
基于数据挖掘的恶意程序智能检测研究
2015-06-25 08:51刘晓蔚
东莞理工学院学报 2015年1期
刘晓蔚
(东莞理工学院 科研处,广东东莞 523808)
恶意程序是一个包含恶意攻击的可执行的程序,如破坏系统或非法获取敏感的用户信息[1-2]。在恶意程序检测中,使用数据挖掘技术就是为了能够建立一套自动检测恶意可执行文件的方法。数据挖掘的检测模式基于海量数据,并使用这些检测模式来检测相似数据[3-5]。设计的检测系统框架是使用分类器检测新型特征的恶意程序,分类器是一种由数据挖掘算法进行训练的规则集。
当前每天都会产生8 ~10 种新恶意程序,2012年新增木马病毒恶意程序已达到几千万,这些恶意程序破坏度大,给用户带来了巨大的损失[6]。而且很多类型的攻击都使用恶意程序来进行,DARPA 检测评价的攻击中,Windows 平台遭受的恶意攻击基本上都是基于恶意程序[7]。目前,微软发布了基于内核网络的漏洞,恶意程序可以使用该漏洞打开后门进入微软内部网络窃取各种资料。恶意程序数量呈几何数增长,给用户信息安全造成了巨大危害。
传统的“获取样本-分析特征-更新部署”方法已无法满足当前查杀病毒的需求[8],为了解决反病毒软件的各种困扰,设计了一种基于新型特征的数据挖掘技术提取恶意程序的智能化检测规则,该方法用Windows 平台可执行文件格式作为主要特征,抽取执行文件的特征,然后分析并获取恶意程序的新型特征,使用数据挖掘技术提取检测规则,找出恶意程序的隐性规则,提高准确率。
1 关键技术
1.1 恶意程序
恶意程序分为六类[9]:病毒、蠕虫、木马、僵尸程序、间谍程序和流氓软件,这六类恶意程序给用户带来巨大的损失。为了对抗反病毒程序,这些恶意程序具有反调试技术、反虚拟机技术、加壳技术及对抗安全软件的技术。
1.2 数据挖掘
为了应对恶意程序的反检测技术,提高恶意程序检测的准确度,目前用于恶意程序检测的技术种类众多,其综合性能较好的数据挖掘技术有:神经网络、贝叶斯、支持向量机、决策树和关联规则等[10]。但这些技术仍然存在着诸多缺陷,如忽视筛选恶意程序特征方法、无法与客户端检测并且检测的效率较低。基于此,设计了一种筛选恶意程序新型特征的方法,并在此基础上提取了恶意程序检测的智能规则,通过该规则可以检测多类恶意程序,并具有通用性。首先提取样本特征,然后对样本特征数据进行预处理,通过处理结果筛选出新型特征,最后提取智能规则。
2 样本数据处理
2.1 样本数据筛选
所研究的源数据采用VX Heavens 中的样本数据,从该网站下载PE 格式的恶意程序样本25 585 个,其中正常程序数量为4 730 个,图1 描述了样本数据中各类程序的分布情况。
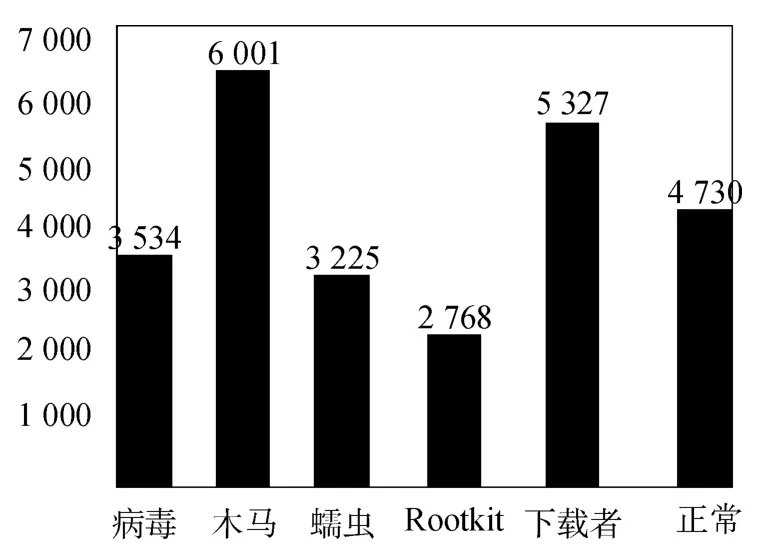
图1 样本数据分布表
2.2 样本数据标准化
