
基于分类号的开放获取期刊评审专家遴选方法研究
2015-06-11 06:40魏健波
新世纪图书馆 2015年11期
魏健波 周 杰
同行评审是保证期刊质量最重要的方法,而评审专家遴选又是同行评审最重要的环节,评审专家选择的合适可以事半功倍,能够为稿件提出许多宝贵的意见。如果评审专家选择不当,可能造成“外行评内行”的现象,最终的评审效果也就可想而知了。传统的评审专家遴选方法主要是编辑根据自己的主观判断选择自己比较熟悉的专家进行评审,这种方法存在很多问题。另外,传统评审专家遴选方法主要是针对传统科技期刊,对于开放获取期刊的专家遴选方法并不适合。所以本文结合开放获取期刊的特点,希望能找到一种更合适的评审专家遴选方法。
1 评审专家遴选存在的问题
开放获取期刊在评审专家遴选上完全继承了传统科技期刊的方法,即期刊编委按照自己的意愿选择评审专家,这就存在着许多问题。首先,编辑的交际范围有限,他只能将稿件交给自己熟悉的几个专家评审;其次,一个学科包括许多研究方向,编辑可能了解评审专家的学科,但不一定真正了解评审专家的研究方向,这可能导致稿件研究方向和专家研究方向不一致;除此之外专家的研究方向并不是一成不变的,在不同的时间段专家的研究方向也有所变化,传统遴选评审专家的方法不能反映这种变化。
开放获取期刊相对于传统期刊有一些新的特点,开放获取期刊由于可以免费获取,没有订阅费,经费来源主要是论文处理费和社会团体的赞助,经费相对于传统期刊是比较少的,所以开放获取期刊要尽量减少成本,而减少成本的一个非常重要的手段就是用计算机来代替人工,如果可以用计算机进行自动专家遴选,那就不需要聘请那么多编辑,成本也就大幅下降。另外,开放获取期刊出版的论文数量一般还要多于传统期刊,如果采用传统遴选专家的方法则需要更多的编辑,成本还要高于传统期刊。
对目前开放获取期刊评审专家遴选进行总结可以得出以下两点结论:第一,传统评审专家遴选方法本身存在一些问题,主要表现为可选专家数量有限、专家选择不准确、不能及时反映专家研究方向的变化;第二,传统评审专家遴选方法与开放获取期刊节约成本的理念相违背,成本比较高。所以对开放获取期刊而言有必要对传统专家遴选方法进行改变,利用计算机进行自动评审专家遴选可能是一个不错的方法。
2 基于分类号的评审专家遴选系统
2.1 基本构想
