
Action recognition using a hierarchy of feature groups
2015-07-25 06:04
(School of Information Science and Engineering,Southeast University,Nanjing 210096,China)
Action recognition using a hierarchy of feature groups
Zhou Tongchi Cheng Xu Li Nijun Xu Qinjun Zhou Lin Wu Zhenyang
(School of Information Science and Engineering,Southeast University,Nanjing 210096,China)
To improve the recognition performance of video human actions,an approach thatmodels the video actions in a hierarchical way is proposed.This hierarchical model summarizes the action contents w ith different spatio-temporal domains according to the properties of human body movement.First,the temporal gradient combined with the constraint of coherent motion pattern is utilized to extract stable and dense motion features that are viewed as point features,then the mean-shift clustering algorithm with the adaptive scale kernel is used to label these features.After pooling the featuresw ith the same label to generate part-based representation,the visual word responses within one large scale volume are collected as video object representation.On the benchmark KTH(Kungliga Tekniska Högskolan)and UCF(University of Central Florida)-sports action datasets,the experimental results show that the proposed method enhances the representative and discriminative power of action features,and improves recognition rates.Compared with other related literature,the proposed method obtains superior performance.
action recognition;coherent motion pattern;feature groups;part-based representation
H uman action recognition(HAR)is one of the hot topics in the fields of computer vision and pattern recognition due to its w idespread applications in video surveillance,human computer interaction and video retrieval.However,its research is influenced by significant cameramotion,background clutter,and changes in object appearance,scale,illum ination conditions and viewpoint.Overall,HAR has become a difficult but also an important task.
Local features together w ith bag-of-visual words[13](BoVW)have gained good recognition performance.Kovashka et al.[1]employed the Euclidean metric to construct variable-sized configurations of local features and learned compound features,and each action video is modelled by the learned compound features in a hierarchical way.A lso,Yuan et al.[4]used the same metric to measure the distance between features,and counted the co-occurrence frequency of pair features w ithin some spatial-temporal extents.Considering the activity data containing information at various temporal resolutions,Song et al.[5]presented a hierarchical sequence summarization and learned multiple layers of discrim inative feature representations.In fact,the methods in Refs.[1,4]w ith the popular spatio-temporal interest points(STIPs),like cuboids,and 3D Harris etc.are easily influenced by the camera m_otion and background clutter,so the learned context[15]lacks the representativeness.To extract stable features for action recognition,the motion compensation technique[6]is introduced to suppress the camera motion.Chakraborty et al.[7]selected STIPs by surrounding suppression combined with local and temporal constraints.Moreover,to reduce the quantization error and preserve the nonlinear manifold structure,Refs.[8- 9]adopted structured sparse coding to encode the local features for recognition tasks.
Inspired by the ideals of Refs.[1,5- 8],we learn a spatial-temporal context w ith an ascending order of abstraction in a hierarchicalway.We first compensate cameramotion,and then utilize temporal gradients to extract stablemotion features.To learn local context and model body parts,we utilize the clustering algorithm instead of the ranked metric.A fter encoding the underlying features w ith locality-and group-sensitive sparse representation(LGSR)[9]and learning part-based representation,the large scale context for the constructed volumetric region is sequentially modelled.From experiments,our representation enhances the discrim inative power of action features and achieves excellent recognition performance on the benchmark KTH(Kungliga Tekniska Högskolan)and UCF(University of Central Florida)-sports action datasets.
1 Proposed M ethod
The hierarchical feature representation model for action recognition proposed in this paper is semantic structures from motion including region,part and object,as shown in Fig.1(c).The initial layer is the low-level features extracted from salient3D motion regions.The second layer is a pool group features labelled by themean-shift clustering algorithm.The top layer is explored to construct body movement representations.Using ourmethod to represent the irregular 3D regions is more flexible than those w ith fixed grids[10]or nearest rank[1,4],as shown inFigs.1(a)and(b),respectively.

