
非监督式层次话题情感模型在网络评论主题发现中的应用
2015-08-01 02:50陈永恒姚桂杰林耀进
东北石油大学学报 2015年1期
陈永恒,姚桂杰,林耀进
(1.闽南师范大学计算机学院,福建漳州 363000; 2.中国石油天然气股份有限公司大港石化分公司,天津 300280)
非监督式层次话题情感模型在网络评论主题发现中的应用
陈永恒1,姚桂杰2,林耀进1
(1.闽南师范大学计算机学院,福建漳州 363000; 2.中国石油天然气股份有限公司大港石化分公司,天津 300280)
自动发现话题的隐含结构、情感的极性及其关系,可以方便用户从海量网络评论集中快速获得他们关注的主要观点.提出一种基于非监督式的层次话题的情感(Unsupervised Level Aspect-Sentiment,ULAS)模型,利用贝叶斯非参数性模型作为先验知识,实现非监督式发现未标记评论文本集话题的层次结构,分析层次话题的情感极性.实验结果表明,相比传统的JST和ASUM模型,ULAS模型具备较高的分类精确度和较强的模型泛化能力,能够解决传统话题情感模型只能在单一粒度话题层进行情感分析的问题,实现多粒度话题层的情感分析,满足用户对于评论对象不同粒度话题的情感信息需求.
非监督式层次话题情感模型;隐藏狄利克雷分配;文本分析;网络评论;主题发现;主题模型;非参贝叶斯模型
0 引言
网络评论文本集中隐含产品话题及消费者情感极性信息,如在笔记本电脑的评论信息中,一般包含笔记本电脑的质量、电池、屏幕及CPU等比较集中的话题信息.在购买笔记本电脑前,消费者希望通过查看其他用户的评论信息,了解产品各话题的情感信息,主要包括产品是否值得购买及产品各话题信息的情感倾向等.面对海量且无结构化的网络评论信息,人们难以获得准确的产品特征情感信息[1].近年来,作为非结构化信息挖掘的一个新兴领域——网络评论的挖掘受到人们关注[2].
大部分网络评论挖掘研究忽视话题情感的层次结构,但不论是从消费者还是从技术角度,话题情感的层次结构对于网络评论挖掘具有重要作用:(1)从消费者角度分析,不同消费者需要不同粒度的话题情感信息,如有些消费者比较关注屏幕和CPU等较粗粒度的话题信息,有些消费者比较关注CPU主频和Cache缓存等较细粒度的话题信息.传统的话题情感模型只能进行单一粒度层的话题情感分析,不能满足所有消费者对不同粒度层话题的情感信息需求,而且消费者需要具有层次结构的话题和情感,找到关注的话题及情感评论.(2)从技术角度分析,层次结构的话题和情感便于情感分析.情感词的识别对于情感分析的精确性非常重要,但不同情感词在表达不同话题时,呈现不同的情感极性[3],如情感词“快”,在CPU话题的评论中具有褒义情感极性,在电池话题的评论中具有贬义情感极性,该问题在基于话题的情感分析模型、尤其是非监督模型中常常难以处理.此外,具有明显情感极性但不依赖话题的一般情感词,如“好”、“坏”等,对话题的情感评价作用非常有限[2].现有非监督模型通过分析一般情感词在某段文本中的共现统计,将一般情感词的极性传递给话题情感词,但当一般情感词在话题中出现数量非常少时,一般情感词的极性难以传递给话题情感词[4].根据发现话题及情感极性的层次结构,情感极性可以沿着从一般到特殊的路径传递,进而能够发现准确表达话题情感的情感极性词.
目前,缺少利用话题的层次结构信息实现不同粒度层话题的情感分析的相关文献.笔者提出一种非监督式层次话题情感(Unsupervised Level Aspect-Sentiment,ULAS)模型,实现无标注网络评论文本集中话题情感的层次发现,克服传统话题情感模型只能在单一粒度话题层进行情感分析的缺点.ULAS模型整体结构为一棵树,树的每个节点为一棵两层节点树,节点的树根代表该节点的话题,第二层子节点集合代表该话题的情感极性分布.为了通过非监督形式自动发现语料库中隐含的层次树,使用非参贝叶斯(Bayesian)(recursive Chinese Restaurant Process,rCRP)模型作为先验,构建话题情感树.
