
DNA数据库数据挖掘应用研究
2015-08-29 10:06刘冰
刑事技术 2015年5期
刘 冰
(公安部物证鉴定中心, 北京 100038)
专题研究:法医遗传学
DNA数据库数据挖掘应用研究
刘 冰
(公安部物证鉴定中心, 北京 100038)
始建于2003年的全国公安机关DNA数据库目前已聚集了大量数据信息,除DNA分型等技术数据外,还包括犯罪的时间、空间、类别、手段以及涉案人员的地域、民族、行为等多个维度的海量数据。将数据挖掘引入DNA数据库的应用,通过分类、估计、预测、相关性分组、关联规则、聚类分析等方法,可以实现对DNA数据库中DNA分型、人员背景和行为、案件特征等复杂类型数据的进一步挖掘。本文采用聚类分析的方
法医遗传学;DNA数据库;数据挖掘;聚类分析
当今社会,随着快速的变革各种危机事件的发生频率不断提高,人类社会逐渐进入了一个“风险社会”。风险社会的本质特征是“不确定性”,即对风险难以进行有效预测与控制。公共安全作为社会发展与文明进步的重要前提条件,风险的防控是其面临的主要课题。大数据能够让人们掌握到前所未有的全面信息,在对其进行有效处理的基础上更为准确地发现事物发展的规律。在大数据环境下,不确定性的消除具备了真正的可能性[1]。始建于2003年的全国公安机关DNA数据库(以下简称“DNA数据库”)目前已聚集了大量公共安全领域中的数据信息,除DNA分型等技术数据外,还包括犯罪的时间、空间、类别、手段以及涉案人员的地域、民族、行为等多个维度的海量数据[2]。随着公共安全治理的实际需求不断增长,上述数据还处于快速累积和持续增长中。目前,我国DNA数据库的主要优势和用途在于人的个体识别,主要应用模式是基于短串联重复序列(short tandem repeat,STR)数据的完全匹配和亲缘关系检索[3]。显然,这一应用模式还没有充分发掘DNA数据库的数据价值:(1)在未形成基于DNA分型数据的个体识别匹配结果时,大量的案件、物证、人员的相关数据信息处于沉寂状态;(2)受限于目前DNA数据库匹配结果的表现形式(一般呈两个样品一对一的形式),数据库匹配结果(包括有关的案件、人员等信息)的应用往往是孤立而不是关联的。
上个世纪80年代,数据挖掘(data mining)被提出。作为数据库知识发现(knowledge-discovery in databases,KDD)中的一个步骤,数据挖掘可以从大量的数据中通过算法搜索发现隐含在其中的概念、规则、规律、模式等有用的知识。利用上述知识,改进工作方法,提高工作效率,实现数据库在原设计目的以外的增值,获取最大效益。数据挖掘通常与计算机科学有关,并通过统计、在线分析处理、情报检索、机器学习、专家系统和模式识别等诸多方法来实现上述目标。数据挖掘目前已成为商业、科研、工业、行政管理等领域的热点,得到广泛应用。数据挖掘是信息发展到一定程度的必然产物,是利用积累数据的一个高级阶段[4]。
