
视频检索中基于GMM聚类的无监督情感场景检测
2015-06-22 14:40:00齐兴斌李雪梅
电视技术 2015年5期
齐兴斌,赵 丽,李雪梅,田 涛
(1.山西大学 计算机工程系,山西 太原 030013;2.北京航空航天大学 计算机学院,北京 100083;3.北京师范大学 教育信息技术协同创新中心,北京 100875)
视频检索中基于GMM聚类的无监督情感场景检测
齐兴斌1,赵 丽2,李雪梅1,田 涛3
(1.山西大学 计算机工程系,山西 太原 030013;2.北京航空航天大学 计算机学院,北京 100083;3.北京师范大学 教育信息技术协同创新中心,北京 100875)
为了高效地从视频中检索出激动人心的场面,提出了一种基于高斯混合模型的无监督情感场景检测方法。首先,从面部选取42个特征点,并定义10种面部特征;然后,利用高斯混合模型将视频的帧划分为多个聚类;最后,利用每一帧的面部表情分类结果将情感场景划分为单个聚类,并通过场景集成和删除完成检测。在生活记录视频和MMI人脸表情数据库上的实验结果表明,该方法的检测率、分类率分别高达98%,95%,检测5分钟左右的情感场景视频仅需0.138 s,性能优于几种较为先进的检测方法。
视频检索;情感场景检测;面部表情识别;无监督;高斯混合模型
生活记录视频[1]有着较为严重的问题,即难以轻松有效地从大量的视频数据中检索出有用的场景画面。因此,有价值的生活记录视频并不能经常得到使用。为了解决该问题,本文提出了一种对于生活记录视频检索有效且令人印象深刻的场景检测方法。令人印象深刻的场景通常都是有用的,因为从生活记录视频检索中检索出来都作为重要事件来使用。生活记录视频通常包含人,他们的情绪变化会改变令人印象深刻的场景。因此,本文基于人脸表情识别提出了一种情感场景检测(ESD)方法,因为情绪可以从面部表情来估计。
近来面部表情识别[2]被广泛地研究,并应用到视频场景检测中[3],但大多数现有的方法侧重于识别典型的面部表情[4](例如愤怒、厌恶、恐惧、快乐、悲伤和惊奇)。然而在生活记录视频中,那些更复杂和/或微妙的面部表情,例如,微微一笑、充满微笑和苦笑都可以观察到[5]。因为大多数现有的方法需要预定义的面部表情[6],这使得有用的场景难以被检测,包括各种各样生活记录视频的面部表情。
文献[7]提出了一种基于人脸表情识别的生活记录视频的情感场景检测方法,该方法能够检测不同的面部表情但是面部表情必须被提前指定。考虑到要检测出各种情绪的场景,因此所有的面部表情很难预先确定,此外,大量较为麻烦的练习数据,都需要构建一个面部表情识别模型。
本文方法中,面部表情识别模型是基于使用高斯混合模型[8]的无监督聚类方法构建的。由于本文方法是无监督的,它不需要同时要求学习的数据和面部表情的预定义。此外,利用人脸表情识别中几个人脸特征点的唯一位置关系,并通过引入分层情感场景集成方法显示出本文提出的情感场景检测方法是完全有效的。通过一些情感场景检测实验,可发现本文方法的灵活性和有效性。
1 面部特征
1.1 面部特征点

1.2 面部特征值
使用面部特征点来定义以下10种面部特征,从而检测在不同面部表情外观下面部特征点的区别。
这个特性值是基于利用最小二乘法从左右眉毛上的面部特征点上得到两行的梯度a1和ar。通过式(1)可获得该特征值。
(1)
使用眉毛和眼睛上侧之间的人脸特征点的平均距离,并通过式(2)来获得该特征值。
(2)
式中,lN是一张人脸大小的差异归一化因子。它被定义为左眼和右眼的中心点之间的距离,lN=‖p27-p28‖。

