
BWDSP SIMD编译的寄存器分配优化技术研究※
2015-08-15 06:26:03王昊王向前
单片机与嵌入式系统应用 2015年4期
王昊,王向前
(中国电子科技集团公司第三十八研究所,合肥230088)
BWDSP SIMD编译的寄存器分配优化技术研究※
王昊,王向前
(中国电子科技集团公司第三十八研究所,合肥230088)
BWDSP是一款自主设计的国产VLIW(超长指令字)数字信号处理器,支持SIMD技术,其SIMD指令可以在4个宏上同时执行4个32位计算,对寄存器使用有特殊规则,Open64编译器的寄存器分配策略并不适用于这种规则。本文对BWDSP SIMD指令的寄存器分配优化技术进行了研究,并在BWDSP的编译器OCC上得以实现。
DSP;SIMD;寄存器分配
引言
BWDSP[1]是一款32位静态超标量浮点数字处理器,采用超长指令字(Very Long Instruction Word,VLIW)架构,支持SIMD技术。BWDSP核内包含4个基本执行宏,代号是X、Y、Z、T,每个宏由算术逻辑单元(ALU)、乘法器(MUL)、移位器(SHF)、超算器(SPU)和一个通用寄存器组成。
BWDSP最多可以同时执行16条指令,其SIMD指令有其特殊性,本质上就是多条相同的指令并发执行,下面将对其特性进行分析,说明BWDSP编译器的寄存器分配需要特殊的优化技术来满足SIMD指令的要求。
1 BWDSP SIMD指令的特性分析
BWDSP计算指令的通用格式如下:
[Macro]Rm=Rnop Rs
Macro是执行宏的代号,op是操作,符号“||”连接多个可并行指令,比如:xRm=Rn+Rs是Scalar指令,表示在X宏上执行整数加法操作;xyztRm=Rn+Rs是SIMD指令,表示在X、Y、Z、T四个宏上同时执行整数加法操作,等同于xRm=Rn+Rs||yRm=Rn+Rs||zRm=Rn+Rs||tRm=Rn+ Rs。图1是BWDSP SIMD add指令的执行示意图。

图1 BWDSP SIMD add指令执行示意图
Intel x86-64 CPU[2]也有SIMD加法指令:
paddd xmmi,xmmk
表示xmmk=xmmi+xmmk,形式很像BWDSP的Scalar加法指令。图2是Intel x86-64的paddd指令执行示意图。
比较以上两种类型的SIMD加法指令,总结4点区别如下:
① x86-64的 paddd指令只需要一个核执行;而BWDSP SIMD add指令需要多个宏同时执行。
②x86-64的paddd指令只需要使用一个加法器;而BWDSP SIMD add指令使用4个加法器。

图2 Intel x86-64 paddd指令执行示意图
③x86-64 CPU为支持128位SIMD数据操作,增加了128位全新的XMM寄存器,这些XMM寄存器属于同一类;而BWDSP只有32位通用寄存器,BWDSP SIMD add指令需要的寄存器在多个宏上,分属不同寄存器类。
④BWDSP SIMD add指令为相同位置的操作数分配的不同宏上的寄存器,其编号必须相同,如图1中4个宏的结果寄存器的编号都是0,而x86-64没有这种约束条件。
以上4点也是对BWDSP SIMD指令特性的分析,接下来本文将对OCC编译器现有的寄存器分配策略进行分析,说明其还无法满足BWDSP SIMD指令的这些特性,需要设计更有针对性的寄存器分配优化技术。