1 层次主题模型
由Lin C等提出的JST(Joint Sentiment/Topic)模型是对隐藏狄利克雷分布(Latent Dirichlet Allocation,LDA)模型的一种拓展[4-5].与LDA模型相似,JST模型同样用于文本分析的概率生成模型并遵循词袋假设;不同的是,JST模型除分析文本的主题属性外,还可以分析文本的情感色彩.通过对文本中的主题和情感信息建模,JST模型可以同时获得文本中隐含的主题和情感极性[1].Jo Y等提出层次情感模型(Aspect and Sentiment Unification Model,ASUM),将文本中的句子作为情感表达的最小单位,句子中包含的词具有相同的情感极性[6];与LDA模型不同,ASUM模型和JST模型一样,可以同时对文本中的主题和情感信息建模,并分析文本的主题属性和情感极性[5];ASUM模型和JST模型的不同在于,后者中每个词可能来源于不同的语言模型,前者约束一个单句中的词来源于相同的语言模型,因此推测的每一个语言模型更注重于在文档局部范围内共同出现[1].JST和ASUM模型虽然能够同时获取评论的主题和主题的情感信息,但不能保证获取每个主题的2个对立的情感信息[7].为解决该问题,文献[1]提出主题—对立情感挖掘模型,采用“文档—主题—情感—词”4层产生式结构,实现每个主题下2个对立的情感信息的挖掘.
LDA、JST和ASUM模型能够提高网络评论文本话题情感分析性能,但没有考虑话题本身固有的层次结构.人们研究层次主题模型,如Blei D M和Kim J H等分别提出基于rCRP的分层主题模型[8-9],能够发现文本中隐含主题的层次结构,但是该模型没有建立主题与情感极性的关联,进而应用到情感分析中.
2 层次话题情感模型
根据网络评论语料库中隐含话题和情感的层次结构,定义用于表述该层次结构的话题情感树T,将层次结构自动组织成层次结构树,层次结构树中每个节点由话题和情感极性组成,利用非参贝叶斯方法从文本集中学习和构建T.

图1 话题情感树Fig.1 Subject emotional tree
2.1 话题情感树
话题情感树中每个节点为一棵二层树,称为话题情感节点.每个话题情感节点由话题及话题情感极性组成,话题情感极性为情感词字典的多项式分布.根据话题情感节点的递归定义,话题情感树区分话题(话题情感节点的根节点)和依赖话题的情感极性(话题情感节点包含的子节点集合),实现主题从粗粒度到细粒度的情感极性表达(见图1).由图1可以看出,T中每个节点θi为一颗二层树,树的根节点为节点θi的话题,集合{,,…}为话题的情感极性词分布,其中S为情感极性词的数量.
2.2 文本生成
层次话题情感模型为分层贝叶斯网络模型,由网络评论文本、话题、情感和词组成.对于每篇评论文本d,通过参数η的Dirichlet先验分布得到其情感分布π,η为π的超参数.在ULAS模型的分层贝叶斯网络模型中,文本、句子和词条件相互独立,其概率图模型见图2.其中Nd为评论文本集包含的文本数量,Ns为文本包含句子的数量,Nw为文本包含词的数量,γ和β分别为T、的超参数.利用(S+1)×∞表示无限个词的情感分布.每个词在确定3个参数,即词所在句子的情感极性s、话题情感节点c及词的主观标识p的前提下,通过分布获取.
ULAS模型的生成过程为概率抽样过程,对于网络评论语料库中网络评论文本d∈{d1,d2,…dNd}的每个句子i,di为评论文本集中的第i个文本,生成过程为
(1)根据话题情感树T获取句子i的话题情感节点c,即c~T,其中T~rCRP(γ);
(2)根据情感分布π的多项式分布获取情感极性s,即s~Multinomial(π);
(3)通过超参数α的Beta分布得到句子i的情感主观分布θ,即θ~Beta(α);
(4)对于句子i中每个词j,获取j的主观标识p,即p~Binomial(1,θ);
ULAS模型将句子作为情感极性分配的最小单位,每个句子都具有一个情感极性.对于具有情感极性s的句子i包含的每个单词w,在获得w的主观标识p的基础上,模型利用s×p得到w的情感极性.主观标识p用于表示单词是否具有主观情感,其中p∈{0,1},如在负情感极性的句子中情感词“glare”的主观标识p为1,该单词由归属的话题情感极性产生;非主观情感词“screen”的主观标识p为0,在任何情感极性的句子中都由话题产生.