为了获取PE 特征,首先对样本特征数据进行提取,提取过程包括:修改PE 文件、PE 头信息获取、PE 节分析、可疑值和恶意值报告、检测加壳文件五个步骤。本文设计的数据提取方法采用pefile提供的python 库进行实现。样本数据经过提取之后,部分属性会以文本的形式存在,不能被数据挖掘工具识别,因此必须通过数据字典映射的方式将数据标准化。将样本数据的属性进行取值标准化,如在描述入口点特性时,通常有无效、有效、模糊三种方式,因此对其以0、1、2 分别进行代替;对于是否异常的情况,对其以0、1 进行代替。
2.3 样本数据分析处理
由于数据缺值或者噪声的原因,在数据挖掘中会降低准确度,因此在数据标准化之后需对数据进行清理,目的是保证样本特征数据干净、整齐,使得数据挖掘的结果更加准确,本节针对缺值处理、探测和清除孤立点对数据进行分析处理。
1)缺值处理。
Windows 平台上由于文件完整性被破坏造成的缺值属于非正常缺值,为了删除这些非正常缺值,处理该非正常缺值数据时采用直接删除法;处理非正常缺值以外的其他缺值不会影响程序的执行,处理该正常缺值数据时采用统计填充法。
缺值处理算法如下:

其中,Y 为样本集合,y 为样本实例,a 为y 的属性,L 为合理缺值集合,U 为不合理缺值属性集合,average(a)为a 属性列的平均值。
“很遗憾,测试已经结束了。”詹寻摇了摇头,“20次模拟海战的结果,已经足够说明问题,我们的任务完成了。谢谢大家的帮助,你们早点回去休息吧。”
根据本算法共找出10 372 个缺值样本,其中合理的缺值为3 017 个,不合理的缺值为7 310 个。
2)探测和清除孤立点。
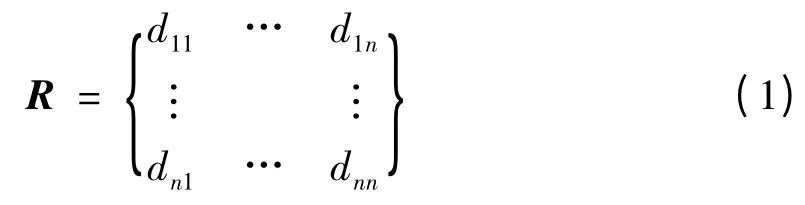
样本数据不可避免的会有孤立点,因此会造成样本数据存在噪声,为消除噪声,使用基于距离和孤立点检测的方法删除孤立点。该方法对原始样本数据集进行标准化后,计算n 个对量两两之间的距离dij,由此形成一个距离矩阵R,如公式1。
根据距离矩阵R,令pi=,当Pi值越大时,说明对象i 与其他的对象距离越远,把Pi最大的若干项删除掉,便清楚掉样本数据的孤立点。
根据该方法共找出6 224 个孤立数据,清楚这些孤立数据项可保证分类规则的准确性。
由以上两种方法,样本数据集的处理结果如图2 所示。
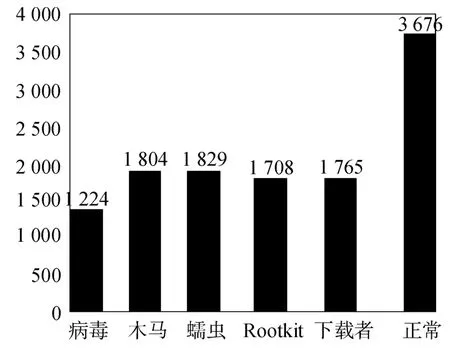
图2 处理后的样本数据
3 筛选新特征
3.1 删除属性相同的数据和属性间线性相关数据
1)样本数据集经过数据处理后,会存在部分属性值一样的数据,这些数据对分类没有实际意义,例如每个PE 文件都会有“MZ”标志,这部分数据会提升特征复杂度,因此对这部分数据进行直接删除,降低特征向量维度。