目前,DNA数据库从数据总量和覆盖程度两个方面已经达到一个可观的程度。以案件信息为例:2011~2013年,DNA数据库共采集了超过30万起刑事案件的相关数据,虽然总体仅覆盖同期公安机关立案刑事案件数量[5,6]的1.8%,但是杀人、强奸等类案的平均覆盖率却高达79.25%和40.53%(见表1)。将数据挖掘引入DNA数据库的应用,通过分类(classification)、估计(estimation)、预测(prediction)、相关性分组(affinity grouping)、关联规则(association rules)、聚类分析(clustering analysis)等方法,可以实现对DNA数据库中DNA分型、人员背景和行为、案件特征等复杂类型数据的进一步挖掘。从数据结构来看,DNA数据库已经具备在以下几个方面深入应用的可能:(1)高发、高危犯罪与时间、空间、人群等维度的动态关系分析;(2)典型犯罪行为在时空中的分布呈现、演化及预测;(3)人个体遗传信息与行为规律相关性模式分析。显然,上述应用已经突破传统观念中DNA数据库在刑事侦查中的应用模式,在对DNA数据库的功能要求呈现多警种、多部门、多角度、多领域、复杂化趋势的今天,显然具有不可估量的价值。本文采用聚类分析的方法,对DNA数据库中2011~2014年间采集的数据,从犯罪的时间、空间、类别等维度进行了初步分析,为我国今后DNA数据库的数据挖掘进行尝试。
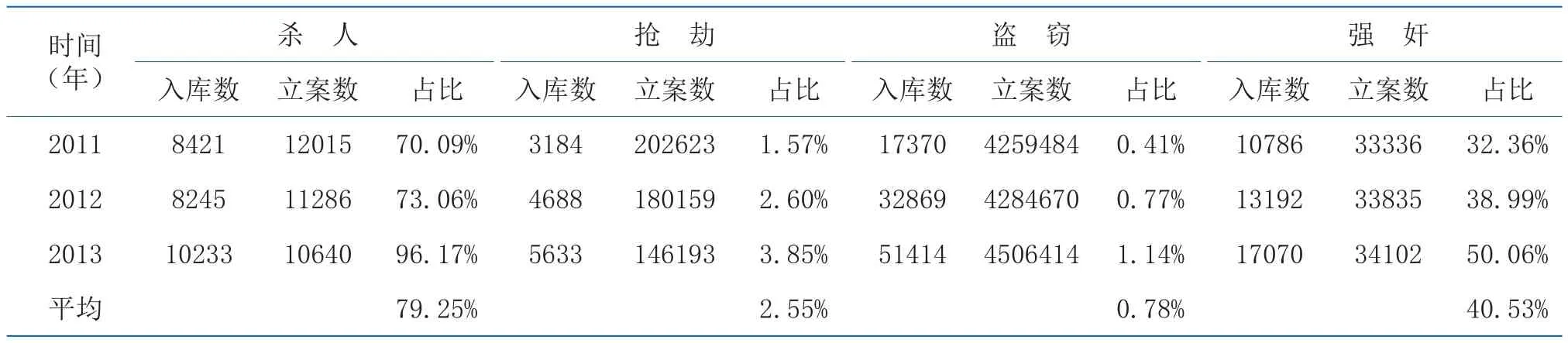
表1 DNA数据库中4类案件数量与同期公安机关立案情况比较(2011~2013年)Table1 Status of cases (murder, robbery, theft, rape) in the national DNA database and the concurrent fi les of public security organs (2011~2013)
1 DNA数据库数据的初步挖掘分析
此次分析,包括数据审查、数据清理、数据转换和聚类分析。数据审查阶段使用描述性统计分析技术进行频数分析,检查统计字段的字段类型,记录有效值、缺失值或空值个数;数据清理段对数据审查过程中出现的缺失值或空值等异常数据进行忽略处理;数据转换阶段对原始数据重新分类,对变量和日期数据进行标准化。聚类分析使用的是基于分类的半监督聚类方法。
1.1 DNA数据库4类案件数据分析
2011~2014年,DNA数据库采集了超过45万起刑事案件的相关数据。以市(地)为地域划分的最小单位,在对这些数据中杀人、抢劫、盗窃、强奸等4类案件进行分析后,可见:
(1)4类案件在国内的分布具有不同的特点(见图1)。根据分析结果杀人、强奸案件的分布高度的一致,2011~2014年DNA数据库中两类案件排在前20位的城市完全相同,仅个别城市的排位有所差异。城市的地理分布呈一带一点状,一带从东北(黑龙江、吉林、辽宁)、华北(河北、山东)、华中(河南)至西南(陕西、云南、贵州、四川)地区,一点主要在华南地区(广东)。抢劫、盗窃类案件主要分布在沿海省份。DNA数据库中抢劫案件排在前10位的城市中有8个位于天津、浙江、福建、广东等4省(市),案件数量占到同期同类案件的25.70%;盗窃案件排在前10位的城市中有8个位于上述4省(市),案件数量占到31.00%。
(2)对于某一类案件而言,其地域分布具有相当程度的时间稳定性(见图2)。2011~2014年,4类案件的基本分布格局并没有发生显著变化。以杀人案件为例,2011~2014年,DNA数据库中广州、成都、保定、邯郸、毕节、西安、南阳、六盘水、烟台、曲靖、唐山、遵义等12个城市的杀人案件始终排在前20位,年度间杀人案件分布的变化也主要发生在省内和邻省之间。
(3)在分析了2011~2014年48个月的案件数据后可见,不同类案件由于其发案特点的不同,发案数量的地域分布格局的变化特点也有差异:对于职业性特征明显的盗窃类案件,其分布格局基本不存在季节性变化(见图3上),显示出犯罪人群的流动性并不强烈;对于偶发性特征较高的杀人类案件,其分布格局的季节性变化较大(见图3下),但变化仍以省内或邻省地理位置临近的城市之间为主,推测与人口的流动性相关。

图1 基于DNA数据库的4类案件(杀人、抢劫、盗窃、强奸)的地域分布分析(2011~2014年)。Fig.1 Geographical distribution of 4 kinds of crime (murder, robbery, theft, rape) in the national DNA database (2011~2014)
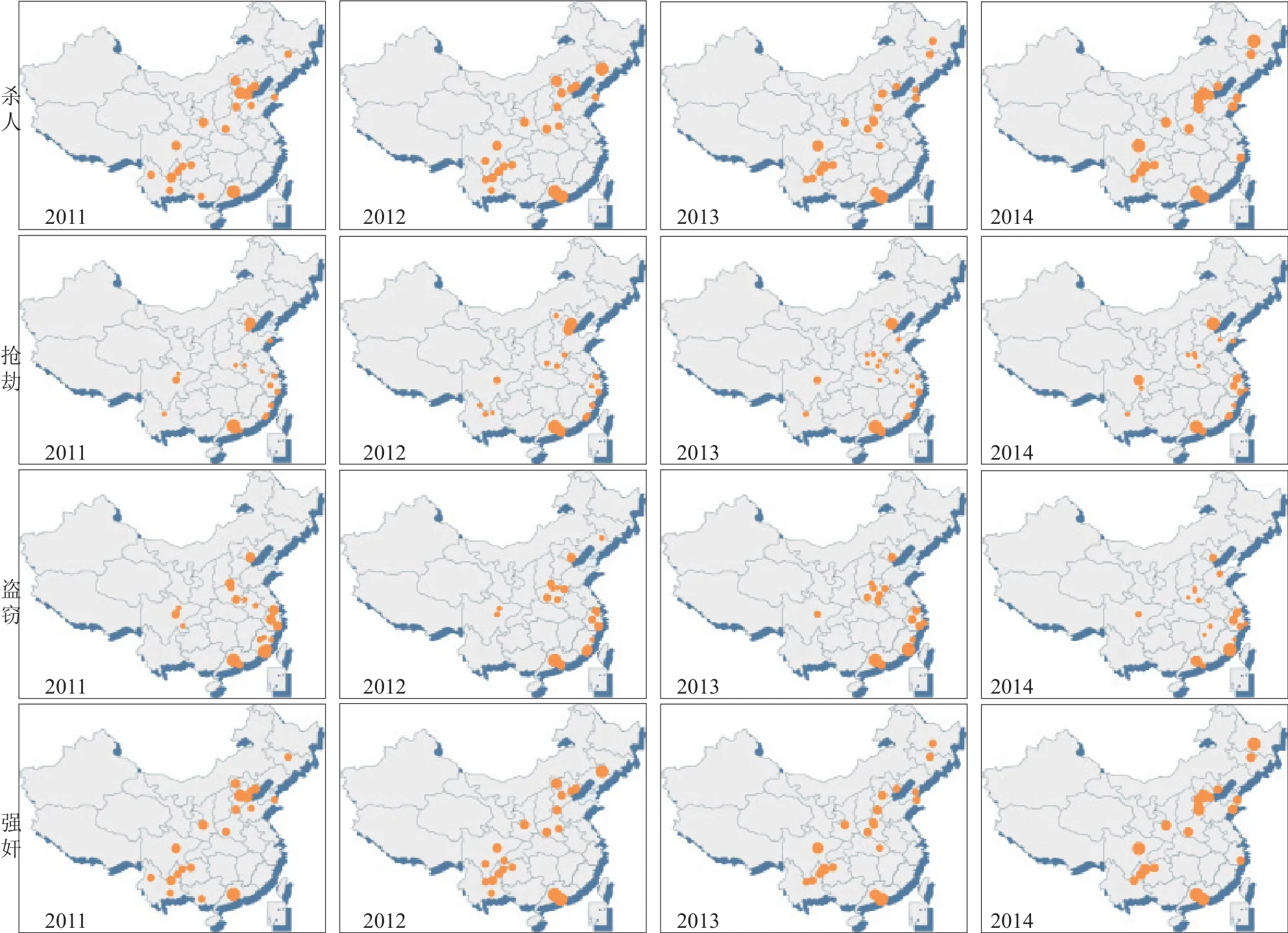
图2 基于DNA数据库的杀人、抢劫、盗窃、强奸案件地域分布分析(2011~2014年)Fig.2 Geographical distribution of murder, robbery, theft and rape cases in the national DNA database (2011~2014)
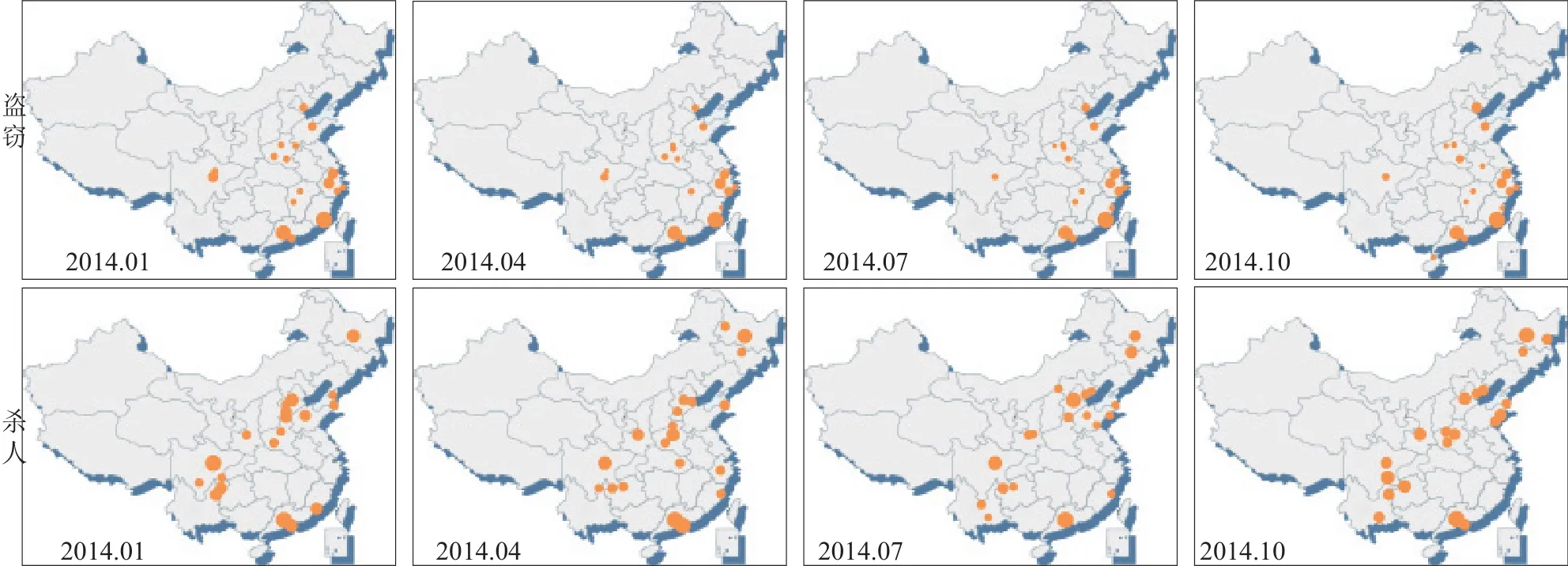
图3 基于DNA数据库的杀人盗窃案件地域分布分析(2014年1、4、7、10月)Fig.3 Geographical distribution of theft and murder cases in the national DNA database in Jan., Apr., Jul., Oct., 2014