2 BWDSP Scalar指令的寄存器分配策略
在机器硬件结构中,寄存器的数量远小于内存,但它们是存储层次结构中最快的介质,也是关键资源之一。为提高程序运行速度,源程序中用户定义的变量应该最大限度地映射到寄存器上。寄存器分配是编译器后端的重要阶段,在寄存器分配之前,中间代码使用虚拟寄存器,数量不受限制,寄存器分配就是把这些虚拟寄存器映射到物理寄存器上的过程。
寄存器分配有一个重要的基本概念——生命期(Live Range,LR),是指一个值从定义到最后一次使用之间的活跃范围,通常用活跃的基本块的集合描述。寄存器分配就是为LR分配寄存器。BWDSP的编译器OCC是以Open64[3]为基础开发的,Open64编译器的寄存器分配分为两类:全局寄存器分配(Global Register Allocation,GRA)和局部寄存器分配(Local Register Allocation,LRA)。全局寄存器分配在一个函数范围内,为活跃范围超出一个基本块的LR分配寄存器;局部寄存器分配在一个基本块范围内,为只活跃在基本块内部的LR分配寄存器。
2.1 全局寄存器分配
OCC采用Chaitin/Briggs的图着色算法[5]实现全局寄存器分配,流程如图3所示。
GRA_Create过程创建全局寄存器分配的冲突图,分为3个子过程:

图3 图着色算法实现全局寄存器分配流程
①Create_LRANGEs创建生命期;
②Create_LiveBB_Sets为每个生命期创建活跃基本块集合;
③ Create_Interference_Graph创建冲突图。
GRA_Color过程执行Chaitin/Briggs的图着色算法为生命期分配寄存器,分为3个子过程:
①GRA_Grant_Some_Locals在全局寄存器分配之前为局部寄存器分配预留一些寄存器,这些寄存器不会参与全局寄存器分配;
②Simplify对冲突图进行着色,能够着色的结点会被分配寄存器;
③GRA_Note_Spill对不能着色的结点标记为溢出结点。
GRA_Spill过程对溢出的生命期在活跃范围内插入相应的存取操作,在生命期的赋值操作后插入一条store指令,在该生命期的每个引用之前插入一条load指令。
2.2 局部寄存器分配
OCC采用线性扫描局部寄存器分配策略,从程序的开始向后依次扫描各个基本块,流程如图4所示。
Init_Avail_Regs初始化可用寄存器,Setup_Live_Ranges bb为基本块bb中的局部TN创建生命期,Assign_Registers (bb,&spill_tn)遍历bb中的所有操作,为其中的局部TN分配寄存器,成功则返回TRUE,失败则返回FALSE,spill_tn是寄存器分配失败的局部TN。如果失败,调用Fix_LRA_ Blues,释放一个已分配但在bb中没有引用的全局寄存器(在bb的Entry部分插入store指令,在bb的EXIT部分插入load指令),然后把该寄存器分配给spill_tn。

图4 线性扫描局部寄存器分配流程
3 BWDSP SIMD寄存器分配优化技术
3.1 Scalar指令寄存器分配策略的不足
第2节详细介绍了BWDSP Scalar指令的寄存器分配策略,但它无法满足BWDSP SIMD指令的寄存器分配要求,主要是因为Scalar指令的寄存器分配策略有如下两点不足:
①无法同时在BWDSP四个宏上分配寄存器。根据第1节对BWDSP SIMD指令的特性分析可知,一个Scalar指令的某个操作数位置需要映射到对应宏(由分簇阶段确定)上的一个寄存器,而一个SIMD指令的某个操作数位置需要映射到4个宏上的4个寄存器,并且要求编号相同。因此Scalar指令的寄存器分配策略目前无法满足SIMD指令对寄存器分配的要求。
②SIMD指令的寄存器分配引入的寄存器溢出操作开销太大。SIMD指令都是在for循环内部,操作数只活跃在一个基本块内部,其寄存器分配是由局部寄存器分配完成的。由2.2节可知,当Assign_Registers(bb,&spill_tn)失败时,需要溢出一个全局寄存器,如果Assign_Registers失败多次,就需要溢出多个全局寄存器,而这些溢出操作都要插入到for循环体内部。一方面,SIMD指令对寄存器的需求量大(一个运算类SIMD指令最多需要12个通用寄存器),寄存器分配失败可能会引入大量的溢出操作;另一方面,循环次数越多,溢出操作带来的额外开销就越大。由此带来的副作用可能会抵消SIMD指令对程序的加速作用,因此应该想办法弥补这个不足。
3.2 SIMD指令寄存器分配优化策略
BWDSP SIMD指令的寄存器分配优化策略是在Scalar指令寄存器分配策略基础上有所创新,是对前者的补充,两者综合在一起满足为两类指令分配寄存器的需求。SIMD指令寄存器分配优化策略需要弥补Scalar指令寄存器分配策略的不足,一方面必须能同时在BWDSP四个宏上分配寄存器,另一方面要消除与SIMD指令相关的寄存器溢出操作。
OCC后端的SIMD指令产生过程如图5所示,SIMD指令寄存器分配优化策略涉及其中3个阶段,分别是SIMD指令WHIRL中间表示产生、全局寄存器分配和局部寄存器分配,下面将逐一对各阶段的优化技术进行详细介绍。
3.2.1 GRA为SIMD指令预留寄存器
SIMD指令的寄存器由LRA阶段分配,只能分配caller-save寄存器(调用函数负责保存的寄存器),GRA先于LRA执行,因此GRA阶段需要为LRA预留适量的callersave寄存器,保证 Scalar指令和SIMD指令有足够的寄存器可供分配。但GRA又不能把所有callersave寄存器都预留给LRA,需要保障自身有充足的可分配寄存器。根据BWDSP的寄存器使用规则,每个宏上可供分配的caller-save寄存器有30个,根据经验选取其中12个编号连续的寄存器预留给LRA使用,4个宏上一共有48个寄存器。
3.2.2 优化SIMD指令WHIRL中间表示产生模块
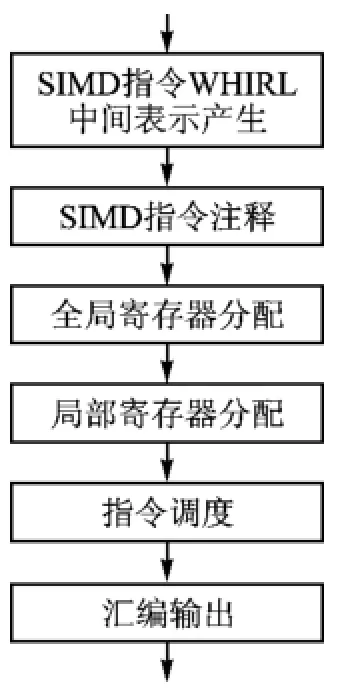
图5 编译器后端SIMD指令产生过程
理论上,一个for循环体内的SIMD指令数量是没有限制的,但由2.2节可知,当LRA失败时会产生溢出操作,而且额外开销很大,应当避免。考察BWDSP的指令集可知一个SIMD运算指令在一个宏上最多使用3个寄存器(4个宏上共使用12个寄存器)。为了不产生溢出操作,根据GRA预留的寄存器数量,每个for循环体内最多可以有4条SIMD运算指令。
当一个for循环体内的SIMD运算指令多于4个时,需要把该循环拆分成多个小循环,保证每个小循环体内最多只有4条 SIMD运算指令。这个判断拆分过程要在SIMD指令的WHIRL中间表示产生模块中进行,因此要对原有的产生模块进行优化,图6显示了原有的 SIMD WHIRL中间表示产生过程,图7显示了为配合SIMD指令寄存器分配而做的优化过程。

