
基于Cortex-M4的MJPEG视频解码算法优化
2015-08-10 12:47:12方兆龙刘凌云杨东平
湖北工业大学学报 2015年4期
方兆龙,刘凌云,江 波,杨东平
(1湖北工业大学电气与电子工程学院,湖北武汉430068;2湖北工业大学太阳能高效利用湖北省协同创新中心,湖北武汉430068)
MJPEG(Motion-Join Photographic Experts Group)即运动静止图像(或逐帧)压缩技术,它是在静态图像压缩技术JPEG的基础上发展起来的动态图像压缩技术[1]。MJPEG把运动的视频序列作为连续的静止图像来处理,只考虑帧内压缩而不考虑帧间压缩,压缩倍数为1/80~1/20倍[2]。这种压缩方式能够单独对某一帧进行压缩处理,在编辑过程中可随机存储每一帧。MJPEG采用渐层式技术,先发送低解析的图档,再补送细部资料,可以获取清晰度很高的视频图像,而且可以灵活设置每路的视频清晰度和压缩帧数[3]。它的压缩和解码是对称的,可以用相同的硬件和软件实现。由于不对视频流的帧间进行时间冗余压缩处理,所以压缩效率不是很高,存储占用空间达到每帧8~15 K字节,最好能做到每帧3 K字节,如果采用高压缩比会严重降级视频质量。然而在对帧数要求不高的情况下,MJPEG的这个弱点却使它拥有很好的性价比[4-6]。如网络摄像机等只要求持续监控,对图像清晰度和刷新率要求不高,它能够在有限网络资源支持下将清晰的画面迅速传送到监控端,因此MJPEG适用于公共场合、公司等场合的视频监控。
视频解码系统根据应用场合不同有多种硬件实现方案,实现高清编解码硬件一般采用专用芯片或者DSP芯片。但是这些芯片有的不支持解压缩,有的仅在功能上支持而没有成熟的核函数,而且价格昂贵。本文采用的Cortex-m4内核的STM32F4系列微处理器,具有微控制器和数字信号处理器的功能,最高主频达168 MHz,支持多种低功耗模式,DSP指令和FPU使它在视频图像处理方面具有很大的优势。综合Cortex-M4硬件的低成本高特性和MJPEG视频解码算法的实时清晰性,在视频监控工程中采用这种方案拥有很好的性价比。
1 MJPEG视频解码的硬件结构
硬件系统采用ARM Cortex-M4处理器内核的STM32F407ZGT6芯片为实验平台,利用SDIO端口读取SD卡里的AVI视频文件到芯片内存中,然后利用芯片的DSP指令和FPU浮点运算以及ART自适应实时加速器功能对视频压缩数据流进行连续解码,解码后的图像帧通过FSMC接口在LCD屏上实现播放清晰的视频。硬件平台的结构如图1所示。
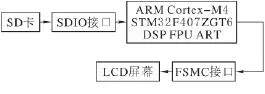
图1 硬件系统图
2 MJPEG视频解码流程
由于MJPEG是在JPEG基础上发展起来的,而且MJPEG只考虑帧内的空间冗余,而不考虑帧间的时间冗余,它把连续的视频图像当作一个个静止图像处理,因此它的解码算法核心还是JPEG算法。在满足视频监控实时性要求的情况下,本文对一帧图像的JPEG解码算法进行优化处理。如图1所示,JPEG图像解码主要包括Huffman解码、反量化、IDCT这三个部分,开始还要经过预处理获取视频解码所需的各种信息和压缩数据,最后还要经过颜色空间转换才能实现图像的显示。
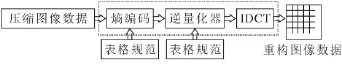
图2 JPEG解码流程图
3 Cortex-M4硬件平台优势