(4)在分析了DNA数据库中案件数量排序前20位的城市,2011~2014年中48个月的案件数据后可见,对于单一城市而言,一方面DNA数据库中4类案件的数量变化与季节无明显相关性,月份之间的数量波动也无明显的规律(见图4、图5);另一方面杀人、强奸2类案件数量的时间分布曲线却呈现高度的相关性(见图6)。横向比较处于华北、华东和西南的天津、广州、成都3个城市,显示这一特点也并不受城市所处地域的影响。
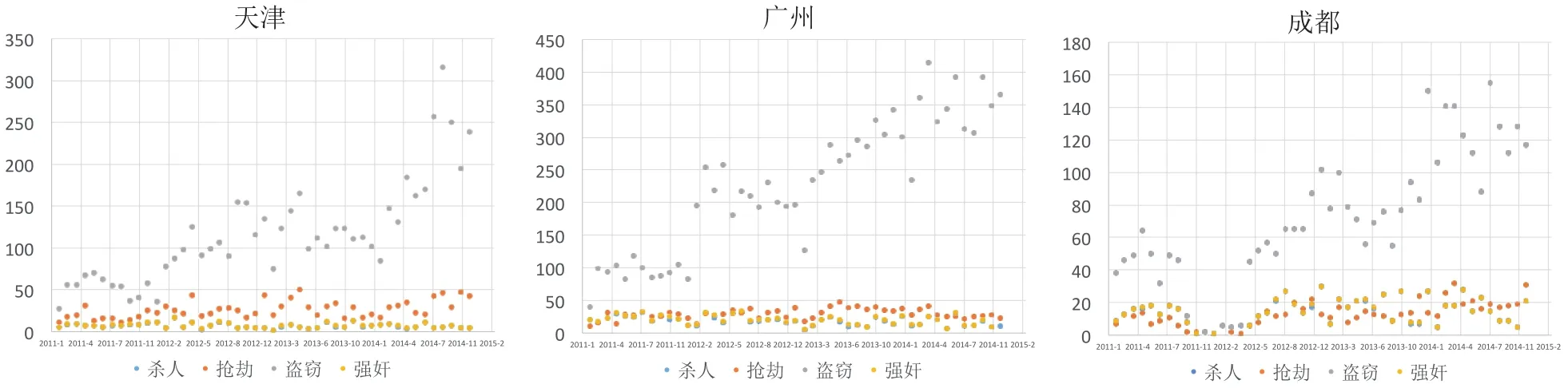
图4 天津、广州、成都4类案件(杀人、抢劫、盗窃、强奸)的时间分布分析(2011年1月~2014年12月)Fig.4 Time distribution of 4 kinds of crime (murder, robbery, theft, rape) in the city of Tianjin, Guangzhou and Chengdu (2011.01~2014.12)

图5 广州市4类案件的时间分布分析(杀人、抢劫、盗窃、强奸)(2011~2014年)Fig.5 Time distribution of 4 kinds of crime (murder, robbery, theft, rape) in Guangzhou (2011~2014)

图6 天津、广州、成都杀人、强奸案件的时间分布曲线(2011年1月~2014年12月)Fig.6 Time distribution curve of murder and rape occurred in the city of Tianjin, Guangzhou and Chengdu (2011.01~2014.12)
1.2 DNA数据库违法犯罪人员分析
2011~2014年,DNA数据库采集了超过2000万违法犯罪人员的相关数据。以市(地)为地域划分的最小单位,对其中采集原因为杀人、抢劫、盗窃、强奸4类涉案人员数据进行分析后,得出:
(1)4类涉案人员的户籍地分布虽然具有不同的特点(见图7),但主要位于东北、华北和西南地区各省份。从图1可发现:杀人、强奸2类案件,在东北、华北和西南地区基本上呈涉案人员本地化的特点,但在广东省外地人口作案的特征十分明显;抢劫、盗窃2类案件,在案件高发的沿海各省份(天津、浙江、福建、广东),绝大部分呈现外地人口作案的特征。
(2)对于盗窃、抢劫类案件而言,其涉案人员户籍地分布具有一定程度的时间稳定性。而涉杀人、抢劫类案件人员并无此特征(见图8)。数据分析,2011~2014年,随着盗窃类案件数量上升,涉案人员大幅度增加,涉案人员的来源地并没有显著变化,显示此类犯罪涉案人群具有很强的地域性,可通过同乡、宗族、朋友或家族等关系快速扩大(见图8)。
