
AltaRica语言在安全性仿真分析平台中的实现与应用
2015-08-01 10:08:23赖智超
航空标准化与质量 2015年6期
赖智超
(中航工业综合技术研究所,北京 100028)
AltaRica语言在安全性仿真分析平台中的实现与应用
赖智超
(中航工业综合技术研究所,北京 100028)
[摘要]通过分析AltaRica语言的特性,在借鉴了编译原理相关理论的基础上,介绍如何实现AltaRica语言的编译解析框架以及在安全性仿真分析平台中的应用。
[关键词]AltaRica语言;编译解析;仿真分析平台
[收修订稿日期] 2015-09-23
AltaRica语言[1]是一种形式化建模语言,被广泛用于复杂系统的事件驱动建模中,它的语言特性非常适用于安全性和可靠性分析,因为安全性和可靠性分析的一个主要目标实际上就是检测和量化导致系统从正常状态到失效状态的事件集合。
AltaRica语言以事件为中心,其语义为:系统通过一系列的变量来描述状态,当事件发生时,系统状态会随之发生改变。
1 安全性仿真分析平台
安全性仿真分析平台是基于模型的安全性和可靠性分析软件。该平台采用AltaRica语言,具有图形化建模、故障树分析、安全性分析、失效模式与影响分析、动态仿真等功能。平台统筹考虑适航安全性评估分析、任务可靠性评估、可靠性设计权衡分析等需求,是仿真大平台的核心组成部分。
在安全性仿真分析平台实现过程中,涉及到的多项功能业务均与AltaRica脚本紧密关联,包括故障树的生成、模块逻辑关系的描述、故障传递的运算、仿真计算分析,因此,实现该平台的首要任务是完成对AltaRica语言的编译解析。
2 AltaRica语言编译解析实现
最基本的语言编译过程通常包括词法分析、语法分析、语义分析、生成目标代码,同样的,AltaRica语言的编译过程也是经过了这几个阶段。首先,AltaRica语言在经过词法分析和语法分析后,会首先生成抽象语法树,生成的抽象语法树再经过语义分析生成AltaRica语法树,最后通过扩展、转换生成中间代码,整个过程如图1所示。
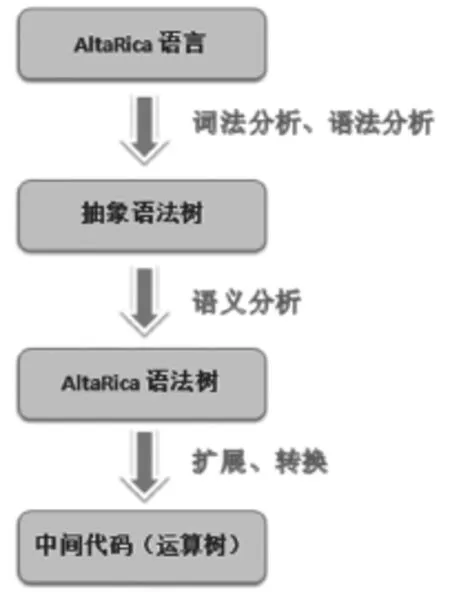
图1 编译解析流程图
2.1 生成抽象语法树
开发一个AltaRica语法分析器大致分3步,第一步:写出所需要分析的内容的文法;第二步:完成针对该文法的语法分析器的代码;第三步:编译语法分析器。
所谓文法,即是一系列的语法规则,它是由若干定义语法规则的推导式组成的。通过简单的以AltaRica语言规范中最基本的条件赋值(Condition)作为例子了解一下文法的表达。条件赋值是一个表达式,它的格式类似于 “STATE = WORKING;”。由于在语法分析中一般是用树来表示语法结构,表达式的语法树是以操作符为根节点和操作数为子节点的树形结构。在安全性仿真分析平台项目中,文法定义大致如图2所示。

图2 文法定义
文法定义中分2大部分:语法描述和词法描述。其中每一行都是一个规则(rule)或叫做推导式,每个规则的左边是文法中的一个名字,代表文法中的一个抽象概念。中间用一个“:”表示推导关系,右边是该名字推导出的文法形式。
语法分析是编译过程的第二步,在词法分析提供的词号流的基础上,对源代码的结构做总体的分析。无论分析的内容有多大,语法分析总是由一个启始规则开始的,最后总是生成一棵语法树。一般情况语法规则是一个文法的主体部分,也是编写文法的难点。
