
基于书写规则的书法字笔画及笔顺提取*
2015-06-05 05:22刘佳岩章夏芬上海海事大学信息工程学院上海201306
网络安全与数据管理 2015年15期
刘佳岩,章夏芬(上海海事大学 信息工程学院,上海 201306)
基于书写规则的书法字笔画及笔顺提取*
刘佳岩,章夏芬
(上海海事大学 信息工程学院,上海 201306)
提出了一种针对篆书和隶书等多类别书法字图像笔画及笔顺信息的提取算法。算法通过使用书法字骨架图与轮廓图相结合的方式,使用针对交叉处轮廓点角度聚类及该点与交叉中心欧氏距离相结合的聚类准则,完成交叉处笔画的信息补全、处理,并根据书写规则提取书法字的笔顺信息。最后,针对楷体、隶书、篆书三类书法字图像做笔画以及笔顺信息的提取,实验结果表明本文所提出的方法对多类别书法字图像笔画提取取得了较好的效果。
书法字;笔画提取;书写规则;书法笔顺
0 引言
中华民族五千年文化中有大量书法作品,这些书法作品被扫描成页面图像,能够有利于书法作品的保护以及便于书法作品的流传、鉴赏,但是书法页面图像却无法表现汉字书写的过程,丢失了笔顺信息。
书法字笔画、笔顺信息除了有益于书法教学之外,在书法书写过程重现、书法风格自动识别等领域中也是最为重要的信息。
本文提出的方法利用书法单字骨架,结合轮廓图提取完整笔画,并依据书写规则,确定笔画书写顺序。
1 相关工作
1.1笔画提取
目前,有很多的方法来完成笔画提取的工作。在笔画提取过程中主要需要解决两个关键问题:(1)独立笔画的提取;(2)交叉笔画在交叉段的处理。
目前大多数的笔画提取方法是细化处理:将输入的汉字图片处理为骨架图。对整个汉字骨架进行跟踪,初步提取笔画。此时,无交叉笔画已完成提取,但分叉点连接着多个不完整的笔画段。此后通过一定的合并、拆分规则,最终获得准确笔画。这种处理方式能够将汉字的笔画方向信息完整地保留下来,同时因为整个骨架图为单像素宽度,降低了后续笔画提取的计算复杂度。这种方式也存在着较为明显的缺点:(1)失去了笔画的宽度信息;(2)在细化过程中,会引入一定的形变,为后续笔画的正确提取造成了一定的难度[1-3]。
另一部分笔画提取方法使用的是轮廓图或线邻接图(LAG)。提取轮廓特征点,计算各特征点的曲率,寻找出曲率最大的点,确定为笔画拐点。由于在笔画交叉处,必然存在拐点或角点,因此确定拐点或角点的位置能够进一步确定笔画的走向,完成交叉段不同笔画的分割、提取[1-3]。
[4]提出了基于Delaunay三角剖分的三角网格表征与点到边界方向距离PBOD曲线相结合的笔画提取方法。相较于传统的基于汉字细化和LGA等方法,该方法从汉字的基础特征着手,提取效果较好。
