
基于GATE框架的地理事件信息抽取设计与实现*
2015-06-30 09:11陈晓慧李海岗
现代测绘 2015年4期
张 伟,陈晓慧,岳 耀,李海岗
(1.信息工程大学,河南 郑州 450000;2.61175部队,山东 淄博 255000;3.地理信息工程国家重点实验室,陕西 西安 710000)
1 引 言
随着科学技术的不断进步,尤其是互联网的飞速发展,用户不仅使用网络下载各类数据,也会通过网络通信产生大量信息内容。如何实时处理和掌握各种 UGC(User Generated Contens)方式产生的地理空间隐喻数据,提取具有空间和时间属性的地理事件信息,已成为地理空间情报领域研究的重要内容。本文通过对地理事件本体模型的研究,以Gate自然语言处理框架为基础,实现地理事件信息抽取,为地理事件分析和可视化提供支撑。
2 基于本体的地理事件语义模型
本体是哲学的概念,关注的是客观现实的抽象本质,最早引入信息科学的目的是为了解决信息唯一性的问题[1]。在信息抽取领域,本体是概念化的明确表述,避免概念之间的关系混淆,解决语义层次上信息共享。
2.1 地理事件概念解析
地理事件是时空数据模型研究过程中提出的概念、时空数据模型,主要有时间附加型,时间四维型、面向对象型和基于事件型4种[2]。因为面向的应用领域不同,对地理事件也没有统一定义,例如数据更新领域,地理事件是地理要素状态与事件共同构成时空对象模型,强调事件的动态性[3];信息检索领域,地理事件是发生在地表空间的各种自然和社会现象,强调静态结果[4]。
本文从地理事件的本体出发,研究信息抽取领域地理事件的概念模型,给出基于本体的地理事件统一模型,为地理事件的信息抽取提供支撑。因此,信息抽取领域的地理事件是指与地理空间信息相关的对象,和它的时间、空间(位置、形状和关系)、属性等发生变化的地理现象。地理事件是一个<Te,Le,Pe,E>四元组集合,其中Te是地理现象的时间属性,Le是地理想象的位置属性,Pe是地理现象的非时空属性,E是地理现象。
2.2 地理事件本体模型
Perez归纳了用于描述本体的基本建模原语包括[5]:类或概念、关系、函数、公理、实例。其中,基本关 系 有 part-of、kind-of、instance-of、attribute-of 4种。
地理事件本体定义为:GeoEvent-Ontology=<GEC、GER、GEH、GEP、GEI>五元组。
(1)GEC——地理事件概念(本体中称作类),表示具有相同属性的对象集合。
(2)GER——地理事件语义关系,概念间的并列关系。
(3)GEH——地理事件层次关系,概念间的层次关系。
(4)GEP——地理事件属性,主要有属性对象和属性限制。
(5)GEI——地理事件实例,即概念的现实实现。
2.3 基于本体的地理事件的语义描述
语义描述的方法有很多,其中 XML、RDF、OWL应用广泛。XML语言可创建具有语义的自定义标签,将数据与显示分离,树结构表示,但是不能表达被机器识别的语义;RDF用URI来标识事物,通过二元关系模型的有向图结构表示能被机器识别的知识表述语言;OWL是RDF扩展,是本体描述语言[6]。
基于本体的地理事件语义描述采用OWL本体语言进行描述,以地震事件为例,如下所示。
<owl:Class rdf:about=“#地震”>
<owl:unionOf rdf:parseType=“Collection”>
<owl:Class rdf:about=“#特大地震”/>
……
<owl:Class rdf:about=“#极小地震”/>
</owl:unionOf>
</owl:Class>
3 基于GATE地理事件抽取的框架设计
3.1 GATE简介
GATE(A General Architecture for Text Engineering),通用文本工程框架,是由Sheffield大学提供的一款基于java的开源软件。GATE的主要功能是基于标注的信息抽取,是计算机语言学(CL)、自然语言处理(NLP)、语言工程学(LE)的软件基础设施和开发工具。
