
基于HMM语音识别的韵律标记
2015-05-30 02:52熊艳娇
中国新通信 2015年12期
关键词:语音识别
熊艳娇
【摘要】 韵律结构的准确度决定语音合成的自然度,想要让合成的语音具有较强的节奏感和较高的自然度,就需要正确地把握,然后恰当地划分韵律。本文利用语音识别结果,提出基于声韵母时长的韵律标记规则,以实现韵律自动标记,并给出具体实现方案和过程。实验结果表明:采用本文提出的规则实现韵律自动标记,其可接受率已达到HMM语音合成的要求。
【关键词】 隐马尔可夫模型 语音识别 韵律标记
语音合成的自然度与语音的韵律要素有着紧密的联系[1],想要让合成的语音具有较强的节奏感和较高的自然度,就需要正确地把握韵律结构,然后恰当地划分韵律。国外有学者对韵律结构中的韵律单元的组成单位(音节或者是音素)的时长关系进行了研究,特别是在英语方面的相关研究中,取得了一定的成果。比如说Oller通过研究发现,对于英语单词的音长,处于词首的辅音比处于词中的辅音长,这种情况在很多语言中都有出现。可见,从时长角度来研究韵律是可行的。
一、语音识别的实现
1.1构建语音库
用以声韵母为基本单位的方法进行语音识别[2],生成识别结果的原始录音数据是由特定实验对象来完成的。录音结束,对结果做如下处理:
①利用音频处理软件Gold Wave将录制的语音数据进行重新采样,其采样速率设定为16KHz。
②将数据重新保存为mono格式,保存类型设置为wav。经过重新采样后的音质与原始语音音质差别不是很大,可以接受。
③将该录音wav文件进行人工切分,一个句子对应一个wav文件。在实验中,最终使用的数据为 wav(Windows PCM),比特率为256kbps,采样率为16KHz的16位mono格式。
1.2识别结果分析
由识别器生成基于HMM的识别结果。
识别结果源文件及解释如图1。
识别结果所携带的信息有四点:
①该句语音中所存在的停顿和开头结尾静音段的结束时间;
②组成该句语音的所有音素说完对应结束时间点;
③组成该语音的各个音素对应的HMM状态的结束时间。
④组成该句语音的各个音节的结束时间。
在此,需要特别说明,识别结果中的音素与通常所熟知的声母、韵母的书写方式不同,其中还有一个转换的问题。
二、韵律标记划分的实现
本文利用C语言编程实现韵律标记划分。以发音人A为例,具体过程如下:
(1)编写C语言程序从识别结果中提取出声母的时长,然后进行统计。
(2)利用excel统计发音人A所录的1005句语料中各个声母的时长,还有在对应时长该声母出现的频率。以发音人A所录语音中的声母b为例,在1005句录音中,对于声母b,出现次数最多的时间段是90-100ms,其次就是70-80ms,最少的就是250-260ms,而200-210ms、220-230ms等都没有出现。其余声母以此类推。
(3)如果以上述的统计结果来总结规律,以每个声母的时长来分别进行韵律划分,就需要设定23个边界。为了减少边界的判断次数,简化判断条件,本文又就声母发音方式的分类规则对各类声母时长做了进一步统计研究,绘制成表格,如下表1。
(4)分析以上统计结果,综合四个发音人的统计表,得出韵律边界规律,从而设定出韵律边界。
(5)人工校对确定最终边界。人工校对归纳出按上述边界划分韵律不准确的音节,然后在原来的边界基础上,对易出错的声母的边界进行相应调整。
(6)最后就将易出错的声母单独设定边界,以最终确定的韵律边界来进行韵律划分。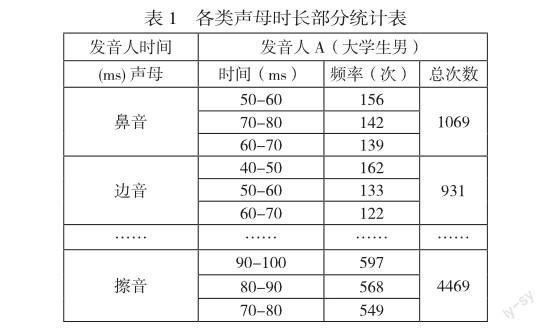
三、实验结果与分析
本文对这种基于声母时长统计信息标记的方法进行了主观评测,以确定这种标记方法是否能用于汉语的韵律自动标记。具体做法如下:
(1)在实验过程中,我们挑选了两个识别的1005句语料进行了韵律边界预测的标记和评测,另取200句作为集内,200句用于集外。
(2)对于每一个句子,组织三位母语为汉语的评测人员根据表2的评分规则对预测结果以打分的方式进行评测。
(3)根据下述可接受率公式进行计算。
从表中可以看出,本文所采用的基于声母时长统计信息作为韵律预测标记的方法可满足在语音转换系统中的初步应用。但本文所采用的方法仍有一定局限性,其原因有四点:
(1)训练数据不充分,用于统计的声母时长的信息不够多,韵律划分边界还有待调整。
(2)本文所采用的方法依赖于语音识别的时间信息。对于语音识别,由于不同发音人之间的差异,会使得相同的字具有不同的语音特征。故而,识别结果具有不确定性。
(3)人为对声母时长边界的调整带有很强的主观性,每个人都有自己的一套特定的说话规则。人工调整韵律,这样做会对该方法的标记结果有很大的影响。
(4)在做韵律划分时,本文主要考虑了时长和停顿,为了提高划分的准确度,在今后的研究中,应进一步研究音高和重音等因素对韵律的影响,如音高降阶效应、语流轻音等问题。
参 考 文 献
[1]韩纪庆,张磊,郑轶然.语音信号处理.北京:清华大学出版社,2004:1-10,160-189
[2] M. Tamura, T. Masuko, K. Tokuda and T. Kobayashi. Speaker adaptation for HMM-based speech synthesis system using MLLR[J]. Proc. of ESCA/COCOSDA Third International Workshop on Speech Synthesis,1998:273-276.
猜你喜欢
科技创新与应用(2017年3期)2017-02-18
中国新通信(2016年21期)2017-01-06
电脑知识与技术(2016年12期)2016-06-14
电脑知识与技术(2015年25期)2015-12-08
物联网技术(2015年9期)2015-09-22
现代电子技术(2015年11期)2015-07-28
现代电子技术(2015年8期)2015-07-09
电子技术与软件工程(2015年6期)2015-04-20
无线互联科技(2015年2期)2015-04-02
物联网技术(2015年3期)2015-03-31