上述方法只是针对于某一单一风格的书法字笔画提取,或者印刷体汉字提取,没有针对多类别的书法字的笔画提取进行验证。
1.2笔顺信息提取
汉字是一种象形文字,其典型的书写规则:先左后右,先上后下。本文利用该规则,结合已有的笔画信息,对笔画进行排序,获得笔顺信息。
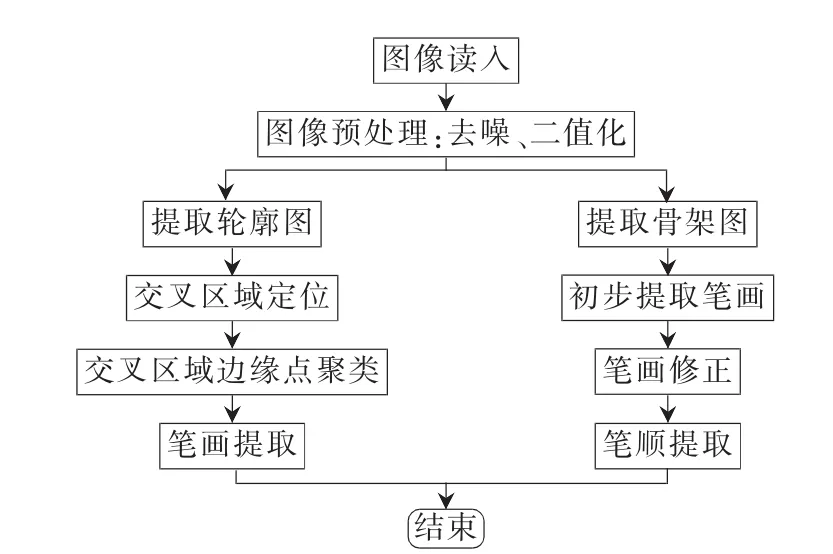
2 系统框架
算法的流程图如图1所示。
3 骨架笔画提取
3.1汉字骨架
汉字的骨架由细化算法获取,它必须满足[5]:
(1)只有一个像素宽;
(2)必须穿越物体的中间;
(3)必须保持物体的拓扑结构。
将汉字骨架中的点分为三类[5]:
(1)Nc(P)=1,则 P为端点;
(2)Nc(P)=2,则 P为普通点;
(3)Nc(P)≥3,则 P为交叉点。
其中Nc(P)为骨架点P八邻域内邻居点数量。图2为书法字骨架及端点、交叉点提取结果示例。
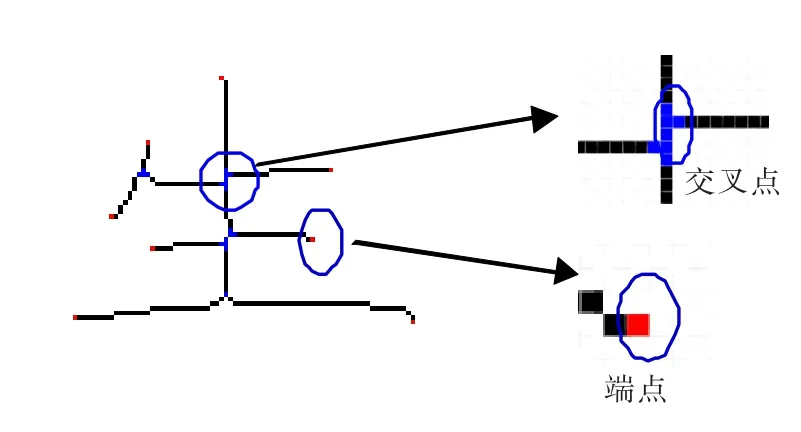
图2 骨架及端点、交叉点提取结果示例
3.2笔画段提取
本文中所使用的骨架笔画段提取方法是根据文献[5]、[6]、[7]中所提出的笔画提取方法,并对其进一步改进而来。
独立笔画:某一笔画与该汉字的其他笔画无相交、无粘连,则该笔画称之为独立笔画,其特征是笔画的起点与终点必为端点,除端点之外的其他骨架点均为普通点。
非独立笔画:某一笔画与该汉字其他笔画中的一笔或者多笔相交或粘连,则该笔画称之为非独立笔画,它是由端点、普通点以及交叉点构成,或者由交叉点、普通点所构成。
骨架笔画段提取步骤如下:
以任意端点为起点,沿其邻接的普通点方向做坐标更新,并记录每次更新的坐标与上一次坐标的方向编码,直至遇到交叉点或端点。具体的方向编码方式如图3所示。
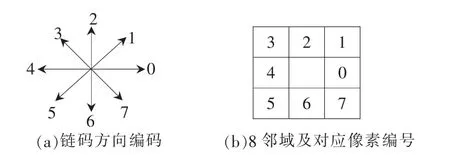
图3 链码方向及编码方式
骨架笔画段的记录方式为:

式中i表示笔画段的标号,Bi、Ei为笔画段的起点与终点,Sni为笔画段的链码表示,如图 2所示的左上角的笔画“撇”的笔画表示为:
{(19,17),(11,33),(666566645644646654)}
笔画段提取完成之后,可能存在错误的笔画段,因此需要依据下述规则对笔画段进行修正,以获得准确的骨架笔画。
规则 1.如果 li<L×η(i=1,2,3,…,Ns),则该笔画为一个错误笔画。其中,η为阈值,本文设为1/3,Ns为已提取到的笔画数,li为第i笔笔画长度:li=lenght(Sni)+1。