3 模型推理和学习
直接求解ULAS模型困难,采用相对简单的基于马尔科夫链蒙特卡罗(MCMC)方法的吉布斯抽样(Gibbs Sampling)算法进行求解.该算法由多元概率分布(两个或多个随机样本的联合概率分布)中获取一系列随机样本组成一个马尔科夫链[10],可以降低推导复杂度,将参数计算转化为简化的计算和抽样过程.
首先,由吉布斯抽样算法估计目标文本中采样词的情感极性的后验分布.设采样词w包含于文本d的第i个句子di中,则为i分配情感极性k的概率为
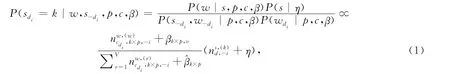
其次,由吉布斯抽样算法估计目标文本中采样词的主观性的后验分布.设采样词w为文本d中第i个句子的第j个词dij,由话题节点θk生成s的主观性值p,则为pdij分配主观性的概率为
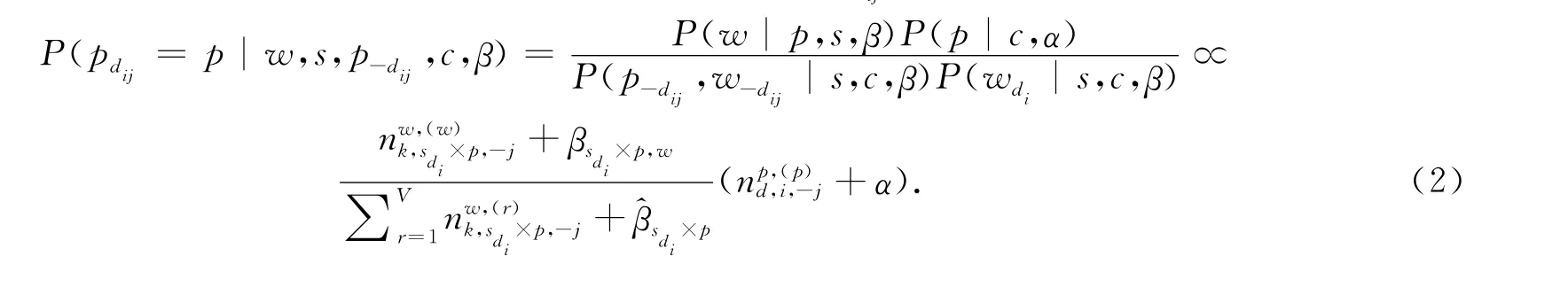
最后,采用rCRP采样方法为每个句子关联话题.目标文本中每个句子都包含情感极性和词的主观性信息,在为句子分配话题过程中可以维持信息.设当前话题节点为θk,则文本d中第i个句子关联话题存在3种可能的分配方案:

child(θk)函数表示话题情感树中某一节点的递归子节点;p(childnew)表示创建一个新节点的概率;Mc表示分配给节点c及其子节点的句子数.
其中文本d句子i中词w的生成概率为

式中:Γ为伽马函数.
4 实验
为验证ULAS模型的分类精确度及泛化能力,利用实验测试ASUM、JST及ULAS模型.
4.1 实验设置
实验数据集为Epinions产品评论数据集,包含10个主要领域的产品评论,文中采用台式PC产品评论数据集训练和测试层次话题情感模型.在删除停用词、标点符号及词频较低词后,语料库中包括2 847篇文本和24 219个互异词汇.设置ULAS模型中初始值α=10.0,β={10-7,0.01,2.5},η=1.0,r=0.1.2种情感极性词(正、负)的主观值为1;话题主题的主观值为0.情感种子词在Paradiams[11]、Mutual Information(MI)[12]和MPQA情感词典[13]中选取,其情感极性词数量见表1.
