
计算机实现火药配方性能数据的自动提取及分类入库
2015-08-26 06:38:10米小亮王亦然赵宏安
电子设计工程 2015年17期
关键词:数据处理
米小亮, 王亦然, 赵宏安, 王 冰
(1. 西安工业大学 北方信息工程学院, 陕西 西安 710200; 2. 西北大学 信息科学与技术学院, 陕西 西安 710069)
随着互联网和信息技术的迅猛发展, 对海量数据的处理和分析逐渐成为十分重要的研究课题。 机器学习、数据挖掘、数据采集、分析、处理、入库等技术被广泛应用于分析这些海量数据,并取得了很多相关的研究成果。Arunasalam[1]提出了适用于类分布不均衡数据上的关联分类方法;Verhein[2]等基于关联分类提出了一种新的处理此类数据的方法;Hinton[3]等提出了通过训练一个中间层有小数目结点的多层神经网络将高维数据映射到低维空间,取得了很好的效果。 为解决高阶异构数据挖掘问题, 基于谱分解算法和基于信息论的协同聚类方法分别被提出,并被应用于文本和特征词的协同聚类[4-6]。 对海量数据的提取、处理、入库也得到了广泛的应用,文献[7]介绍了地形数据库的处理及入库方法;文献[8]分析了不同类型工作站的数据格式, 实现了从样品到数据处理及入库的全过程自动化;文献[9-11]分别介绍了卷烟入库数据的采集系统,地震数据的传输与入库, 城市绿化数据的加工处理方法及入库技术。 在“中国知识资源总库”数据库中输入关键词“数据处理”,仅2000 年以来,相关的文献就达6 万之多。
火药配方有双铅、双石、双芳镁等成百个类型,每种配方有能量特性、燃烧性能、力学性能、安全性能、应用情况及使用特点等分类性能参数, 每一类性能又有多个性能参数,如能量特性就有比冲、爆热、密度等几十个参数,这些参数又有理论数据和实验数据之分,参数数值还和温度、压力等实验条件有关,且又分为不同的批次。 再如燃烧性能,有燃速、燃速经验公式、燃速温度系数等参数,燃速又分为燃速仪测定和发动机测定,不同的温度和压强下,测定的数值又不一样;即使同温同压下,不同的批次测定的结果又不一样。 数百个推进剂配方,数百种性能指标,在不同的物理和化学条件下测定和计算的数十万的数据,将其提取、归类、入库,是十分繁杂的任务。 火药配方数据的复杂性及其独特的性能,使得其它文献介绍的数据处理方法并不能完全满足本项目对其数据自动处理的需求。
文中在认真阅读推进剂原始文档的基础上,细致分析了原始word 文档的数据组织结构, 努力找出性能数据的显示规律,采取了一系列的方法和手段,设计了性能数据的归类目标及结构,编写计算机程序,实现了火药配方性能数据的自动提取和归类,并写入设计好的数据库中。
1 火药性能数据预处理
长期以来, 众多资料报道的火药性能数据格式多样,为便于计算机的编程,实现数据处理的自动化,需对原始数据的文本格式做初级处理,具体做法是添加行序号和编写实现数据处理的功能函数。
1.1 添加行序号
在自动处理数据过程中,当提取一个具体的性能参数数值时,必须确定该数据归属于哪一个推进剂,这样才能实现该数据的自动化归类。 为此,对原始数据文档的每一行加上行序号。
首先,将所有推进剂的多个原始word 文档,汇集成一个word 文件,即.doc 文件,再将此文件另存为.txt 文件。 之所以汇集成一个文件,是为了程序一次运行,便可提取出所有推进剂的相关数据。
原始.doc 文件的每一段,在.txt 文件中都为一行,每一行的编号分为三个部分,第一部分为推进剂序号,第二部分为该推进剂的行序号,第三部分为改行在文档中的总行号。 文档编号基于以下的方法实现:
观察知:每个推进剂的第一行都以数字开始,以“推进剂”三个字结束,如“17. GOL-1 改进型双基推进剂”,由此得编程的实现方法:
1)读取文件的每一行,赋值给一字符串变量;
2)去掉字符串的前后空格;
3)取出该字符串的首个字符及最后3 个字符,判断第一个字符是否数字,后三个字符是否是推进剂;
4)如条件为真,则为新的推进剂,推进剂序号加1,新推进剂的行号初始为1,总行号加1;
5)如条件为假,推进剂序号不变,推进剂的行号加1,总行号加1;
6)循环返回到步骤1),直至文件结束。文档添加行序号后的效果如图1 所示。
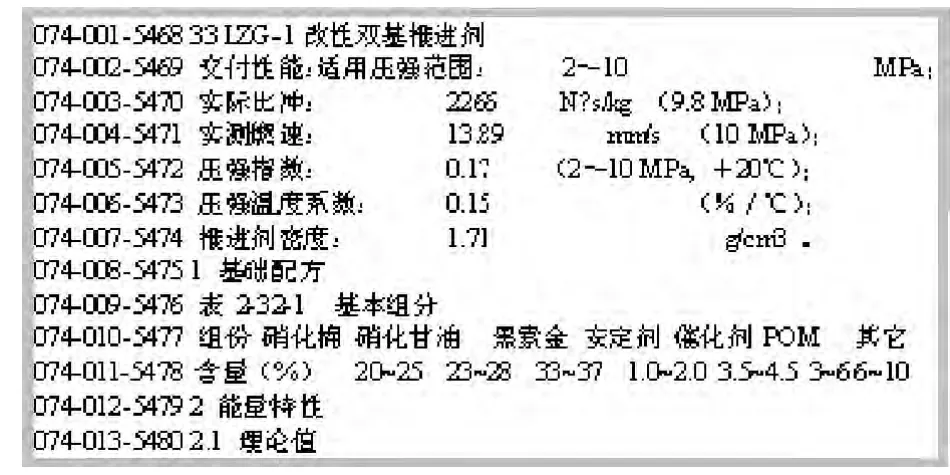
图1 原始文档添加行序号效果Fig. 1 The effect of the original document to add line number
1.2 几个重要的功能处理函数
1)字符串查找函数strFind(string1,string2)和字符串替换函数strReplace(string,oldString。 newString)
计算机编程语言都有字符串查找函数strFind(string1,string2),该函数查找string2 在string1 的位置。 如果查到,返回其在字符串string1 的位置,否则返回0;
字符串替换函数的实现,可利用字符串查找函数确定字符串的位置,将其分割为两部分,去掉旧字符串,添加新字符串,再将两字符串合并,即完成字符串的替换。 函数参数表示在string 中用newString 替换oldString。
2)取数字函数pickoutNum(string)
该函数的功能,是将字符串中的数字保留,去掉所有的中文符号和西文的非数字符号。 其实现原理为:依次读取字符串中的每一个字符, 取其ASCII 码值, 比较是否和0~9、“+”、“-”、“.”的ASCII 码值相同,相同的则保留。
符号“+”、“-”和“.”是为了保留如“-37”、“+25”、“-4.28”等含符号及小数的数字。
为了防止保留文中单独出现的符号“+”、“-”和“.”,必须有判断条件,只保留那些既出现符号“+”、“-”、“.”且下一个相邻的字符是数字的字符串。
3)取中文字符函数pickoutChinese(string)
该函数的功能,是仅保留字符串中的中文字符,去掉所有的数字字符、标点符号和西文字符,其实现原理同取数字函数pickoutNnm(),在此不再赘述。
4)分割字符函数strSplit(string,char),该函数可按分隔字符char 将字符串string 分割为字符串数组。
5)写数值数组或矩阵到excel 文件函数writeToExcel()有些编程语言如MATLAB2007 以后版本,提供了该类函数,其形式如下:
xlswrite(filename,Matrix,sheet,range)
该函数可将所要写的数组矩阵Matrix, 一次写到给定的excel 文件filename,写到给定的表sheet 且范围range 的起始行、列到终止行、列的位置上。
1.3 特定字符串的替换
由于原始数据结构的多样性, 在数据处理的过程中,出现了一些非预想的结果, 如原word 文档中的 “厘米2”或“cm2”,转化为.txt 文档后,变为“厘米2”或“cm2”,使用取数字函数后,数字“2”保留了下来,但这是无效和无用的数字,必须去掉。 本文采用了如下的方法,先将“厘米2”替换为“厘米平方”,这样在就避免了非预想数字“2”的出现。
类似的还有反映实验数据第一、第二、第三批次的“D1”、“D2”、“D3”,都替换成“D 一”、“D 二”、“D 三”等。
2 火药性能数据的提取、分类及入库
分析可知,所有原始文档数据以3 种形式之一呈现:
1)性能属性和属性值在同一行(段)中,该类数据称为简单结构数据;
2)性能属性以简单表格的形式呈现;
3)性能属性以较为复杂表格的形式呈现;