规则 2.如果笔画 Si,Sj(i≠j)满足如下条件:(1)Dis (Si,Sj)<λ×μw;(2)笔画走向一致或相近,则 Si,Sj可以合并为同一笔画。其中 Dis(Si,Sj)为笔画起止点之间的欧式距离。μw为近似的书法字平均笔画宽度,λ为阈值,本文λ=0.5。
经过二值化处理之后的图像可以认为是一个多边形,黑色像素点数目可以近似为该多边形的面积S,骨架的总长度可以看作经过多边形中轴的多边形的底b,汉字笔画的平均宽度可以近似看作这个多边形的高h,由多边形面积公式S=b×h推导出近似的平均笔画宽度μw的计算公式:

NPB为经过二值化处理之后的书法字黑色像素点数,NSP为骨架点的数目。
规则 3.如果笔画 Si,Sj(i≠j)满足如下条件:(1)Si,Sj与同一交叉点簇相交;(2)Si,Sj笔画走向一致或相近,则 Si,Sj可以合并为同一笔画。
4 笔顺信息获取
汉字的书写顺序大致满足如下规则:从左到右,从上到下。本文依据该规则提取书法的笔顺信息。
4.1笔画起止点的确定
本文规定书法图像左上起点为坐标原点,x轴正向为原点指向其右侧,y轴正向为原点指向其下侧。
对于骨架笔画 Si的端点 Bi,Ei,当其满足如下条件之一:

则将端点Bi,Ei进行交换。
4.2标定笔画顺序
对已正确获得起止点的笔画,按照如下确定笔画提取的优先顺序:
(1)如果Bi.x<Bj.x,则笔画 Si先于 Sj书写;
(2)如果Bi.x=Bj.x且Bi.y<Bj.y,则笔画Si先于Sj书写;
(3)如果Si满足式(6):

则该笔画为末笔。
5 笔画复原
前文中所提取的骨架笔画丢失了书法字的宽度信息,将笔画宽度信息恢复。
独立笔画的完整笔画轮廓是一条封闭的曲线;非独立笔画在剔除交叉区后,其轮廓线是断开的,需要补全成为封闭曲线。因此,对于独立笔画而言其所对应的轮廓只需通过连通性检测即可实现宽度信息恢复。本文重点解决对于存在交叉区域的笔画宽度信息恢复。
5.1交叉点簇与交叉区域
由于骨架图在提取过程中会产生一定的形变,因此交叉区域在骨架中会产生两种情况:
(1)在交叉区域,由交叉点与普通点组成,如图4左图:由两个交叉点包围着多个普通点在小的邻域内连续出现。
(2)在交叉区域,骨架图完全由交叉点组成,如图 4右部,在一个小的邻域内连续出现交叉点。
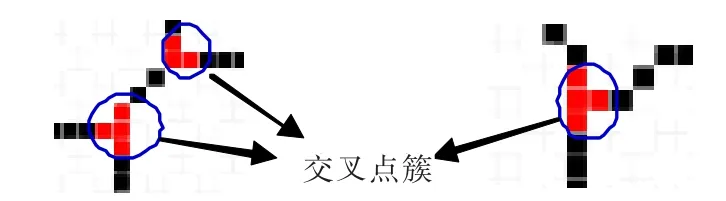
图4 交叉点簇示例