Fig.1 The learned spatial-temporal relationships.(a)Multi-level fixed grids[10];(b)Nearest rank[1,4];(c)Ourmethod
1.1 Extracting and encoding features
Each video is first segmented to narrow clips.According to themotion compensation[6],the 2D polynom ial affinemotionmodels are considered for estimating the dominantmotion,and the adjacent frames from a narrow clip are aligned.Fig.2(a)shows an example w ith the high score matching corner points in the region of interest(ROI),where the corresponding dots are in the first and second columns,and the circles in the second and third columns.A fter the processes of motion compensation,temporal gradient and the adaptive threshold,the saliency map shown in Fig.2(b)is obtained by
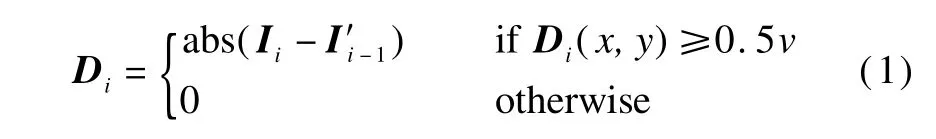
where Di(x,y)means the pixel value;I′i-1is the compensated ROI image corresponding to Ii-1;and v is the saliency maximum of the absolute difference image Di.

Fig.2 Processes of saliency motion extraction.(a)Matching points;(b)Difference images;(c)Saliency motion cumulative image
Unfortunately,some noise still persists,and the processmentioned above may lead to leak detection.To handle these problems,the constraints of some context clues including coherentmotion patterns,changes of displacement and phase,color value invariance in short duration are adopted to select saliency motion sub-regions.According to the central coordinate set{r′1,r′2,…,r′n}obtained by 8-connected regions of the difference cumulative image,we sample sub-volume w ithin the difference volume constructed by difference images.For one subvolume,the spatial window for KTH and UCF-sports is empirically set to be 10×10 and 30×30,respectively,and temporal scale L is the number of difference images.The process to extractmotion features is followed by

where Pi(x,y)is the pixel value at coordinate(x,y)of the i-th patch of a sub-volume;w and M are defined as the Boolean-valued function;w is used to distinguish whether themotion exists in some patch and M is used to distinguish whether the spatial-temporal feature is valid.After pruning,the new center coordinate set{r1,r2,…, rm}is viewed as STIPs,and the new difference cumulative image shown in Fig.2(c)is defined as

where D′pmeans the difference image after pruning Dp.After describing volumes,we transform the HoG/HoF descriptors(HoG:4 bins;HoF:5 bins)into structured sparse representations by LGSR.This encoding method takes advantages from both group sparsity and data locality structure in determ ining the discrim inative representation for classification[9].Cgcan be solved by the following optim ization problem:
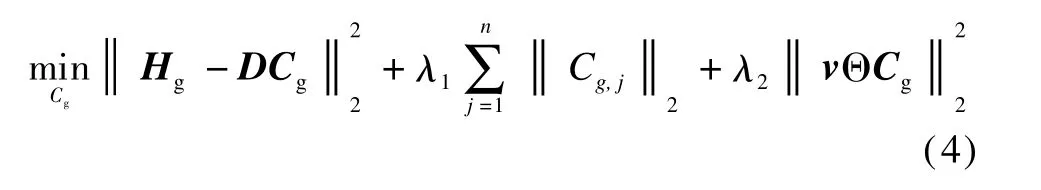
where D=[D1,D2,…,Dn]∈RD×dis the codebook;λ1andλ2are the weights for the group sparsity and locality constrains,respectively;and the vector v∈Rd×1is the distancemeasurement between Hg,jand each visualword.
1.2 Group feature generation by clustering
In this section,we use the mean-shift clustering algorithm to construct group features,and then adopt amaxpooling operator to generate part-based representation.For themean-shift clustering,3D templatew ith the adaptive scale is used instead of the fixed bandw idth kernel that is unsuitable to model the irregular movement part.The temporal scale of 3D kernel is L frames.The 3D kernel’s spatial scale(rx,ry)controlling the ranges of motion sub-region centers is a parameterized function,which can adaptively change by zooming in or out of thebody scope(O-x,O-y)as follows by the given annotation.The scale(rx,ry)is defined as

where R-xand R-yare set to be(80,50),and they are the reference sizes of body scope;rref-xand rref-y,the spatial sizes of template,are set to be(20,20)in our experiments.Moreover,if the features deviate from the clustering center,the extracted color information(gray image:illum ination)is used to re-label them.After the above two stages,some action features w ith the same label can give an enough coverage of the body part,as shown in Fig.3,where the defined ROIs are represented by large blue boxes.The body movement parts are described by small red boxes,and the centers of 8-connected motion regions are denoted by green points in red boxes.

