
基于云计算的大数据分析
2015-06-12 06:15:50王树文
吉林广播电视大学学报 2015年7期
王树文
(吉林省计算中心(吉林省计算机技术研究所),吉林 长春 130022)
随着科技的进步,海量的数据分析成为目前市场面临的重要问题,这些数据一般都来源于互联网。对于大数据的分析成为当前不可忽视的重要内容。本文对大数据及云计算的概念、两者之前的关系以及大数据分析面临的挑战进行分析,希望通过本文的研究,可以为促进企业的生产经营提供一定的帮助。
一、云计算与大数据
1、云计算及其相关技术
云计算是以因特网为基础的,它可以如同电网提供电力资源,用户可以再云计算基础上根据自身需求对计算资源进行访问。云的构成主要包括三种形式分别是公共云、私有云以及混合云。公共云主要是被一些大型组织使用,一般为销售的云服务提供供应;而私有云主要是由公司内部自身来管理,主要是由企业内部创建并进行控制的;而混合云主要是指公共云和私有云的结合,也就可以提供公共和私有服务。与公共云相比,目前私有云和混合云使用的较为广泛。
云计算是一种新型超级计算,云计算的技术实际上是实现计算、服务、存储、应用软件等硬件资源的虚拟化。云计算在数据存储、数据管理以及虚拟化等方面具有独特的技术。云计算技术的基础主要是实现安全可靠的信息存储以及读写,云计算技术可以实现数据的备份以此来保证数据的安全可靠。云计算主要是对数据进行分布式的处理以及分析来实现数据管理技术。对于云计算来说,虚拟化技术是云计算的关键技术,虚拟化技术可以使计算机的资源得到最大的利用。
2、大数据的概念
大数据实际上是一种数据集,它主要是由数量巨大、结构复杂、类型众多的数据构成的。大数据与普通的数据不同,它远远超过了典型结构化的数据范围,大数据一般来源于半结构化的文化、图像、视频以及记录数据。由于大数据的复杂性必须依靠云计算技术和方法进行管理和分析。大数据具有以下几点特点:
(1)数据的规模大:对于大数据而言,很难对其规模做出规定;(2)数据结构复杂:结构的复杂可以为其提供更加丰富的信息;(3)数据间的关联度较高,如果数据间的关联度低,无论数据的信息量有多大,结构有多复杂,都不可以称之为大数据。
3、云计算与大数据之间的关系
大数据和云计算在技术上有着密不可分的关系,只不过云计算针对的是计算,而大数据则是指计算的对象。对大数据进行分析不能利用单台计算机进行分析和处理,必须依靠分布式的计算机架构,利用云计算的数据存储、处理以及虚拟化技术对数据进行分析。云计算技术为大数据的分析提供了机会。大数据的分析需要具有分析大数据的能力,而云计算技术恰好有这项能力,而大数据也同样为云计算提供了应用的平台。
二、大数据时代面临的挑战
1、数据的收集与存储
大数据最主要的一个特点就是规模巨大,数据增长的速度越来越快,云计算为此提供了有效的解决方案,主要是将该数据传送到后台进行处理。而这一过程中最主要的问题是将这些数据利用因特网上传到云,这需要进一步的研发。
对于大数据进行存储时要对存储的类型进行选择,如果利用云方法,那么传统的数据库不适合云的可量测性。目前存在的系统为了提供可量测性,而牺牲了关系模型等许多功能,因此对于大数据的存储迫切需要研发可测量性的数据库模型。
2、数据的分析
对数据进行处理的主要目的是将有价格的数据从海量的数据中提取出来,从而方便用户的需求。面对大数据时代的来临需要对不断增长的数据进行收集,这就需要不断的研发可以处理大数据的系统,这也是大数据发展的重要目标。
3、数据的安全性
随着大数据时代的来临,数据的重要性也逐渐显现,如何保护这些数据的安全,成为新信息时代的主要问题。第一要在限制成本的情况下确保系统各项性能;第二要确保在各项数据分析渠道中对数据采取保护;第三要对系统中可能存在的攻击类型进行分析和研究,这样才能对数据进行更好的保护,从而保证数据的安全性。
三、基于云计算的大数据分析
1、数据传输
利用云架构对数据进行分析时最主要的是必须确保数据在云端。为了确保数据可以上传到云端,一般会利用广域网优化组合的技术方法,这些方法主要包括删除重复数据、优化缓存、压缩等。其中压缩技术可以方便广域网的优化,其效果主要取决于被压缩的数据类型。另外减少传输数据的方法就是对重复数据进行删除,其核心技术就是冗余消除。
2、数据的存储和管理