4.2 模型分类精确度
比较采用不同情感字典时3种模型的分类精确度(见表2).由表2可以看出,使用包含21个正、负情感极性词的Paradiams情感字典,JST和ASUM模型在台式PC产品评论数据集的分类精确度为67.85%和71.85%;ULAS模型的分类精确度高于JST和ASUM模型的.结合Paradiams和MI情感字典在台式PC数据集的实验结果表明,JST和ASUM模型的分类精确度提高7%;ULAS模型的分类精确度提高12%,为86.5%,优于JST和ASUM模型的.3种模型分类精确度的提高与同情感词字典的增加呈非正比关系.在MPQA情感字典上测试3个模型的分类精确度,基于台式PC产品评论数据集的实验结果表明,3种模型的分类精确度分别降低3%、4%和7%,但ULAS模型的分类精确度好于其他2种模型的(见表2).
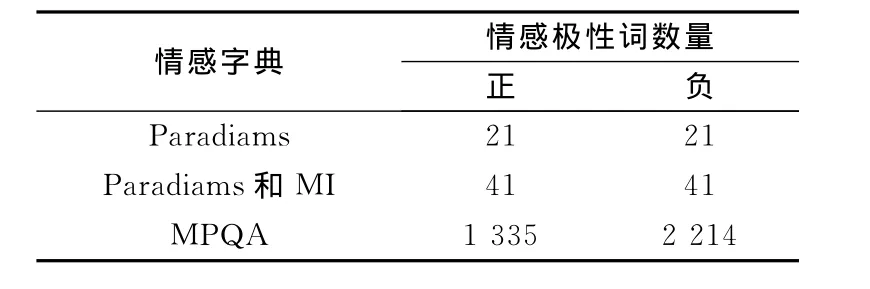
表1 情感字典的情感极性词数量Table 1 The number of emotional polarity word in the emotional dictionary

表2 采用不同情感字典的模型分类精确度Table 2 The model classification accuracy with different emotional dictionary
在台式PC产品评论数据集上,分析ULAS模型采用不同情感词典时话题数量和模型分类精确度的关系,结果见图3.由图3可以看出,当话题的数量为1时,ULAS模型变为具有S个主题的LDA层次模型,并且忽略话题和情感极性词之间的关系.采用Paradigm、Paradigm和MI情感词典的ULAS模型的平均分类精确度为上升曲线,当话题数量为1时,模型分类性能最差.采用MPQA情感词典的ULAS模型的平均分类精确度,当话题数量小于85时为上升曲线,当大于85时为下降曲线,当话题数量为60时模型分类性能最差.实验结果表明,不同情感词典的话题数量影响ULAS模型的分类精确度.
4.3 模型泛化能力
泛化能力是衡量模型对未知数据的预测能力,为研究语言主题模型过程中的重要指标,将语言主体模型中评判准则困惑度(perplexity)作为评价模型泛化能力的标准[14].通过perplexity评价ULAS模型,即由训练数据中学习的层次话题情感模型在测试集上建模的泛化能力.已知训练集合Dtrain,测试文本d∈Dtest包含的词汇wd的perplexity定义为
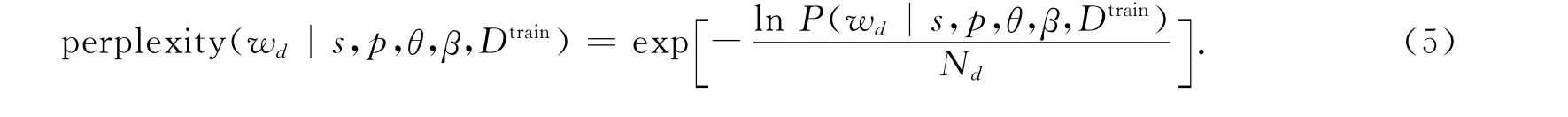
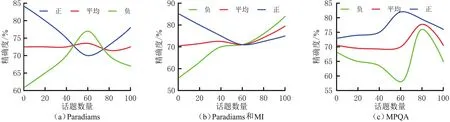
图3 ULAS模型采用不同情感词典时话题数量和分类精确度关系Fig.3 The relationship between number of topics and classification accuracy when using different emotional dictionary in ULAS model
一般情况下,perplexity越小模型泛化能力越强.训练时,为保证模型收敛,每次训练迭代次数为1 000次[15].在台式PC产品评论数据集中抽取2 000篇文本作为训练集合,抽取847篇作为测试集,测试集包括7 236个互异词汇.perplexity测试结果见图4.由图4可以看出,ULAS模型比JST和ASUM模型具有更低的perplexity值,即ULAS模型比JST和ASUM模型具有更强的泛化能力.说明ULAS模型在JST和ASUM模型的基础上,将非参贝叶斯(Bayesian)模型rCRP作为先验,细化话题分类,能够构建话题情感树,提高模型预测的准确性.
