
基于Hadoop分布式计算的图像检索方法
2015-09-11 13:11梁欣然等
电脑知识与技术 2015年17期
关键词:分布式计算
梁欣然等
摘要:针对传统单节点的基于内容的图像检索方法计算速度较慢,检索效率不高的问题,提出了一种基于Hadoop分布式计算的图像检索方法。首先提取出图像的颜色、纹理和形状特征用于表示图像,在检索阶段将检索任务分配到各个Map子节点,所有的Map结果根据相似度非减进行排序,并将前N个结果进行输出。实验结果表明,该方法有效地利用了云计算平台的并行处理能力,相比较单节点的图像检索方法,提高了CBIR方法的运行效率。
关键词:图像检索;分布式计算;Hadoop
中图分类号:TP393 文献标识码:A 文章编号:1009-3044(2015)17-0153-02
Image Retrieval Based on Hadoop Distributed Computing
LIANG Xin-ran1, LIANG Peng2, ZHOU Hai-tao1, ZHOU Jian-xiong1, ZHOU Yi-shu1, LAO Xue-li3
(1.China Mobile, South Base, Guangzhou 510640, China;2.School of Computer Science, GuangDong Polytechnic Normal University, Guangzhou 510665, China;3.Bingosoft Development Corporation Limited, Guangzhou 510663, China)
Abstract: Aiming at the problem of inefficiently of traditional content based image retrieval method, this paper proposes an image retrieval method based on hadoop distributed computing. We first extract color features, texture features and sharp features from image dataset. Then, the retrieval job will be distributed to all map services and all retrieval results will be sorted according to matching results. Finally, the first N images will be sent back to user. The experimental result shows that our proposed method can improve the computing efficiency of traditional CBIR method.
Key words: image retrieval; distributed computing; hadoop
基于内容的图像检索(CBIR)是指根据图像内容而并非文字关键词对图像进行检索的方法,并在许多领域得到了广泛的使用[1-3]。CBIR检索方法首先提取出图像数据集的特征,用图像的特征代表图像,匹配时用测试图像特征与特征数据集进行比较,最后返回匹配程度较高的部分图像。然而当图像数据集数量增大时,检索性能和速度会急剧下降,如何提高CBIR检索方法的计算速度成为了一个迫切的研究问题。
云计算是指将数据存储和检索任务分布在大量的分布式计算机上,而非本地计算机。Hadoop[6,7]是一个可扩展的分布式系统基础架构,并且对用户提供了开发接口,使得用户无需关注分布式底层的实现细节,很方便地搭建分布式计算平台;此外Hadoop技术支持在普通计算机上实现分布式计算架构,而无需服务器进行支撑,因此得到了广泛的应用[4,5,6]。