1.3 DNA数据库违法犯罪人员重复采集情况分析

图7 基于DNA数据库的涉4类案件人员(杀人、抢劫、盗窃、强奸)的户籍地分布分析(2011~2014年)Fig.7 Residence distribution of 4 kinds of offenders (murder, robbery, theft, rape) in the national DNA database (2011~2014)
2011~2014年,DNA数据库通过完全匹配的比对模式,共生成超过100万条通报。这其中,有“物证-人员”的匹配,也有“人员-人员”的匹配。在对上述通报信息和同期采集的人员数据进行清洗和综合数据分析后,可见:
(1)根据人员身份证信息进行的人员查重分析,2011~2014年DNA数据库中人员数据的重复采集率为3.39%(见表2)。不同涉案人员的重复采集率有所不同,以诈骗类犯罪最高,为4.55%(见图9)。被重复采集的样本中,重复采集2次的占92.89%,采集超过10次的占0.55%(见表3)。
(2)根据DNA信息进行的人员查重分析,2011~2014年DNA数据库采集的人员数据中,有3.3万人使用了多个身份被重复,约占被采集人员总数的0.16%。其中,使用2个身份的占此类人员的97.53%,使用超过10个身份的占0.03%(见表4)。
2 DNA数据库数据挖掘的SWOT分析
SWOT(strengths,weaknesses,opportunities, threats)分析,也称态势分析,1971年由Kenneth R.Andrews在《公司战略概念》中首次提出,20 世纪80年代又由Heinz Weihrich发展。SWOT分析,就是将与研究对象密切相关的各种主要内部优势(strength)、劣势(weakness)和外部的机会(opportunity)和威胁(threats)等,通过调查列举出来,并依照矩阵形式排列,然后用系统分析的思想,把各种因素相互匹配起来加以分析,从中得出一系列相应的结论,运用这种方法,有利于人们对组织所处情景进行全面、系统、准确地研究,有助于管理者和决策者制定较正确的发展战略和计划,以及与之相应的发展计划或对策。本文对DNA数据库数据挖据应用进行了如下分析(见图10)。
3 结 语
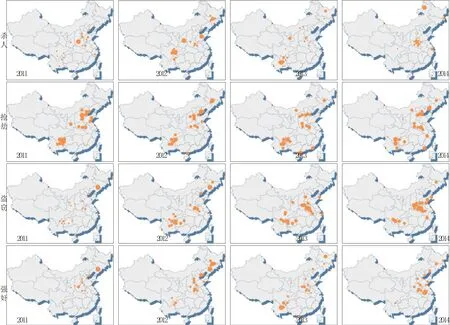
图8 基于DNA数据库的涉杀人、抢劫、盗窃、强奸案件户籍地分布分析(2011~2014年)Fig.8 Residence distribution of 4 kinds of offenders (murder, robbery, theft, rape case) in the national DNA database (2011~2014)