由于嵌入式程序受硬件资源的限制,因此实现视频解码需要充分利用Cortex-M4硬件平台资源。Cortex-M4内核采用32位、多重AHB总线矩阵和多通道DMA控制器,能够实现程序执行和数据传输的并行处理,数据传输速率得到很大提升。它还拥有192KB的SRAM和自适应实时加速器ART,SRAM是CPU和外部主存的高速缓冲器。如果CPU访问的数据已经预存到SRAM中,就不用等待去外存中完成数据的搬移,SRAM连接到I-Bus可以加快程序执行速度,SRAM连接到D-Bus可以加快获取数据,因此可以将经常使用的数据指令成组读到SRAM中,提高运算效率。Cortex-M4具有浮点运算单元(FPU),支持所有的ARM单精度数据处理指令和数据类型,通过内置单精度FPU提升算法的执行速度,利用Cortex-M4自带的DSP指令和浮点运算功能提高视频图像处理质量。采用浮点功能的指令对比见图3。

图3 浮点指令性能对比
4 MJPEG视频解码算法的优化实现
目前主要的优化处理方式:离散余弦变换采用并处方式;以增加储存容量的代价来换取速度的提高;根据输入图像的频率特点,采用自适应改变量化等级数,即对图像变换后的低频分量和高频分量进行不同步长的自适应量化。综合考虑以上方法和对比其他软硬件平台,本文的重点是利用硬件平台Cortex-M4的优势实现MJPEG视频解码,在降低硬件成本的情况下,极大提高图像的质量,更注重方案的工程实际应用价值。
4.1 Huffman解码和反量化的优化实现
Huffman解码一个MCU得到亮度和色度的一维64位元素的数组,数组中第一个元素解码称为直流解码,剩余的63个元素解码称为交流解码。直流系数DC由于前后块间存在相关性,一般采用DPCM编码,而交流系数AC采用RLE编码,因它们的编码特点不同,所以解码时要采用不同的Huffman表。人眼对亮度比色度敏感,编码过程中对色度的压缩比亮度大,因此两者的解码表也不同。一个MCU解码单元需要4个huffman表。反量化是将霍夫曼解码得到的数组中的元素与量化表中对应位置的元素相乘的过程,也需要2个量化表,分别对应亮度和色度。这两个过程实际上是一个查表的过程,如果将压缩数据流逐个输入,查找huffman表和量化表直到找到正确的码表,将耗费大量的存取操作,降低了整个系统的速度。Cortex-M4内核含有192KB的SRAM和自适应实时加速器ART,而查表是不断重复的操作,因此可以将huffman表和量化表存取到片内数据存储器中。当从输入码流中读取一个MCU时,可以实现快速查表解码,而不用到外存中去查表,节省了大量的查表解码时间。
4.2 IDCT的优化实现
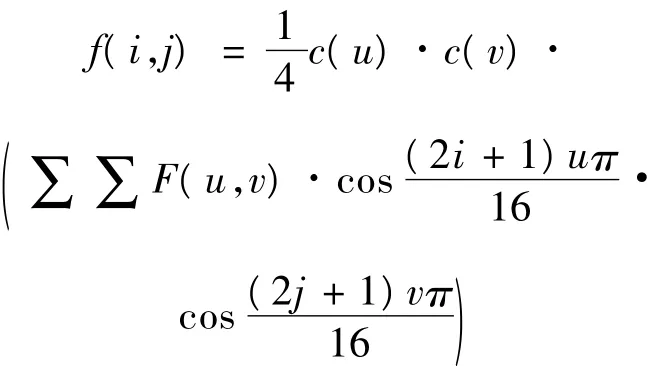
把图像数据从频率域变换到空间域,离散余弦反变换(IDCT)变换公式如上式。考虑这个公式的运算量,可以采用行列分离算法完成IDCT的硬件实现,而行列分离算法就是把二维IDCT变成2个一维IDCT,即先对数组的行进行8次一维IDCT,再对列进行8次一维IDCT,使得计算复杂度降低。转换公式如下
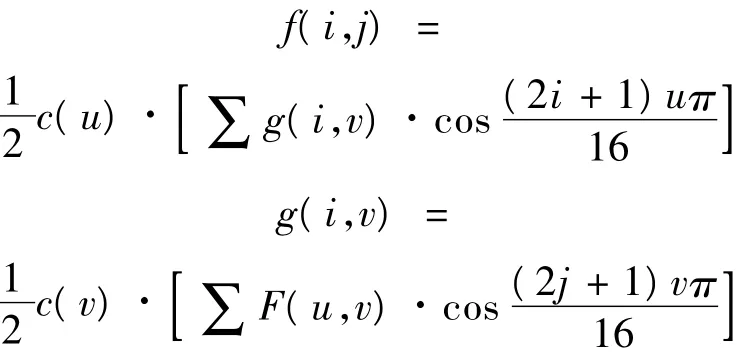
本文离散余弦反变换部分采用Arai算法,因为相比其它算法,它只需要13次乘法和29次加减法,而其中8次乘法可以合并在前面的反量化部分,所以Arai算法实际上只需要5次乘法和29次加法。它采用二维变一维以及奇偶分开处理方式,一维IDCT流程图见图2。
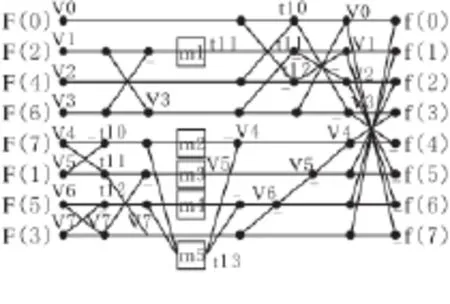
图4 1维IDCT变换
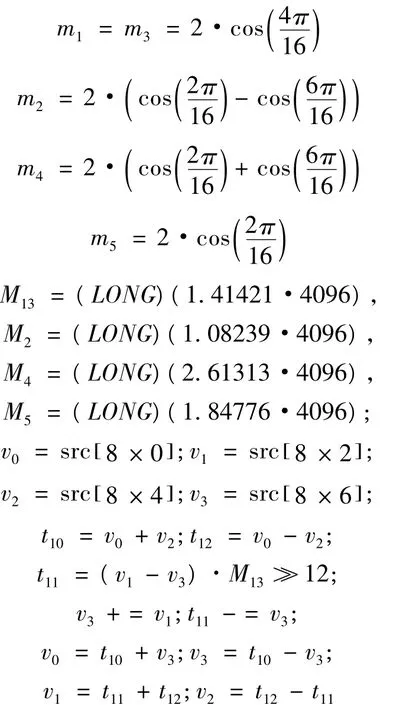