Fig.3 Clustering results ofmotion features for some action video frames.(a)Dive;(b)Kick;(c)Skate;(d)Swing 2;(e)Walk
A fter clustering,the coefficient set Cg∈Rd×kcorresponding to the descriptor set Hgis represented as

Themax-pooling[10]operator for Cgis defined by

where S(i)represents the maximum absolute response of the i-th atom,and S is the descriptor for certain body part.
1.3 Object-level context
Due to the lim ited scale of body parts,it is not enough to capture large scale co-occurrence relationships.We use ROIs of narrow clips to construct volumes which can adaptively adjust the spatial scales follow ing the changing human body scope,and then accumulate each element of all part descriptors as volume descriptors.The produced vector is computed as

where V(i)is the weight accumulation of the i-th atom response,and Sgdenotes the g-th body part descriptor.
2 Action Representation and Recognition
After describing feature groups and object context,each video is represented by the descriptors of linear quantization corresponding to different levels,and the lengths are all NatomsNbin,where Natomsdenotes the dictionary size,and Nbinrepresents the quantization bins.
Recognition is performed by the nearest neighbour classifier(NNC)and support vector machine(SVM).The NNC is a simple and effective classifier and the absolute distance is used to measure the sim ilarity.For the SVM classifiers,we adoptχ2 kernel[11]which is an extension form ofχ2 distance[11]and the Gaussian radial basis function[12](G-RBF),respectively.The two kernels are commonly used for classification task.The Gaussian radial kernel andχ2 kernel are,respectively,defined by

where Hiand Hjrepresent the histograms of video representations.In the cases of the G-RBF kernel,the r values are selected heuristically.
3 Experimental Results
3.1 Action dataset
We adopt KTH[1,78]and UCF-sports[12,10,1214]action datasets to validate our proposedmethod.The KTH dataset contains 599 videos of 25 actors perform ing six types of human actions,box,clap,wave,jog,run,and walk.Each action is repeated in four different scenarios:outdoors,outdoorswith scale variation,outdoors with clothing variation and indoors.All sequences with low resolution are recorded.The UCF-sports dataset consists of 150 video clips acquired from sports broadcast networks.The videos have cameramotion and jitter,highly cluttered and dynam ic backgrounds,compression artifacts and variable illumination settings at variable spatial resolutions.Fig.4 shows the classof 10 action samples on the UCF-sports action dataset.
3.2 Experim ental settings

Fig.4 Sample action frames from video sequences of the UCF-sports dataset.(a)Dive;(b)Golf;(c)Kick;(e)Lift;(f)Walk;(g)Run;(h)Ride;(i)Sw ing 1;(j)Skate;(k)Sw ing 2
The narrow clip length is set to be 3.λ1andλ2are set to be 0.3 and 0.1,respectively.Video frames in the KTH dataset have a simple background and slight camera motion,so we do not need to align adjacent frames.The dictionary with 936 atoms is constructed by random ly selected 280 sets of group features.For the KTH dataset,we follow the leave-one-out cross-validation(LOOCV)evaluation scheme,and adopt themost simple NNC w ith k=3.For UCF-sports dataset,the defined ROIs’scale is zoomed in 20%under the original center-frame ROI.The dictionary w ith 839 atoms is built by a random ly selected 105 group of descriptors._Ourmethod is validated by the five-fold cross-validation[1314]and the split evaluation scheme[2].For the NNC,the neighbour parameter is set to be 5.W ith the SVM classifier,we adopt a oneagainst-rest training approach.For the G-RBF kernel,by cross-validation,the optimal values of two controlling parameters are set to be C=380 and r=0.2.For theχ2 kernel,the parameter C is set to be 380.The recognition accuracy is average result over 100 runs.
3.3 Evaluation on KTH dataset
Fig.5 shows the recognition accuracy for the KTH dataset in the form of confusion matrix.From Fig.5,the majority of the confusion between“jog”and“run”is expected due to sim ilar nature between their local features.Tab.1 shows performance comparison w ith other methods.Among theusing local features to model actions,ourmethod achieves 96.11%recognition accuracy.