所以,对推进剂原始文档数据的处理,就归结为对这不同格式数据的处理,分别介绍如下。
2.1 简单结构数据的处理
简单结构数据处理的方法步骤:
1) 运行程序,遍历文档所有行,查找设定的性能参数(如实测比冲),若找到,提取该行,添加到字符串中。
2) 依次取出该字符串的每一行,分割出前12 个字符,再取出前3 个字符(推进剂序号),转换成整数,再转成字符串。其功能是,若推进剂序号前有0,则去掉;再和该行的后面部分连接,对性能“实测比冲”运行程序至此,结果如图2 所示。
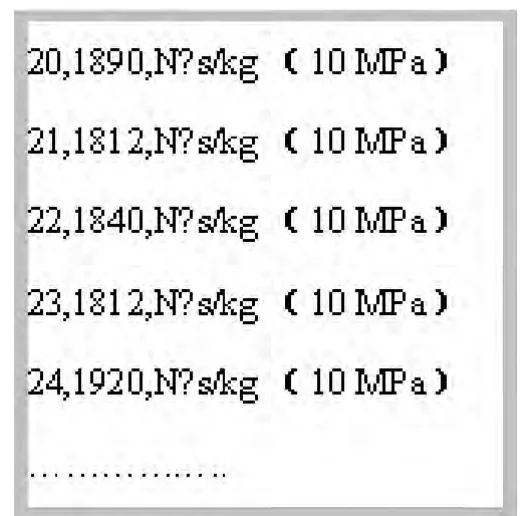
图2 查找并处理性能"实测比冲"的结果Fig. 2 The results of find and processing performance
3)分析可见,每一行由5 部分组成,分别是①推进剂序号;②实测比冲值;③比冲单位;④压强值;⑤压强单位。
4)运行程序功能函数pickoutNum(),得①、②、④3 个数值部分;运行程序功能函数pickoutChinese(),得③、⑤单位部分。
5)将数值部分分割,把每一数值部分分别保存到相应的数组矩阵中;将单位部分分割,把每一单位部分分别保存到相应的数组矩阵中。
6)运行程序功能函数writeToExcel(),将数组矩阵分别写入excel 文件的相应位置。
7)将excel 文件中的数据导入到数据库中。
性能指标的处理,分为多个步骤是为便于说明,实际操作中,运行程序,可一次完成上述的1)~6)步骤。
2.2 简单结构表格数据的处理
对简单结构表格如表1 所示。

表1 原始文档简单表格结构Tab. 1 A simple table structure of the original document
提取该文档性能数据,其方法步骤为:
1)依次读取文档的每一行,赋值给一字符串变量string1;
2)对string1,运行程序的strRplace()函数,将字符串“厘米2”替换为“厘米平方”;
3)去掉string1 的前后空格,提取前两个字符,作为推进剂编号,保存到数组tuijinji[]中;
4)去掉string1 的前11 个字符,得字符串string2;
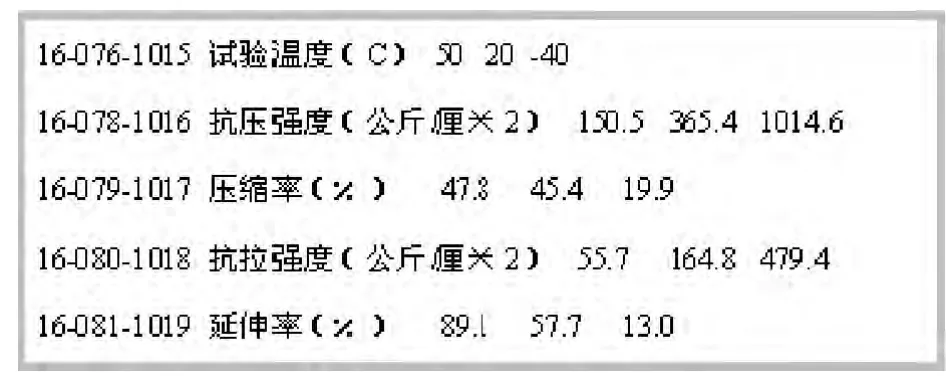
图3 表1 数据添加行序号后结果Fig. 3 The results of table 1 data after adding line number
5)对string2,运行程序的strChinese()函数,提取中文字符string3;
6)以“(”为分隔符,分割string3 为两部分,前一部分为性能参数,保存到数组xingneng[]中,后一部分去掉末位字符“)”后为性能单位,保存到数组danwei[]中;
7)对string2,运行程序的strNum()函数,提取数字部分并保存到string4;
8)以空格为分隔符,分割string4 为3 个数值,保存到数组value[5][3]中,第一维为行号,第二维为列号;
9)运行程序功能函数writeToExcel(),分别将数组tuijinji[]、xingneng[]、danwei[]、value[][]写入excel 文件的相应位置。
10)将excel 文件中的数据导入到数据库中。
2.3 复杂结构表格数据的处理
对如图3 所示具有复杂表格结构的燃速数据,每个数据都和测量条件温度及压力有关,且又分为3 批次测量。 该表格转换成.txt 文档后,如表2 所示。

表2 原始文档复杂表格结构Tab. 2 The original document complex table structure
提取该文档性能数据,其方法步骤为:
1)对图6 所示的文档,运行strReplace()函数,替换字符串“D1”、“D2”、“D3”为“D 一”、“D 二”、“D 三”;
2)读取文档第1 行,赋值给字符串变量string1,提取前两个字符,作为推进剂编号, 保存到数组tuijinji[]中;
3)去掉string1 的前后空格,去掉前11 个字符,运行strSplit()函数,将分割所得部分分别保存到数组xingneng[]和数组danwei[]中;
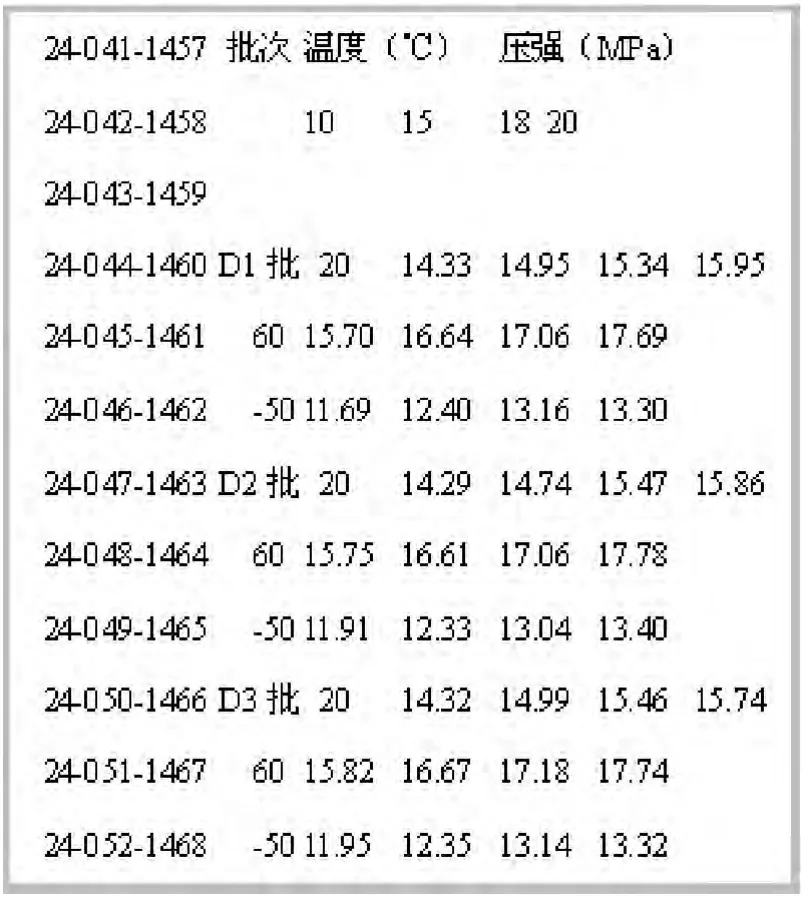
图4 表2 数据添加行序号后结果Fig. 4 The results of table 2 data after adding line number
4)读取文档第2 行,去掉前11 个字符,运行strNum()函数,再运行strSplit()函数,将分割的4 个数值保存到yaQiang[]数组中;
5) 分别读取文档的第4+3*0 行、4+3*1 行、4+3*2 行,去掉前11 个字符,再用pickoutNum(string) 去掉中文字符,得string2,再用strSplit(string1)函数,得数字字符串数组,读取的第一个是温度值,保存到数组wendu[]中;其它数值是燃速值,保存到燃速数组ransu[][]中。 该数组的第一维为温度参数,第二维为压强参数。
6) 分别读取文档的第5+3*0 行、5+3*1 行、5+3*2 行,去掉前11 个字符,再用pickoutNum(string) 去掉中文字符(该步骤也可不用),得string3,再用strSplit(string1)函数,得数字字符串数组, 读取的第一个是温度值, 保存到数组wendu[]中;其它数值是燃速值,保存到燃速数组ransu[][]中。
7)分别读取文档的第6+3*0 行、6+3*1 行、6+3*2 行,其后方法同步骤6)。
8)运行程序功能函数writeToExcel(),分别将数组tuijinji[]、xingneng[]、danwei[]、wendu[]、yiQiang[]、ransu[][]写入excel 文件的相应位置。
9)将excel 文件中的数据导入到推进剂定型配方数据库中相应的数据表内。
3 结束语
数百个火药推进剂配方,数百个性能属性,数十万个性能数据,根据功能和属性的不同,本文设计了燃速、燃速经验公式、燃速温度系数、机械性能、安全性能、能量特性、燃气成分等10 多个数据库表,按照文中介绍的方法和步骤,编程实现了对原始文档数据的自动提取及自动分类入库。 实践表明,文中所给出的方法是有效且高效的。 虽然文中只是针对推进剂数据的处理,但其方法,可广泛应用于其它行业的数据自动提取及分类入库,对数据的有效管理和高效使用有积极的意义。
[1] Arunasalam B. Chawla S CCCS. a top-down associative classifier for imbalaneed class distribution [C]//In Proc.of 2006 Int.Conf.onKnowledge Diseovery and Data Mining,2006:517-522.
[2] Verhein F,Chawla s. Using Signficant Positively Associated and Relatively Class Correlated Rules for Associative Classification of Imbalanced Datasets [C]//InProc.of 2007 IEEE Int.Conf.on Data Mining,2007:679-684.
