
一种基于特征差异度和SVM投票机制的数字音乐语音情感识别算法
2015-06-01 10:17:11谢志成
福州大学学报(自然科学版) 2015年4期
王 秀, 谢志成, 张 栋
(福州大学数学与计算机科学学院, 福建 福州 350116)
一种基于特征差异度和SVM投票机制的数字音乐语音情感识别算法
王 秀, 谢志成, 张 栋
(福州大学数学与计算机科学学院, 福建 福州 350116)
针对数字音乐语音情感识别问题, 提出一种基于特征差异度和SVM投票机制进行识别的方法. 该方法不仅降低了特征向量的维度, 而且保留了足够的能够描述数字音乐语音不同情感之间差异的特征. 同时, 该方法利用多个二分SVM分类器进行投票, 减少了每个分类器的权重, 从而降低了误差. 实验结果表明, 该方法能够有效地提高识别准确率.
数字音乐语音; 情感识别; 支持向量机; 特征差异度
0 引言
随着科学技术的发展, 人们的娱乐生活越来越丰富多彩, 对于娱乐内容的要求也不断提高. KTV作为娱乐的一种形式, 已经被人们广为接受. 如何提高人们对于KTV服务质量的满意程度也开始受到学术界和业界的广泛关注. 目前, KTV系统已经可以对演唱者的音高、 音长等音准方面的因素进行评判和打分, 但是并不能评判演唱者的演唱是否带有符合歌曲本身的情感, 导致评分反映不出演唱主观质量, 这样就会降低评分的准确性, 影响用户的体验. 针对上述情况, 本研究提出一种基于特征差异度(DBC, difference between characteristics)系数和SVM投票机制的数字音乐语音情感识别算法, 将识别结果加入评分系统中, 从而增加评分的主观性. 语音情感识别方法的一般流程如图1所示.

图1 语音情感识别流程图Fig.1 The flow chart of emotion recognition
目前, 语音情感识别主要关注的是正常说话语音而不是音乐语音, 识别的关键问题在于特征与识别模型的选取, 现有的识别方法各有不同. 文献[1]采用提取Mel倒谱系数(MFCC)作为特征参数, 然后选择SVM作为分类器的方法. 该方法不仅考虑了低频部分的MFCC, 同时提升了中高频MFCC的计算精度, 并将其作为低频MFCC的补充, 然后利用SVM作为分类器进行识别. 这种利用MFCC参数的方法考虑了Mel频率同Hz频率的非线性关系, 但如果单一利用MFCC系数作为识别参数, 特征包含的信息太少. 文献[2]采用直接计算传统特征, 如能量、 过零率、 能零积、 基频、 共振峰等, 再计算上述特征的最大值、 最小值、 平均值、 标准差, 然后利用混合蛙跳算法(SELA)神经网络识别情感的方法. 这种方法没有对特征进行降维处理, 不仅计算量较大, 而且可能把一些在分类过程中没有用的特征也考虑进来, 从而影响识别准确率. 文献[3-5]采用提取传统特征及其衍生参数作为备选特征, 然后利用Fisher准则或者PCA等方法, 从备选特征提取适合特征进行分层识别[6]. 基于Fisher准则提取传统特征及其衍生参数的方法, 如果准则模型与实际样本数据的分布有较大的偏差, 就无法得到好的识别结果[7]. 同时, Fisher判别的思想是先确定类与类间的临界值, 然后以临界值作为准则进行判别. 而计算临界值时没有考虑样本总体大小及类的离散程度对临界值的影响, 这样会导致判别效果变差[8].
1 数字音乐语音情感特征的提取与选择
数字音乐语音和正常说话语音的情感不一样. 正常说话语音的情感类型指的是根据所处环境、 心情等因素的不同, 说话人在发音时表现出的不同的语气、 语调和语速. 一般来说, 正常说话包括6种基本情感类型[9-11]: 悲伤、 愤怒、 惊奇、 恐惧、 喜悦、 厌恶. 而数字音乐语音的情感类型跟环境、 心情等因素无直接关系. 歌者努力演唱所要表现的是歌曲本身就富含的情感, 因此, 数字音乐语音的情感类型与歌曲类型息息相关. 本研究根据不同歌曲的风格, 提出了音乐语音基本情感模型: 悲伤、 高兴、 激昂、 抒情和发泄. 同时, 将音乐语音情感模型与情感语音特征结合, 提出一个基于特征差异度的特征选择方法, 并利用SVM分类器, 实现音乐情感识别.