图6 原有的SIMD WHIRL中间表示产生过程
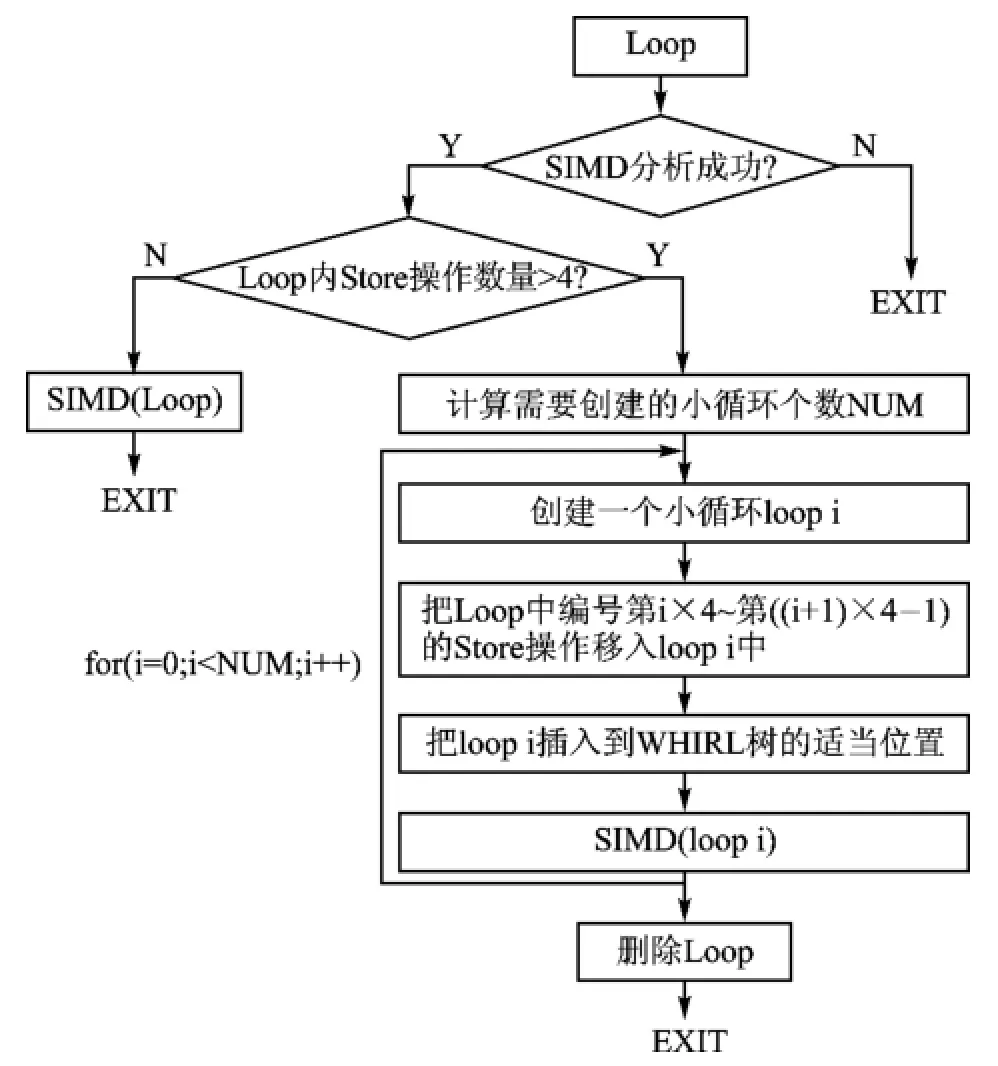
图7 优化后的SIMD WHIRL中间表示产生过程
在优化过程中,如果一个Loop经过分析可以做SIMD优化,还要判断其内部的Store操作(每个SIMD WN的顶层OPC都是Store)数量是否大于4。如果不大于4,直接执行SIMD(Loop),产生Loop的SIMD WHIRL中间表示;如果大于4,就要把Loop拆分成多个小循环,并对每个小循环分别执行SIMD处理过程,产生各自的SIMD WHIRL中间表示。以上的优化过程限制了小循环的体积,保证了SIMD指令在LRA阶段不会产生额外的寄存器溢出操作。
3.2.3 优先为SIMD指令分配寄存器
经过上面两个优化过程,保证在LRA阶段有足够的寄存器可以分配给SIMD指令,不会产生寄存器溢出操作,接下来就要解决LRA无法同时在BWDSP四个宏上分配寄存器问题。LRA阶段为SIMD指令分配寄存器的优化方法的程序原型略——编者注。
针对BWDSP SIMD指令的特点,程序原型采取的优化方法解决了LRA的两个关键问题:
①保证SIMD指令有足够可分配的寄存器。函数Assign_Registers为基本块bb中的操作(OP)分配寄存器,其中的函数Init_Insts_Vector为 bb生成 OP序列 Insts_ Vector,在Insts_Vector中,SIMD操作排在Scalar操作之前。接下来,函数Assign_Registers_For_OP按照Insts_Vector内的顺序依次为各个OPs分配寄存器,因此SIMD指令会被优先分配寄存器,这就保证了SIMD指令有足够可供分配的寄存器。
②保证SIMD指令的操作数能够同时获得4个宏上相同编号的寄存器。函数Allocate_Register为虚拟寄存器tn指派物理寄存器,其中的函数Get_Avail_Reg获得一个可用的物理寄存器(reg是寄存器编号)。如果tn是SIMD指令的操作数,调用函数Delete_Avail_Reg把X、Y、Z、T四个宏上同为编号reg的寄存器都标记为已使用,这样该tn所代表的SIMD指令的操作数就同时获得了4个宏上相同编号的寄存器。
结语
本文详细介绍了如何在编译器 OCC上实现为BWDSP SIMD指令分配寄存器的优化技术,该技术紧密结合BWDSP SIMD指令的特殊规则,可以与已有的Scalar指令寄存器分配策略有机整合在一起,相辅相成,共同满足为BWDSP的两类指令分配寄存器的需求。
编者注:本文为期刊缩略版,全文见本刊网站www. mesnet.com.cn。
[1]王昊,黄光红.基于BWDSP100的传播分簇算法研究与实现[J].中国集成电路,2014(8):24-28.
[2]Vernon Turner.White Paper Intel Announces Xeon Processor with 64-Bit Extensions[EB/OL].[2014-12].http://developer.intel.com/technology/64bitextensions/IDC_Intel_Xeon_ Whitepaper.pdf.
[3]University of Houston.Overview of the open64 Compiler Infrastructure[EB/OL].[2014-12].http://www2.cs.uh.edu/~dragon/Documents/open64-doc.pdf.