本文对DNA数据库的数据挖掘,受到基础数据条件的限制,上述分析还存在诸多不足:(1)由于各种原因,DNA数据库中的数据质量非常不均衡。如早期的数据大量存在非法字段;由于历史原因,江苏、上海等地的数据很多数据项在国家库中为空等。虽然选取的2011~2014年的数据在整体质量上已经高于其他数据,但仍存在一定比例的脏数据。(2)由于不同省份间DNA实验室的建设情况存在较大的差异,数据采集节点、数据数量的分布呈现东高西低的大致特征,因此分析中使用数据的覆盖率和代表性地区性差异明显。如西藏、青海、甘肃、宁夏的数据采集节点密度和数据数量要低于广东、浙江等省份。(3)DNA检验技术的差异也会影响分析的结果,某些案件的数据可能因DNA实验室不具备特殊生物检材的检验能力而未能采集到。(4)聚类中采用的分类原则还有可改进的地方。如将天津(直辖市)、广州(省会市)、成都(省会市)与邯郸、驻马店等城市作为同等级别的城市进行分析是否恰当还值得商榷。(5)缺乏与外部数据,特别是相关专业系统的业务数据的比较分析。如果进行此类工作,则可以在对分析结果验证的同时,得出更深层次的情报产品。
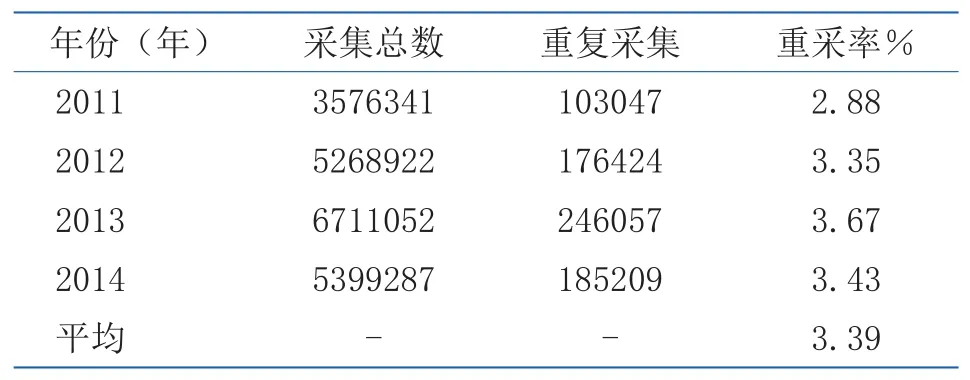
表2 DNA数据库人员样本的重复采集情况(2011~2014年)Table2 The offenders resampled in the national DNA database (2011~2014)

表3 DNA数据库人员样本的重复采集次数(2011~2014年)Table3 The repetitious times of offenders resampled in the national DNA database (2011~2014)
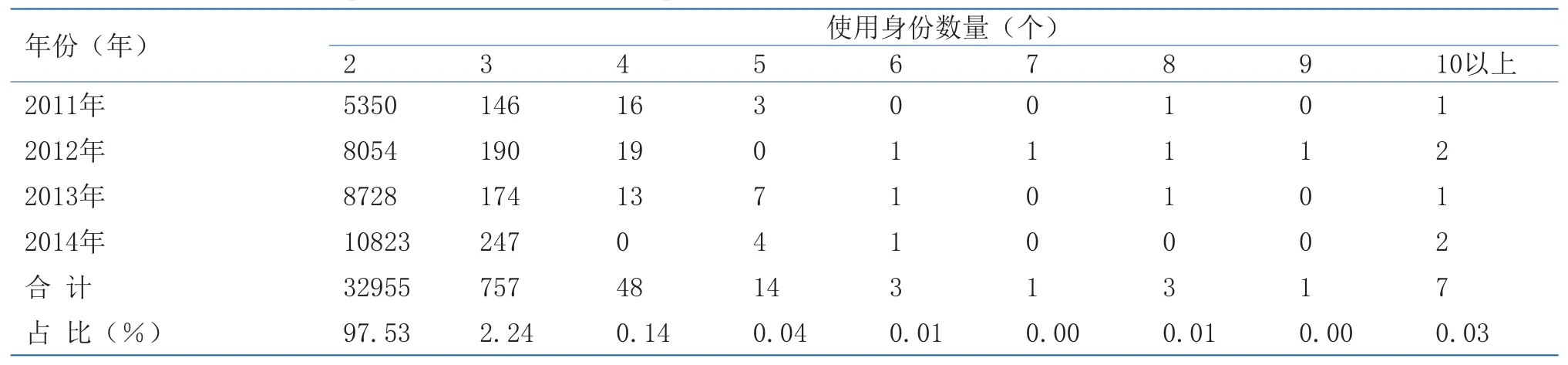
表4 DNA数据库使用多身份被采集人员的统计(2011~2014年)Table4 Statistics of resampled offenders with multiple IDs in the national DNA database (2011~2014)
目前,DNA数据库的建设发展已经进入关键节点,很多传统的观念和模式已经面临挑战:(1)除刑事侦查工作以外,整个公共安全行业对DNA数据库的服务需求不断增长。作为需求导向的信息系统,DNA数据库以DNA数据应用为主体的单一应用模式已经难于满足这一变化。(2)作为资源型的数据库,DNA数据库具有先天的扩张属性。而其用户具有二元属性,既是数据的提供者也是信息产品的使用者。因此在提供稳定高质量信息产品的同时,不断提升系统的附加价值和吸引力,是保证数据库规模持续增长的前提。(3)分布式的数据应用模式对现有DNA数据库的组织形式提出挑战,充分显示和发挥数据集中管理的优势,是维护现有DNA数据库体系和模式主导地位,确保DNA技术健康发展,为公共安全工作提供优质高效服务的保证。数据挖掘是一个具有广阔应用前景和富有挑战性的新兴技术,将其引入DNA数据库的管理和应用是信息化社会开放思维的体现,也是DNA数据库面向挑战,不断自我完善和发展的一种选择。
