
概率数据库研究问题综述
2015-09-18 01:22王雅瑜工业和信息化部电子第五研究所软件质量工程研究中心广州510610
现代计算机 2015年15期
王雅瑜,熊 婧,林 军(工业和信息化部电子第五研究所软件质量工程研究中心,广州510610)
概率数据库研究问题综述
王雅瑜,熊婧,林军
(工业和信息化部电子第五研究所软件质量工程研究中心,广州510610)
概率数据库的管理,在不确定数据处理需求与日俱增的今天变得极为重要。一个概率数据库管理系统,是一个能够存储大量概率数据并提供复杂查询方法的数据库管理系统,而且要能对概率计算进行处理。在PRM模型的基础上,根据现阶段研究概况,给出由对象属性、静态属性、动态属性、概率属性组合而成的概率数据库模型;针对概率数据处理的应用需求,论述查询计算及查询排序的方法及其特点,以及概率数据库中安全问题的处理方法。
概率数据库;概率数据库管理;不确定数据;查询计算;查询排序
2012“核高基”科技专项(No.2012ZX01045-006-003)
0 引言
最近几年,在很多新兴的数据应用中,对不确定数据的处理需求与日俱增。不确定数据来源很广:传感数据处理、科学计算、数据综合与清理[1]、信息提取[2]、自然语言分析、图像识别、数据录入偏差等。传统的数据库管理系统操作的数据对象都是确定的,完整的,对这一类不确定数据缺乏处理方法。而用户们需要对它们分析、整理,从而找到自己需要的结果。近年来,研究者们对相关的问题做了许多工作,提出了概率数据库的概念,以解决对不确定数据的处理。本文对这些工作进行了分析和总结,阐述了概率数据库中的几个关键问题及研究方法。
1 概率数据库的基本概念
1.1概率数据库的概念与应用
概率数据库是根据不确定数据处理的需要而提出的。然而,对不确定或不完整数据的处理在上世纪八、九十年代就已有研究。Immelinski等在文献[3]中提出了c-table这一形式来表示一个不完整的数据库;Barbara等在文献[4]中用概率理论提出了关系模式的扩展,重新定义了投影、选择、等操作,对概率数据提出了一个描述模型;Shashi K.Gadia等在文献[5]中给出了一个包含完整信息的临时数据库模型,在此基础上又给出了包含不完整信息的临时数据库模型,并研究了相关的查询代数;等等。其中一些对不确定数据的处理方法、理论仍旧是现今研究的基础。
N.Dalvi等在文献[6]中对概率数据库管理系统做了以下定义:一个概率数据库管理系统,是一个能够存储大量概率数据并提供复杂查询方法的数据库管理系统,而且要能对概率计算处理。文章还指出,概率数据库管理系统也可包含更新、恢复等功能,不过这些功能与传统数据库并无不同,主要的难点在查询上。许多在概率数据库方面的研究也着力于top-k查询的处理[7],出现了多种不确定性top-k查询的语义和处理方法。
概率数据的应用来源主要分为两大类。一类是本身不可避免的模糊的、不确定的数据的应用。例如传感器传送的数据、测量误差、移动设备的数据噪声、网络延时造成的影响、图像的识别、文本的信息提取、数据更新不一致带来的数据冲突、歧义等。另一类不确定数据应用的产生是人为的、出于特定需要的考虑。例如牵涉个人隐私保护的应用中,可以通过不确定数据隐藏一些敏感信息[8];一些数据清理应用中,可以通过保留不确定数据来提高效率;对不确定数据的计算结果也会成为不确定数据的来源,等等。
1.2概率数据库的主要研究问题
N.Dalvi等在文献[6]中指出了概率数据库研究的三个重要方面:怎样存储或表达一个概率数据库;怎样用这样的表示去响应查询;怎样将查询结果返回给用户。后两个主要是对查询的处理方法的研究,是近年来研究的重点。另外,Christoph Koch等在文献[9]中研究了有效计算可信度并对概率数据进行条件过滤的方法。Vibhor Rastogi等在文献[10]中研究了对不确定数据实施访问控制的方法。Qin Zhang等在文献[11]中分别对静态的和动态的不确定数据给出了计算高频记录的算法。Saket Sathe等在文献[12]中研究了为不确定的时间序列创建概率数据库的方法。Jianwen Chen等在文献[13]研究概率数据库的集合运算结果概率计算的精确方法和近似方法。Christopher R'e在文献[14]总结了通过Top-k查询以及聚集计算、物化视图等方法对大规模不确定数据的处理方法。
