
基于关键词协同投票过滤的短文本特征提取算法研究
2015-06-07 11:09周丽杰于伟海郭成
泰山学院学报 2015年6期
周丽杰,于伟海,郭成
(1.烟台职业学院电教中心,山东烟台264670; 2.烟台市普通话培训测试中心,山东烟台264003;3.大连理工大学软件学院,辽宁大连116620)
基于关键词协同投票过滤的短文本特征提取算法研究
周丽杰1,于伟海2,郭成3
(1.烟台职业学院电教中心,山东烟台264670; 2.烟台市普通话培训测试中心,山东烟台264003;3.大连理工大学软件学院,辽宁大连116620)
特征提取算法的目的是为了放大特征项和非特征项之间的权值差异性。目前文本特征提取算法通常都是面向通用文本,文本因篇幅差异在采用通用特征提取算法进行特征提取时性能也各有差异.以关键词词频特性为基础,构建关键词间协同过滤投票矩阵,投票矩阵中特征值作为特征项之间的投票数值,以投票权值和反文档频率共同来表征特征项权值,以此来满足短文本内容简短而特征提取准确率较高的要求.以新浪微博数据为测试数据集,实验结果表明,本文算法能够较为明显地差异化特征项和非特征项之间的权值.
共现频率;投票矩阵;协同过滤;特征提取;短文本
短文本因内容简短,在对短文本进行特征提取时要更加注重特征提取算法的准确率,否则稀疏的关键词将严重影响文本主题的表征[1].目前,短文本的特征提取已经在自然语言处理、问题系统、搜索引擎等多个领域崭露头角,对于时下流行的微博话题发现具有非常重要的现实意义[2-3].
经典的特征提取算法有基于关键词词频方法(TF)、基于文档倒排频率方法(TF-IDF)、基于卡方统计方法(CHI)和基于信息增益的方法(IG)等.上述算法在文本特征提取领域都是非常成熟的算法,然而在处理时下流行的微博短文本时效果不佳[4].针对文本的结构特征,有研究者采用最长公共子序列(LCS)的方法试图从结构角度来对文本块做整体划分以此来进行特征提取,这种方式比较适用于长文本[5];针对中英文在表达上的差异性,结合中文微博和英文Twitter的差异性,研究者们试图从语义的角度来出发,通过HowNet和WordNet词典计算特征项语义权值来进行特征提取,因词典本身容量有限难以适用适应微博中不断出现新词的场景[6];在对文本结构化分析的基础上,有学者提出发现文本中相同或相近语法结构来进行特征项筛选,诸如提取文本中名词-动词组合、动词-副词组合[7],这种方式同样比较适用于长文本,短文本本身篇幅非常有限,其自身包含的模式串也非常有限.
本文在关键词词频信息的基础上,以关键词在文本中出现频率为依据,构造短文本中关键词间共现频率矩阵,共现频率矩阵中元素的权值表示为该特征项在短文本中出现次数.某元素的权值通过其它特征项对该元素进行投票所得,采用迭代进化的方式,当元素的权值进行一定次数的迭代趋于稳定时,则该趋于稳定的权值与反文档频率组合作为该特征项的最终权值.
1 投票模型
投票模型依赖图结构,图以结点和边构成,各个节点都有出度和入度之分,投票模型假设各个节点的权值受到出度和入度的影响.每一条指向该节点的边都认为是其它节点对该节点的投票(即节点入度),从该节点出发的边则认为是该节点对其它节点的投票(即节点出度),根据出度和入度的关联性对节点的权值进行迭代计算[8-9].投票模型的具体流程可表示如表1所示.

表1 投票模型算法流程
根据表1所示投票模型算法流程图,对于图中某个节点v,则该节点的权值可以量化表示为公式1所示.
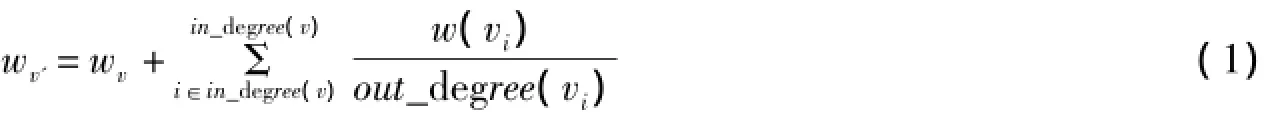
在公式1中,wv'和wv分别表示本次迭代和上次迭代时节点v的权值,in_degree(v)和out_degree (vi)分别表示节点v和节点vi的入度和出度.