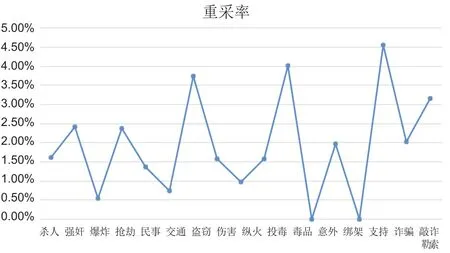
图9 不同涉案人员样本的重复采集情况(2011~2014年)Fig.9 The crime-different offenders resampled in the national DNA database (2011~2014)
本文的工作是希望从新的角度拓展人们看待DNA数据库的视野。随着DNA数据库整体发展,从广度上可以不断拓展数据覆盖范围,增加数据总量;从深度上可以通过技术标准和规范管理,实现数据的汰弱留强。作为目前唯一实现全国实时网络化运行的生物特征识别数据库,DNA数据库人员身份精确识别的特征和不断增长的数据体量,使得其从基层DNA实验室和管理系统获取数据的能力不断加强。通过数据挖掘,联机分析处理(online analytical processing,OLAP)等相对成熟的信息化手段,本文中的一些尝试以及更多的分析模式可以在动态条件和更深层次得以实现,如基于人员、案件背景信息分析的典型犯罪行为在时空中的分布呈现、演化及预测,基于DNA和身份信息查重的高危人群与时间、空间等维度的动态关系分析和预警等。其情报产品的实时性,可靠性,特别是对人员个体识别的精准属性,将充分展示DNA数据库在犯罪规律研究、犯罪动态分析、公共安全管理决策等领域应用的潜力和价值。

图10 DNA数据库数据挖掘应用的SWOT分析Fig.1 0 Data mining by SWOT analysis into the national DNA database
[1] 张春艳.大数据时代的公共安全治理[J].国家行政学院学报,2014,5:100-104.
[2] 刘冰.基于数据库数据分析的DNA证据作用评价[J].刑事技术,2015,40(3):199-203.
[3] 刘冰.现阶段我国DNA数据库发展的几个关键问题[J].刑事技术,2015,40(4):318-323.
[4] 徐守军,高波,甄蓓,等.数据挖掘技术在科研管理中应用前景初探[J].中华医学科研管理杂志,2005,18(4):214-216.
[5] 中华人民共和国国家统计局.中国统计年鉴-2013 [M].北京:中国统计出版社,2013.
[6] 中华人民共和国国家统计局.中国统计年鉴-2014 [M].北京:中国统计出版社,2014.
引用本文格式:刘冰.DNA数据库数据挖掘应用研究 [J].刑事技术, 2015,40(5): 345-352.