[3] Hinton G E,Salakhutdinov R R. Redueing the dimensionality of data with neural networks [J]. Seience,2006,313(5786):504-507.
[4] Gao B,Liu T Y,Ma W Y. Star-structured high-order heterogeneous data co-clustering based on consistent information theory [C]//In: Processing of the 6th International Conference on Data Mining,2006:880-884.
[5] Luxburg U V. A tutorial on special clustering [J]. Statistics and Computing,2007,17(4):395-416.
[6] Luxburg U V,Belkin M. Bousquet O. Consistency of spectral clustering[J]. Aunals of Statistics,2008,36(2):555-586.
[7] 张卓然. 基于ArcSDE的地形数据入库互操作研究[D]. 长沙:湖南大学,2008.
[8] 肖景娴,李斌. 色谱工作站中分析数据的自动处理[J]. 现代科学仪器,2009,10(5):55-56.
XIAO Jing-xian,LI Bin. Auto-process of analytical data in chromatography workstation[J].Modern Scientific Instruments,2009(5):55-56.
[9] 马春华. 基于现场总线的卷烟入库数据采集系统[J]. 自动化技术与应用,2006(10):71-73,86.
MA Chun-hua. Fieldbus based-data acquisition system for cigarette warehouse [J]. Techniques of Automation and Applications,2006(10):71-73,86.
[10]魏柳,谷光裕,杨威. 地震前兆数据的自动传输与入库[J].东北地震研究,2002(3):65-67.
WEI Liu,GU Guang-yu,YANG Wei. Automatic transfer and input of digital seismic prcusory data[J]. Seismological Research of Northeast China,2002(3):65-67.
[11]杨琳. 城市绿化数据生产及研究入库[D]. 上海:上海师范大学,2009.
猜你喜欢
中学生数理化·自主招生(2022年9期)2022-05-30 10:48:04
心理学报(2022年4期)2022-04-12 07:38:02
能源工程(2021年6期)2022-01-06 02:04:38
水泵技术(2021年3期)2021-08-14 02:09:20
电子测试(2018年4期)2018-05-09 07:28:12
当代化工研究(2016年9期)2016-03-20 16:22:13
中国惯性技术学报(2015年1期)2015-12-19 13:12:17
计算机工程(2015年4期)2015-07-05 08:28:04
西华师范大学学报(自然科学版)(2015年3期)2015-02-27 15:31:22
中国质量与标准导报(2014年7期)2014-02-28 22:24:35