3.1.1 GATE体系结构
GATE是基于JavaBean的可重用组件式开发[7],其核心是CREOLE组件集,具体划分为3类组件。
(1)语言组件(LR):主要包括数据相关的实体,例如文档、语料库、标注等。
(2)处理组件(PR):主要包括与算法相关的实体,例如解析器、生成器等,会对本体、词表、规则等进行操作。
(3)可视化组件(VR):主要包括图形组件,提供用户图形界面。
3类组件构成了GATE的MVC体系框架,即模型-视图-控制器的设计模式。
3.1.2 GATE的规则语言
GATE信息抽取采用基于规则的方法(有别于基于统计的方法),通过JAPE规则定义语言,实现命名实体的识别与标注。JAPE规则的基本结果如下。
(1)每条规则(rule)分为左侧(LHS)和右侧(RHS)2部分。
(2)左侧是标注识别规则,包含操作符(|,*,?,+)等标注模式。
(3)右侧是标注操作规则,包含对标注集操作的描述。
3.1.3 GATE组件开发
GATE执行流程如下:通过建立Application应用将相关的处理组件PR拼接起来,创建工作流水线对文本进行处理。例如GATE内置组件ANNIE等。
GATE提供了一个开发组件的环境架构,在此架构上可以开发自己的组件,支持架构和组件导出(gate.jar),并且可以方便地嵌入到其他应用程序中。自定义组件继承于GATE的CREOLE资源的3类组件,一般包括jar包和xml及Jape规则制定,具体如下。
(1)建立基于GATE接口的java类,并编译。(2)编写XML配置数据。
(3)把JAR和XML集成到GATE中。
3.2 地理事件信息抽取框架设计
3.2.1 信息抽取
信息抽取就是从文本中抽取特定实体、关系及相关信息。MUC定义了信息抽取的5个类型[8],包括:命名实体识别(NE)、共指消解(CO)、模板元素构建(TE)、模板关系构建(TR)和情景模板建立(ST)。
信息抽取常用方法有基于自然语言处理、基于规则、基于统计学习3种方法。其中基于统计学习是利用统计知识对未标注语料进行训练并获取信息的方法;基于规则是从带标注的训练语料库中提取规则,用构建规则库的方式匹配信息的方法。
GATE采用基于规则方法进行信息抽取,步骤如下。
(1)首先,对原始语料库进行标注,得到带标注的训练语料库。
(2)其次,定义规则的表示模式,例如GATE基于键值对的标注集和特征集。
(3)最后,根据规则模式,采用算法学习规则,构建规则库,例如覆盖算法、压缩算法等。
3.2.2 框架设计
基于GATE的地理事件信息抽取流程框架如图1所示。首先,根据地理事件的任务描述,对原始语料数据进行信息抽取的预处理,主要是数据清洗、中文分词、句子拆分、词表构建等。其次,随机划分标注训练语料库和未标注的测试语料库,对标注训练语料库进行规则的机器学习,构建规则库。对通过语义网本体解析得到的本体库也可以进行规则学习,导入规则库。最后,利用GATE框架对测试语料库进行基于规则的信息抽取,得到地理事件的描述信息。
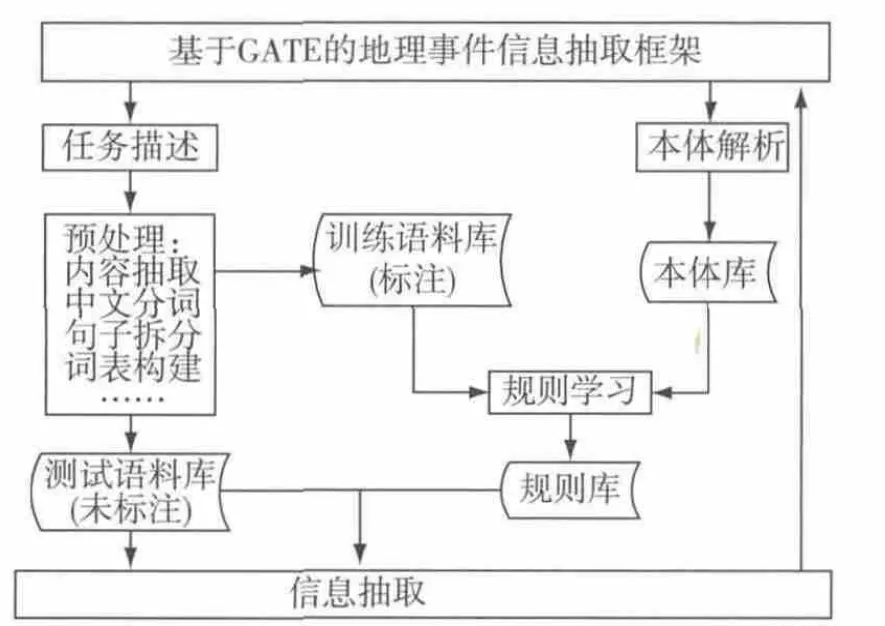
图1 基于GATE的地理事件信息抽取流程
4 基于GATE地理事件抽取的预处理
4.1 JAPE规则的制定
制定利用GATE进行信息抽取的规则至关重要。GATE中规则被保存为*.jape文件,一般存放在grammer文件夹中。JAPE是规则制定的基本语言,是提高命名实体识别精度的关键。但是,JAPE有其自身优点,主要如下。
(1)JAPE允许右边部分不仅仅可以添加属性项,也可以编写java代码,很大程度上扩展了GATE规则的强大功能。
(2)JAPE可以使用宏的概念,避免不同规则重复信息出现。
(3)JAPE可以编译并存储为java对象。
地理事件命名实体的抽取规则应根据任务的需求定制。只有在一定的语言环境中,才能更好进行信息抽取。地理事件规则库是根据训练语料不断学习更新的,规则学习的好坏对信息抽取至关重要,以下是规则示例。