2 改进的特征提取算法
将文本转化为图的表示方式,图中各个节点对应于文本中各个关键词,图中节点之间的边关系对于文本中关键词之间共现频率,如此,可以通过关键词间投票关系实现特征项的提取.
2.1 共现投票矩阵构建
通过文本分词和停用词去除,将文本切分为以关键词组合来表征的集合,以关键词作为基础进行投票矩阵构建,构建的二维矩阵表示如表2所示.

表2 投票矩阵
在表2中,wij表示关键词ti和关键词tj之间的共现频率,共现频率表示关键词ti和关键词tj共同出现的次数.
在表2中,可以看出文本被形式化的表征为图的模式,wij可以对应于关键词ti和关键词tj边上的权值,关键词则对应于图中各个节点.
2.2 特征项权值计算
通过将文本中关键词转为二维矩阵的表现方式,借助于投票模型,从而实现关键词间投票权值计算.
关键词存在于文本当中,关键词间具有一定的关联性,关键词之间的关联性通过相互之间的共现关系加以体现[10],共现关系构成投票关系,以投票关系来反映关键词在文本中重要程度.根据投票模型和表征文本的二维矩阵,关键词ti的投票权值可表示为公式2所示.

vwti'和vwti分别表示本次迭代和上次迭代时关键词ti的权值,wtitj和wtjti分别表示关键词ti和tj的共现频率以及关键词tj和关键词ti的共现频率.关键词的投票权值受到当前投票权值以及其它节点的投票共同影响.
关键词当前的投票权值通过其自身的权值和其它节点的投票加权获得.其它节点的投票加权表示为当前的共现频率与该节点的共现频率之和的比例决定.
2.3 特征项选择
通过特征项投票权值,可以反映出该关键词在文本中重要程度[11],同时文本特征选择的结果是该特征项能够较为明显地区分该文本和其它文本,在TF-IDF方法[12]的基础上,将关键词词频信息更改为特征项投票权值与反文档频率的乘积,通过此种方式,一方面提取出来的特征项反映了该特征项在文本中重要程度,另一方面,也能够达到区分文本的目的.则最终关键词t的权值可表示为公式3所示.

3 实验与分析
本文实验采用新浪微博测试数据集,数据集来源于数据堂科研共享平台,微博内容语料库由北京理工大学网络搜索挖掘与安全实验室张华平博士,通过公开采集与抽取从新浪微博、腾讯微博中获得.为了推进微博计算的研究,已通过自然语言处理与信息检索共享平台(www.nlpir.org)予以公开共享其中的23万条数据[13-14].
3.1 实验结果
将23万条数据随机分成9组,分别采用本文算法VA(vote algorithm)、文档频率算法(TF-IDF)、卡方统计算法(CHI)和信息增益算法(IG)[15]计算这9组数据中关键词的权值.
分别对9组数据中特征项权值较大者和权值较小者两两做差值,对所有的差值做平均化,如表3所示.

表39 组数据权值差值平均值
在表3中可以看出,本文算法VA在特征提取时,能够较为明显地差异化特征项中权值较大者和特征项中权值较小者,从而达到特征提取的目的,即通过权值差异分离出特征项,特征项之间的形式化表示如图1所示.
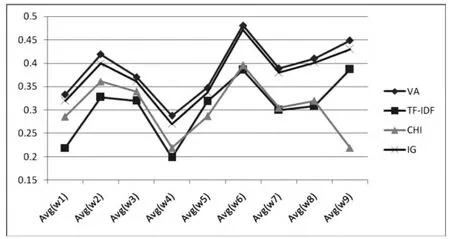
图1VA、TF-IDF、CHI和IG四种算法权值比较图
在图1中可以看出,本文算法VA和IG算法使得特征项的权值差异性较为明显,这也比较符合实际的情况,IG算法本身是比较好的特征提取算法.相比而言,TF-IDF算法和CHI算法的差异化并不明显,也表明TF-IDF算法和CHI算法在处理微博这种短文本时效果并不明显.从图中走势图上可以表明本文算法在微博短文本特征提取时效果较为明显.分别从9组数据中统计TopN(N=3)条特征项权值差异化最大的前N条数据,比较前N条记录的权值差异化平均值,如表4所示.