2)线性相关数据分为函数关系和统计关系两类,函数关系表示变量之间数量上的确定性关系,统计关系表示变量之间的相随变动的某种数量的统计规律性。样本数据集经过数据处理后会存在部分此类数据,如PE 文件头部若标志了一个文件为DLL,则这个文件必然有导出函数,则这两个属性线性相关。
该算法如下,其中p、q 为常数。

3.2 冗余数据处理
冗余特征消除算法用主成分分析法,该方法将多个变量通过线性变换选出较少个数的重要变量,其最优性侍从N 个训练集中提取n 个主要特征,从而降维。假设N 个d 维的原始样本为x1,x2,…,xn组成一个矩阵X(d* n),通过式(2)把X 投影到低维空间的向量Y,计算出样本均值μ 后,通过式(3)得到协方差矩阵ST,最后通过式(4)计算ST的特征值ei。

通过上述方法和SPSS 统计软件对样本集的恶意程序特征进行综合评价,得到如表1 样本集特征值表。
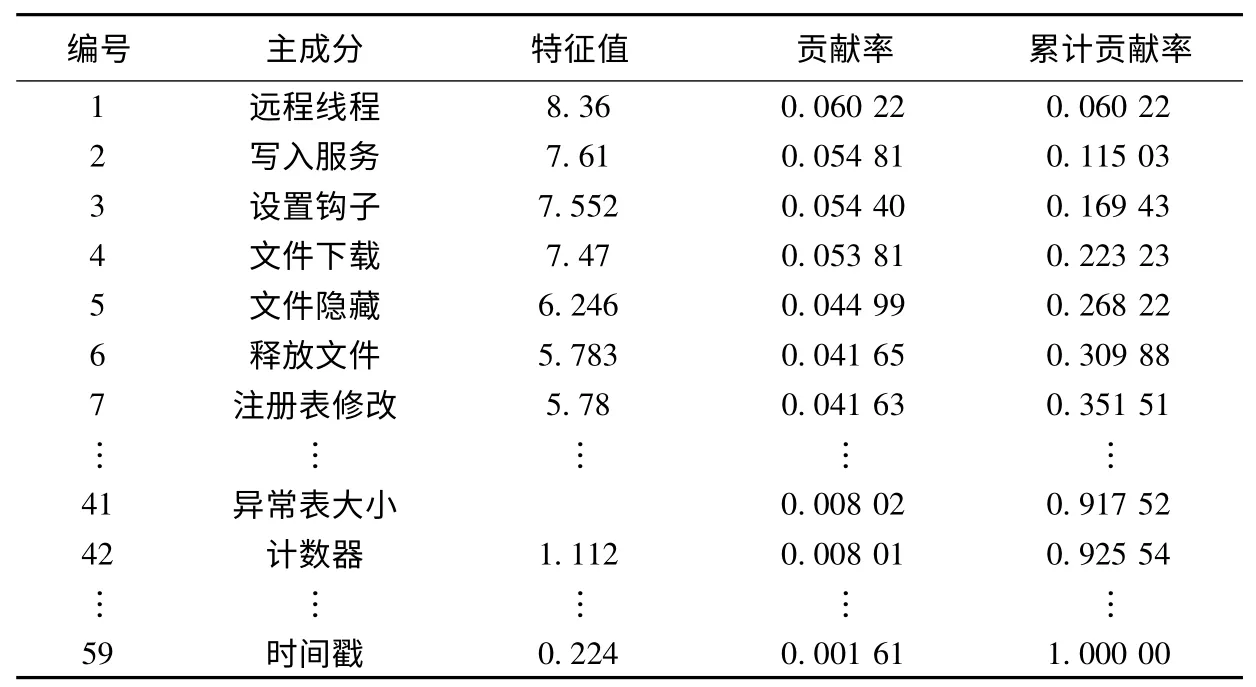
表1 特征值分析结果
由上表,保留主成分系数大于92%并且特征值大于1 的特征值,删除其它18 个不符合要求的特征项。经过特征值筛选后,得到41 个属性作为恶意程序的新型特征,并且恶意程序的特征向量包括以下属性:序号、文件名、文件类别、文件头信息、API 函数序列、API 函数名。其中文件类别使用0、1 表示,0 表示正常程序,1 表示恶意程序。
4 特征评估
为了对筛选后的41 个新特征进行评估,验证其有效性,将对本文的新特征进行仿真实验,得出实验结果,包括准确率、误报率和漏报率。
本文使用的数据集从VX Heavens 下载,是经过数据处理后的11 955 个PE 文件信息,并选择Knime作为数据挖掘平台。Knime 的分类工作流程为原始数据经过列的过滤和颜色区分后得到训练集和测试集,训练模型对训练集和测试集训练后,对预测进行打分,最后得到评估模型。本文原始数据集为11 955 个数据,包含3 676 个正常程序和8 279 个恶意程序。如表2 所示的几种分类算法的测试结果。
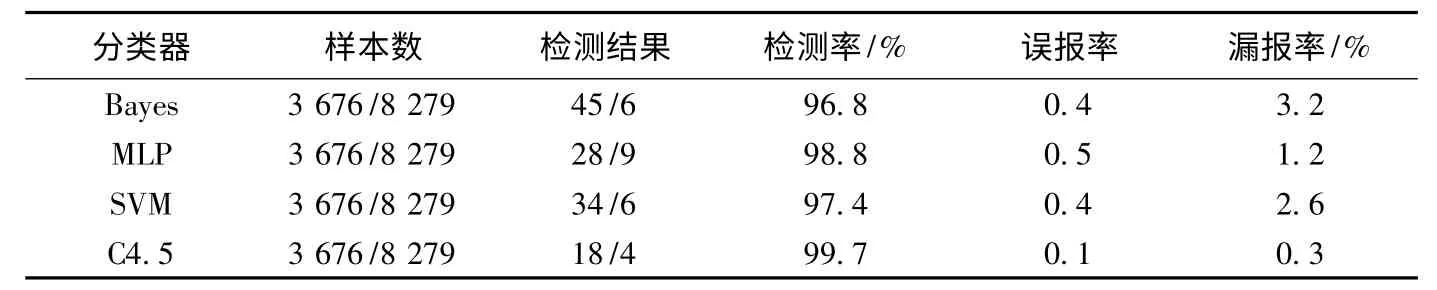
表2 特征值评估结果

图3 Knime 生成的智能规则树
5 提取规则
提取规则的目的是为了将正常程序和恶意程序分开,而且需要有较高的检测率和较低的误报率,根据表2 的检测结果,发现使用决策树的C4.5 算法可以得到最好的检测效果,因此本文选择C4.5 作为构建分类器的算法,在Knime 平台上生成如图3 所示的决策树结果,由于结果数据较大,该图仅为部分决策结果。
6 结语
本文将PE 文件格式作为主要特征来源,通过筛选新型特征得到了恶意程序新型特征以及可重复利用的智能检测规则,并通过Bayes、MLP、SVM、C4.5 分类方法对其进行的验证,实验结果表明,将该新型特征应用于分类算法中具有较低漏报率、误报率和较高的检测率,对提高恶意程序检测的效率和准确率具有重要的作用。
