
一种基于改进Kmeans的动态文摘提取方法
2015-06-01 06:18郭海蓉等
软件导刊 2015年5期
郭海蓉等
摘 要:随着互联网的发展和Web2.0的应用,网络信息呈现出越来越明显的动态演化性,传统的静态文摘方法不能很好地反应文摘的动态变化和新颖性,难以满足人们对于摘要获取效率的要求,动态文摘技术成为新的研究热点。提出一种基于改进K-means算法的动态文摘提取和更新方法。为了减小聚类结果对初值的依赖性,提高聚类的稳定性,采用聚类中心的搜索算法获得较优的初始聚类中心。它能解决使用传统聚类方法进行动态文摘提取中存在的重复计算问题,并能保持较高效率。在TAC2008上的实验证明,该方法生成的动态文摘效果较好、算法效率高。
关键词:K-means;动态文摘;增量聚类;TAC 2008数据集
中图分类号:TP312
文献标识码:A 文章编号:1672-7800(2015)005-0077-03
作者简介:郭海蓉(1989-),女,四川眉山人,西南科技大学计算机科学与技术学院硕士研究生,研究方向为自然语言处理;张晖 (1972-),男,四川绵阳人,博士,西南科技大学教育信息化推进办公室教授,研究方向为文本挖掘、知识工程;赵旭剑(1984-),男,四川绵阳人,博士,西南科技大学计算机科学与技术学院讲师,研究方向为中文信息处理、Web信息检索;李波(1977-),男,四川绵阳人,博士,西南科技大学计算机科学与技术学院讲师,研究方向为信息过滤、信息安全;杨春明(1980-),男,四川绵阳人,硕士,西南科技大学计算机科学与技术学院讲师,研究方向为文本挖掘、知识工程。
0 引言
随着互联网的高速发展,网络信息日益丰富,为了帮助读者从海量的网络文档中抽取他们感兴趣的信息,多文档文摘技术研究不断发展[1]。由于传统的多文档文摘技术是一种静态文摘[2],只能对一个静态的文本集合进行文摘抽取,如果依然使用传统的静态文摘方法进行摘要的抽取和更新,则需要不断重复对历史文档集的提取过程,因而非常耗时而且浪费资源。为了适应用户需求,快速、高效地更新文摘信息,动态文摘技术成为一个新的研究热点。
目前的动态文摘研究工作大多基于批处理原则以文档集合为单位进行处理[3]。而在实际应用中,如新闻更新、灾难报告、舆情分析等系统,文档数据是不稳定的数据流,因此需要研究高效的基于数据流处理的动态文摘抽取办法。为了解决上述问题,本文提出了一种基于聚类的动态文摘方法。该方法通过改进的K-means聚类算法进行句子分类,结合图中节点权重和时间因素筛选出候选文摘句,根据摘要长度抽取出动态文摘,实现动态文摘的数据流处理和文档数据流的增量式处理,实时更新文摘内容。改进的K-means算法对文本摘要提取精度有较大提升。
1 相关工作
动态文摘的概念是由DUC(document understand conference)于2007年提出,并成为TAC2008之后TAC会议的3大主要评测任务之一。TAC的动态文摘指,假设用户已经阅读过历史文档信息,需要获取当前文档集合中重要的、新颖的、区别于历史信息的内容作为更新摘要来向用户反馈关注事件的最新进展情况[4]。
基于时间因素的相关研究中, Wan[5]等将时间序列应用到文摘抽取中,是对著名的图排序算法TextRank[6]的改进应用。Boudin等[7]对MMR[8]算法进行扩展应用。Li等[9]提出的PNR2和Du等[10]提出的MRSP就是基于图模型的代表。基于内容过滤的方法也是动态文摘抽取的主流方法之一,Zhang[11]等最早提出了一种基于句子排序算法的内容过滤模型进行动态文摘抽取。基于增量聚类的方法能通过对文档数据流进行处理来抽取动态文摘。Wang 和 Li等[12]在2010年实现了基于改进COBWEB算法的动态文摘方法,通过把文档句构建成一个层次聚类树,选出聚类结果中最重要的句子作为文摘句。
本文采用改进的K-means聚类划分子主题,并通过加权公式为句子节点打分的方式实现一种基于增量图聚类的动态文摘方法。本文方法与其它基于增量聚类方法的动态文摘抽取方法的区别在于:从实际应用需求出发,用改进的K-means方法实现对文档的数据流处理,并在聚类过程中考虑了数据的删除,以解决计算机资源限制问题并提高处理效率。
2 改进的K-means算法
在K-means 算法中初始化聚类中心时,采用随机抽取样本数据集合中的K个样本来近似。样本点抽取的不同将很大程度地影响到聚类结果的获取。因此,本文采用预处理初始聚类中心点的方法来改进该算法[13]。为了减小聚类结果对初值的依赖性,提高聚类的稳定性,采用聚类中心的搜索算法可以获得较优的初始聚类中心。在搜索过程中通过对数据随机取样,尽量使得取样后的数据既不失真,又能体现数据的原始分布特征。