1.1 备选特征提取
特征提取的任务是提取并选择具有可分性强的特征. 目前大部分情感识别系统采用的都是声学层面的特征. 为了创建一个丰富的备选特征集合, 经过分析选取了音乐语音的韵律特征和音质特征作为基本特征. 韵律特征包括音高、 音长, 音质特征包括前三个共振峰及其导数、 短时能量、 短时能量的对数及对数的导数. 然后分别计算每个基本特征的方差、 均值、 最大值、 最小值、 偏差及一阶导数, 最终得到52维的备选特征作为音乐语音情感特征选择和分析的基础, 如表1所示.

表1 备选特征列表
1.2 基于特征差异度(DBC)的特征选择方法
对表1的音乐语音情感特征, 定义了特征差异度(DBC)系数, 计算长度不一的不同类样本间的距离, 解决了Fisher准则样本分布无规律以及样本数量不一致的缺陷, 借助DBC寻找不同特征之间的差异性, 选择合适特征.
1.2.1 DTW距离
动态时间规整(DTW)[12]是基于动态规划(DP)的思想提出的, 它解决了长短不一的模板匹配问题. 简单来说, 就是通过构建一个邻接矩阵, 寻找最短路径和.
设序列A(m)={a1,a2, …,am}和B(n)={b1,b2, …,bn},则序列A和序列B的DTW距离计算公式:
DTW[i, j]=dist(A[i],B[j])+min(DTW[i-1, j], DTW[i, j-1], DTW[i-1, j-1])
其中: dist()表示A[i]和B[j]的欧式距离; DTW(A,B)=DTW[m, n].
1.2.2DBC系数的提出
设特征类别T={T1,T2, …,T52}, 分别代表52个备选特征,情感的类别Y={Y1,Y2,Y3,Y4,Y5}, 分别代表五种不同情感. 用T1Y1表示第一类情感所有样本的第一个特征的集合, 设第一类情感共有N个样本,则向量T1Y1={T1Y1(1),T1Y1(2), …,T1Y1(N)}.
对每个样本进行分类时, 要求所选择样本的特征序列的类间相似度尽可能小, 而类内相似度尽可能大. 基于这个原则, 定义特征差异度(DBC)系数, 用来计算在样本确定的情况下某个特征序列的类间相似度和类内相似度的大小.DBC系数越大, 说明该特征越能反映异类间的相异性和同类间的相似性. 特征Ti的DBC系数dist(i)定义为TiY1,TiY2,TiY3,TiY4,TiY5中任意两个不同向量的DTW距离之和除以所有向量方差之和, 具体计算方法如下:
上式中,variance()表示一个序列的方差,max()表示一个序列的最大值. 计算每个特征向量的DBC系数.
2 基于SVM投票机制的音乐语音情感识别
由于ANN在语音情感识别的推广性能不如SVM, 文中选择SVM作为检验不同特征选择方法的分类器.SVM用于二类问题效果很好, 但对于多类问题效果不佳, 因此, 通过构建多个二分SVM分类器进行投票表决, 将待测样本的特征序列输入不同二分SVM分类器, 统计每个SVM分类器的分类结果, 得票数最大的情感则为识别结果. 二分SVM原问题的目标函数:
其中:w是超平面距离; ε是松弛变量;P是惩罚因子.
当情感特征的区分度比较大时, 可以减小P值从而增加SVM的分类准确性, 而当情感特征的区分度比较小时, 应该适当提高P值从而增加对错分样本的约束程度. 本文的SVM投票机制的识别模型采用的惩罚因子P与选取特征的DBC系数有关:
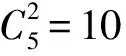
3 实验结果与分析
3.1 实验数据
由于现有的情感语音数据库都属于正常说话语音, 因此, 实验数据选取网络下载不同男女声清唱版(未带伴奏音且吐词清晰)的歌曲录音, 重新采样得到采样频率44.1 kHz, 采样位数16 bit的清唱录音, 然后将每首歌逐句分割得到备选录音. 事先, 由本实验组共6人将所有备选录音按照上述5类情感进行分类, 若判断演唱感情平淡, 则将该句录音删除不作考虑, 然后统计每句录音的情感分类结果. 如果有5个人或以上均认为该录音属于某同一类别, 则将这句歌曲分入该类情感作为实验素材. 最后, 每类情感均得到600条左右清唱语句的录音. 考虑到如果每个类型的训练样本不同, 则SVM分类器可能会出现偏向性, 将所得实验素材数量最少的情感——发泄, 按照训练/测试比1 ∶2的比例, 从发泄素材中随机选取1/3的句子作为训练样本. 同时, 为了保持训练时的不偏向性, 也从其他四类情感实验素材中随机选取同样数量的句子作为训练样本, 其他剩余的句子均作为测试样本.