安全性仿真分析平台采用自顶向下的语法分析方法。自顶向下的分析方法的思路是从起始规则开始选择对应的规则反复推导,直到推导出待分析的语型。如果推导失败则返回选择其他规则进行推导,即回溯,如果所有规则都失败则说明这个句型是非法的。AltaRica语言进过语法分析之后,生成抽象语法树,这棵抽象语法树则是进行下一步语义分析的基础。
2.2 语义分析及中间代码
在完成语法分析阶段后,接下来的目标就是通过遍历抽象语法树,完成语义分析并生成中间代码。
语义分析是编译过程的一个逻辑阶段,它的任务是对源程序进行上下文有关性质的审查和类型审查,审查其有无语义错误,为代码生成阶段收集类型信息。比如审查某个运算符是否具有语言规范允许的运算对象,当不符合语言规范时,编译程序应报告错误。
2.2.1 语义分析
通过语法分析得出的抽象语法树,它的某个节点在整个程序上下文的意义是需要经过分析转换得到的,因为语法分析并未对一个源代码内部的逻辑含义加以分析。因此,编译框架接下来需要执行语义分析,即审查每个语法成分的静态语义。静态语义检查涉及了以下几个方面:
● 类型检查,比如某个操作符的两个操作对象必须类型一致。
● 控制流检查,判断控制语句的流向是否正确,比如if(…)then(…)else(…)格式语句需要有跳转点,否则出错。
● 一致性检查,比如在相同的作用域里,定义了两个同名的标识符,这样会造成歧义。
在语义分析阶段,通过遍历抽象语法树进行转换,以生成中间代码。遍历转换过程针对AltaRica语言规范中的文法规则来定义不同类型的节点,这些节点将用来对语法树节点进行转义吸收,为后续的语义校验提供基础。遍历过程针对不同类型节点,可分为如下几类:
● 定义常量及变量节点
针对AltaRica语言规范定义出整形、浮点、布尔值、字符型、枚举等常量节点,以及定义出代表系统变量(如系统端口、状态)的变量节点,这些节点均继承自基类AltaRicaNodeBase,我们称之为AltaRica节点。在遍历到该类型的语法树节点时,进行转义吸收。如图3所示,AltaRica节点派生出各种类型的常量和变量节点。
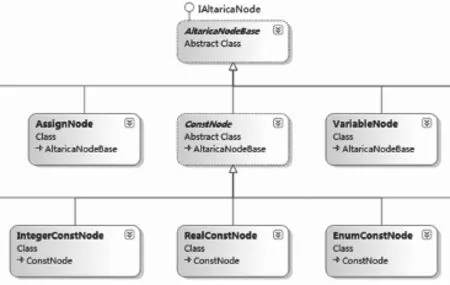
图3 AltaRica节点
● 定义逻辑操作符节点
它代表的是与操作符、或操作符、非操作符等。比如,当代表一个或门的AltaRica节点出现时,在语义分析阶段,会把它转义为或操作符,同时遍历该AltaRica节点的所有孩子作为操作对象,并同时分析孩子的类型是否匹配。如图4所示。
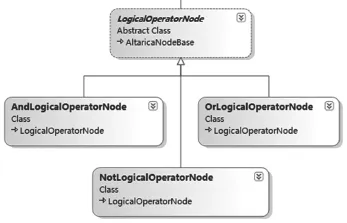
图4 逻辑操作符节点
● 定义运算操作符节点
它代表的是常见的加、减、乘、除、比较等操作符。其中,比较运算符又细分为小于、小于等于、大于、大于等于、相等、不等操作符。
● 定义函数节点
它代表一些自定义的常用的函数。所有符合ANTLR函数规则文法的表达式,均会被语法分析器解析成函数,但是符合规则的这些函数其语义需要在函数节点中重新定义,赋予其真正的含义。比如Max函数,它在语法树中,只能被告知这是一个函数节点,只有在语义解析阶段,才给它定义功能为:这是一个二元及以上运算操作的函数,必须包含两个及两个以上的运算对象,其计算结果是取所有运算对象中值最大的那个。函数节点的定义如图5所示。