本文将目前对概率数据库的研究大致概括为三方面:①概率数据库的表示;②概率数据库中查询的处理;③概率数据库的安全问题。下面将对这三方面问题分别阐述。
1.3一个具体实例
为了方便问题的说明,本文给出一个学生管理的实例。如表1,是一个学生-班级表。表中,学生Li Lei、Han Meimei所在班级不唯一,这在实际情况中是不可能的。造成这种结果的原因可能是数据录入时的输入模糊,或者数据更新不一致导致的数据冲突等。表中第三列概率p,是对数据不确定度的一种表示,来源于得到数据的工具。为了简化问题,本文假定表中两个人的记录之间是相互独立的。
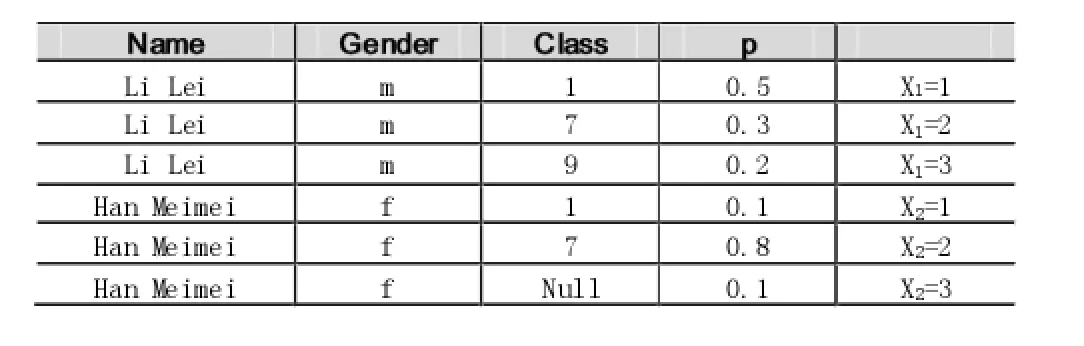
表1 概率数据库学生-班级表a
2 概率数据库的表示
传统的关系数据库处理不了包含概率的数据,因此要对数据库模型加以扩展。许多科研工作者都提出了自己对概率关系数据模型的描述。目前,普遍被认可的概率关系模型有两种——BGP框架和DS框架,金宗安在文献[15]中大致总结了这两个模型的优缺点。Debabrata Dey和Sumit Sarkar提出了PRM[16]模型(Probabilistic Relational Model),该模型在数据库的每个元组中引入概率标记属性表示元组的不确定性。本文在该模型基础上,总结现阶段研究概况,给出以下概率数据库模型。
一个概率关系模式R{A1,A2,…,An}由对象属性K、静态属性S、动态属性T、概率属性P组合而成。对象属性是一个对象或事件的标识,静态属性是伴随该对象存在的相对稳定的特性,动态属性是在该对象存在的情况下,具有多种可能性的属性,概率属性则描述了这种可能性,取值范围(0,1]。概率关系模式R{A1,A2,…,An}上每一属性的取值范围称为属性域,记为dom(Ai),模式上属性域中值的笛卡尔积称为关系模式R上的值域,记为dom(R)=dom(A1)×dom(A2)×…×dom(An)。关系模式R上的一个元组t就是从模式R到值域上的一个映射t:R→dom(R)。
如表1,对象属性是Name,静态属性是Gender,动态属性是Class,概率属性是p。这种概率关系模式是对传统关系模式的属性进行了区分,并增加了概率属性的概念。形式上它类似传统关系模式,一个元组也是二维表中的一行,本质上它描述某事件发生的概率。传统数据库模型中,一条元组即可代表现实世界的一个对象(记录);而在概率数据库模型中,一条元组也许只是一个对象的一种可能表示,一个对象可能需要几个元组来表示其各种取值的联合概率分布。
表1中,Li Lei和Han Meimei的记录是相互独立的,而Li Lei记录包含的三条元组是互斥关系。N.Dalvi等在文献[6]中把包含这样的表的概率数据库称为BID (Block Independent-Disjoint)。即所有的元组可以划分成几块,每块里的元组互斥,不同块的元组相互独立。
比起传统数据库模型中的关系运算,概率数据库模型中的关系运算也有所改动。例如当对元组进行合并或投影操作时,根据元组之间关系的不同,需采取不同的规则。对于互斥的多个元组,进行投影操作时,使用的是互斥事件的概率计算公式p=p1+p2+…+pn;对于相互独立的多个元组,进行投影操作时,使用的是相互独立事件的概率计算公式p=1-(1-p1)(1-p2)…(1-pn)。当在投影操作过程中,既有互斥元组,也有相互独立元组,则要先对互斥元组进行合并,再对相互独立的元组合并。例如表1,如果Class定为7,要对Class属性投影,则相应的概率p=1-(1-0.3)(1-0.8)=0.86。
表1的学生-班级表中还有一个属性,形如Xi=j,这样的表示叫做lineage,是指对一个元组所加的注释。Immelinski等在文献[3]中提出了c-table这一形式来表示一个不确定数据库。在c-table中,一个元组由这样的属性经过布尔运算表示。例如表1,若要对Class属性投影,采用c-table的表示如表2。

表2 采用c-table表示C lass上的投影