第二种情况是由骨架图的形变所引起。为了修正形变,根据最大圆准则[5-8]进行简化处理:对于骨架图中的两个特征点(交叉点),分别计算出它们在原图(未骨架化的图像)中到笔画轮廓的最大内切圆的半径。如果两个特征点之间的距离小于或等于各自内切圆半径之和,那么这两个特征点对应一个笔画的相交区域。将第二种情况中的由交叉点所包围的普通点标定为交叉点。进一步将上文中所述的两种情况归并为对交叉点簇的处理。
本文使用点簇的虚拟质心Pc来标定笔画交叉区域,Pc的计算如式(7)所示:

其中,N为交叉点簇中交叉点的数量,pif为该点簇中的第i个交叉点。
5.2交叉区处理
前文中通过交叉点簇的中心完成了交叉区域的定位,为了进一步减少待处理的像素点的数目,使用轮廓图来进行交叉区域的处理。
骨架是图像的中轴[9-11],因此,对书法字轮廓图做笔画提取,交叉区域的轮廓图有如下的特点:
(1)位于交叉区域的轮廓线,相对于交叉区域质心位置相对固定,且局部不相交。
(2)笔画在交叉区域的轮廓缺失。
因此,要提取到完整的笔画信息需要补全笔画缺失的轮廓点。
5.2.1聚类坐标系建立
为了更好地提取四条轮廓线,应按照如图5所示的方式建立聚类坐标系:
(1)坐标系原点为交叉区域质心,x轴正方向为由原点指向右侧,y轴正方向为由原点指向上侧。
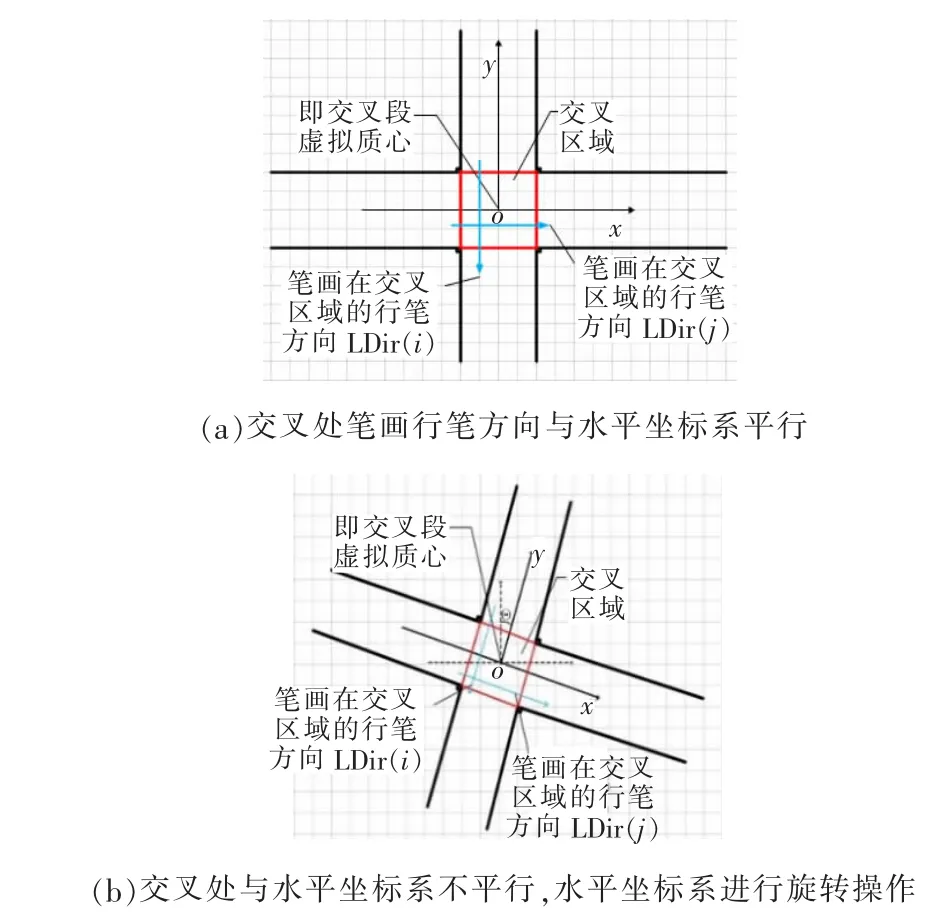
图5 坐标系建立示意图
(2)若交叉笔画在交叉处的行笔方向LDir(i)、LDir(j)与(1)中所建立的坐标系中坐标轴不平行,则坐标系逆时针旋转θ=45°。
5.2.2轮廓点聚类
坐标系的建立,为轮廓点的分类奠定了基础。按照轮廓点所属象限将轮廓点分为四个类别,具体步骤如下:
(1)以原点为圆心,以间隔角度ω=1°,最大半径R= 3μw,做扫描,记录落入圆内的所有轮廓点。
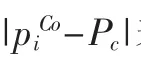
(3)计算每一个点的类别C(θ),并将其记录。其中:
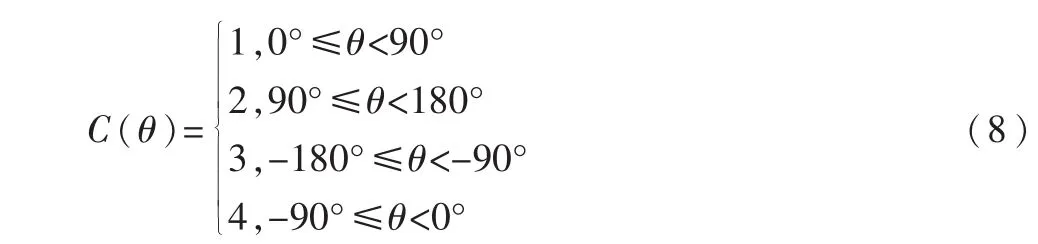
5.2.3轮廓连接点确定
使用轮廓图提取笔画的关键点是找到轮廓点中拐点或角点,来确定笔画的走向,完成笔画的提取。为了补全笔画所缺失的轮廓点,需要确定轮廓线在交叉区域的拐点,找到各个象限中距离原点最近的点,从而确定轮廓图在交叉区域的拐点即笔画在此处的链接点 Plinkc。
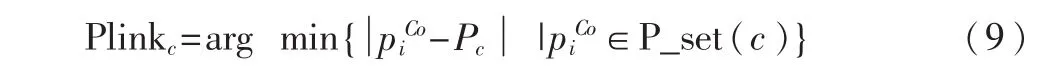
其中,P_set(c)为第 c类轮廓点集合,Plinkc为第 c类连接点。