3.2 特征选择实验结果
实验分别采用DBC、 PCA、 因子分析、 Fisher等方法, 得到相应的选择结果. 根据DBC方法, 实验结果如表2所示.

表2 DBC选择特征列表
从表2看出, 基于DBC系数的特征选择提取了20个特征, 特征个数的选择是自适应的. 在计算每个特征值的DBC系数后, 将DBC系数值大于所有DBC系数平均值的特征选出. 为了便于识别准确率的比较, 将其他特征选择方法也选出相同个数的特征数.

因子分析法主要步骤如下: 根据输入原始数据SN×M=[X1,X2, …,XN]T, 计算样本均值和方差, 进行标准化处理. 求样本相关系数矩阵R=(rij)M×M, 求相关系数矩阵的特征值λi(λi>0,i=1, 2, …,M)和相应的标准正交的特征向量, 确定公共因子数, 计算公共因子的共性方差, 对载荷矩阵进行旋转, 以求更好地解释公共因子, 最后对公共因子做出专业性的解释. 实验采用统计分析软件——SPSS18(PASWStatistics18.0.0)进行因子分析. 实验通过导入数据、 参数设置(抽取特征值>1, 最大收敛性迭代次数为25, 方法为最大方差法)等步骤, 计算每个特征向量成分得分系数的绝对值的和, 并根据大小选择前20个即为结果. 实验结果见表3.