使用lineage既可以表示概率数据,也可以表示查询结果[6]。对c-table的一个查询结果仍旧可以用ctable和相应的属性表示,易于理解和处理。而且,通过它可以将用户对查询结果的反馈跟踪到原数据。因此,在概率数据库中,lineage有很重要的作用。
3 概率数据库的查询
概率数据库管理系统需要提供复杂的、强大的概率数据处理能力以满足应用需求。其中的研究重点在查询的处理上。因为传统的数据库运算,如选择、投影、连接等无法处理包含概率的数据;而在更新、删除等操作上,概率数据库与传统数据库并无很大差别。
由于自身特点,概率数据库的查询主要包含两个问题:①查询计算的处理;②查询结果的处理。
3.1查询计算
一般,对概率数据的查询计算有两个逻辑步骤:首先获得数据并做相应转换,其次采用概率算法对数据做概率推演。简单的方法是使用数据库引擎做第一步,使用概率推演技术做第二步。研究工作者们提出了许多算法做这样的处理。还有一种方法是将这两个步骤合起来放在数据库中处理。这样的优点在于可以使用数据库本身的机制和技术处理数据,简化了概率推演的复杂度,尤其在需要对数据进行聚集处理时。但后者需要查询语句本身是“安全”的才能完成[6]。
安全查询是指能够将全部概率推演放到查询计划中处理的查询;相应的,安全计划是指能够使用扩展的概率关系代数处理概率计算,进而处理查询的计划。表3所示为与表1对应的学生-成绩表。对于一个查询“SELECT a.Class,Confidence()FROM a,b WHERE a. Name=b.Name and b.Subject='English'and a.Class=7”,如果执行计划的关系代数是πClass(σClass='7'(a▷◁πName(σSubject='English'(b)))),则计算的概率结果是1-(1-p2q1)(1-p2q2);如果执行计划的关系代数是,则计算的概率结果是p2(1-(1-q1)(1-q2))。在传统数据库中,两种执行计划的结果应该是等效的,差别只在于是否先对b表做Name上的投影。而如果采用上文提到的c-table表示这样的查询,则相应的lineage应当是(X1=2/Y1=1)/(X1=2/Y1=2),因此正确的执行计划是后一种,即概率结果应当是p2(1-(1-q1)(1-q2))。造成这种差别的原因是表3中的前两个元组并非相互独立,而连接操作对这样的情况无法正确计算。可见,对同一查询语句的不同执行计划在计算概率上有可能不同。N.Dalvi等在文献[6]中对这个问题有更详尽的描述。
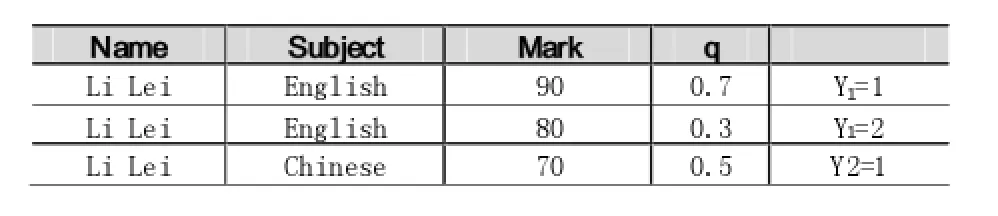
表3 概率数据库学生-成绩表b
聚集查询在数据统计中有很广泛的应用。在概率数据库中,聚集查询需要考虑对象的每一种可能性。如果查询元组有N个,那么聚集查询的结果有可能到2N个,尤其在非安全查询中,计算十分困难。研究工作者们提出了各种方法处理概率数据库中类似的大计算量的问题。有的工作对聚集函数进行改造;有的工作在查询中设置了相关参数;有的工作采用实体化视图将非安全查询转化为对安全查询的处理,等等。
概率数据的查询中,经过大量复杂计算产生的结果有时并非对所有用户都很有意义,这样既耗费资源,又无法让用户满意。因此需要对查询结果排序、过滤。
3.2查询排序
由于概率数据库处理对象的模糊特性,不同用户对查询结果的需求也不同。怎样和用户交互,返回最合适的查询结果,是一个难题,也是目前研究的热点。
常用的一种方法是将查询结果按照一定的标准排序,只返回k个排序靠前的元组给用户,这一般被称作Top-k查询问题。这一方法降低了查询计算的复杂度,提高了查询性能。在传统数据库中也有广泛应用。然而在概率数据库中,数据的不确定性、用户的不同要求,使得使用什么样的排序标准成了一个问题。例如,可以返回k个具有最高分值的元组,或者k个概率最大的元组,或者k个最小期望排序的元组,等等。具体使用哪种排序方法要根据实际需求决定。现今的许多工作针对不同情况提出了各种排序算法。Christopher等在计算Top-k时,主要使用的方法是同时并列使用多个Monte-Carlo模拟算法[17];Ming Hua等提出了一个基于泊松估计的算法,通过设定概率的阈值返回不确定数据的Top-k查询结果[18];Dylla M等提供了一种通过计算条件概率的边界值来获得top-k查询结果的算法[19]。