针对传统评审专家遴选所存在的一些问题,如果可以在一个学科或一个领域内建立一个专家遴选系统,将有关专家的一些信息放到系统中,通过计算机自动匹配推荐几个合适的评审专家,然后编辑再对推荐的专家进行甄别,从而选择合适的评审专家,这样就可以解决传统评审专家遴选时所存在的一些问题。对于评审专家遴选的问题我国也曾经做出过努力,例如1993年《中国科学技术论文评审专家名典》、2000年《西北地区高校审稿专家名录(自然科学类)》、2001年《上海市高校科技论文评审专家名录》等。这些评审专家名录虽然起到了一定作用,但还存在两个严重的缺陷:第一,因没有实现计算机的自动匹配需要人工查找,人工查找不但成本高而且很容易受主观因素的影响;第二,更新慢,这些名录从编审到出版需要很长的时间,且出版后很长时间不会更新。通过建立评审专家系统,借助计算机技术完全可以实现自动匹配,而且更新及时,可以解决评审专家名录所存在的问题。
2.2 实现方法
评审专家的遴选需要考虑两个方面:一方面是评审专家的学术水平,另一方面是评审专家研究方向与稿件研究方向的匹配度。稿件审理过程中评审专家的水平很重要,高水平的专家才能提出准确的审稿意见,所以评审专家系统建设的第一步是收集相关领域专家的信息。目前,评判学者学术水平的指标有很多,例如H指数、发文数、引用数等,通过这些指标找出合适的评审专家。接下来是如何判断评审专家研究方向与稿件研究方向的匹配度,这是评审专家系统建设的重点。
那么如何评判评审专家研究方向与稿件研究方向的匹配度呢?专家的研究方向可以从他发表的论文反映出来,引用次数较多的论文表明该学者在这个研究方向有较为突出的贡献,而最新发表的论文代表着该学者最新的研究方向,那么可以将待审稿件与该学者引用次数最多的几篇论文和最新发表的几篇论文进行相似性比较,如果相似性较高,那么我们可以认为该学者的研究方向和稿件研究方向一致。那么如何比较论文的相似性呢?最容易想到的是利用类似论文查重的方法进行比较,但这种方法非常复杂,而且由于汉语语法的复杂性,进行分词比较时很容易产生歧义,比较的准确性并不高。我们都知道每篇论文都会给出一个分类号用于表示论文的研究主题和方向,那么可不可以利用分类号进行论文相似性的比较呢?如果可以的话应该怎样进行比较?下面主要讨论利用分类号进行论文相似性比较的方法。