Data Mining of the National DNA Database
LIU Bing
(Institute of Forensic Science, Ministry of Public Security, Beijing 100038, China)
ABATRACT: Until present, China national DNA database has already gathered tens of millions of data, including not only the DNA profi les but also a large amount of information related to the time, space, means, type of the committed crime and the residence, nationality, individual behavior of the suspect.With the growing needs of public security, the data are still in rapid accumulation and growth.From 2011 to 2013, the database collected relevant data covering over 79.25% of murder and 40.53% of rape cases fi led.Currently, the main use of the DNA database is personal identifi cation, not fully tapping its data value.Data mining can provide assistance in conceptual formation and accuracy, exploration on regularity and pattern,modeling and the other useful knowledge.Using the methods of classification, estimation, prediction, affinity grouping,association rules and cluster analysis, data mining can fulfi ll a deep analysis of the intricate data in the DNA database, like the DNA profiles, the relevant information of cases, the background and behaviors of individual suspects.By resorts of cluster analysis, this paper attempts to obtain a preliminary analysis at multiple dimensions of time, space, type of crime.The analyzed data covered over 0.45 million criminal cases, 20 million individuals and 1 million matched reports, which were collected and produced in the past four years.The analysis is made up of three parts: the distribution of four kinds of crime (murder, robbery, theft, rape); the residence distribution of the offenders involved into the four kinds of crime; the situation of offenders resampled in the national DNA database.This study also carried out a SWOT (strengths, weaknesses, opportunities,threats) analysis on the application of data mining in the national DNA database.Data mining is an emerging technology of wide prospect.Its usage into the management and application of the national DNA database conforms to the open-mindedness of the information society, in favor of the improvement and development of the database itself.However, the above analysis is not perfect due to the limitations of underlying conditions.Through the combined application of the established means of data mining plus online analytical processing (OLAP), the attempts hereof can be continuously elevated along with the other analyses under dynamic and deep-reaching conditions.Therefore, the criminal time and space distribution will be defi ned more clearly, evolution and prediction of typical crime given more timely based on the personal and crime background, and the dynamics and early detection of high-risk criminal groups tracked more tightly with the DNA hunting and ID checking.Ideally, the DNA database can provide real-time, reliable and accuracy-high personal identifi cation intelligence, showing its particular potential and value in the study of criminal pattern and dynamics, public security management decision and other involved aspects.
forensic genetics; DNA database; data mining; clustering analysis法,对DNA数据库中2011~2014年采集的数据信息从犯罪的时间、空间、类别等维度进行了初步分析,共超过45万起刑事案件、超过2000万个违法犯罪人员和超过100万条通报。包括:杀人、抢劫、盗窃、强奸等4类案件的时间、空间分布;数据库中4类涉案人员的地域分布情况分析;数据库人员重复采集情况分析等。文章同时对DNA数据库应用数据挖掘技术做了SWOT分析。虽然受到基础数据条件的限制,上述分析还存在诸多不足,但是数据挖掘是一个具有广阔应用前景和富有挑战性的新兴技术,将其引入DNA数据库的管理和应用中是信息化社会开放思维的体现,也是DNA数据库面对挑战,不断自我完善和发展的一种选择。随着DNA数据库的数据总量的增长、数据覆盖范围的扩大和数据质量的提高,通过数据挖掘,联机分析处理等相对成熟的信息化手段,文中的分析模式可以在动态条件下和更深层次中实现,如基于人员、案件背景信息分析的典型犯罪行为在时空中的分布呈现、演化及预测,基于DN A和身份信息查重的高危人群与时间、空间等维度的动态关系分析和预警等。DNA数据库数据挖掘的情报产品所具有的实时性、可靠性,特别是人员身份识别的识别精准性,使其在犯罪规律研究、犯罪动态分析、公共安全管理决策等领域具有特殊的潜力和价值。
10.16467/j.1008-3650.2015.05.001
中央级公益性科研院所基本科研业务费项目(No.2013JB019)
刘 冰(1974—),男,黑龙江齐齐哈尔人,副主任法医师,硕士,研究方向为法医遗传学。 E-mail: liubing@cifs.gov.cn
DF795.2
A
1008-3650(2015)05-0345-08
2015-07-23
猜你喜欢
水上消防(2021年4期)2021-11-05
大众投资指南(2021年35期)2021-02-16
学生天地(2020年2期)2020-08-25
中国交通信息化(2020年1期)2020-07-27
职工法律天地(2018年2期)2018-01-22
环球时报(2017-12-22)2017-12-22
中国交通信息化(2016年10期)2016-06-08
信息通信技术(2015年6期)2015-12-26
中国卫生(2015年9期)2015-11-10
中国检察官(2015年20期)2015-02-27
