库中进行PCFG估计。通过从标注好的树库中获取上下无关文法,得到一个符合哈萨克语句法的概率上下无关文法规则集[6],将规则在树库中出现的次数进行统计获取PCFG参数。将获取的参数与哈萨克语上下无关文法规则集相结合,形成初始的哈萨克语PCFG文法。
2.1PCFG概率参数的估计
模型的训练[7]是语法学习的过程,即从树库中进行PCFG参数获取。PCFG中概率的获取:如产生式A→BC的概率获取如公式(6)所示。
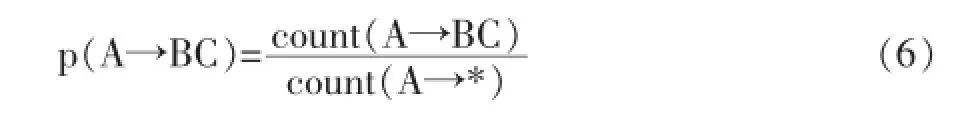
其中count(A→BC)是指产生式A→BC在树库中出现的次数。
count(A→*)是指A非终结符推出任何组合的次数。
具体的伪代码描述为:
For each tree in the Treebank
Get the context-free rules from the tree
For each(L->R)context-free of rule
Update the count of L
Update the count of(L->R)
For each(L->R)context-free of rule in the Treebank
Count(L)=the count of L!Count(L->R)=the count of(L->R)P
rob(L->R)=Count(L->R)/Count(L)
2.2规则集的自动获取
从树库中获取规则集的过程为:首先,将树库如图1(a)转换为树的形式如图1(b),然后将树的形式转为CFG规则。则训练树库中获取PCFG文法的过程的伪代码为:
For tree in treebank,parsed_sents():
Perform optional tree transformation
Correspond to the non-terminal nodes of the tree generate the productions
哈萨克语规则集的获取,首先,先将哈萨克语熟语料用相应的方法进行处理,将处理过的熟语料按照上述的方式可以直接获取文法规则;然后,将获取的文法规则用哈萨克语的反相应方法进行处理得到正确的哈萨克语的规则集;根据PCFG概率参数获取方法得到适合哈萨克语句法的PCFG文法如图1(b)。
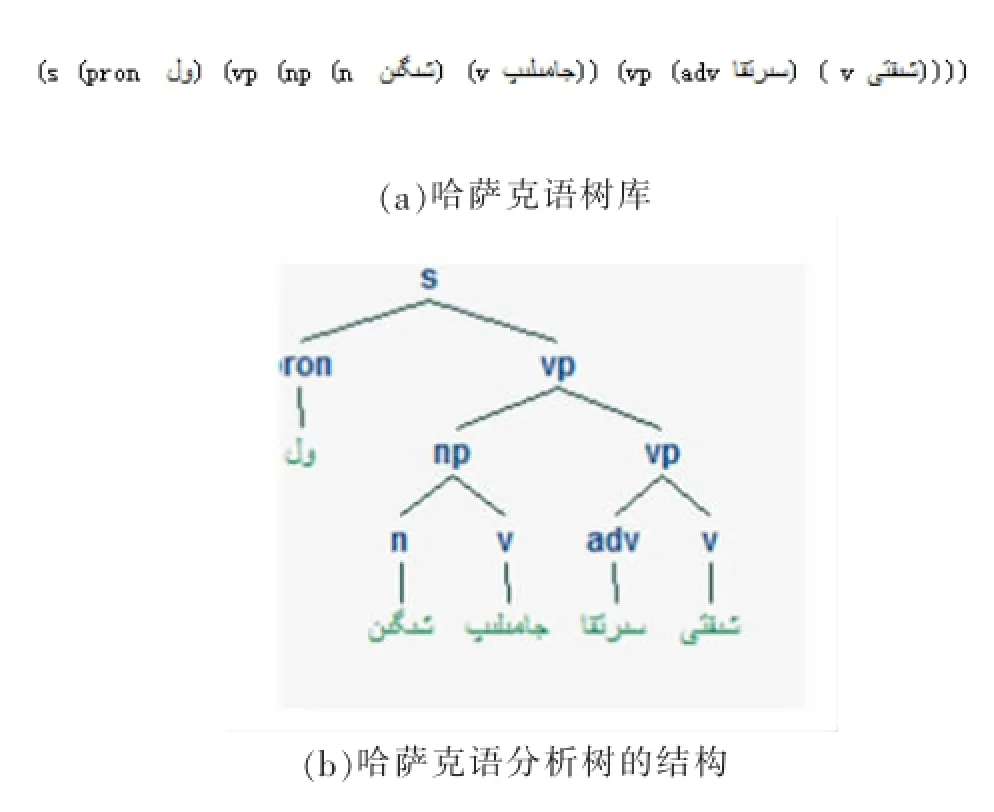

图1 哈萨克语PCFG
2.3哈萨克语PCFG句法分析器
根据哈萨克语的句法特点和标注好的树库信息,结合PCFG模型的特点,形成了一个自动学习的哈萨克语概率句法分析器。它可以根据给定的标注树库,对树库进行学习,得到一个正确的哈萨克语的概率上下无关文法,并以此作为此分析器的知识,然后利用算法对生语料进行分析,得到了较好的分析结果。其对应的结构图如图2所示。
即当训练树库如图1(a)所示。句子进行训练可以得到PCFG文法如图1(c)所示。
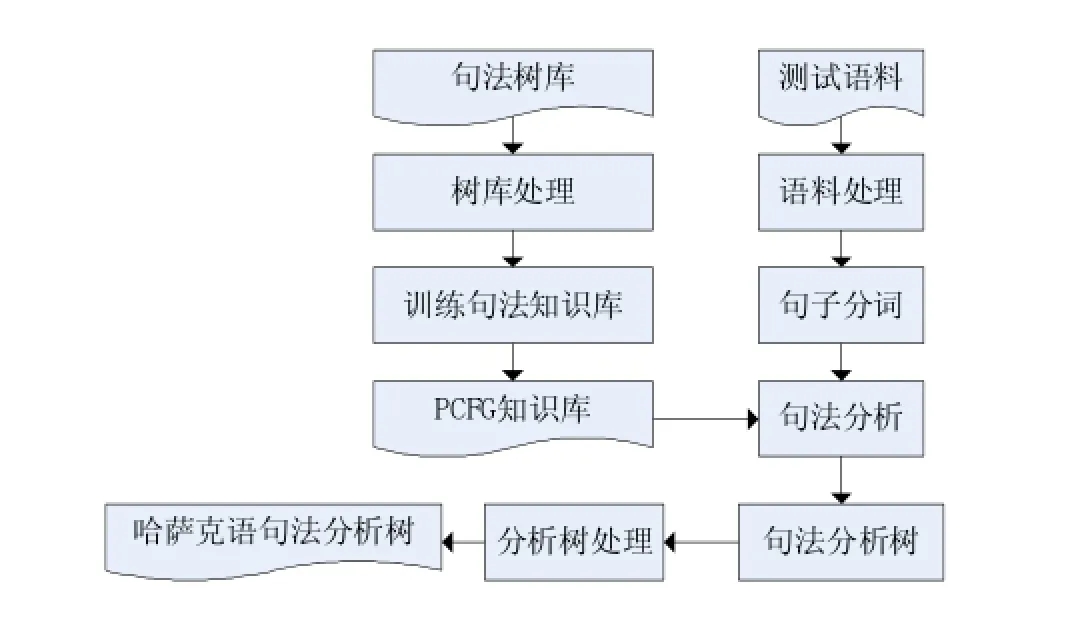
图2 哈萨克语句法分析器结构
3 实验结果