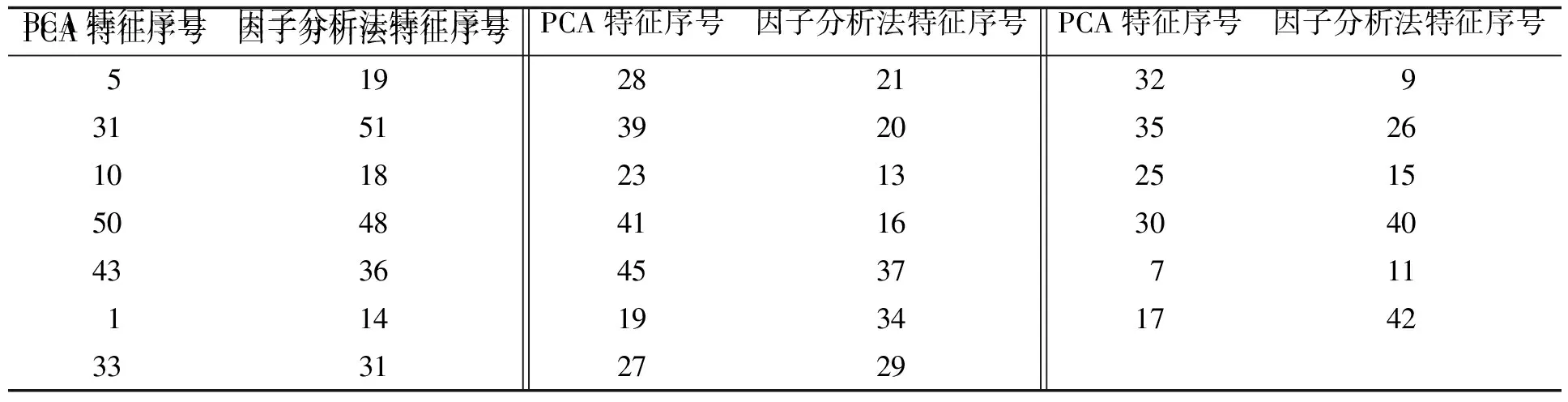
表3 PCA与因子分析法选择特征列表

图2 分层语音情感空间模型Fig.2 Hierarchical speech emotion space model

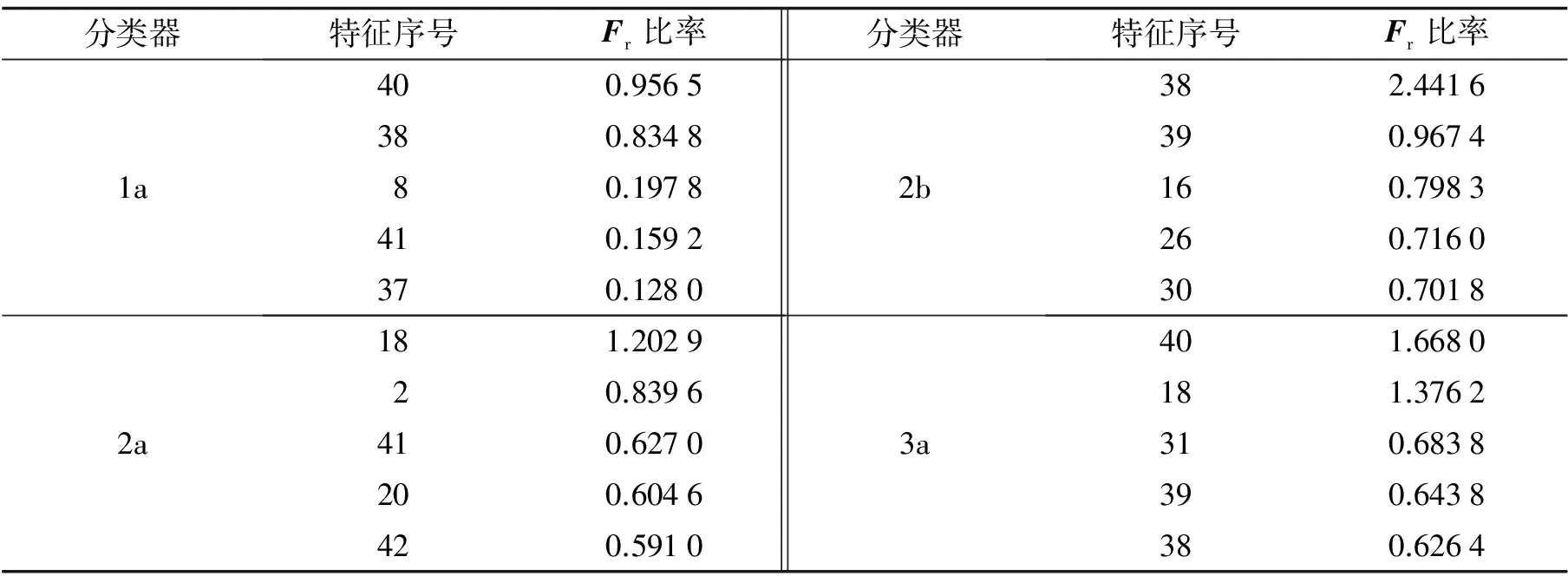
表4 各分类器不同特征Fisher比率
3.3 音乐语音情感识别实验结果
5组对比实验, 包括DBC算法、 Fisher方法、 PCA方法、 因子分析方法以及使用全部52维特征的DBC算法, 分别验证了不同特征选择方法和SVM对音乐语音情感识别的识别准确率. 识别结果如图3所示.
对比图3的5组实验结果可知, 本文算法利用DBC系数进行特征选取, 不仅降低了特征的维度, 减少了SVM训练和识别的时间, 且较为准确地保留了能够描述不同情感差异的特征, 与其他4组方法对比, 实验的识别准确率高. 同时, 由于全部52维特征中有部分特征具有较为明显的相似性, 如抒情与悲伤、 发泄与激昂, 因此, 利用DBC系数进行特征选取后, 算法的准确率也高于采用全部52维特征时的准确率. 也正是因为存在这些相似性, 从图3还可以看出, 抒情和发泄两类情感的整体识别准确率均不高.