Rule:Location
Priority:100
(({Lookup.majorType==location})+):tag-->
{gate.FeatureMap features = Factory.new-FeatureMap();
gate.AnnotationSet locSet= (gate.AnnotationSet)bindings.get("tag");
gate.AnnotationSet loc= (gate.Annotation-Set)locSet.get("Lookup");
if(loc!=null &&loc.size()>0)
{gate.Annotation locAnn = (gate.Annotation)loc.iterator().next();
features.put("locType",locAnn.getFeatures().get("minorType"));}
features.put("rule","Location");
outputAS.add(locSet.firstNode(),locSet.lastNode(),"Location",features);
outputAS.removeAll(loc);}
4.2 GATE词表的构建
GATE中的词表(gazetteer)由一组列表组成,用于发现文本中包含这些名称的命名实体,其标注类型为lookup。词表用基于规则的方法,而语料用基于统计的方法进行信息抽取。GATE自身词表数量有限,且中文词表不够完善,尤其是专业领域词表不全。因此,需要根据任务更新词表。
GATE中词表被保存在*.lst文件中,多个词表会建立索引文件,一般保存为lists.def文件。词表索引文件描述每个列表的主要类型、次要类型和语言,用冒号隔开。如表1所示,第一列是词表文件名,第二列是主要类型,第三列是次要类型。

表1 词表索引格式
词表文件可以用任何文本编辑器打开或修改,也可以在GATE框架中打开,一般词表用UTF-8编码形式存储。如图2所示,左边显示索引文件,右边显示词表文件,有1+2n列(值,特征1,值1……特征n,值n)。词表的质量及完善性直接决定了命名实体识别的准确率和效率。

图2 GATE中词表编辑显示
5 基于GATE地理事件的信息抽取
5.1 中文文本分词
信息抽取的前提是对文本进行分词,GATE对中文分词做的不够好,因此需要借助中文分词组件弥补不足。ICTCLAS是中科院计算技术研究所研发的分词软件,该软件中文分词精度可达98.45%,是目前比较流行的汉语词法分析器。
GATE是基于java语言编写的框架,要调用ICTCLAS的C++函数接口,需要通过JNI调用其分词效果,如图3所示。
基于GATE的中文分词只是利用ICTCLAS进行分词,不需要词性标注。以空格将文本进行分词之后,即可转换为GATE识别的格式,进行下一步处理。

图3 ICTCLAS中文分词和词性标注效果
5.2 命名实体识别
命名实体是文本中最基本的信息元素,包括现实世界中的实体甚至时间、数量等。根据MUC标准,命名实体可分为:人名(Person)、地名(Location)、机构名(Organization)、日期(Date)、时间(Time)、百分数(Percentage)、货币(Monetary Value)等几大类[9]。根据ACE的解释,实体在文本中有命名性、名词性、代词性3种表现形式。
命名实体识别是从文本中匹配识别命名实体,是信息抽取的关键。命名实体识别有基于规则的方法和基于统计的方法2种[10]。早期的命名实体识别采用基于规则的方法,移植性差。而基于统计的方法是在大规模语料基础上进行的,主要有以下4种。
(1)有监督学习方法,例如 HMM、MEM、SVM、CRF、DT等。
(2)半监督学习方法,例如利用标注的小规模语料自己学习。