这个特征值是在4个人脸特征点p5,p6,p16和p15围成的区域中通过式(3)得到的,并且p15位于眉毛和眼睛的内角形成的区域。
(3)
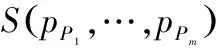
通过归一化的两个八边形所表示的左眼和右眼的区域,特征值由式(4)来定义。
(4)
基于眼睛顶部和底部点之间的距离与眼睛左侧和右侧点之间的距离比,这个特征值定义为
(5)
这个特征值是在由嘴巴周围的8个面部特征点所围成的一个八边形区域中,定义为
(6)
类似于第6个特征值,这个特征值是通过嘴巴内圈内8个面部特征点而形成的八边形区域,定义为
(7)
基于嘴巴周围顶部和底部点之间的距离与嘴巴周围左侧和右侧点之间的距离比,定义为
(8)
类似于第8个特征值,这个特征值是基于嘴巴内圈顶部和底部点之间的距离与嘴巴内圈左侧和右侧点之间的距离比,定义为
(9)
10)垂直于嘴角的位置
此特征值代表嘴角的位置高度,定义为
2 人脸表情识别模型
大多数现有的面部识别方法都是基于监督学习的[11-12],监督学习通常需要大量的训练数据。本文提出了一种无监督人脸表情识别模型,以消除预定义的面部表情和准备训练数据。
2.1 特征向量

(11)


(12)
(13)
式中,m是用于构造新的特征向量的主成分的数目,因此Xi是m维向量。对于每个j≤m,ljk是第j个主分量的第k个分量的量。
2.2 高斯混合模型
面部表情识别模型是通过基于高斯混合模型使用特征向量的聚类算法构建的,聚类通过期望最大化(ExpectationMaximization,EM)算法[14]构成。在视频的每个帧被分配到聚类,聚类对应一个特定的面部表情,从而生成的K聚类对应的帧划分为K种面部表情。
该聚类算法如算法1所示,本文在初始化步骤中给出随机值参数值ξ,μ和M,阈值ε设置为10-3。
算法1,即基于高斯混合模型的聚类算法,具体描述如下:
1)初始化ξk,μk和Mk,分别表示混合系数、平均矢量和第k个高斯分布的方差-协方差矩阵。
t←1,其中t为步数。

(14)
(15)
3)(M步骤)分别根据方程(16)、(17)和(18)更新ξ,μ和M。
(16)
(17)
(18)

4)如果式(19)条件满足,则转到步骤5)。否则,t←t+1,回到步骤2)。
(19)
式中:ε是终止条件的阈值,并且
(20)
5)根据式(21)分配给每个帧的集群CK(Xi)。
(21)
3 情感场景检测
通过使用第2章中所示的面部表情识别模型,将一个视频的帧划分为K个聚类[15](即划分为K种面部表情)。利用每一帧的面部表情分类结果将情感场景划分为单个聚类,因为某些类型的面部表情可以从一个视频中通过分析单个聚类进行检测。
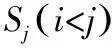
(22)

对于场景Si,如果Si和Si-1之间的距离小于阈值θ,则Si-1被集成为Si,如图1a所示。如果Si和Si+1之间的距离小于阈值θ,则Si+1被集成为Si。

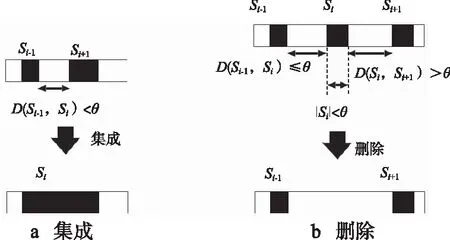
图1 场景集成和删除
情感场景的集成和删除过程一直重复进行,直到没有更多的场景可以被用来集成或删除,在视频中包含着多个面部表情的情况下,上述情感场景检测分到每个聚类中,详细的检测算法如算法2所示。
算法2,即情感场景检测算法,其伪代码如下:



结束条件

结束条件

如果v=1,那么
完成场景检测(没有情感场景输出)。
或者
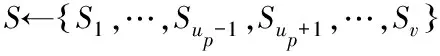
转到步骤6)。
结束条件
结束条件
6) 如果p=v,那么
i从1到v