图3 不同实验的准确率Fig.3 The accuracy of different experiments
4 结语
提出一种基于特征差异度和SVM投票机制进行音乐语音情感识别的方法. 基于DBC系数进行特征选取, 不仅降低了特征向量的维度, 同时保留了足够的能够描述数字音乐语音不同情感之间差异的特征, 较PCA、 因子分析、 Fisher准则提取特征而言提高了识别的准确率. 同时, 利用多个二分SVM分类器进行投票识别情感的方法, 减少了每个分类器的权重, 从而降低了误差, 能够有效地提高识别准确率.
[1] 韩一, 王国胤, 杨勇. 基于MFCC的语音情感识别[J]. 重庆邮电大学学报: 自然科学版, 2008, 20(5): 597-602.
[2] 余华, 黄程韦, 张潇丹, 等. 混合蛙跳算法神经网络及其在语音情感识别中的应用[J]. 南京理工大学学报, 2011, 35(5): 659-663.
[3] Guo Yuefei, Shu Tingting, Yang Jingyu,etal. Feature extraction method based on the generalized Fisher discriminant criterion and facial recognition[J]. Pattern Analysis & Applications, 2001, 4(1): 61-66.
[4] Wang S, Li Deyu, Wei Yingjie,etal. A feature selection method based on Fisher’s discriminant ratio for text sentiment classification[C]//Proc of the International Conference on Web Information Systems and Mining. Shanghai: [s.n.], 2009: 88-97.
[5] Pearson K. On lines and planes of closest fit to systems of points in space[J]. Philosophical Magazine, 1901, 2 (6): 559-572.
[6] 陈立江, 毛峡, Mitsuru I. 基于Fisher准则与SVM的分层语音情感识别[J]. 模式识别与人工智能, 2012, 25(4): 604-609.
[7] 黄国宏, 刘刚. 一种改进的基于Fisher准则的线性特征提取方法[J]. 计算机仿真, 2008, 25(7): 192-195.
[8] 黄利文, 梁飞豹. 改进的Fisher判别方法[J]. 福州大学学报: 自然科学版, 2006, 34(4): 473-477.
[9] Tomkins S S. Affect, imagery, consciousness[M]. New York: Springer, 1962.
[10] Izard C E. Human emotions[M]. New York: Plenum Press, 1977.
[11] Ekman P. An argument for basic emotions[J]. Cognition and Emotion, 1992, 6(3/4): 169-200.
[12] Sakoe H. Two level DP matching: a dynamic programming based parton matching algorithm for connected word recognition[J]. IEEE Trans Acoustic Speech Signal Processing, 1979, 27: 588-595.
[13] 刘颖, 王成儒. 用于人脸动画的语音特征提取算法研究[J]. 电声技术, 2009, 32(12): 49-53.
(责任编辑: 沈芸)
An emotion recognition algorithm for digital music speech based on difference between characteristics and SVM voting mechanism
WANG Xiu, XIE Zhicheng, ZHANG Dong
(College of Mathematics and Computer Science, Fuzhou University, Fuzhou, Fujian 350116, China)
To solve emotion recognition problem for digital music speech, an emotion recognition method which is based on difference between characteristics and SVM voting mechanism is proposed. The method not only reduces the dimension of feature vectors, but retains the characteristics between different emotions of digital music speech. Meanwhile, using multiple two-class SVM classifier to vote for digital music speech, the method decreases the weight of each classifier and reduces the error. The experimental results show that this method can effectively improve the recognition accuracy.
digital music speech; emotion recognition; support vector machine; characteristic difference
10.7631/issn.1000-2243.2015.04.0460
1000-2243(2015)04-0460-06
2013-12-05
张栋(1981-), 讲师, 主要从事计算机网络、 网络虚拟化研究, zhangdong@fzu.edu.cn
福建省青年科技人才创新资助项目(2011J05150); 福建省自然科学基金资助项目(2013J01231,2015J01420); 福州大学科技发展基金资助项目(2012-XY-20)
TP391
A
猜你喜欢
阅读(快乐英语高年级)(2019年5期)2019-09-10 07:22:44
电子制作(2019年14期)2019-08-20 05:43:38
电子制作(2019年9期)2019-05-30 09:42:10
小说界(2018年5期)2018-11-26 12:43:42
电子测试(2018年1期)2018-04-18 11:52:35
电子制作(2017年23期)2017-02-02 07:17:06
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
西北工业大学学报(2015年4期)2016-01-19 03:31:47
电测与仪表(2014年15期)2014-04-04 12:05:20