本文在Windows 7环境下使用Python语言[8]和NLTK自然语言[8]处理工具编写的哈萨克语分析器界面如图3所示。其中训练语料为如图1(a)所示的树库存放在txt文本中,测试语料如图3原始文件所示,存放在txt文本中,一句占用一行。
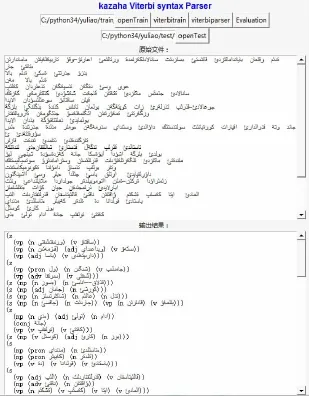
图3 哈萨克语句法分析界面

表1 哈萨克语测试结果
通过对300个哈萨克语句子进行封闭性测试,测试结果如图3输出结果所示。测试数据结果如表1所示。结果显示基于PCFG模型的哈萨克语句法分析效果很好,但也有些句子没有正确地分析成功,原因主要有:
(1)一些句子没有匹配正确的规则
(2)某些句子的顺序比较难
(3)某些句子比较长
4 结语
本文描述了基于概率上下无关文法适用于哈萨克语和NLTK自底向上的Viterbi算法分析技术。NLTK是自然语言处理工具。由于哈萨克语的句法分析刚刚起步,很多方面还不成熟,例如语料规模比较小、语料题材的选取等使得哈萨克语的句法分析器不够完善。总之,本文的哈萨克语概率分析器对一些相对简单的句子分析效果比较好,下一步,我们对基于短语结构的哈萨克语句法分析从以下几个方面改进:①训练语料的不断扩充和修改;②参数的训练;③自动获取哈萨克语的相关的结构信息,尽量提高系统的运行效率;④改进算法等方面进行探索研究。
[1]吴伟成,周俊生,曲维光.基于统计学习模型的句法分析方法综述[J].中文信息学报2013,27(3):9~19
[2]冯志伟.基于短语结构语法的自动句法分析.当代语言学2000,2(2):84~98
[3]Booth T L,Thompson R A.Applying Probabihty Measures to Abstract Languages.IEEE Tmnsactiom on Computers,1973,C-22(5):442~450
[4]D.Mckee,K.Krebsbach.A learning Natural Language Parser[J],2004.https://www2.lawrence.edu/fast/krebsbak/Research/Publications/ pdf/mics08-mckee.pdf
[5]张瑞岭.一个上下文无关文法获取过程的设计和实现[J].软件学报,1998,9(8):601~605
[6]王鹏,戴新宇,陈家俊,王启祥.基于规则的汉语句法分析方法研究.计算机工程与应用[J],2003:29
[7]周强.汉语句法知识的自动获取研究.中国中文信息学会二十周年学术会议,2001[c]
[8]Stenven Bird,Ewan Klein Edward Loper[M].Natural Language Processing with Python.O’Reilly Media,Inc.2009:291~322
Probabilistic Context Free Grammars;Kazakh;Syntactic Parser;Syntactic Tree;Viterbi Algorithm
Syntactic Analysis of Kazakh Language Based on PCFG Model