大数据的出现彻底改变了数据存储的系统架构,促进这种改变主要包括两个因素,分别是可量测性和处理大数据的需要。分布式系统主要是对数据进行存储,在这个系统中数据被存储为64M的文件布局。在系统中,GFS顶端主要使用MAP/Reduce对节点处的数据进行处理,这对于数据的处理提供了有效的推动作用。其中对于数据的存储和管理应用最普遍的是Hadoop,而对于Hadoop最主要的核心部件是Map/Rdeuce工具以及Hadoop分布式文件系统。
3、云计算架构
Hadoop是一种支持可靠地可升级的分布式计算,是一种云计算架构。它主要是以GFS以及Map/Reduce为技术基础。Hadoop的三个主要组成部分是分布式文件系统、Map/Reduce工具以及其他模块,其中最主要的核心部件就是Map/Reduce工具和Hadoop分布式文件系统,图1是Hadoop的体系结构分布图。数据库、查询以及协调服务是Hadoop模块发展较大的几个模块。
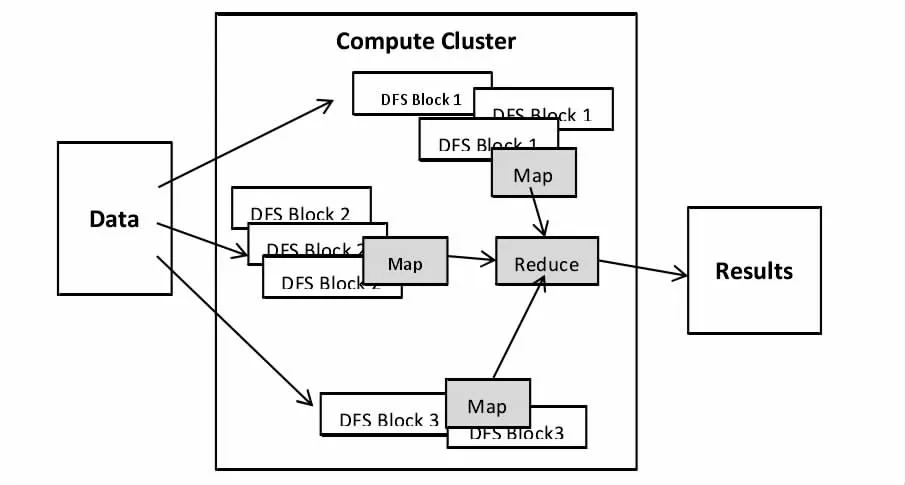
图1 Hadoop的体系结构
数据库系统:ApacheHive是一个数据库系统,它的主要功能是对存储的数据进行查询汇总和分析。Hive解决了Map/Reduce功能不易于保护和重复利用的缺点,Hive提供了完成数据操作的方法,这种操作方法主要是利用Hive自身的查询语言,因此不必再对Map/Reduce功能进行编写。Hive将数据分成表、分区以及块,其中一个表包括行和列。块内的分区被散列分隔开来,并由驱动器完成包括从编译到执行的全部工作,图2为Hive系统架构图。

图2 Hive系统架构
数据分析平台:Apachepig是大型的数据分析平台,它是以Hadoop中Map/Reduce程序的高层语言为基础的。数据分析平台中的Pig主要是用来降低编写Map/Reduce的复杂性的,同时可以将特殊的查询方法考虑进去。
非关系类型数据库:HBase是分布式的,主要是以列为主,而HBase主要是在Hadoop分布式文件系统上运行的。HBase提供的是分布式数据存储,由于HBase建立在HDFS上,所以它是具有容错功能的。
协调服务:ZooKeeper主要提供的是协调服务,同时可以利用Hadoop实现同步。ZooKepper对信息进行保存,这些信息主要包括数据和空间。同时ZooKeeper可以根据需要来恢复客户端的应用程序,其优点在于与Hadoop保持同步。
另外列数据库主要是指Cassandra系统,主要有Facebook发展而来。在Cassandra中最小的数据部分是列,一行包括多个列,列族包括行,键间距包含列族。其中列族存储在单独的文件中。数据在里面并不是均匀分布的,节点可以通过调整来缓解处于压力下的节点。
四、总结
数据的不断增加和快速增加成为大数据对于存储技术以及处理的首要挑战。云计算技术成为了主要的计算模式,为数据的研究和应用提供了技术支持。目前Hadoop已经成为处理大数据的关键方案,然而面临持续增加的数据量,以及用户要求的不断提高,我们需要对云计算处理技术不断的进行研究和开发,从而适应大数据时代的要求。本文通过对大数据以及云计算概念以及两者之间关系的分析,提出了大数据时代面临的挑战,同时对云计算技术对大数据处理进行了分析,希望可以为云计算技术的不断提升提供参考性价值。
[1]张蕾.基于云计算的大数据处理技术[J].信息系统工程,2014.
[2]孟小峰,慈祥.大数据管理:概念、技术与挑战[J].计算机研究与发展,2013.
[3]冯海超.透视美国大数据爆发全景[J].互联网周刊,2013.
猜你喜欢
计算技术与自动化(2022年4期)2022-12-27 13:19:06
成都信息工程大学学报(2022年4期)2022-11-18 07:31:10
汽车工程(2021年12期)2021-03-08 02:34:30
岩土工程技术(2019年6期)2020-01-06 03:19:26
电子制作(2019年10期)2019-06-17 11:45:10
电子制作(2018年14期)2018-08-21 01:38:20
电子测试(2017年11期)2017-12-15 08:57:56
电信科学(2017年6期)2017-07-01 15:45:17
物探化探计算技术(2016年6期)2017-01-12 03:24:41
湖南城市学院学报(自然科学版)(2016年4期)2016-02-27 14:02:42