在遍历抽象语法树时,会根据不同的类型,执行不同类型节点的转义操作,在遍历完抽象语法树之后,AltaRica代码的文法定义也就都经过了语义分析,具备了属于其自身的含义,这时,将生成另外一棵树:AltaRica语法树,这时,它的节点已经具备了上下文关系。利用AltaRica语法树可以在接下来的语义校验过程中,很方便地识别某个节点的身份含义,从而判断某些节点是否存在语法错误。
在校验阶段,其实就是对AltaRica语法树的节点进行语法检查的一个过程。还是以Max函数为例,如果有一个函数被描述为Max(A,B),在AltaRica语法树中,它的结构应该是如6所示的。
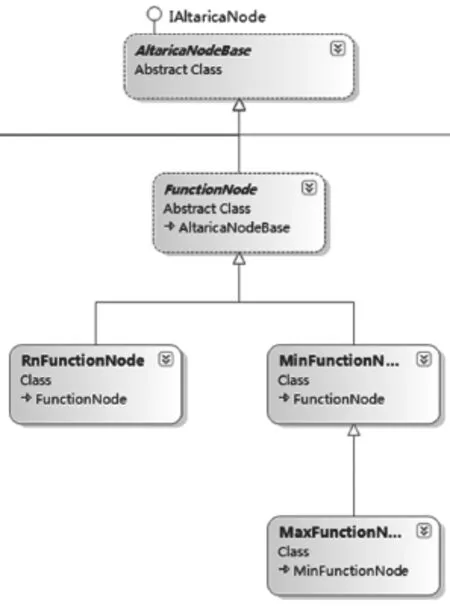
图5 函数节点的定义
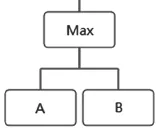
图6 语法树结构示例
在执行到Max节点的语法检查时,会同时启动对孩子节点的检查,如果发现孩子节点少于两个时,会报“函数定义不合法”的错误。
在安全性仿真分析平台中,定义了信号流(Flow)和断言(Assert),它们的文法如图2所示。
假设有下面这样一段代码:
flow
A:bool: in;
B:bool: in;
X:bool: out;
assert
X = if ((A=false) and (B=false)) then false else true;
它表示有A、B、X 3个布尔型的变量,X为输出端口,A、B为输入端口,这句断言的语义是“当输入端口A和B的取值同时为false的时候,输出端口X取值为false,否则为true”。上面的代码将会被编译成如图7这样的AltaRica语法树结构。
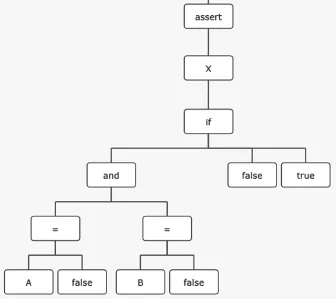
图7 断言在AltaRica语法树中的结构
生成中间代码,是在AltaRica语法树的基础上,扩展出一套符合AltaRica运算法则的方法。基于前面生成的AltaRica语法树,在它上面挂载一些系统的业务功能比如逻辑关系运算、仿真计算、故障传递等接口,使它可以在中间代码解析执行引擎执行相应的功能。
2.2.3 中间代码解析执行引擎
中间代码必须在经过加载、初始化、解析等阶段才能被使用。在编译解析框架中实现了一个中间代码解析执行引擎,就是做这部分工作。
在中间代码解析执行引擎的内部维护了一个状态机,当中间代码被加载时,状态机会开辟出包括变量区、操作数栈、栈信息区等区域。
变量区:是一组变量值的存储空间,用于存放在AltaRica代码中定义的各种变量,在安全性仿真分析平台中,这个区域一般是存放系统状态值、端口的状态值以及其他系统配置参数。
操作数栈:是用来存放操作数的栈结构,当一个方法刚开始执行的时候,这个方法的操作数栈是空的,在方法的执行过程中,会有指令向操作数栈中写入和提取内容,也就是入栈和出栈的操作。
栈信息区:主要用于存储操作数栈的一些基本信息,包括方法返回的地址、临时变量的地址、回调方法的地址等等。
⑮数据来自 Schenk C.R.,“The Origins of the Eurodollar Market in London:1955 ~ 1963”,Explorations in Economic History,2004,35(2),pp.221 ~238.