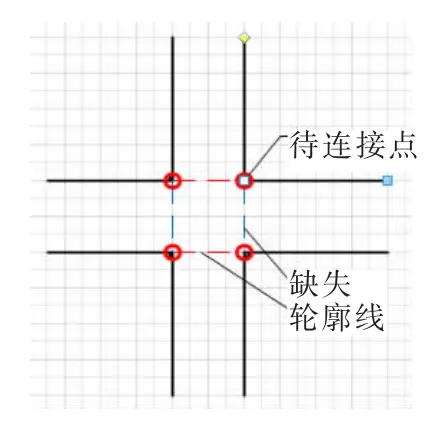
交叉笔画可以分为“十”型交叉及“T”型交叉,针对不同的交叉类型,选择不同连接点。
(1)“十”型交叉如图 6,交叉各笔画缺失两条轮廓线,因此需要选择四个连接点,依据笔画在交叉处的行笔方向,组合为两条平行于笔画交叉处行笔方向的轮廓线的起止点,完成轮廓线的补全。
(2)“T”型交叉如图 7,交叉各笔画,均缺失同一条轮廓线,因此需要选取两个连接点,依据某一笔画在交叉处的行笔方向,选取相同的两类连接点作为一条轮廓线的起始点(该轮廓线平行于一条笔画的行笔方向,垂直于与该笔画相交的笔画的行笔方向),完成轮廓线的补全。
6 实验分析
6.1实验结果
图8为楷体字“生”的笔画及笔顺提取示意。为了验证本文所提出算法的有效性,本文使用三类不同书法风格的单字图像完成笔画提取实验。实验结果如表1、表2所示。
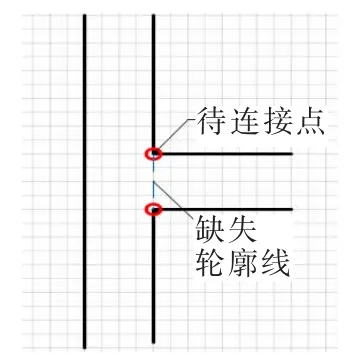
图7 “T”型交叉的示意图,相交笔画缺失同一条轮廓线


表1 笔画提取结果(骨架图)

表2 笔画提取结果(二值化图)
6.2实验结果分析
整个实验共有110幅单字图片,不同类别的图片数分别为40、40、30。由表1可以看出,针对不同类别的书法单字图像的笔画提取的准确率不同,对篆书书法字的提取效果最好,行楷提取效果最差。在表2中针对提取正确的书法单字图像做完整笔画提取,可以看到准确率均在90%以上。总的笔画提取(骨架)正确率为83.9%,针对笔画提取(骨架)正确的图像做完整的笔画提取总的准确率为93.2%。
可以看到,本文提出的基于骨架与轮廓图相结合的笔画提取算法能够较好地完成不同类别的书法单字的笔画提取,受书法字骨架引入的形变的影响较小。同时可以看出,笔画提取(骨架)的正确率对整体的笔画提取工作有着较大的影响。如何进一步完成笔画(骨架)的修正是提高整体笔画提取正确率的关键。
7 总结
本文提出将书法汉字图像骨架图与轮廓图相结合的方法,能够完成适应多类书法风格的书法汉字笔画提取以及基于书写规则的笔顺信息提取。相较于传统方法,本文所提出的算法能够有效地降低笔画提取操作所需要的时间,简化了计算复杂度,并且对多类书法字的笔画、笔顺提取都取得了较好的效果。
下一步的工作将是继续对算法进行修正,以获得针对更多类别书法字的笔画提取的结果,提高笔画提取的准确率。
参考文献
[1]张世辉,孔令富.汉字识别及现状分析[J].燕山大学学报,2003,27(4):367-369.