[1]刘辉. 基于虚拟机的网络计算模型[J].科学技术与工程,2005,16(5):1209-1211
[2]Thuraisingham B. Data mining for malicious code detection and security applications[C]//proc of Europen Intelligence and Security Informatics Conference[s.l.]. IEEE Conference Publications,2011.
[3]颜富强,吴昊.一种基于免疫遗传算法的数据挖掘方法[J].科学技术与工程,2008,14(8):3966-3969.
[4]罗文华. 基于逆向技术的恶意程序检测方法与研究[J].警察技术,2012(6):26-28.
[5]罗文华.基于逆向技术的恶意程序分析技术[J].计算机应用,2011,31(11):63-64.
[6]Masud M M,Khan L,Thuraisingham.A Hybird Model to Detect Malicious Executables[C]//in proc of the IEEE international onference on communication(ICC'07). IEEE Conference Publications,2007.
[7]罗文华.基于抽象解释理论抽取多态恶意程序特征码[J].信息网络安全,2013(1):16-18.
[8]李鹏,王汝传.基于自相似特性的恶意代码动态分析技术[J].南京邮电大学学报:自然科学版,2012,32(3):86-90.
[9]张一驰,庞建民,范学斌,等.基于模型检测的程序恶意行为识别方法[J].计算机工程,2012,38(18):107-110.
[10]Farrukh S,Muddassar F. ELF-Miner:using structural knowledge and daga mining methods to detect new(Linux)malicious executables[J]. Knowl Inf Syst,2012,30:189-192.
猜你喜欢
小猕猴智力画刊(2022年3期)2022-03-29
数学小灵通(1-2年级)(2021年4期)2021-06-09
中学生数理化·高一版(2021年2期)2021-03-19
大众投资指南(2021年35期)2021-02-16
知识经济·中国直销(2018年8期)2018-08-23
Coco薇(2017年11期)2018-01-03
电力与能源(2017年6期)2017-05-14
数学学习与研究(2017年3期)2017-03-09
暨南学报(哲学社会科学版)(2016年9期)2017-01-15
中国老区建设(2016年1期)2016-02-28