对取得的样本数据进行K-means聚类,通过实验发现聚类所有数据最终得到的簇中心结果与样本相近,因此证明此方法可应用于K-means初始聚类中心的选取。为了将初始聚类中心选取所产生的影响最小化,采用多次样本提取,提取的样本集在不影响系统需求速度的前提下尽量扩展,并且n次抽样的样本总数量约等于原始数据集。对每次样本进行K-means聚类,得到一组聚类中心,抽样n次,产生n组聚类中心,然后对n组聚类中心进行聚类准则函数值的比较,确定误差值最小的一组聚类中心为最优初始聚类中心。
3 基于改进K-means的动态文摘算法
3.1 算法框架
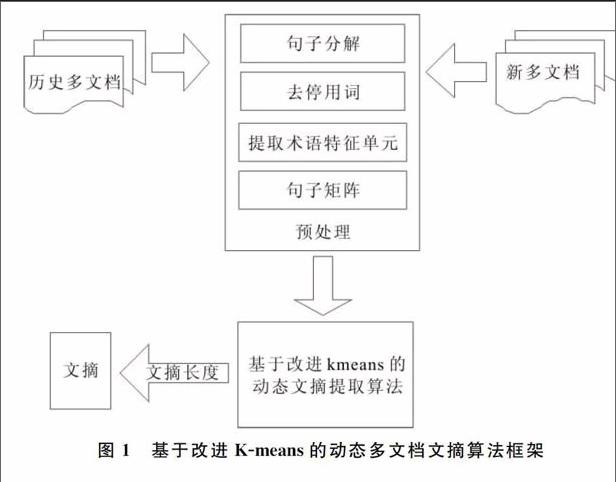
本文提出的动态多文档摘要算法框架如图1所示。首先,对文档集合进行预处理;然后,采用改进的K-means算法进行句子聚类,利用摘要选择算法获得候选文摘句;最后,根据摘要长度确定最终摘要。
3.2 预处理
文摘抽取的第一步是对文档集合进行预处理,首先对其进行句子分解,获得文档集合中的所有句子,然后去除停用词并提取n维术语特征词集合W(w1,w2,w3,…,wn),再使用术语特征词构建句子向量S(TFW1,TFW2,TFW3,…,TFWn),最终形成文档的句子矩阵。其中,TFwi代表术语特征词wi在句子S中出现频率。
3.3 基于改进K-means的动态多文档自动摘要算法
本文的动态文摘算法采用改进K-means算法对文档句子流进行聚类实现话题的子主题划分,并增加数据仓库和数据删除机制实现增量式的聚类句子节点,同时对每个句子进行权重打分以提高最终文摘质量。句子权重计算公式如下:weight=log(λ)·(currentTime·creatTime(ri)+1)+log(count+1)+D(ri,rcenter),其中rcenter代表聚类中心点。选出每个聚类中weight最大的数据点作为备选文摘句,再根据文摘长度截取weight排名靠前的句子作为最终文摘。基于改进K-means的动态多文档自动摘要算法如下:
算法1:动态文摘算法
输入:多文档,聚类个数k,文摘长度w
输出:动态文摘
(1)将多文档分解为句子,提取特征词,构建多维句子向量。
(2)对句子向量进行改进K-means算法聚类,更新K-means聚类簇数据。
(3)将新的句子向量加入数据仓库,计算句子的重要度,判断是否删除数据。
(4)重复(2)-(3)直到当前句子向量集合处理完毕。
(5)计算聚类中心,选出距离聚类中心较近的节点中句子权重排序。
(6)根据要求的文摘长度w截取排名靠前的句子作为动态文摘。
4 实验结果与分析
4.1 数据集
本文采用TAC 2008Update Summarization 任务的测试语料集。假定读者对该话题的历史文档信息有了解,Update Summarization任务的目的是对每一段时间的文档集给出100字的文摘,该文摘能反映沿着时间变化的内容更新。
4.2 文摘评测
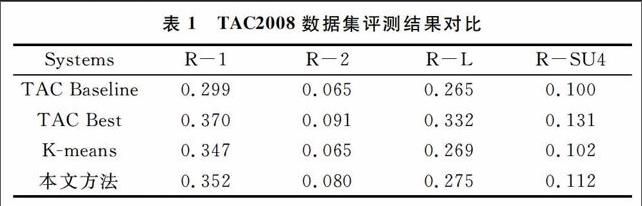
基于ROUGE准则的评测是由ISI的Lin和Hovy[18]提出的一种自动摘要评价方法。目前,ROUGR评测已经被广泛应用于TAC的动态文本摘要评测任务中。本文实验采用TAC 2008的Update Summarization测试数据,将所得动态文摘结果的ROUGE-1(R-1)、ROUGE-L(R-L)、ROUGE-2(R-2)和ROUGE-SU4*(R-SU4)得分与TAC 2008 Update任务中其它系统的得分进行对比,如表1所示。结果表明,本文提出的动态多文档文摘方法效果良好。
4.3 实验结果
为了更好地给出采用本文方法后的结果,选取传统算法作为本文算法结果的对比算法。TAC Baseline是TAC创建的一个文摘评测基本标准,其原理是从最近的文档集合中选出文章的第一个句子作为文摘;TAC Best表示TAC文摘任务参赛者中的最佳结果。
从评测结果可以看出,传统K-means算法效果较差,因为传统K-means算法聚类效果不佳,并且每次都是随机选取初始聚类中心,稳定性差,同时聚类个数的人工设定也有相当大的影响。而改进后的K-means算法在提升摘要质量上效果明显,并且对句子的加权也进一步提升了摘要效果。同时,本文方法是基于增量聚类算法,能很好地适用于大数据情况。