结束条件
完成场景检测。
或者
p←p+1并且回到步骤5)。
结束条件
7)更新S中元素的索引,如下所示:
4 实验
4.1 生活记录视频
实验通过5位研究对象来准备了5个生活记录视频(称为研究对象A、B、C、D和E),所有研究对象都是男性大学生。对于所有研究对象,都通过打牌场景记录为生活记录视频。每个生活记录视频的长度、大小和帧速率分辨为5 min、640×480像素、25 f/s(帧/秒),从每个视频中每10帧挑选出1帧,每个视频共750帧。
由于大多数生活记录视频中观察到的面部表情都是微笑[16],设定聚类K的大小为2,即通过生活记录视频的帧分成笑容和非微笑来检测微笑的场景。图2a和2b所示为情感帧图像示例,图2c和2d所示为非情感帧图像示例。
情感场景检测精度的阈值θ如图3所示,对于大多数的受试者,阈值θ越小,检测精度越低。当θ值较小时,检测结果中会出现许多无用的场景,导致精度降低。此外,θ值较大时,检测结果可能会忽略许多有用的场景,因此,θ=25适合大多数的受试者。

图2 情感帧及非情感帧

图3 对于每个受试者情感场景检测的精度
当θ=25时,除了受试者E,所有受试者检测精度都在0.9以上,甚至最高可达0.996。考虑到本文方法不需要训练数据,并且在该实验中所用的视频包含各种类型的笑容,因此检测精度应该是相当不错的。
受试者E的检测精度比其他受试者都相对较低,这是因为受试者E的脸有时会用其双手遮挡,这种情况下很难精确地检测面部特征点,故无法很好地辨别面部表情。
4.2MMI表情数据库
使用MMI人脸表情数据库[17]进行了一次情感的场景检测实验,该数据集包含29个受验者,年龄在18~63岁之间,有男性和女性的短片。实验从MMI数据集中选取100个实例(即视频剪辑)。由于实验使用的视频包含一种无表情及6个面部表情,聚类K设定为7,表1所示为实际的训练和测试序列,表2所示为检测到的训练和测试序列平均数,表3所示为测试序列的正确和错误分类。

表1 实际的训练和测试序列

表2 检测到的训练和测试序列

表3 测试序列的分类结果
从表2可以看出,分别有1个愤怒和1个惊讶表情没有检测到,主要由于这两种表情的特征点受表情影响而不规则,检测到的训练和测试序列总数为98,而实际的训练和测试总数为100,检测正确率为98%。
从表3可以看出,分类阶段,所有恶心、幸福、悲伤和惊讶表情的分类都准确,由于愤怒与恐惧、恐惧与惊讶易混淆,一个愤怒场景被误分类为恐惧,一个恐惧场景被误分类为惊讶,40个测试表情中产生了2个错误分类,正确分类率为95%。
此外,使用处理器为XeonW3580(主频为3.33GHz)内存为8Gbyte的计算机测试了检测模型的用时,“功能”、“主成分”、 “聚类”和“检测”的处理时间分别对应于计算面部特征、进行主成分分析得到特征向量、通过聚类分类每个帧的面部表情、检测情感场景,“总数”表示整个处理时间,表4所示为本文模型各个阶段的耗时情况。