基本思想是从万方或中国知网等数据库中选择某位学者引用次数较多的若干篇论文和最近发表的若干篇论文,将这些论文与待审稿件两两进行相似性比较,得出相似性指数,然后求出平均相似性指数,将平均相似性指数作为该学者研究方向与稿件研究方向匹配度的指标。在对两篇论文进行相似性比较时首先将两个分类号进行拆分,例如在比较G 254.2与G 253的相似程度时,需要将前者拆分为G、2、5、4和 2五部分,后者拆分为 G、2、5和 3四部分,然后从前往后依次比较两者相同部分的个数,上面的例子中有3个相同的部分,最后将两者相同的部分乘以2再除以两者拆分后的部分总和,在上面的例子中为3*2/(5+4)=2/3,即66.7%,那么我们认为G 254.2与G 253的相似程度为66.7%。这样我们就可以定量地比较评审专家研究方向和待审稿件研究方向的相似程度。至于这种方法的可行性如何下面将进行验证。
2.3 可行性验证
这种方法对分类号准确性的要求很高,但目前我国科技论文的分类号是很不规范的,随意性非常大,所以在进行相似性计算前一定要对分类号进行规范,有些论文的主题包括多个概念,这时可以用多个分类号来表示,分别将这几个分类号与待审稿件分类号进行相似性比较并取其中较大者。在可行性验证时,为了简单每位学者仅选择10篇论文进行比较,其中5篇引用次数最高的论文和5篇最新发表的论文,这10篇论文必须是该学者为第一作者。这里选取图书馆学领域三位专家进行可行性验证,选择的三位专家分别为肖希明、陈传夫和张晓林,待审的两篇文章分别是《数字资源整合研究》(分类号为G 250.7,见相似性1)和《战略性新兴产业信息资源服务模式与竞争力分析》(分类号为G 203,见相似性2),相似性比较结果如表1、表2和表3所示。
如表1、表2和表3所示,对于论文《数字资源整合研究》,即各表中相似性1所示,肖希明、陈传夫和张晓林三位专家的平均相似性分别为55.8%、64.3%和74.9%,相似性大于80%的数量分别为0、3和4个,从这两个方面可以看出三位专家研究方向与论文《数字资源整合研究》的研究方向相似性为张晓林>陈传夫>肖希明,从理论上讲中国科学院国家科学图书馆的张晓林更适合作为这篇论文的评审专家,其次是武汉大学的陈传夫,而武汉大学的肖希明不太适合作为这篇论文的评审专家。对于论文《战略性新兴产业信息资源服务模式与竞争力分析》,即各表中相似性2所示,肖希明、陈传夫和张晓林三位专家的平均相似性分别为68.3%、71.9%和65.6%,相似性大于80%的数量分别为4、4和3个,所以三位专家都对信息资源建设方面有所研究,但相比而言肖希明和陈传夫两位专家对这方面的研究更多,而张晓林在这方面的研究相对而言要少一些,结合上述两个方面,武汉大学的肖希明和陈传夫作为这篇论文的评审专家更好一些。