Jian Li等在文献[20]中提出了一个统一的Top-k查询排序方法。它将该问题看作一个多标准的最优化问题,认为一个单独的排序函数无法满足概率数据库的需要,提出了两个带参数的函数PRFW和PRFE来模拟已有的排序函数。文中首先根据概率数据库的模型,对数据库定义了一系列能够指示排序结果的关键属性(即元组排列在某位的概率);然后在已有的一些概率数据排序函数的基础上,根据关键属性定义了两个带参数的排序函数PRFW和PRFE;函数的参数可以通过在小数据集上对用户需求的排序而学习得到;这两个函数包含了现有的一些排序函数,也可以模拟一些其他排序函数;文章还设计了一个根据这些排序函数找到Top-k查询结果的有效算法。与其他类似工作相比,该方法有一定的普适性,并且能够与用户交互。
4 概率数据库的安全
数据库安全是指数据库的信息不受恶意侵害或未经授权的访问和修改。其内涵包括三方面:保密性、完整性、可用性。对传统数据库管理系统的安全性研究已经比较成熟,身份鉴别、访问控制、数据加密、审计等机制都可以保障数据库安全。而对概率数据库的安全性研究则刚开始。下面以自主访问控制为例说明概率数据库中的安全问题。
传统数据库中,用户的自主访问权限一般通过访问控制矩阵表示。假设数据库中的访问只有“读”,矩阵元素M[si,oj]=1,表示用户si对对象oj有读权限;M[si,oj] =0,表示用户si没有oj的读权限。但是,在概率数据库中,数据对象本身就是不确定的、以概率的形式表示的,因此对其权限的控制也无法轻易地用0或1决策,而要用概率代替。例如对本文的学生管理例子,加入教师元素,同时有这样的访问控制策略:教师只能查看自己班级学生的成绩,那么7班的教师能不能查询Li Lei的成绩?下面假设教师能查询Li Lei成绩的概率为p,最终查询的结果为r。
一种方法是设置一个阈值b(0≤b≤1),如果p≥b,则r=pt(pt为查询对象t的概率,这里理解对对象的查询即是对其概率的查询),如果p<b,则r=deny。该方法实施简单,缺点在于阈值b的选取很关键,对于不同应用可能有不同要求,很难制定统一标准。
还有一种方法是抽样。该方法类似于随机掷骰子,骰子为p的概率为1,(1-p)的概率为0。若结果为1,r= pt,反之r=deny。掷骰子的时机是用户做一系列的查询前,而并非对每一个查询,这是为了防止攻击者通过多次重复查询推算出概率值。该方法有可能导致系统漏洞。即使用户能够访问某数据的概率很低,在此方法下仍有可能执行访问。
Vibhor Rastogi等通过对结果加入随机噪声的方法来实现概率数据的访问控制[21]。用户对对象t的访问结果r=pt+n,其中n是噪声,其选择由关于p的函数决定。当p=1时,n为0;当p=0时,n是一个使得r成为与pt无关的随机噪声的值,即表示deny。该方法稍复杂,但是不论p为多少,都能给用户一个返回值,较平滑地实现了对概率数据的访问控制。
概率数据库安全性的研究还包括数据加密、推理控制、隐通道判断等,但相关文献很少,研究工作也不成熟。
5 结语
随着概率数据的应用日益广泛,对概率数据库的研究也步步深入。本文大致介绍了概率数据库的概念与应用,对概率数据库的表示、查询、安全三方面内容及现阶段的研究方法做了较细致的阐述。
作为近年来新兴的研究,概率数据库中的许多问题还没有得到很好的解决。例如对概率数据库的关系运算的扩展还不够完备、概率数据库的安全问题还没有得到足够的重视、目前尚没有一个完备的形式化的模型来描述概率数据库,等等。这些都有待学者们更深一步的研究。
[1]Cuzzocrea A.Approximate OLAP Query Processing Over Uncertain and Imprecise Multidimensional Data Streams[C].Database and Expert Systems Applications.Springer Berlin Heidelberg,2013:156~173
[2]Dylla M,Theobald M.Learning Tuple Probabilities in Probabilistic Databases[J],2014