为此,本文提出基于Hadoop分布式计算的图像检索方法,利用云计算平台的并行处理能力提高CBIR方法的运行效率,实验结果表明基于Hadoop分布式计算的图像检索方法减少了检索的时间,提高了检索的效率。
1 Hadoop平台
Hadoop平台是当今使用最广泛的分布式云计算平台,主要分为HDFS、MapReduce和Hbase三部分。HDFS提供了一个可以运行在普通硬件集群上的分布式文件系统,可以存储超大文件并使用流对文件进行高速读写。HDFS是由一个NameNode主服务器和多个DataNode块服务器组成的主从结构,NameNode用于管理文件系统的命名空间以及用户对文件的读写访问,其中包括各个DataNode的新增、删除和修改;DataNode则实现了对大数据的分割和存储,此外DataNode之间的数据还会相互复制以保证数据的安全和高速读取。
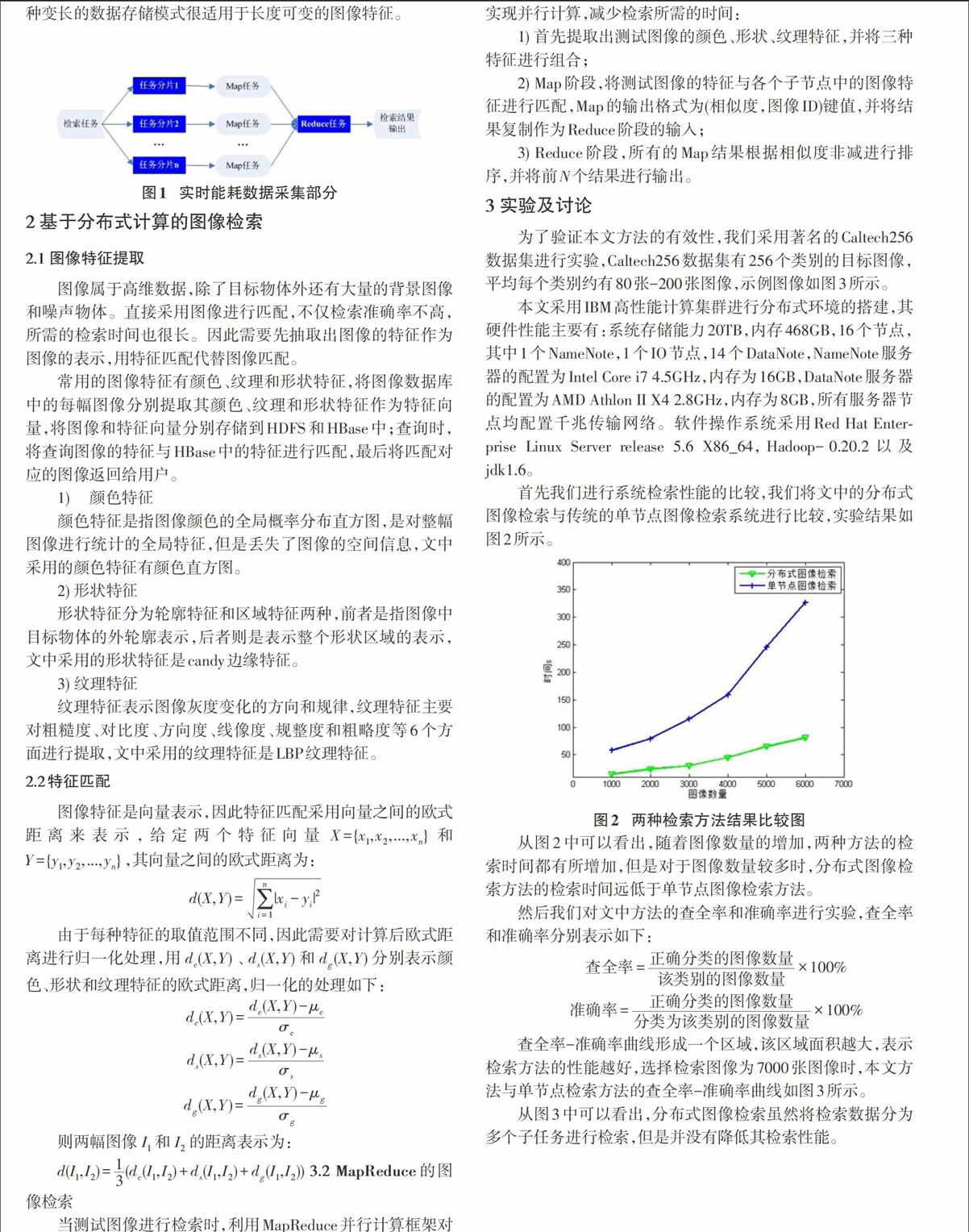
MapReduce是一个可用于大数据处理的分布式计算框架,实现了并行计算功能。研究发现,大部分的并行计算都可以分解为Map-Reduce的框架,其主要思想是将一个大数据的检索任务分割为多个子任务,系统根据不同的分配策略将子任务分配到各个节点中运行,子节点将结果返回后再进行合并处理。具体的来说,即将输入的检索请求分解为多个中间的Key/Value组合(Map),再将返回的Key/Value合成最终的用户输出(Reduce),如图1所示。
图像存储在HDFS系统中,提取的图像特征则存储在Hbase数据库中,Hbase数据库是一种非结构化数据库,数据存储以列为模式,每一个数据行可以增加任意数量的列数据,这种变长的数据存储模式很适用于长度可变的图像特征。
2 基于分布式计算的图像检索
2.1 图像特征提取
图像属于高维数据,除了目标物体外还有大量的背景图像和噪声物体。直接采用图像进行匹配,不仅检索准确率不高,所需的检索时间也很长。因此需要先抽取出图像的特征作为图像的表示,用特征匹配代替图像匹配。
常用的图像特征有颜色、纹理和形状特征,将图像数据库中的每幅图像分别提取其颜色、纹理和形状特征作为特征向量,将图像和特征向量分别存储到HDFS和HBase中;查询时,将查询图像的特征与HBase中的特征进行匹配,最后将匹配对应的图像返回给用户。
1) 颜色特征
颜色特征是指图像颜色的全局概率分布直方图,是对整幅图像进行统计的全局特征,但是丢失了图像的空间信息,文中采用的颜色特征有颜色直方图。
2) 形状特征
形状特征分为轮廓特征和区域特征两种,前者是指图像中目标物体的外轮廓表示,后者则是表示整个形状区域的表示,文中采用的形状特征是candy边缘特征。
3) 纹理特征
纹理特征表示图像灰度变化的方向和规律,纹理特征主要对粗糙度、对比度、方向度、线像度、规整度和粗略度等6个方面进行提取,文中采用的纹理特征是LBP纹理特征。
2.2特征匹配
图像特征是向量表示,因此特征匹配采用向量之间的欧式距离来表示,给定两个特征向量[X={x1,x2,...,xn}]和[Y={y1,y2,...,yn}],其向量之间的欧式距离为:
[d(X,Y)=i=1n|xi-yi|2]
由于每种特征的取值范围不同,因此需要对计算后欧式距离进行归一化处理,用[dc(X,Y)]、[ds(X,Y)]和[dg(X,Y)]分别表示颜色、形状和纹理特征的欧式距离,归一化的处理如下:
[dc(X,Y)=dc(X,Y)-μcσc]
[ds(X,Y)=ds(X,Y)-μsσs]
[dg(X,Y)=dg(X,Y)-μgσg]
则两幅图像[I1]和[I2]的距离表示为:
[d(I1,I2)=13(dc(I1,I2)+ds(I1,I2)+dg(I1,I2))]3.2 MapReduce的图像检索