(3)无监督学习方法,例如利用词典进行文本聚类。
(4)混合方法,几种方法或模型的结合。
基于GATE的命名实体识别采用基于规则的学习方法,首先对文本进行分词,再对已有词典进行查找匹配,对未识别实体进行标注规则学习,最后将识别结果按照标注模式进行信息抽取,以此得到用户关心的内容,如图4所示。
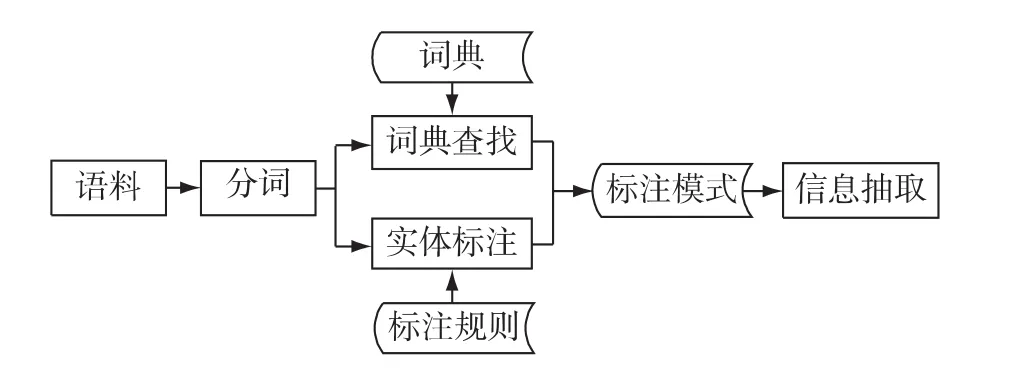
图4 基于GATE的命名实体识别流程示意图
5.3 标注语料库生成
GATE中标注类型通过标注模式库来定义,支持XMLSchema表示的标注模式,可根据解析器进行扩展,表示领域本体的标注模式,例如地理事件中地震事件的标注模式文件(如下所示)。地理事件本体中不同的概念对应不同的标注模式并以此共同构成标注模式库。
<?xml version="1.0"encoding="utf-8"?>
<EventList><Event>
<DataId>1</DataId>
<Type>新闻</Type>
<Url>http://news.21cn.com/caiji/roll1/a/2015/0401/18/29324097.shtml</Url>
<Date>2015年04月01日07:18</Date>
<EventTitle>贵州剑河5.5级地震已致3万余民众受灾</EventTitle>
<EventType>地震</EventType>
<Annotated><when>2015年3月30日9时47分</when>,<where>贵州省</where><where>黔东南</where><where>苗族侗族自治州</where><where>剑河县</where>发生<what>5.5级地震</what>,震源深度7千米。</Annotated>
</Event></EventList>
6 总 结
随着互联网信息的日益增长,面向任务的信息抽取成为各个领域研究的重要内容。本文基于GATE的地理事件信息抽取是地理空间信息领域面向地理事件挖掘的研究内容。通过对地理事件本体模型的研究,利用GATE自然语言处理框架,可以对领域语料库进行中文分词、词表构建、规则制定、命名实体识别等,实现了地理事件的标注和信息抽取。
[1] 王振峰.基于本体的地理事件信息检索[D].武汉:武汉大学,2009.
[2] 杜哲.GIS时空数据模型研究[D].北京:北京林业大学,2011.
[3] 王艳军,徐狄军,李丹农,等.面向服务架构的地理要素在线更新[J].测绘通报,2013(6):41-44.
[4] 严薇.基于地理事件的变化信息存储管理和应用研究[D].郑州:信息工程大学,2011:28-30.
[5] Perez A G,Benjamins V R.Overview of Knowledge Sharing and Reuse Components: Ontologies and Problem-Solving Methods[C]// Proceedings of the 16thInternational Joint Conference on Artificial Intelligence(IJCAI-99).Stockholm:the IJCAI-99 Workshop,1999:1-5.
猜你喜欢
校园英语·月末(2021年13期)2021-03-15
英语世界(2021年13期)2021-01-12
——三份医学英语词表比较分析
江西理工大学学报(2020年2期)2020-05-21
天津外国语大学学报(2020年1期)2020-03-25
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
语言与翻译(2015年4期)2015-07-18
外语教学理论与实践(2014年4期)2014-06-13
图书馆建设(2012年3期)2012-10-23
对联(2011年20期)2011-09-19