Fig.5 Confusionmatrix for KTH dataset

Tab.1 Performance comparison w ith othermeth___ods
3.4 Evaluation on UCF-sports dataset
We first adopt the simple NNC to validate our proposed method.Under the five-fold cross-validation and split evaluation scheme,all class average recognition accuracies are shown in Figs.6(a)and(b),respectively.For the SVM classifier,under the split scheme,the recognition results for all action videos are shown in Figs.7(a)and(b)corresponding to theχ2 kernel and G-RBF kernel,respectively.From Figs.6 and 7,we can see that the majorities of recognition error are among“Golf”,“Skate”and“Run”.
To evaluate performance at different levelsw ith respect to histogram bins,we use the simple NNC w ith five-fold cross-validationmanner.Fig.8 shows the recognition accuracy plot varying w ith the histogram bins,where each point on the curves corresponds to an average result.At some bins,recognition accuracies w ith object representation are lower than thatof the part representation,but recognition rates tend to be insensitive to the quantization bins.The recognition results w ith the part representation can reach 100%in some quantization bins.

Fig.6 Confusion matrices w ith NNC for UCF-sports dataset.(a)Five-fold cross validation;(b)Splitting

Fig.7 Confusion matrices w ith SVM for UCF-sports dataset.(a)χ2 kernel;(b)G-RBF kernel

Fig.8 Recognition results at different levels
Tab.2 lists performance comparison of our method w ith othermethods on the UCF-sports dataset.Compared w ith the literature using local features to model actions,the recognition rates of ourmethod using object representation are higher than those of other methods.The obtained better performance benefits from three aspects,having stable and densemotion features,a semantic context and robust LGSR-based sparse representation.In addition,the recognition performance with the SVM classifier is better than that based on the NNC.Note that Sanin et al.[15]designed dense spatio-temporal covariance descriptors and adopted the LogitBoost classifier to recognize actions.M ichalis et al.[14]utilized the dense trajectories to learn discrim inative action parts in terms of an MRF score.Lan etal.[2]employed a figure-centric visual word representation for joint action localization and recognition.