5 结语
本文提出了一种基于改进K-means聚类算法的动态多文档摘要提取新方法,通过改进的K-means算法对句子进行聚类,并提出了新的句子权重计算方法用于动态文摘提取方法,实现了文档数据流的增量式处理,在TAC 2008数据集的基础上,使用ROUGE-1.5.5的评测工具包对摘要结果进行评测,验证了该方法的有效性。后续研究中将着重考虑提高动态文摘算法的准确性和效率,并将该算法更好地应用于超大规模的数据处理中,如舆情分析系统。
参考文献:
[1] 秦兵,刘挺,李生.多文档自动文摘综述[J].中文信息学报,2005(6): 15-22.
[2] 刘美玲,郑德权,赵铁军,等.动态多文档文摘模型[J].软件学报,2012(2): 289-298.
[3] LI X,DU L,SHEN Y.Update summarization via graph-based sentence ranking[J].Knowledge and Data Engineering, 2013, 25(5): 1162-1174.
[4] DANG H T,OWCZARZAK K. Update summarization task[C].Overview of the TAC 2008, 2008.
[5] WAN X. TimedTextRank: adding the temporal dimension to multi-document summarization[C].ACM, 2007.
[6] MIHALCEA R,TARAU P.Textrank:bringing order into texts[C].Association for Computational Linguistics,2004.
[7] BOUDIN F,ELBZE M.A scalable MMR approach to sentence scoring for multi-document update summarization[C].Citeseer,2008.
[8] CARBONELL J,GOLDSTEIN J.The use of MMR, diversity-based reranking for reordering documents and producing summaries[C].ACM,1998.
[9] LI W,WEI F,LU Q,et al.Ranking sentences with positive and negative reinforcement for query-oriented update summarization[C].ACM,2008.
[10] DU P,GUO J,ZHANG J,et al. Manifold ranking with sink points for update summarization[C]. ACM,2010.
[11] ZHANG J,CHENG X,XU H,et al.Ictcass ictgrasper at tac 2008:summarizing dynamic information with signature terms based content filtering[C].Citeseer,2008.
[12] WANG D,LI T.Document update summarization using incremental hierarchical clustering[C].ACM, 2010.
[13] ZHOU P,LEI J,YE W.Large-scale data sets clustering based on mapreduce and hadoop[J].Journal of Computational Information Systems,2011, 7(16): 5956-5963.
(责任编辑:孙 娟)
猜你喜欢
中国新闻周刊(2021年26期)2021-07-27
环境影响评价(2020年2期)2020-12-02
汽车维修与保养(2020年11期)2020-06-09
电脑与电信(2018年12期)2018-03-23
宝藏(2017年2期)2017-03-20
信息安全研究(2016年4期)2016-12-01
西北工业大学学报(2015年3期)2015-12-14
中国卫生(2014年7期)2014-11-10
电脑迷(2012年4期)2012-04-29