在中间代码加载完毕之后,会进行初始化工作,首先把AltaRica代码中定义的变量初始化进变量区,然后在栈信息区里存储各种函数调用关系。
初始化工作完成后,便可以执行各种需要的运算工作,比如项目执行仿真计算或者故障推进演算等等,都是在这个时期进行的。
当运算工作结束,可以主动调用状态机去释放内存,或者等待系统在注销状态机时自动释放,完成垃圾回收工作。
2.2.4 中间代码优化
所谓代码优化,是在不改变程序运行效果的前提下,对被编译的程序进行等价变化,以生成更加高效的目标代码。代码优化的级别一般分为3种:局部优化、循环优化、全局优化。由于AltaRica语言的特性,循环操作强度不大,而且代码量不会非常庞大,做循环优化和全局优化的意义并不大,所以目前这套解析框架只实现了局部优化。
局部优化的第一步是划分基本块,一个基本块内的语句是没有跳转及分叉汇合的,比如,在安全性仿真分析平台中常用到的影响(Effect),它的格式是Effect:= Assert1; Assert2;… .,它可以包含N个断言(Assert),而Assert的格式则是这样的X:= If(逻辑语句 A)then true else false;那么,在划分基本块时,会自顶向下进行划分,一直到逻辑语句A时,把它划分为一个基本块。
这时进行第二步:基本块处理。基本块处理主要是进行转移分析,凡是控制流不可到达的语句,直接忽略处理,比如,逻辑语句A的内容恒真,则它永远不会到达else那部分逻辑处理,可以将else部分直接忽略处理。除此之外,基本块处理还会进行变量分析,比如,对于已定义却从未在语句中使用过的变量,会直接剔除掉。在经过局部优化之后,生成的AltaRica语法树会较未优化之前的要小。
3 AltaRica语言编译解析框架的应用
在安全性仿真分析平台中,有相当多的地方使用到了AltaRica语言,整个系统与AltaRica语言可谓是紧密相连,在系统的诸多功能中,AltaRica语言扮演了重要的角色,它既是参与模块信息存储的一份子,也是故障树的前身;既是逻辑关系运算的载体,也是仿真计算的主角。下面介绍一下AltaRica语言在仿真计算中的应用。
首先,仿真计算中关键的一步就是,如何计算出一个信号的流入或者系统自身状态的改变,会影响系统自身的输出。这个计算的依据,就是存储在模型设计时用于描述系统模块状态变化的逻辑关系,而逻辑关系则直接由AltaRica脚本编写,所以,仿真计算的这一步,其实最终就是简化为对AltaRica脚本的编译计算,这样,就可以根据逻辑关系的推演计算结果得到仿真计算的结果。
假设,在模型设计时,有如图8的模型关系。
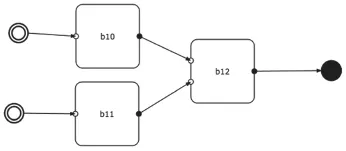
图8 模型示例
其中,模型b12的逻辑关系如图9所示。
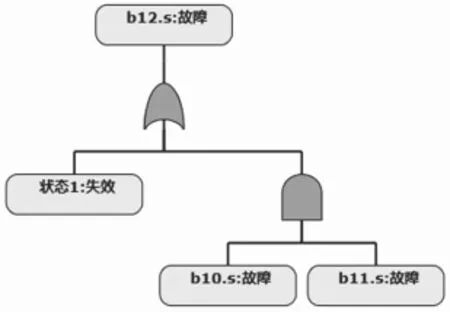
图9 模型b12的逻辑关系
它对应的AltaRica代码如下:
o := if((状态1=失效) or ((i=故障) and (i1=故障))) then 故障 else 正常;
这段代码的语义是:“当自身的某个状态1是失效,或者当两个输入端口信号同时均为故障时,输出信号为故障,否则输出信号为正常”。
这段代码经过编译解析框架的编译之后,其AltaRica语法树如图10所示。
生成中间代码后,即可用于仿真计算,比如,系统b10和系统b11的输出均为故障信号,则系统b12的两个输入端口均接收到该故障信号,这时,针对系统b12的输出计算,就是把故障信号作为参数传递给中间代码,在解析执行引擎中,会把这段逻辑关系执行运算,得出系统b12的输出端口的值,即推算出了系统b12的输出结果,从而达到仿真计算的目的。
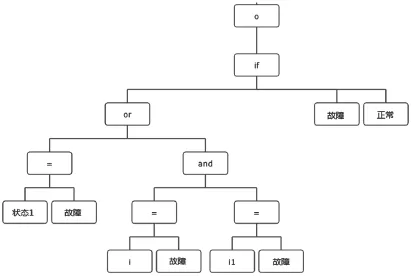
图10 编译后的语法树内容
4 结束语
本文从应用需求的角度出发,提出了一种解决AltaRica语言的编译解析的方法,借鉴于一般的编译原理方式,解决了AltaRica语言的词法分析、语法分析、语义分析等编译任务,并建立了一套可扩展的编译解析框架,在后期中间代码生成阶段,也充分考虑到了业务的可扩展性,能够在未来可以实现插件的方式来注入自定义的一些功能。
这套编译解析框架虽然很好地解决了AltaRica语言的编译需求,整个设计非常的简洁统一,但是在对AltaRica语言进行词法分析、语法分析时,生成的抽象语法树有些庞大,希望后续的研究中能对其进行改进优化,以提升整个编译解析框架的执行效率。
[参考文献]
[1] Antoine B. Rauzy. AltaRica Data-Flow Language Specification –Version 2.1[EB/OL] . http://www.lix.polytechnique.fr/~rauzy/altarica/.
[2] T. Prosvirnova & Antoine B. Rauzy. AltaRica 3.0 project : compile Guarded Transition Systems into Fault Trees[EB/OL] . http://www.lix.polytechnique.fr/~prosvirnova/.
(编辑:劳边)
[中图分类号]TP391
[文献标识码]C
[文章编号]1003–6660(2015)06–0037–05
[DOI编码]10.13237/j.cnki.asq.2015.06.009