Tab.2 Performance comparison w ith othermethods
4 Conclusion
In this paper,we propose an action hierarchicalmodel,which can capture the discrim inative statistics of co-occurring motion features at multiple levels.A fter extracting the stable and densemotion features by motion compensation techniques together w ith temporal gradient and coherentmotion pattern constraints,we use the structured sparse representations of HoG/HoF descriptors as underlying features.Then the orderly hierarchical spatial-temporal context for different scale volumes is represented by aggregating group features generated bymean-shift clustering,and accumulating each element of visual word responses,respectively.On the KTH and UCF-sports action datasets,the experimental results show that our method obtains good performance.
[1]Kovashka A,Grauman K.Learning a hierarchy of discrim inative space-time neighborhood features for human action recognition[C]//Proc of the International Conference on Computer Vision and Pattern Recognition.San Francisco,CA,USA,2010:2046- 2053.
[2]Lan T,Wang Y,Mori G.Discrim inative figure-centric models for joint action localization and recognition[C]//Proc of the International Conference on Computer Vision.Colorado,USA,2011:2003- 2010.
[3]Hu Q,Qin L,Huang Q,et al.Action recognition using spatial-temporal context[C]//Proc of the 20th International Conference of Pattern Recognition.Istanbul,Turkey,2010:1521- 1524.
[4]Yuan C,Hu W,Wang H,etal.Spatio-temporal proximity distribution kernels for action recognition[C]//Proc of the International Conference of Acoustics,Speech and Signal Processing.Dallas,TX,USA,2010:1126-1129.
[5]Song Y,Morency L P,Davis R.Action recognition by hierarchical sequence summarization[C]//2013 IEEE Conference on Computer Vision and Pattern Recognition.Portland,OR,USA,2013:3562- 3569.
[6]Jain M,Jegou H,Bouthemy P.Better exploiting motion for better action recognition[C]//Proc of the International Conference of Computer Vision and Pattern Recognition.Portland,OR,USA,2013:2555- 2562.
[7]Chakraborty B,Holte M B,Moeslund T B,et al.Selective spatio-temporal interest points[J].Computer Vision and Image Understanding,2012,116(3):396- 410.
[8]Zhou T C,Chen X,Wu Z Y.Action recognition using hierarchically tree-structured dictionary encoding[J].Journal of Image and Graphics,2014,19(7):1054-1061.(in Chinese)
[9]Chao Y W,Yeh Y R,Chen Y W,et al.Locality-constrained group sparse representation for robust face recognition[C]//Proc of the International Conference on Image Processing.Brussels,Belgium,2011:761- 764.
[10]Xiao W H,Wang B,Liu Y,et al.Action recognition using feature position constrained linear coding[C]//Proc of the International Conference on Multimedia and Expo.San Jose,CA,USA,2013:1- 6.
[11]Vedaldi,A,Zisserman A.Efficient additive kernels via explicit featuremaps[C]//Proc of the International Conference on Computer Vision and Pattern Recognition.San Francisco,CA,USA,2010:2046- 2053.
[12]Chapelle O,Haffner P,Vapnik V N.Support vectormachines for histogram-based image classification[J].IEEE Transactions on Neural Networks,1999,10(5):1055-1064.
[13]Castrodad A,Sapiro G.Sparse modeling of human actions from motion imagery[J].International Journal of Computer Vision,2012,100(1):1- 15.
[14]M ichalis R,Iasonas K,Stefano S.Discovering discrim inative action parts from m id-level video representations[C]//Proc of the International Conference of Computer Vision and Pattern Recognition.Rhode Island,USA,2012:1242- 1249.
[15]Sanin A,Sanderson C,Harandi M T,et al.Spatio-temporal covariance descriptors for action and gesture recognition[C]//Proc of International conference on Application of Computer Vision Workshop.Sydney,Australia,2013:103- 110.
分层特征组的行为识别
周同驰 程 旭 李拟珺 徐勤军 周 琳 吴镇扬
(东南大学信息科学与工程学院,南京210096)
为提高视频人体行为识别的性能,提出了一种分层建模行为的方法.该分层模型根据人体运动的属性概述不同时空域的行为内容.首先,利用时间梯度并结合连贯的运动模式约束提取稳定、密集的运动特征作为点特征;然后,采用自适应尺度核的mean-shift聚类算法标定这些特征.具有同一标签的特征组通过最大池运算产生身体部分表示后,累积大尺度的视频体内视觉词响应作为视频对象的表示.在基准的KTH和UCF-sports行为数据库上,实验结果表明所提方法增强了行为特征的代表性和判别能力,同时提高了识别率.与其他相关文献相比,所提方法获得了优越的识别性能.
行为识别;连贯的运动模式;特征组;部位表示
TP391.4
10.3969/j.issn.1003-7985.2015.03.005
2015-01-04.
Biographies:Zhou Tongchi(1979—),male,graduate;Wu Zhenyang(corresponding author),male,doctor,professor,zhenyang@seu.edu.cn.
The National Natural Science Foundation of China(No.60971098,61201345).
:Zhou Tongchi,Cheng Xu,LiNijun,etal.Action recognition using a hierarchy of feature groups[J].Journal of Southeast University(English Edition),2015,31(3):327- 332.
10.3969/j.issn.1003-7985.2015.03.005
猜你喜欢
新世纪智能(语文备考)(2021年4期)2021-08-06
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
计算机工程(2020年3期)2020-03-19
中国听力语言康复科学杂志(2019年3期)2019-06-24
新世纪智能(语文备考)(2018年11期)2018-12-29
中国交通信息化(2018年3期)2018-06-13
太空探索(2016年5期)2016-07-12
中国交通信息化(2016年2期)2016-06-06
时代英语·高三(2014年5期)2014-08-26
外语学刊(2010年2期)2010-01-22
 Journal of Southeast University(English Edition)2015年3期
Journal of Southeast University(English Edition)2015年3期
- Journal of Southeast University(English Edition)的其它文章
- CoMP-transm ission-based energy-efficient scheme selection algorithm for LTE-A system s
- Detection optim ization for resonance region radar w ith densemulti-carrier waveform
- Dimensional emotion recognition in whispered speech signal based on cognitive performance evaluation
- Cascaded projection of Gaussian m ixturemodel for emotion recognition in speech and ECG signals
- Ergodic capacity analysis for device-to-device communication underlaying cellular networks
- Intrusion detection model based on deep belief nets