[3]T.Im ielinskiand W.Lipski.Incomplete Information in Relational Databases.Journal of the ACM,31:761~791,October 1984
[4]D.Barbara,H.Garcia-Molina,D.Porter.The Managementof Probabilistic Data.IEEE Transaction of Knowledge and Data Engineering.4(5):487~502,1992
[5]Shashi K.Gadia,Sunil S.Nair,Yiu-Cheong Poon.Incomplete Information in Relational Temporal Databases.VLDB,1992
[6]N.Dalvi,C.Re and D.Suciu.Probabilistic Databases:Diamonds in the Dirt.CACM 52(7):86~94,2009
[7]李文凤,彭智勇,李德毅.不确定性Top-K查询处理[J].软件学报,2012,23(6):1542~1560
[8]Hamm J.Preserving Privacy of Continuous High-Dimensional Data with Minimax Filters[J],2015
[9]Christoph Koch,Dan Olteanu.Conditioning Probabilistic Database.VLDB,2008
[10]Vibhor Rastogi,Dan Suciu,EvanWelbourne.Access Control over Uncertain Data.VLDB,2008
[11]Qin Zhang,Feifei Li,Ke Yi.Finding Frequent Items in Probabilistic Data.SIGMOD,2008
[12]Sathe S,Jeung H,Aberer K.Creating Probabilistic Databases from Imprecise Time-Series Data[C].Data Engineering(ICDE),2011 !IEEE 27th International Conference on.IEEE,2011:327~338
[13]Chen J,Feng L.Computing Event Probability in Probabilistic Databases[C].Intelligent Computing and Intelligent Systems(ICIS), !2010 IEEE International Conference on.IEEE,2010,3:249~253
[14]RéC.Managing Large-Scale Probabilistic Databases[D].University ofWashington,2009
[15]金宗安.概率数据库及有效查询技术的研究.硕士学位论文,2009
[16]Dey D,Sarkar S.A Probabilistic RelationalModel and Algebra.ACM Transaction on Database System,22(3):419~469,1997
[17]R'eC,N.Dalvi,D.Suciu.Efficient Top-k Query Evaluation on Probabilistic Data.ICDE,2007
[18]Ming Hua,Jian Pei,Wenjie Zhang,Xuem in Lin.Ranking Queries on Uncertain Data:A Probabilistic Threshold Approach.SIGMOD,!2008
[19]Dylla M,Miliaraki I,Theobald M.Top-k Query Processing in Probabilistic Databaseswith Non-Materialized Views[C].Data Engineering(ICDE),2013 IEEE 29th International Conference on.IEEE,2013:122~133