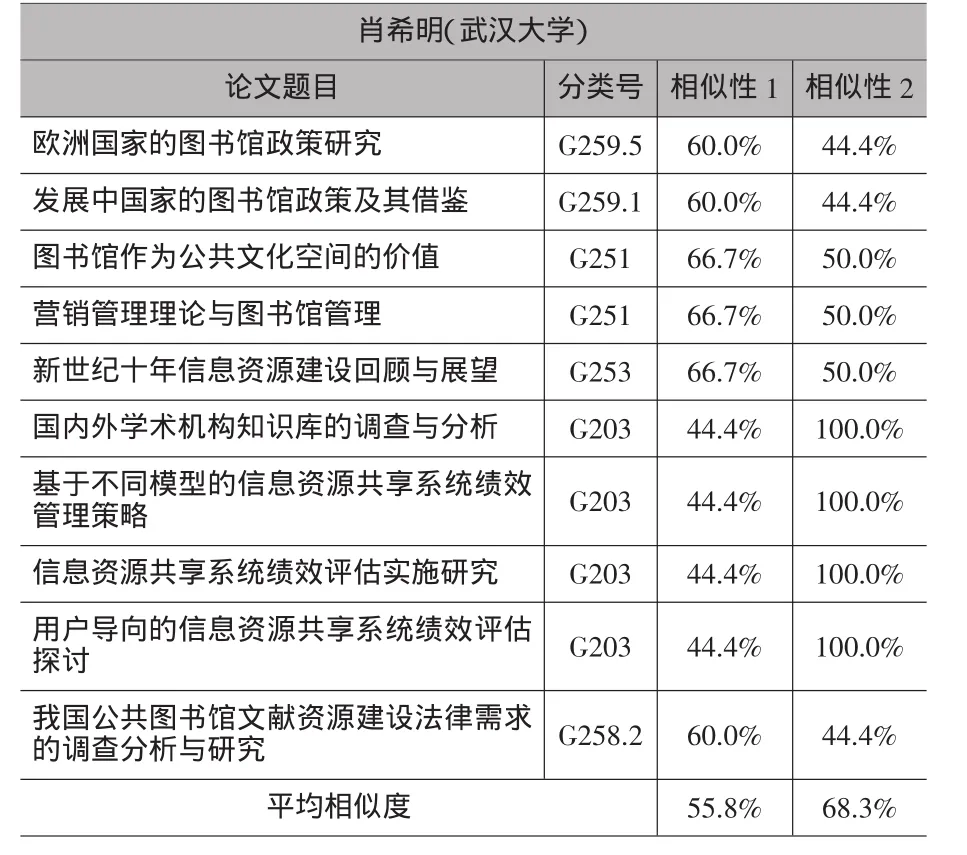
表1 论文相似性比较一
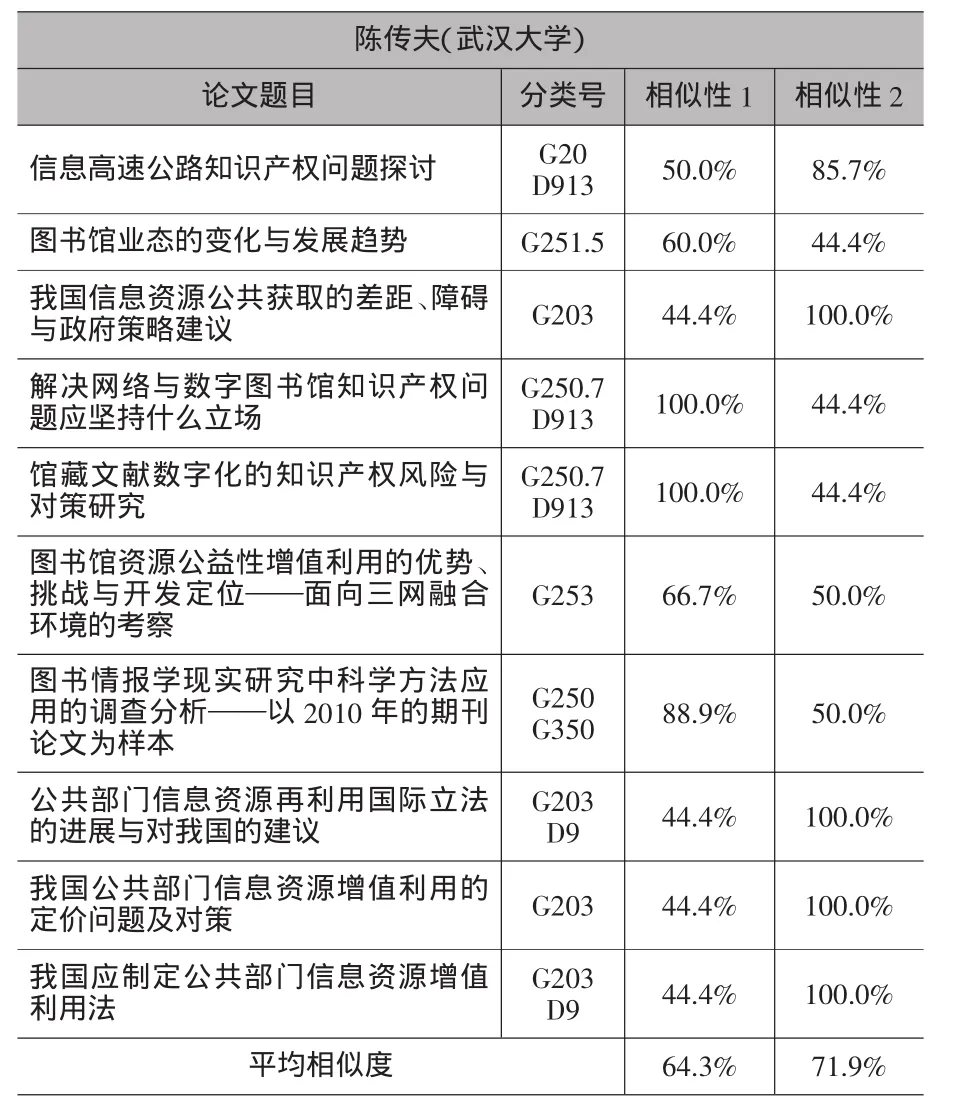
表2 论文相似性比较二
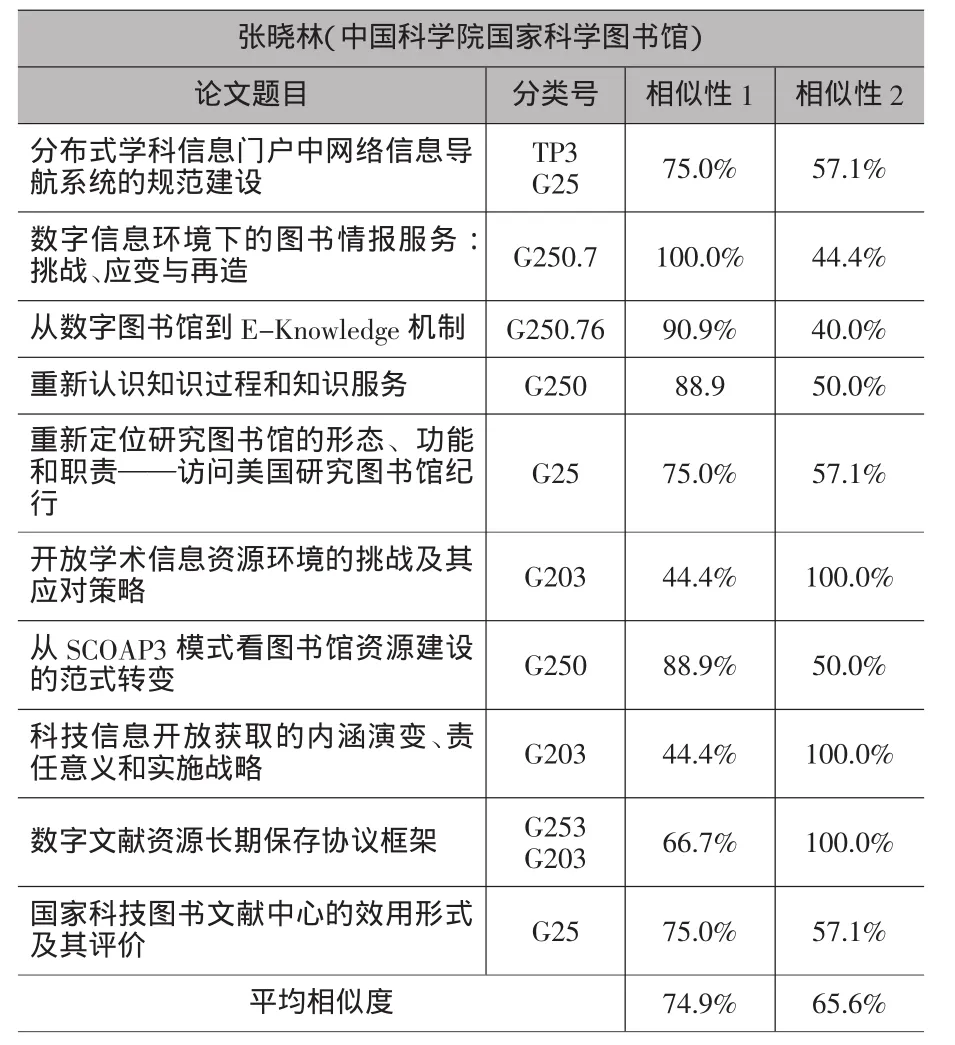
表3 论文相似性比较三
上面以两篇论文为例,通过分类号计算专家研究方向和稿件研究方向的相似程度,从而找到合适的评审专家,那么这种方法是否可行,与实际情况是否相符呢?这就需要比较上述三位专家的实际研究方向与计算的结果是否相符,通过查阅相关资料得知三位专家的研究方向如下:肖希明主要研究领域为信息资源建设、图书馆学基础理论、图书馆管理等[2];陈传夫主要从事信息资源管理、图书馆发展理论和知识产权研究[3];张晓林主要研究领域包括数字图书馆技术与系统、数字对象与元数据技术、知识组织与知识构建技术、知识发现与情报分析技术、开放集成系统技术、数字资源长期保存技术等[4]。可以看出肖希明和陈传夫都从事信息资源建设研究,虽然他们都从事图书馆理论方面的研究,但肖希明从事图书馆学基础理论,陈传夫从事图书馆发展理论,而张晓林主要从事数字图书馆、图书馆自动化和网络化方面的研究。
第一篇论文《数字资源整合研究》主要是进行数字图书馆方面的研究,从上述三位专家研究方向的介绍中可以看出张晓林是最适合的评审专家,他主要从事数字图书馆、图书馆自动化和网络化方面的研究;另外两位专家中陈传夫从事图书馆发展理论研究,研究图书馆未来的发展方向,而数字图书馆是未来图书馆非常重要的发展方向,显然在他的研究范围之内;肖希明从事图书馆学基础理论研究,与前面两位专家相比他的研究更加偏向于传统图书馆,所以他不太适合评审这篇文章。第二篇论文《战略性新兴产业信息资源服务模式与竞争力分析》主要研究信息资源建设方面,很显然肖希明和陈传夫都非常适合作为这篇论文的评审专家,因为他们都进行信息资源建设方面的研究,相比而言张晓林在这方面的研究较少一些。可见实际情况与通过分类号计算出来的结果基本一致,所以通过分类号来计算专家研究方向和稿件研究方向的相似程度,从而找到合适的评审专家是可行的一种方法。
3 结语