[4]SGI Inc.Whirl intermediate language specification[EB/OL]. [2014-12].http://open64.sourceforge.net.
[5]Briggs P,Cooper K,Torczon L.Improvements to Graph Coloring Register Allocation[J].ACM Transactions on Programming Languages and Systems,1994,16(3):428-455.
王昊(工程师),主要研究方向是DSP编译器设计。
Register Allocation Optimization Technology Based on BWDSP SIMD Compilation※
Wang Hao,Wang Xiangqian
(No.38th Research Institute,China Electronic Technology Group Corporation,Hefei 230088,China)
BWDSP is a self-designed home made VLIW(Very Long Instruction Word)digital signal processor,which supports SIMD technology.BWDSP SIMD instructions can execute four 32-bit computing in four macros simultaneously.BWDSP SIMD instructions have special rules of register usage,but Open64 register allocation strategy is not fit for these rules.This paper carries out research on register allocation optimization of BWDSP SIMD instructions,and the actual process has been implemented on the BWDSP OCC compiler.
DSP;SIMD;register allocation
TP314
A
薛士然
2014-12-01)
猜你喜欢
小型微型计算机系统(2022年5期)2022-05-10 08:45:42
计算机工程(2021年3期)2021-03-18 08:03:34
计算机与现代化(2020年8期)2020-08-17 13:59:50
铁道通信信号(2020年7期)2020-02-06 09:04:50
大气科学学报(2017年3期)2017-05-30 10:48:04
项目管理技术(2015年10期)2015-12-26 09:36:04
传感器与微系统(2014年1期)2014-09-20 08:03:28
组合机床与自动化加工技术(2014年10期)2014-03-01 02:22:05
智能建筑与智慧城市(2014年2期)2014-02-27 05:28:38
哈尔滨工程大学学报(2011年6期)2011-04-13 09:20:22