[20]Jian Li,Barna Saha,Amol Deshpande.A Unified Approach to Ranking in Probabilistic Database.VLDB,2009
[21]Vibhor Rastogi,Dan Suciu and Evan Welbourne.Access Control over Uncertain Data.VLDB,2008
王雅瑜(1987-),硕士研究生,助理工程师,研究方向为数据库应用、软件测试
熊婧(1985-),硕士研究生,工程师,研究方向为现代数据库理论与实现、数据库安全
林军(1976-),硕士研究生,高级工程师,研究方向为移动通信、信息安全及基础软件质量测评技术
Probabilistic Database;Probabilistic Database Management;Imprecise Data;Query Computing;Query Sorting
An Overview of Research on Probabilistic Databases
WANG Ya-yu,XIONG Jing,LIN Jun
(Software Quality Engineering Research Center,China Electronic Products Reliability and Environmental Testing Research Institute,Guangzhou 510610)
Probabilistic database management is very important while the need for processing over imprecise data is increasing.A probabilistic databasemanagement system is a databasemanagement system that can store large amountof probabilistic data,provides complex query theory and handles probability calculation.On the basis of PRM model and researches nowadays,probabilistic databasemodel which is composed of object attribute,static attribute,dynam ic attribute,proposes probabilistic attribute,for the need of probabilistic data handing,proposes themethods of query computing and query sorting and their features,and mentions the methods security of probabilistic database.
1007-1423(2015)15-0057-06
10.3969/j.issn.1007-1423.2015.15.015
2015-04-21
2015-05-05
猜你喜欢
中学生数理化·中考版(2022年6期)2022-06-05
中学生数理化·七年级数学人教版(2022年11期)2022-02-14
中学生数理化·中考版(2021年6期)2021-11-22
新世纪智能(数学备考)(2021年4期)2021-08-06
新世纪智能(数学备考)(2021年4期)2021-08-06
电脑报(2021年14期)2021-06-28
科普童话·学霸日记(2020年1期)2020-05-08
软件学报(2019年11期)2019-12-11
计算机与生活(2019年5期)2019-07-18
小天使·一年级语数英综合(2019年2期)2019-01-10