SHANG Wen-qing1,2,Gulila·Altenbek1,2,NIU Na1,2,YU Zhi-juan1,2
(1.Department of Information Science and Engineering,Xinjiang University,Urumqi830046)(2.National Language Resource Monitoring and Research Center,Minority Language Center,Hazakh and Kirgiz Language Base,Urumqi 830046)
Introduces the work of Kazakh language in language processing,does the technology research on the construction of corpus annotation of syntax,analyzes the method to study the Kazakh syntax,and combined with the existing parsing model,it can learn that Kazakh probabilistic context free grammars from the annoted syntactic corpus,and then puts forward a self-learning Kazakh syntax parser.Experimental results show that it perform well.
1007-1423(2015)14-0007-04
10.3969/j.issn.1007-1423.2015.14.002
尚文清(1988-),女,河北衡水人,研究生硕士,研究方向为自然语言信息处理
古丽拉·阿东别克(1962-),女,新疆乌鲁木齐人,博士,博士生导师,研究方向为自然语言信息处理
牛娜(1989-),女,新疆伊犁人,研究生硕士,研究方向为自然语言信息处理
于智娟(1988-),女,新疆沙湾人,研究生硕士,研究方向为自然语言信息处理
2015-04-08
2015-05-13
猜你喜欢
西部蒙古论坛(2021年4期)2021-03-02 11:33:18
High Technology Letters(2017年2期)2017-06-27 08:09:22
海外华文教育(2016年1期)2017-01-20 08:21:58
High Technology Letters(2016年3期)2016-12-05 07:01:07
学生天地(2016年26期)2016-06-15 20:29:39
当代教育理论与实践(2015年9期)2015-12-16 16:26:05
新疆大学学报(哲学社会科学版)(2015年5期)2015-10-12 01:16:14
民族古籍研究(2014年0期)2014-10-27 08:24:34
语言与翻译(2014年2期)2014-07-12 15:49:28
语言与翻译(2014年2期)2014-07-12 15:49:13