表4 各个阶段的耗时 s
提取人脸特征和集群的特征矢量的时间构成了处理时间的很大一部分,然而,该方法非常有效,从表4可以看出,检测平均5min长的情感场景视频仅需0.138s,表明本文方法有望应用于大规模视频数据库。
4.3 性能比较
实验将本文方法的检测率、分类率和总耗时与其他几种较好的检测方法进行比较,包括Gabor多方向特征融合(GMDFF)[2]、文献[7]提出的面部特征选取方法、基于稀疏表示的KCCA方法(SRC-KCCA)[13]、文献[15]提出的霍夫森林(HoughForest,HF)方法,比较结果如表5所示,其中,实验设置与4.2节相同,各个比较方法的参数设置均参考各自所在文献。
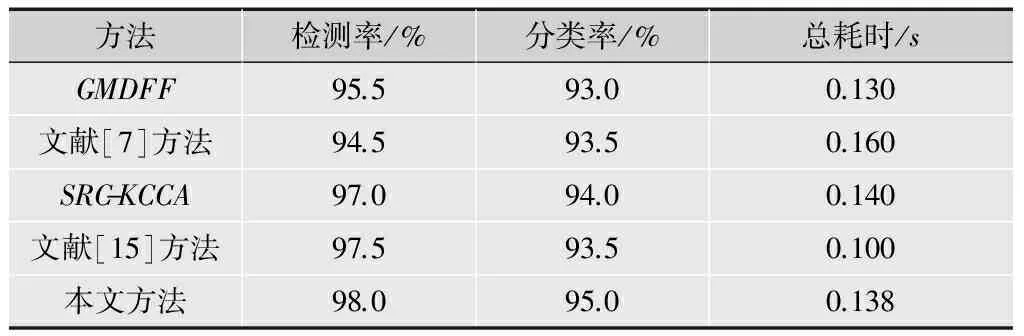
表5 各方法的性能比较
从表5可以看出,相比其他几种方法,本文方法取得了更高的检测率和分类率,相比文献[15]方法,本文方法耗时较高,霍夫森林方法通过构建随机森林寻找目标,相比传统的分类方法更偏向判别式,可在训练阶段减少耗时,未来也会考虑在本文方法中引入该方法,相比其他几种方法,本文方法取得了更好的耗时。文献[7]方法通常需要提前限定面部表情才能取得较好的检测结果,故检测率、分类率低于上述所有比较方法。在提高检测率和分类的情况下,仍然能保持较低的耗时,表明了本文方法的优越性。
5 结束语
本文提出了一种基于高斯混合模型的视频情感场景检测方法,通过引入无监督的方式,构建一个面部表情模型,在没有训练数据和面部表情预定义的情况下可以检测出不同的情感场景。此外,本文方法由于简单的面部特征和低计算量的现场检测算法显得非常有效。实验结果表明,相比其他几种较新的检测方法,本文方法取得了更高的检测率和分类率,同时仅需很少的总耗时。
未来会将本文方法与其他新颖技术相结合,并使用更多的生活记录视频数据集、更多的受验者、更广泛的面部表情评估本文方法。此外,由于情感场景检测精度不够,计划通过改善面部特征值的质量,提高面部表情识别模型的性能以提高检测精度。
[1]LEEMW,KHANAM,KIMTS.Asingletri-axialaccelerometer-basedreal-timepersonallifelogsystemcapableofhumanactivityrecognitionandexerciseinformationgeneration[J].PersonalandUbiquitousComputing, 2011, 15(8): 887-898.
[2]刘帅师, 田彦涛, 万川.基于Gabor多方向特征融合与分块直方图的人脸表情识别方法[J].自动化学报, 2012, 37(12): 1455-1463.
[3]李春芝, 陈晓华.白化散度差矩阵的独立元分析应用于表情识别[J].计算机应用研究, 2011, 28(11): 4361-4363.
[4]胡敏, 朱弘, 王晓华, 等.基于梯度Gabor直方图特征的表情识别方法[J].计算机辅助设计与图形学学报,2013, 25(12): 1856-1861.
[5]TIANY,KANADET,COHNJF.Facialexpressionrecognition[M].London:Springer, 2011.
[6]VALSTARMF,MEHUM,JIANGB,etal.Meta-analysisofthefirstfacialexpressionrecognitionchallenge[J].IEEETrans.Systems,Man.,andCybernetics,PartB:Cybernetics,2012, 42(4): 966-979.
[7]NOMIYAH,MORIKUNIA,HOCHINT.Emotionalvideoscenedetectionfromlifelogvideosusingfacialfeatureselection[C]//Proc.4thInternationalConferenceonAppliedHumanFactorsandErgonomics.[S.l.]:IEEEPress,2012: 8500-8509.
[8]袁少锋, 王士同.基于多元混合高斯分布的多分类人脸识别方法[J].计算机应用研究, 2013, 30(9): 2868-2871.[9]梁荣华, 叶钱炜, 古辉, 等.特征点自动标定的颅面复原及其评估方法[J].计算机辅助设计与图形学学报, 2013, 25(3): 322-330.
[10]TANPY,IBRAHIMH,BHARGAVY,etal.Implementationofbandpassfilterforhomomorphicfilteringtechnique[J].InternationalJournalofComputerScience, 2013, 1(5):1-6.
[11]DELFM,BOSZORMENYIL.State-of-the-artandfuturechallengesinvideoscenedetection:asurvey[J].MultimediaSystems, 2013, 19(5): 427-454.[12]胡步发, 黄银成, 陈炳兴.基于层次分析法语义知识的人脸表情识别新方法[J].中国图象图形学报, 2011, 16(3): 420-426.[13]周晓彦, 郑文明, 辛明海.基于稀疏表示的KCCA方法及在表情识别中的应用[J].模式识别与人工智能, 2013, 26(7): 660-666.
[14]赵玥, 苏剑波.一种用于人脸识别的矢量三角形局部特征模式[J].电子学报, 2013, 40(11): 2309-2314.