上述代码是一列中偶数点的IDCT运算程序,它们只是简单的加减法和与常数的乘法运算,理论上IDCT运算的复杂度已经降低很多。但是Cortex-M4内核含有DSP指令和单精度浮点运算功能,可以有效提高代码执行效率,减少了定点算法的缩放比和饱和负荷。Cortex-M4是32位处理器,乘法累加MAC能够在单周期内完成一个32×32+64→64或2个16×16的运算,为其它任务释放了处理器的宽度。在解码过程中IDCT系数占用连续的16位宽数据,可以利用SIMD指令将2个16位打包进行并行的读写运算,实现一次读取2个系数即32位宽,提高代码执行效率。而DSP指令库函数含有数学函数,利用这些函数改写上述程序将提高速度。因为一般的硬件平台没有浮点运算单元,通常将浮点转成定点进行处理。原程序中对变换系数采取了定标处理,将它们左移12位变成定点处理。因此可以利用Cortex-M4平台的DSP指令和浮点功能对上述程序进行优化,变换代码如
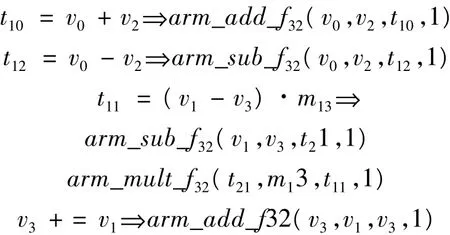
4.3 颜色空间变换的优化实现
经过上述步骤解码出来的信号是YCbCr格式,由于人眼的视觉特性,这种格式有利于压缩处理,但是它需要转换成RGB信号才能在屏幕上显示。其转换公式为
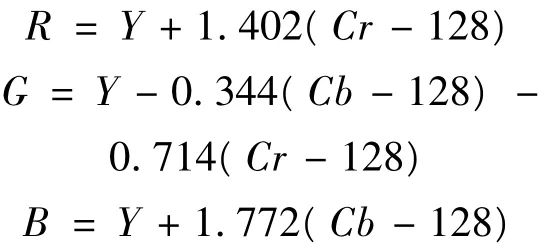
这个变换公式中存在浮点运算,因此也可以运用Cortex-M4内核的DSP指令和浮点运算库函数对它们进行改写替换。完成上述所有操作后,就可以在LCD屏上显示动态连续播放的视频(图5)。

图5 LCD屏播放的视频
5 结束语
本文以JPEG算法为基础对MJPEG的视频解码算法进行分析和优化处理,结合硬件平台Cortex-M4的资源优势,利用它的DSP指令和浮点运算功能对离散余弦反变换和颜色变换部分进行重点优化,而对比较耗时的依据Huffman表和量化表进行查表解码的过程,利用自适应实时加速器功能将他们预存取到内存缓冲区,提高了代码运算精度和运算效率。虽然MJPEG压缩比不是很高,但在视频清晰度要求不高的情况下,它的性价格比却很高。如小区、企业视频监控等地方,利用Cortex-M4硬件平台研发相关产品,既能降低硬件成本又能保证实时性清晰监控图像要求。
[1]魏忠义,朱 磊.基于DSP的JPEG图像解码算法的实现[J].多媒体技术,2004,193(02):66-70.
[2] 杨贵臣,王 双,全子一.高清MJPEG2000编解码系统的设计[J].视频技术应用与工程,2005,281(11):85-87.
[3] 王丽霞,李巴津.JPEG算法的改进[J].电脑开发与应用,2004,30(11):48-48.
[4] 薛永林,刘 珂,李凤亭.并行处理JPEG算法的优化[J].电子学报,2002.30(02):160-162.
[5] 王 海,刘彦隆.基于JPEG图像压缩算法的研究[J].科技情报开发与经济,2010,20(10):108-200.
[6] Miodrag Potkonjak,Anantha Chandrakasan.Synthesis and selection of dct algorithms using behavioral synthesisbased algorithm space exploration[J].IEEE,1995,121(02):65-68.
猜你喜欢
科普童话·神秘大侦探(2023年1期)2023-05-30 12:48:10
现代装饰(2022年4期)2022-08-31 01:41:24
中国石油石化(2022年12期)2022-07-16 08:28:28
今日农业(2021年9期)2021-07-28 07:08:36
中国外汇(2019年19期)2019-11-26 00:57:32
成都信息工程大学学报(2018年4期)2019-01-23 06:57:18
家庭影院技术(2018年11期)2019-01-21 02:20:50
家庭影院技术(2018年11期)2019-01-21 02:20:48
信息安全研究(2018年12期)2018-12-29 11:01:56
测控技术(2018年5期)2018-12-09 09:04:26