开放获取期刊与传统期刊相比发表的论文更多、经费更少,所以开放获取期刊评审专家遴选必须要节约成本,传统评审专家遴选方法并不适合开放获取期刊。在计算机网络技术日益发达的今天,我们完全可以建立评审专家遴选系统,并通过计算机数据分析进行客观、公正地遴选评审专家。但这种方法也不是完美的,还有许多局限和不足,主要体现在以下几个方面。
(1)评审专家遴选系统的建立不是单个期刊可以完成的,需要某个领域的众多期刊合作完成,而且还需要收集专家的相关信息,前期工作量非常大。
(2)这种方法对分类号的要求很高,而目前我国学术论文中作者给出的分类号非常不规范,所以要对每篇论文的分类号重新规范化,这个工作量比较大,而且分类号是人工给予,它也受到人的主观性影响。
(3)计算结果区分度不够,可以看到计算结果中很多相似度相同,但论文之间的两两相似度不可能完全相同,这种计算方法并不能反映这种较小的差别。
虽然目前评审专家遴选系统的设想还有许多缺陷,但系统建成之后将使许多期刊长期受益,节约大量的人力物力,而且还可以扩大评审专家遴选范围,避免遴选专家时受编委主观倾向的影响,这将为期刊质量的提高产生重要的作用,至于存在的局限和不足还需要有关学者提出宝贵的意见和建议。
[1] 方卿.中国学术期刊同行评审的实践与研究[J].图书情报知识,2007(6):89-92.
[2] 武汉大学信息管理学院.肖希明简介[EB/OL].[2015-04-22].http://sim.whu.edu.cn/index.php/index-viewaid-221.html.
[3] 武汉大学信息管理学院.陈传夫简介[EB/OL].[2015-04-22].http://sim.whu.edu.cn/index.php/index-viewaid-210.html.
[4]中国科学院国家科学图书馆.张晓林简介[EB/OL].[2015-04-22].http://www.las.cas.cn/jypx/yjsjy/zs/bszs/201106/t20110621_3291388.html.
猜你喜欢
地理教育(2018年6期)2018-07-12
雪莲(2017年2期)2017-05-12
课程教育研究·新教师教学(2016年1期)2017-04-10
环球市场信息导报(2017年1期)2017-04-08
地理教育(2016年9期)2016-05-14
地理教育(2016年1期)2016-01-27
数理化学习·高一二版(2009年2期)2009-03-30
中国校外教育(上旬)(2006年5期)2006-05-25