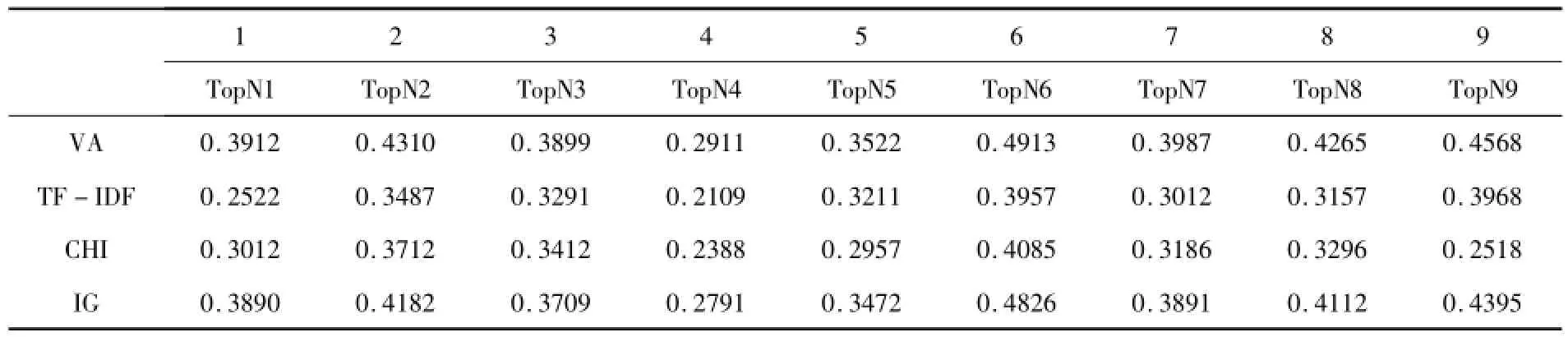
表4 TopN权值差异平均值
在表4中可以看出,本文算法VA使得9组中数组的权值较为明显,相对于其它三种,本文算法VA使得权值差异化也保持最大化,从数据中可以看出本文算法能够使得特征项权值差异化较明显,同时也说明本文算法不仅在稳定上较好,同时,在局部数据上效果同样很明显,当需要根据TopN来取特征记录时,本文算法是一个比较好的选择.本文算法的走势图如图2所示.
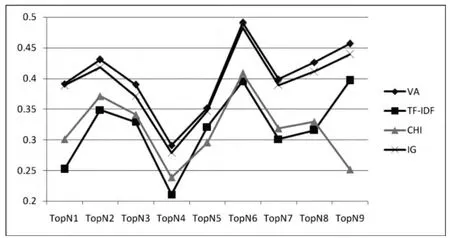
图2 四种算法在9组数据上TopN值
3.2 结果分析
从实验结果可以看出,本文算法在特征提取时能够较为明显的差异化特征项之间的权值特征,从而达到区分特征项的目的.
本文算法主要从微博短文本自身的特性出发,利用微博文本内容的结构特征,利用特征项之间的投票关系来判定特征项在文本中的重要程度,相比于IG算法在特征提取方面,本文算法不需要IG算法来进行特征类别扫描,能够较为明显地降低时间开销,同时又能使得特征选择的效果较好.
4 结论
本文以时下流行的微博短文本为研究出发点,分析并阐述文本特征提取的目的是为了差异化特征项和非特征项的权值,文本中关键词间共现频率为基础,构建关键词间共现频率矩阵,以图模型中投票为理论出发点,将关键词间关联性通过关键词间相互投票加以反映,关键词的投票权值用来表征该关键词在文本重要性,同时结合反文档频率来区分各个文档.改进的算法在新浪微博测试语料库上的结果可以表明本文算法能够较为明显地差异化特征项和非特征项,从而达到文本特征提取的目的.