当测试图像进行检索时,利用MapReduce并行计算框架对实现并行计算,减少检索所需的时间:
1) 首先提取出测试图像的颜色、形状、纹理特征,并将三种特征进行组合;
2) Map阶段,将测试图像的特征与各个子节点中的图像特征进行匹配,Map的输出格式为(相似度,图像ID)键值,并将结果复制作为Reduce阶段的输入;
3) Reduce阶段,所有的Map结果根据相似度非减进行排序,并将前N个结果进行输出。
3 实验及讨论
为了验证本文方法的有效性,我们采用著名的Caltech256数据集进行实验,Caltech256数据集有256个类别的目标图像,平均每个类别约有80张-200张图像,示例图像如图3所示。
本文采用IBM高性能计算集群进行分布式环境的搭建,其硬件性能主要有:系统存储能力20TB,内存468GB,16个节点,其中1个NameNote,1个IO节点,14个DataNote,NameNote服务器的配置为Intel Core i7 4.5GHz,内存为16GB,DataNote服务器的配置为AMD Athlon II X4 2.8GHz,内存为8GB,所有服务器节点均配置千兆传输网络。软件操作系统采用Red Hat Enterprise Linux Server release 5.6 X86_64,Hadoop-0.20.2以及jdk1.6。
首先我们进行系统检索性能的比较,我们将文中的分布式图像检索与传统的单节点图像检索系统进行比较,实验结果如图2所示。
从图2中可以看出,随着图像数量的增加,两种方法的检索时间都有所增加,但是对于图像数量较多时,分布式图像检索方法的检索时间远低于单节点图像检索方法。
然后我们对文中方法的查全率和准确率进行实验,查全率和准确率分别表示如下:
[ 查全率=正确分类的图像数量该类别的图像数量×100%]
[ 准确率=正确分类的图像数量分类为该类别的图像数量×100%]
查全率-准确率曲线形成一个区域,该区域面积越大,表示检索方法的性能越好,选择检索图像为7000张图像时,本文方法与单节点检索方法的查全率-准确率曲线如图3所示。
从图3中可以看出,分布式图像检索虽然将检索数据分为多个子任务进行检索,但是并没有降低其检索性能。
4 结论及未来工作
本文针对传统单节点的CBIR检索方法计算速度较慢,检索效率不高的问题,提出了一种基于Hadoop分布式计算的图像检索方法,利用云计算平台的并行处理能力提高CBIR方法的运行效率,实验结果表明基于Hadoop分布式计算的图像检索方法减少了检索的时间,提高了检索的效率。未来的主要工作集中在提高CBIR检索的准确率和查全率。
参考文献:
[1] 宋真,颜永丰.基于兴趣点综合特征的图像检索[J].计算机应用,2012,32(10):2840-2842.
[2] 张泉,邰晓英 基于Bayesian 的相关反馈在医学图像检索中的应用[J].计算机工程, 2008,44( 17) : 158-161.
[3] 余胜,谢莉,成运.基于颜色和基元特征的图像检索[J].计算机应用, 2013, 33(6):1674-1708.
[4] 陈康, 郑纬民. 云计算: 系统实例与研究现状. 软件学报, 2009,20(5): 1337-1348.
[5] 陈全, 邓倩妮. 云计算及其关键技术[J].计算机应用, 2009,29(9): 2562-2567.
[6] Armbrust M. A view of cloud computing. Communications of the ACM, 2010, 53(4): 50-58.
[7] Borthakur D. The hadoop distributed file system: Architecture and design. Hadoop Project Website, 2007: 11-21.
猜你喜欢