[2]李正华,胡奇光.汉字笔画提取的算法与实现[J].计算机应用与软件,2004,21(7):96-97.
[3]王建平,蔺菲,陈军.基于手写体汉字笔画提取重构的识别方法[J].人工智能及识别技术,2007,33(10):230-232.
[4]Wang Xiaoqing,Liang Xiaohui,Sun Linjia,et al.Triangular mesh based stroke segmentation for Chinese calligraphy[C].International Conference on Document Analysis and Recognition,2013:1155-1159.
[5]陈睿.汉字离线识别技术中笔画提取模型研究 [D].重庆:西南师范大学,2004.
[6]陈睿,唐雁,邱玉辉.基于笔画段分割和组合的汉字笔画提取模型[J].计算机科学,2003,30(10):74-77.
[7]章夏芬.中国数字书法检索与作品真伪鉴别的研究[D].杭州:浙江大学,2006.
[8]章夏芬,庄越挺,鲁伟明,等.根据形状相似性的书法内容检索[J].计算机辅助设计与图形学报,2005,17(11):2565-2569.
[9]郭晨.基于图像处理技术的手写体汉字特征分析的研究[D].天津:天津科技大学,2010.
[10]孙华,李爱平.支持向量机的古汉字识别研究[J].电脑知识与技术,2013,9(18):4296-4298.
[11]苗晋诚.基于骨架化、骨架划分获取书法汉字结构特征的方法[J].昆明理工大学学报(理工版),2008,33(3):53-61.
Calligraphy′s strokes and orders extraction based on the rules of writing
Liu Jiayan,Zhang Xiafen
(College of Information Engineering,Shanghai Maritime University,Shanghai 201306,China)
This paper proposes a novel stroke and the orders extraction algorithm adopted to multiple classes of the Chinese calligraphy.In order to process the region of fork strokes,the paper proposes a new cluster method which combine the skeleton image and the contour image.The rules of clustering is based on the angle of the contour points and the Euclid distance of the point to the fork region′s center point.And then completing the stroke′s missing information in the fork region,extracting the orders of the stroke based on the rules of writing.Finally,the strokes of three types Chinese calligraphy are extracted with this algorithm.Experimental results show that the proposed algorithm achieves a better effect.
Chinese calligraphy;stroke extraction;rules of writing;orders of calligraphy′s stroke
TP391.1
A
1674-7720(2015)15-0051-04
刘佳岩,章夏芬.基于书写规则的书法字笔画及笔顺提取[J].微型机与应用,2015,34(15):51-54,58.
2015-03-13)
刘佳岩(1990-),男,硕士研究生,主要研究方向:数字图像处理与模式识别。
国家自然科学基金(61303100);上海海事大学校基金(20130467)
章夏芬(1977-),女,博士,讲师,主要研究方向:图像处理、模式识别、数字图书馆。
猜你喜欢
吉林师范大学学报(自然科学版)(2022年4期)2022-12-09
计算机仿真(2022年8期)2022-09-28
World Journal of Psychiatry(2020年4期)2020-07-11
中国教育信息化(2019年22期)2019-12-20
孩子(2019年7期)2019-07-29
小学生学习指导(中年级)(2019年3期)2019-04-10
家教世界(2018年34期)2018-12-24
学生天地·小学低年级版(2018年10期)2018-12-15
小天使·六年级语数英综合(2018年6期)2018-10-08
计算机系统应用(2017年3期)2017-03-27