[1]熊忠阳,蔺显强,张玉芳,牙漫.结合网页结构与文本特征的正文提取方法[J].计算机工程,2013(12):200-203.
[2]Jung Yi Jiang,Shian Chi Tsai,Shie Jue Lee.Multi-label text categorization based on fuzzy similarity and k nearest neighbors[J].Expert Systems with Applications,2012,39(3):2813-2821.
[3]何晓亮,宋威,梁久祯.基于资源分配网络和语义特征选取的文本分类[J].计算机工程与科学,2014(2):340-346.
[4]邵晓根,鞠训光,胡局新,马忠伟.基于改进权重的贝叶斯推理和TFIDF算法文本主题词提取研究[J].南京师大学报(自然科学版),2014(1):57-60.
[5]程传鹏,苏安婕.一种短文本特征词提取的方法[J].计算机应用与软件,2014(6):162-164.
[6]路永和,梁明辉.遗传算法在改进文本特征提取方法中的应用[J].现代图书情报技术,2014(4):48-57.
[7]李明江.结合类词频的文本特征选择方法的研究[J].计算机应用研究,2014(7):2024-2026.
[8]张凤琴,王磊,张水平,王鹏,程超.一种基于聚类加权的文本特征生成算法[J].计算机应用研究,2013(1):146-148.
[9]侯勇,郑雪峰.基于最大间隔超平面的增强特征提取算法[J].计算机应用,2013(4):998-1000.
[10]李建林.一种基于PCA的组合特征提取文本分类方法[J].计算机应用研究,2013(8):2398-2401.
[11]林少波,杨丹,徐玲.基于类别相关的新文本特征提取方法[J].计算机应用研究,2012(5):1680-1683.
[12]Yan hui Gu,Zheng lu Yang,Guan dong Xu.Exploration on efficient similar sentences extraction[J].World Wide Web,2013,23(1):1-32.
[13]陈炯,张永奎.一种基于词聚类的文本特征描述方法[J].计算机系统应用,2011(2):211-215.
[14]刘海峰,刘守生,张学仁.聚类模式下一种优化的K-means文本特征选择[J].计算机科学,2011(1):195-197.
[15]Aminul Islam,Diana Inkpen.Semantic text similarity using corpus-based word similarity and string similarity[J].ACM Transactions on Knowledge Discovery from Data,2008,2(2):1-25.
Research on Short Text Feature Extracting Algorithm Based on Keywords Collaboratively Voting Filter
ZHOU Li-jie1,YU Wei-hai2,GUO Cheng3
(1.Electronic Teaching Center,Yantai Vocational College,Yantai,264670; 2.Yantai Mandarin Training and Testing Center,Yantai,264003; 3.School of Software Technology,Dalian University of Technology,Dalian,116620,China)
Feature extraction algorithm is designed to amplify the weight difference between feature and non-feature characteristics.Currently,the text feature extraction algorithm is usually designed for general text,however,there exists performance difference while adopting common feature extracting algorithm because of length differences among texts.In this paper,we begin with the term frequency,constructing voting matrix of collaborative filter among terms,the characteristic value in voting matrix is set as the voting value between characteristics,merging the inverted document frequency with voting value to represent weight of characteristic in order to meet the requirement of the content of short text is less while precision rate of characteristic extracting is high.The experimental results on sina weibo datasets show our proposed algorithm can significantly amplify the weight between feature and non-feature characteristics.
common frequency;voting matrix;collaborative filter;feature extracting;short text
TP391
A
1672-2590(2015)06-0043-05
2015-09-28
国家自然科学基金资助项目(61401060;61272173);山东省高等学校科技计划基金资助项目(J12LN73)
周丽杰(1976-),女,山东龙口人,烟台职业学院电教中心实验师.
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01
电子制作(2019年15期)2019-08-27
时代英语·高二(2018年7期)2018-12-03
电子制作(2018年19期)2018-11-14
时代英语·高二(2018年3期)2018-06-06
计算机测量与控制(2018年3期)2018-03-27
自动化学报(2017年7期)2017-04-18
自动化学报(2017年11期)2017-04-04
噪声与振动控制(2015年4期)2015-01-01