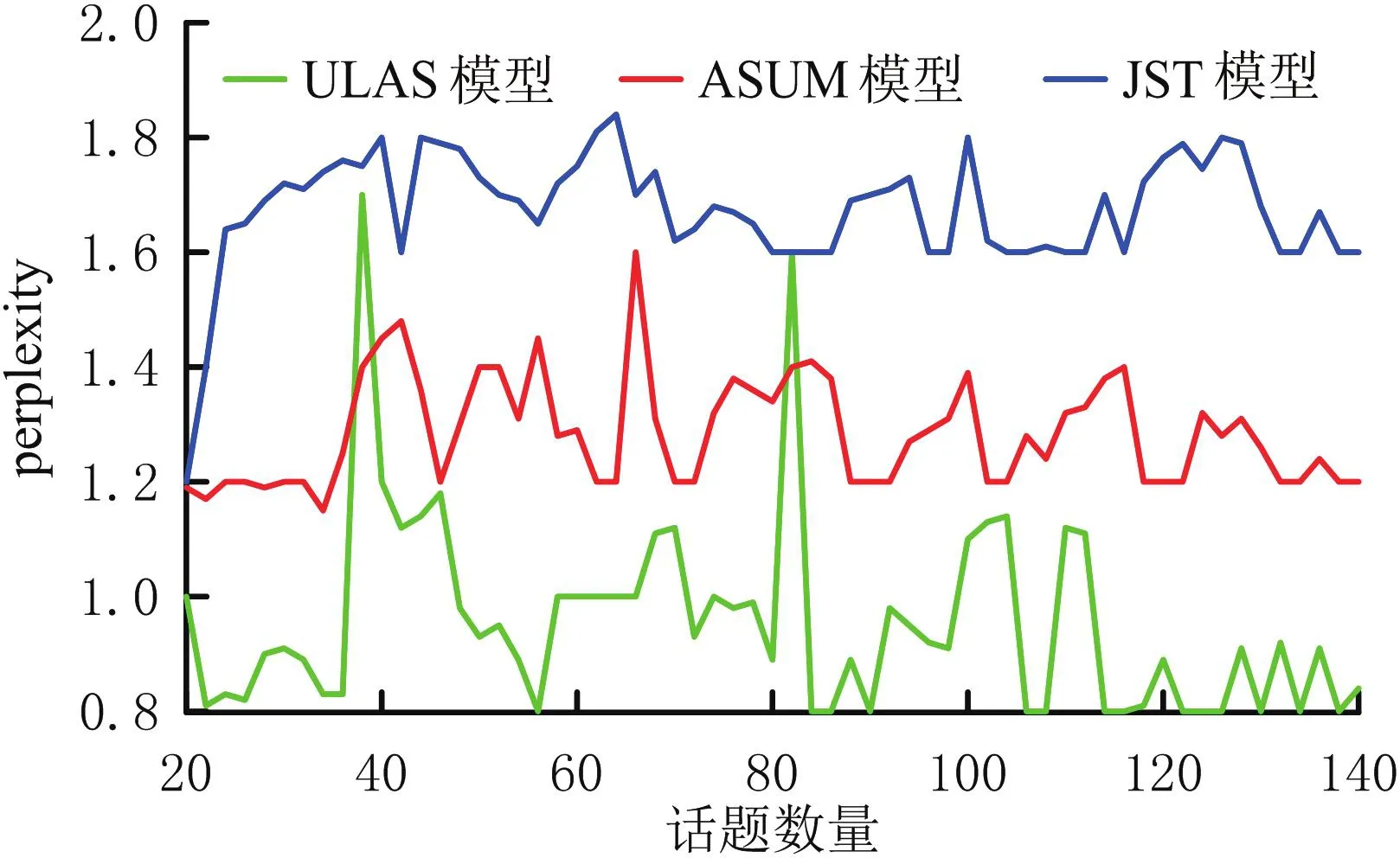
图4 不同情感模型的模型泛化能力Fig.4 The generalization ability of the model with different emotional model
5 结束语
文中提出基于一种非监督式层次话题情感(ULAS)模型,实现情感、层次话题、句子和词之间的关联关系.该模型利用非参贝叶斯(Bayesian)模型实现话题的层次分类,将模型应用到句子级的情感模型中,实现网络评论文本话题情感的隐含层次结构的发现.相比JST和ASUM模型,ULAS模型能够提高层次话题情感模型分类的精确度,并且具有较高的模型泛化能力.