[15]FANELLIG,YAOA,NOELPL,etal.Houghforest-basedfacialexpressionrecognitionfromvideosequences[M].Heidelberg:SpringerBerlin, 2012.
[16]KELLYP,DOHERTYA,BERRYE,etal.Canweusedigitallife-logimagestoinvestigateactiveandsedentarytravelbehaviour?resultsfromapilotstudy[J].InternationalJournalofBehavioralNutritionandPhysicalActivity, 2011, 8(1): 44-57.
[17]FANGT,ZHAOX,OCEGUEDAO,etal.3D/4Dfacialexpressionanalysis:anadvancedannotatedfacemodelapproach[J].ImageandVisionComputing, 2012, 30(10): 738-749.
齐兴斌(1976— ),硕士,讲师,主研视频检索、图像处理;
赵 丽(1980— ),女,硕士,讲师,主研视频检索、中文信息处理,本文通信作者;
李雪梅(1962— ),女,教授,主研多媒体、视频处理等;
田 涛(1980— ),硕士,工程师,主研视频检索、机器学习等。
责任编辑:闫雯雯
Unsupervised ESD Method Based on GMM Clustering in Video Retrieval
QI Xingbin1, ZHAO Li2, LI Xuemei1, TIAN Tao3
(1.SchoolofComputer,ShanxiUniversity,Taiyuan030013,China; 2.SchoolofComputerScienceandTechnology,BeijingUniversityofAeronauticsandAstronautics,Beijing100083,China; 3.Collaborative&InnovationCenterforEducationInformationTechnology,BeijingNormalUniversity,Beijing100875,China)
For the purpose of an efficient retrieval of impressive scenes from videos, an emotional scene detection method based on Gaussian mixture model is proposed.Firstly, 42 feature points are selected from facial, and 10 features are defined.Then, Gaussian mixture model is used to divide video into multiple clusters.Finally, emotion scene is divided into single cluster by using facial expression classification results of each frame, and scene integrating and deleting is used to finish detecting.Experimental results on life record video and MMI face expression database show that the detecting and classification rate of proposed method can achieve 98% and 95% respectively.It takes only 0.138 seconds in detecting emotion scene video with five minutes.Proposed method has better performance than several advanced detecting methods.
video retrieval; emotional scene detection; facial expression recognition; unsupervised; Gaussian mixture model
国家自然科学基金项目(61202163);山西省自然科学基金项目(2013011017-2);山西省科技攻关项目(20130313015-1)
TP391
A
10.16280/j.videoe.2015.05.032
2014-07-05
【本文献信息】齐兴斌,赵丽,李雪梅,等.视频检索中基于GMM聚类的无监督情感场景检测[J].电视技术,2015,39(5).
猜你喜欢
数学物理学报(2021年5期)2021-11-19 07:01:12
少儿美术·书法版(2021年9期)2021-10-20 06:35:00
烟台大学学报(自然科学与工程版)(2021年1期)2021-03-19 08:38:40
动漫星空(2018年9期)2018-10-26 01:17:14
电子测试(2017年15期)2017-12-18 07:19:27
智能系统学报(2015年4期)2015-12-27 09:38:39
东北电力大学学报(2015年1期)2015-11-13 05:20:25
电子设计工程(2015年6期)2015-02-27 12:04:53
发明与创新(2015年33期)2015-02-27 10:40:09
奇闻怪事(2014年5期)2014-05-13 21:43:01