(References):
[1] 张倩,瞿有利.用于网络评论分析的主题—对立情感挖掘模型[J].计算机科学与探索,2013,7(7):620-629.
Zhang Qian,Qu Youli.Topic-opposite sentiment mining model for online review analysis[J].Journal of Frontiers of Computer Science and Technology,2013,7(7):620-629.
[2] Moghaddam S,Ester M.Aspect-based opinion mining from online reviews[C].Tutorial at SIGIR Conference,2012.
[3] Li F,Huang M,Zhu X.Sentiment analysis with global topics and local dependency[C].Proceedings of the Twenty-Fourth AAAI Conference on Artificial Intelligence,2010:1371-1376.
[4] Lin C,He Y.Joint sentiment/topic model for sentiment analysis[C].Proceedings of the 18th ACM Conference on Information and Knowledge Management,2009:375-384.
[5] 单斌,李芳.基于LDA话题演化研究方法综述[J].中文信息学报,2010,24(6):43-49.
Shan Bin,Li Fang.A survey of topic evolution based on LDA[J].Journal of Chinese Information Processing,2010,24(6):43-49.
[6] Jo Y,Oh A H.Aspect and sentiment unification model for online review analysis[C].Proceedings of the Fourth ACM International Conference on Web Search and Data Mining,2011:815-824.
[7] Mukherjee A,Liu B.Aspect extraction through semi-supervised modeling[C]//Proceedings of the 50th annual meeting of the association for computational linguistics.Jeju:Association for Computational Linguistics,2012:339-348.
[8] Blei D M,Griffiths T L,Jordan M I.The nested chinese restaurant process and Bayesian nonparametric inference of topic hierarchies[J].Journal of the ACM,2010,57(2):7.
[9] Kim J H,Kim D,Kim S,et al.Modeling topic hierarchies with the recursive chinese restaurant process[C].ACM:Proceedings of the 21st ACM International Conference on Information and Knowledge Management,2012:783-792.
[10] Blei D M.Probabilistic Topic Models[C]//Communications of the ACM.ACM,2012,55(4):77-84.
[11] Pang B,Lee L,Vaithyanathan S.Thumbs up:sentiment classification using machine learning techniques[C]//Proceedings of the 2002conference on Empirical methods in natural language processing.Morristown:Association for Computational Linguistics,2002:79-86.
[12] Maes F,Collignon A,Vandermeulen D.Multimodality image registration by maximization of mutual information[J].IEEE Trans.on Medical Imaging,1997,17(16):187-198.
[13] Wilson T,Wiebe J,Hoffmann P.Recognizing contextual polarity in phrase-level sentiment analysis[C]//The conference on human language technology and empirical methods in natural language processing.Vancouver:ACL,2005.
[14] Hu P F,Liu W.Latent topic model for audio retrieval[J].Pattern Recognition,2014,3(47):303-315.
[15] Pang Bao,Lee Lillian.Opinion mining and sentiment analysis[J].Foundations and Trends in Information Retrieval,2008,2(1/2):1-135.
DOI 10.3969/j.issn.2095-4107.2015.01.015
TP181;TP301.2
A
2095-4107(2015)01-0112-06
2014-12-23;编辑:张兆虹
国家自然科学基金项目(60373099,60973040,61303131);福建省教育厅科技A类项目(JA13196)
陈永恒(1980-),男,博士,副教授,主要从事机器学习、数据挖掘和推荐系统方面的研究.
book=117,ebook=120
猜你喜欢
云南教育·中学教师(2020年11期)2021-01-07
山东煤炭科技(2020年1期)2020-03-06
时代英语·高一(2019年5期)2019-09-03
科技创新与应用(2017年3期)2017-02-18
电脑知识与技术(2016年25期)2016-11-16
天然产物研究与开发(2016年1期)2016-06-05
项目管理技术(2016年6期)2016-05-17
电测与仪表(2016年11期)2016-04-11
无线互联科技(2015年11期)2016-03-04
数理化学习·高一二版(2009年2期)2009-03-30
